-
项目(day02网站流量指标统计)
Hive的占位符与文件的调用
[root@hadoop01 ~]# cd /home/presoftware/apache-hive-1.2.0-bin/bin [root@hadoop01 bin]# vim 01.hive use weblog; create table stu(id int,name string);- 1
- 2
- 3
- 4
- 5
- 6
- 7
[root@hadoop01 bin]# sh hive -f 01.hive- 1
hive> show tables; OK dataclear flux stu tongji Time taken: 0.267 seconds, Fetched: 4 row(s) hive> desc stu; OK id int name string Time taken: 0.491 seconds, Fetched: 2 row(s)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
删除表
[root@hadoop01 bin]# vim 02.hive use weblog; drop table ${tbname};- 1
- 2
- 3
- 4
- 5
[root@hadoop01 bin]# sh hive -f 02.hive -d tbname='stu'- 1
[root@hadoop01 bin]# sh hive -f 03.hive -d time=' 2022-09-28'- 1
- 2
对于日期,如果不想手写的话,可以通过linux的指令来获取
date "+%G-%m-%d"- 1
方式一:
[root@hadoop01 bin]# date "+%G-%m-%d" 2022-10-01 [root@hadoop01 bin]# sh hive -f 03.hive -d time=`date "+%G-%m-%d"`- 1
- 2
- 3
方式二:
[root@hadoop01 bin]# sh hive -f 03.hive -d time=${date "+%G-%m-%d"}- 1
Linux Crontab定时任务
在工作中需要数据库在每天零点自动备份所以需要建立一个定时任务。crontab命令的功能是在一定的时间间隔调度一些命令的执行。
可以通过crontab -e进行定时任务的编辑
crontab文件格式︰
[root@hadoop01 bin]# crontab -e- 1
0 0 * * *./home/software/hive/bin/hive -f /home/software/hive/bin/O3.hive -d reportTime=`date %G-%y-%d`- 1
- 2
每隔1分钟,执行一次任务编写示例∶
*/1 * * * * rm -rf /home/software/1.txt- 1
每隔一分钟,删除指定目录的1.txt文件
将业务表数据导出到数据库
[root@hadoop01 software]# mysql -uroot -proot- 1
- 2
mysql> create database weblog; mysql> use weblog;- 1
- 2
create table tongji (reporttime varchar(40),pv int,uv int,vv int,br double,newip int,newcust int,avgtime double,avgdeep double);- 1
进入到sqoop,导出hdfs的文件到数据库
#hive 存储在hdfs的文件路径 /user/hive/warehouse/weblog.db/tongji #原文件内容格式按 | 分割 terminated-by '|'- