-
自定义类型(结构体、位段、联合体、枚举)

🎈前言
学了挺久的C语言,是不是发现仅有的内置类型不能描述很多问题呢?
一起走进自定义类型的世界吧φ(* ̄0 ̄)
自定义类型也包括数组。🏡结构体
为什么存在🤔
计算机本质是为了解决人类的问题,在生活中存在大量的集合体,仅有内置类型是无法描述复杂对象的。这个对象的特征属性存在多种类型。为了描述这个复杂对象,因此就需要一个类型来描述这个复杂对象的类型,结构体也就诞生了。
举个栗子
在写贪吃蛇小游戏的时候,你需要将蛇的属性描述出来。比如说蛇头,蛇身,长度,方向等,这样才能更好的去描述蛇这个对象。

🌲使用
🌱声明结构体
struct是关键字,这两个连起来struct S才是结构体类型。申明时内部成员不可以被赋值,成员用;结尾,最外面还有一个;struct S { int t; char a; };- 1
- 2
- 3
- 4
- 5
typedef重命名结构体类型,这个时候struct才可以省略,用St来表示这个结构体类型,struct S仍然可以使用。typedef struct S { int t; char a; }St;- 1
- 2
- 3
- 4
- 5
注意
可以像下面这样写吗?答案是不能。
可以这样去理解,程序执行的时候是顺序执行,从上到下,执行到St* stu;重命名的类型St并没有执行到,所以不可用。typedef struct S { int t; char a; St* stu; }St;- 1
- 2
- 3
- 4
- 5
- 6
只能这样写
typedef struct S { int t; char a; struct S* stu; }St;- 1
- 2
- 3
- 4
- 5
- 6
🌳结构体的自引用
这可以引出结构体的自引用,即结构体自己调用自己。
可以像下面这样无限套娃吗?不可以。struct S { int t; char a; struct S s1; };- 1
- 2
- 3
- 4
- 5
- 6
只能通过指针的形式去自引用
struct S { int t; char a; struct S* stu; };- 1
- 2
- 3
- 4
- 5
- 6
🌱特殊声明
对于下面这种声明,结构体类型并没有写完整,但却定义了变量。定义的两个变量,它们是同一个类型吗?不是。这种定义变量的形式只能在声明处定义变量,其它地方不可使用这个结构体类型去定义变量,可使用已经定义的变量
St。struct { int t; char a; }St; struct { int t; char a; }*Sa;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
🌲定义结构体变量
定义变量:结构体类型+ 变量名。有以下几种

结构体变量只能初始化,不能赋值!初始化:在定义变量处赋值。那如何赋值?只能取出成员一个一个赋值。
🌲结构体存储----内存对齐—重点难点
结构体的空间存储是怎么样的呢?
引入两个概念:偏移量,和对齐数。
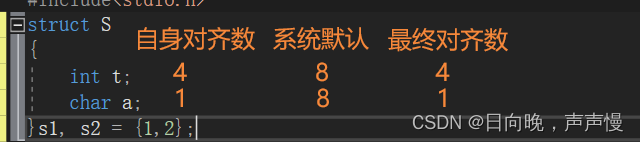
偏移是不是需要一个参照去进行偏移呢?这个参照是谁?是结构体的起始地址。那偏移量呢?相对于起始位置的差值。
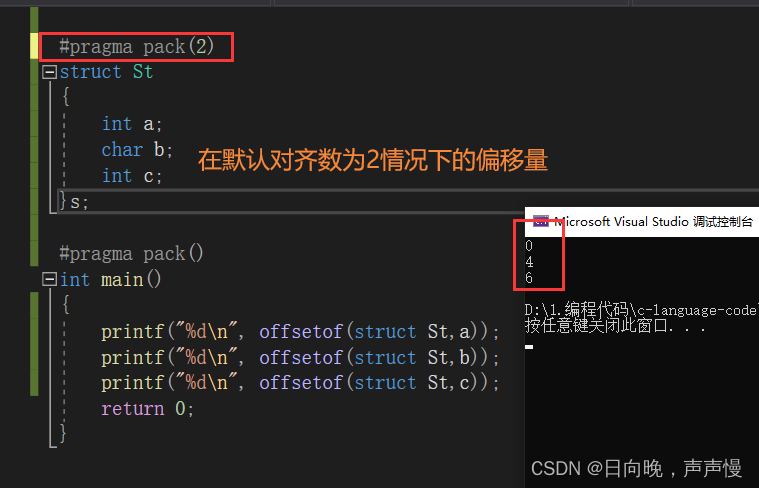
对齐数:编译器会存在一个对齐数,vs环境下,这个对齐数默认是8。结构体内部成员中,每个成员自身对齐数是自身类型的大小。每个成员所对应的对齐数是默认对齐数和自身对齐数中的较小者偏移量
假设起始地址为0x11223340。

对齐数
🌳求结构体空间大小的步骤
基本概念了解了,那可以开始了解结构体的内存布局。
①:第一个成员的起始位置永远在0偏移处
②:其它成员的起始地址处的偏移量是自身对应对齐数(最终对齐数)的整数倍
③:结构体中嵌套结构体,这个嵌套结构体的对齐数,为其内部成员的最大对齐数。
④:结构体最终的大小是:内部成员中最大对齐数的整数倍。每个成员都有一个对应的对齐数,选其中最大的。通过几个例子深入理解:
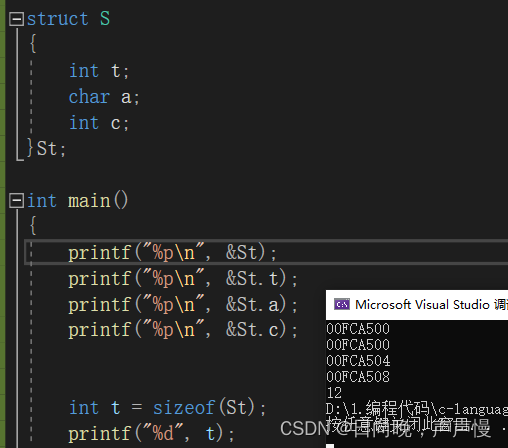
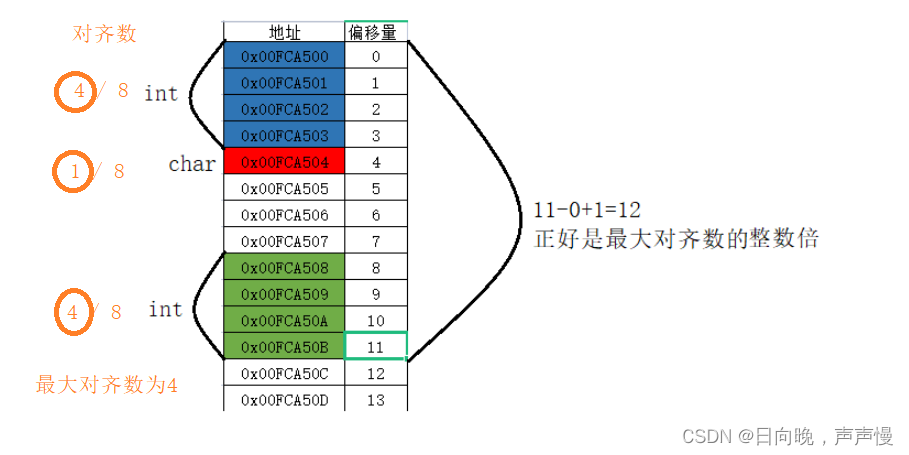
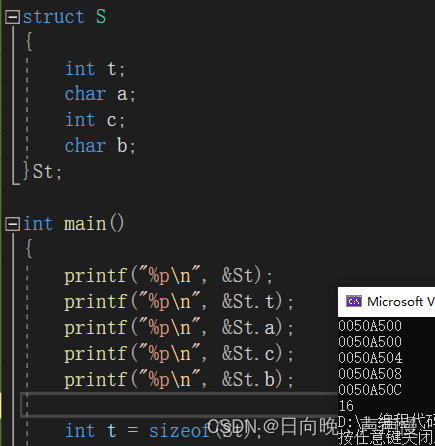
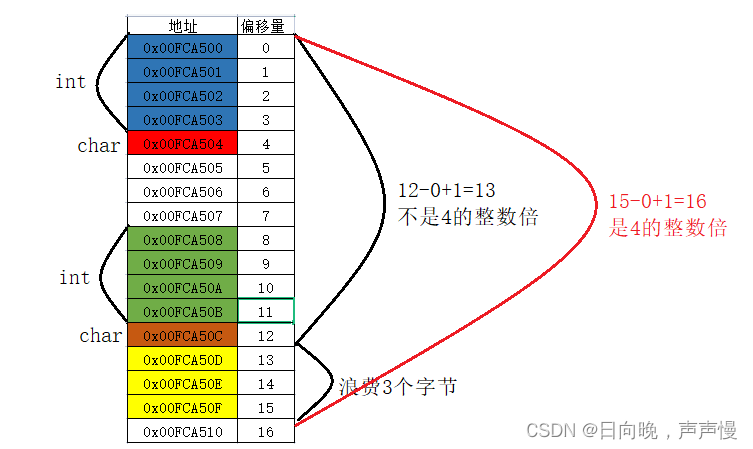
嵌套结构体的情况
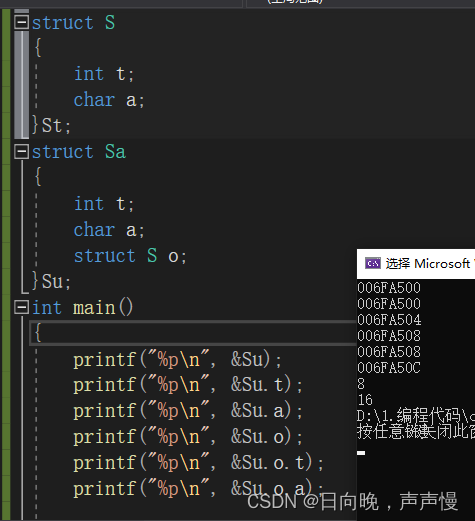

🌲offsetof和#pragma pack()
offsetof是一个宏,用来求结构体成员起始位置对应的偏移量。#pragma pack()是用来设置默认对齐数。
假设起始地址为0x00D3A500

和上面的图是对应的。
🌴offsetof的实现
我们已经知道了,偏移量是根据所对应的地址来求的。把起始地址特殊化,以0为起始地址,这样成员的地址就是它所对应的偏移量。光知道这还不成,你还需要知道,宏是可以传类型的。

为什么存在内存对齐🤔
①是为了提高访问的速率。
要读取int类型的数据(每次访问四个字节),在没对齐的时候,需要访问两次才可以拿到所有数据。而对齐的情况,只要访问一次就能读取到所有数据。
有人可能会疑惑为什么不直接从偏移量为1的地址处开始读取呢?需要知道偏移量0处才是结构体的起始位置。读取数据都是从起始位置开始向后读取的!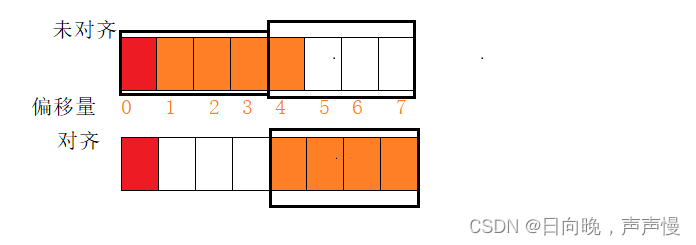
②平台原因,并不是所有的硬件平台上都可以访问任意地址,某些硬件平台只能在特定地址访问,否则会抛出硬件异常
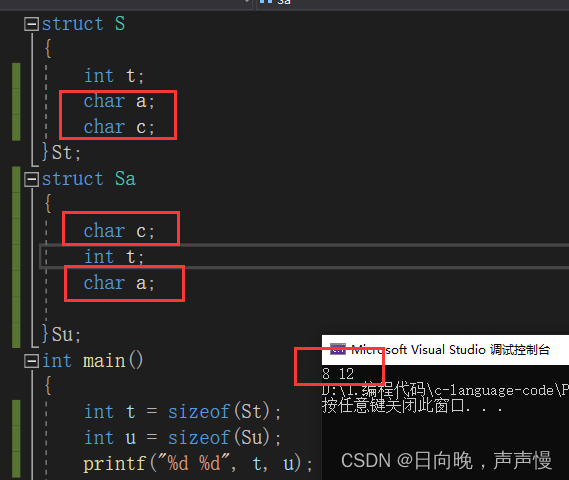
总体来说,内存对齐是拿空间换时间,但在设计结构体时可以将类型大小比较小的成员放在一起。这样结构体的空间会略小。
🌲结构体传参
先讲取成员的操作符
.和->int main() { St.a = 0; struct S* ps = &St; ps->b = 0; (*ps).c = 0; printf("%d\n", St.a); printf("%d\n", ps->b); printf("%d\n", (*ps).c); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
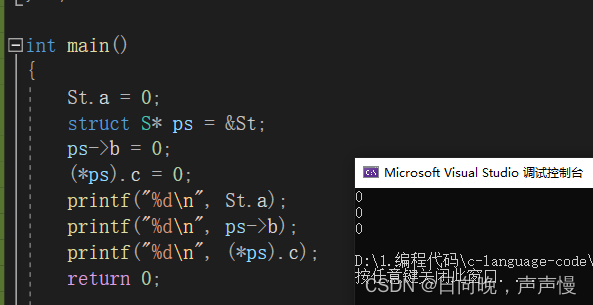
对于取成员存在两个操作符一个是
.一个是->为什么还要存在->呢?C语言是一门面向过程的语言。面向过程的语言失去了函数也就没有了灵魂,换句话说,在C语言中会大量用到函数。这又和->有什么关系呢?用到函数就要涉及到传参。对于结构体适合传值调用,还是适合传址调用呢?
储备知识:形参是实参的一份临时拷贝,即形参也会开辟一块内存空间存储数据。说的深奥一点,形参的形成,是在函数栈帧形成之前,形参是需要进行压栈,压栈就是将变量放到栈区即开辟空间。就拿之前写的通讯录来举例说明,如果通讯录内部的联系人有几十个,如果传值调用,形参又要再次开辟很大的空间来存储数据,主函数中已经存在一个同样大的空间存储这些联系人的数据。这是不是很浪费空间呢?如果是传址调用,那么的空间只有4个字节(32位平台下)两者两比孰优孰劣自能分晓。
这个时候也能回答为什么存在
->了,C语言中会使用大量的函数,而结构体是描述复杂对象,需要经常使用,传参又是传指针,给指针配套一个指向成员的操作符这能大大减轻程序员的负担,(*ps).c和ps->c哪个方便不用多说了吧。🌴位段
🌱为什么存在
存在的目的是节约空间。位段成员是以比特位为单位,去存储数据的,在有限的空间内,可以表达出更丰富的含义。
比如网络数据分装包就会涉及到位段,如果是以字节为单位,一个字节8个比特位,会存在大量的空间被浪费。
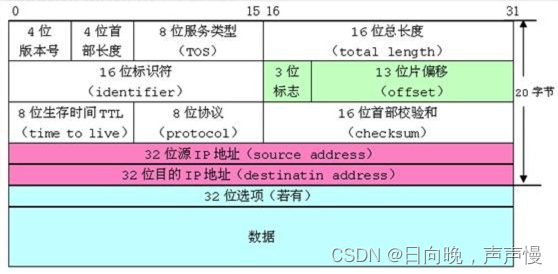
🌱什么是位段
和结构体类似不过成员后面用
:和数字。这个数字就是位段成员所需要的空间单位是比特位struct S { int t:1; char a:2; char c:3; }St;- 1
- 2
- 3
- 4
- 5
- 6
解释:对于成员t需要1个比特位,成员a需要2个比特位,成员c需要3个比特位。
🌱存储结构又如何?
位段是不具有跨平台性的,在不同平台下,位段存储的方式是不一样的。这里讲的是在VS下位段的存储。
🌲为什么不具有跨平台性呢?
①:位段在存取数据的时候并没有规定是从左边向右存取,还是从右向左存取数据。
②:不能判断位段的最高位是不是符号位
③:假如分配给位段1个字节的空间,使用完后,有剩余空间。这个剩余空间是继续使用还是丢弃,并未说明。
④:最大位不同。在32位平台下最大比特位是32,在64位平台下最大比特位是64。你可能会问既然存在这么多不确定性为什么还要存在?还是那句话为了节省空间。可以在不同的编译环境下写对应的位段,虽然麻烦,但能省空间。
🌲存储
位段的成员类型只有4种,有符号无符号的
int和char,当成员类型为int,每次先分配4个字节,只有当4个字节不够了,才会再次申请4个字节。当成员类型为char,每次先分配1个字节,不够了,再次申请1个字节。
如果存储数据的二进制位>分配的空间,会发生截断。
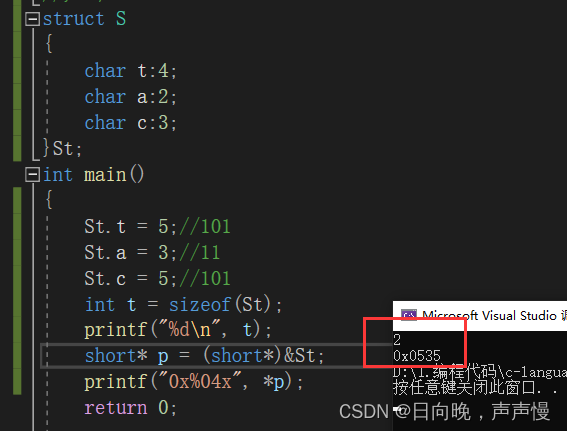
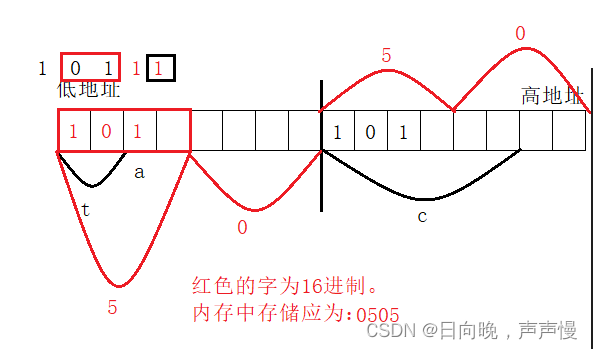
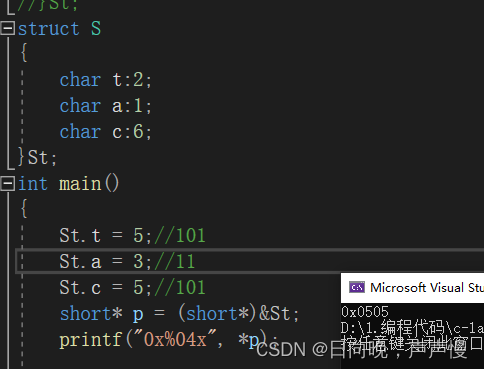
存储过程中遵循大小端。struct S { char t:4; char a:2; char c:3; }St; int main() { St.t = 5;//101 St.a = 3;//11 St.c = 5;//101 int t = sizeof(St); short* p = (short*)&St; printf("%d", t); printf("0x%04x", *p); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17

截断情况:struct S { char t:2; char a:1; char c:6; }St; int main() { St.t = 5;//101 St.a = 3;//11 St.c = 5;//101 short* p = (short*)&St; printf("0x%04x", *p); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
一般用不到,以后从事这方面工作的话可能会遇到,了解即可。
⛪联合体
是妙蛙种子😄
具体为什么存在挺难描述的,但我知道它挺妙的。
不知是否听闻大小端存储?用联合体判定大小端,比指针更为巧妙一些。什么是联合体🤔
联合体和结构体用法类似,然后换了个关键字
union,需要注意的是:在初始化的时候只能赋值一个。union Un是联合体类型,同样也是可以通过typedef重命名。typedef union Un { int a; char b; }Un;- 1
- 2
- 3
- 4
- 5
联合体的存储结构
联合体顾名思义共同使用一块空间。空间大小的不就简单了吗,只要选取最大的那个不就行了吗?真能这么简单吗?答案是不能。联合体的最终大小也要是最大对齐数的整数倍。
char b[7]它的对齐数是1union Un { int a; char b[7]; }u1,u2; int main() { int t = sizeof(u1); printf("%d\n", t); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
成员最大的空间是
char b[7];占7个字节,不是最大对齐数(4)的整数倍,最终的结果是8
联合体成员中谁是第一个成员🤔
union Un { int a; char b[7]; }u1,u2;- 1
- 2
- 3
- 4
- 5
是
int a吗?当然不会这么容易,对于联合体来说,内部成员都是第一个成员。为何这样说呢?来看各自成员的地址。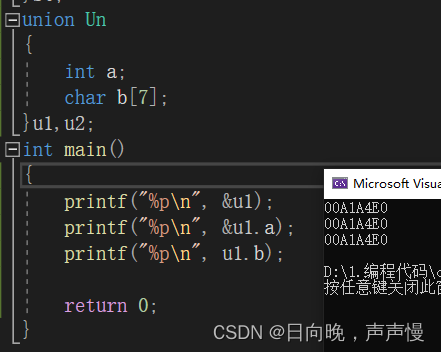
它们各自地址都是一样的。在C语言中取地址,取到的这个地址值一定是开辟空间中众多地址值最小的根据成员类型的大小来使用这块空间,成发散状。哪个成员使用,它就拥有这块空间,根据自身类型大小去使用空间。
第二次使用,第一次使用的数据会被清空吗?🤔
答案是不会。
union Un { int a; char b; }u1; int main() { u1.a = 0x11223344; printf("%x", u1.b); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
结果是44

开始提到的妙蛙种子,就是依据这个原理去判断大小端。
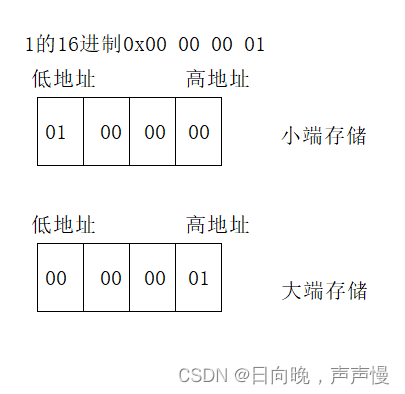
何为大小端?数据存入内存时,低权值位存入低地址,高权值位存入高地址就是小端存储。低权值位存入高地址,高权值位存入低地址就是大端存储联合体判断大小端
union Un { int a; char b; }u1; int main() { u1.a = 1; if (u1.b) printf("小端存储\n"); else printf("大端存储\n"); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
🛕枚举
为什么存在🤔
生活中存在大量相关性的常量需要去描述,这些相关性的常量就可以用枚举来表示,表达出来的效果具有自描述性,说人话就是你看到这个枚举的常量就能知道它是什么意思。这种情况下比用
#define定义的标识符会更好些举个栗子
在贪吃蛇中使用枚举常量来表示上下左右,比用1,2,3,4来描述是不是更好呢?用了枚举,你在写代码的时候,就不要去想1是什么,2是什么,看
UP,DOWN...就很容易知道往哪个方向,这就是自描述性,望文知意。
又如在通讯录的设计中,这里的常量就特别多,如果不使用枚举常量来代替,那每次写的时候,可能都要上去翻一翻1是什么,2是什么。
讲了这么多你可知其好处呢。
🌴声明枚举
和结构体不同,成员之间是用
,分隔,使用的关键字是enum。枚举成员叫枚举常量。enum color是枚举的类型,同样也可以通过typedef来重新命名。typedef enum color { BLUE, RED, GREEN, WHITE, }color;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
🌴枚举常量的值
枚举常量,既然是常量肯定有值,不做修改的话,这些值是连续的自然数。
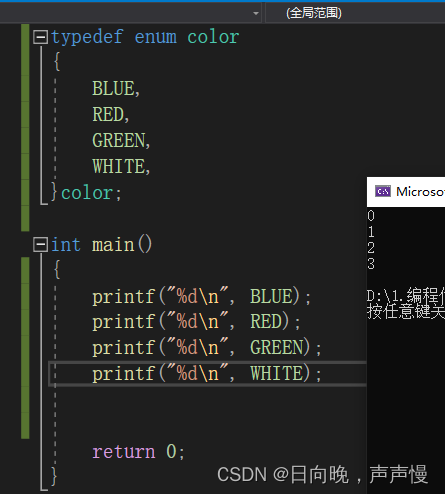
枚举常量的值以1去递增,可以修改枚举常量的初值。

一般是这样使用的:①定义枚举类型变量,赋值。这个值是枚举常量。②直接使用枚举常量的值。
第一个应用情境:在模拟aoti函数,需要去表示这个数值的有效还是无效,就可以用枚举来表示。//状态 enum status { VALID,//有效 INVALID,//有效 }; enum status st = INVALID;//转换的这个数是有效数值还是无效数值- 1
- 2
- 3
- 4
- 5
- 6
- 7
🌴枚举类型大小
枚举成员叫枚举常量,看到常量,我想你应该有所猜测了。

🌴枚举 vs #define定义的标识符
枚举是一种类型,
#define定义的标识符本质上是一种替换。在程序的预处理阶段就完成了替换,这就会导致,后续调试的时候并不能检测到标识符,而枚举可以检测到,使用枚举,代码可维护性更高。有多个常量,它们具有一定关联,用枚举更好,
#define这种代码太长,枚举的代码长度更短。单个出现的常量就用#define定义的标识符🌋结束语
-
相关阅读:
弗洛伊德算法(Java)
Oracle数据库---JDBC连接
java农家乐旅游管理系统springboot+vue
权限提升-Linux脏牛内核漏洞&SUID&信息收集
GO微服务实战第五节 为什么说 Service Meh 是下一代微服务架构?
Paragon NTFS 15Mac上NTFS分区的必备工具
MySQL8.0.26安装配置教程(windows 64位)
[附源码]计算机毕业设计springboot大学生考勤管理系统论文
面试面经|Java面试MySQL面试题
Ribbon 添加快速访问区域
- 原文地址:https://blog.csdn.net/m0_64212811/article/details/127352226
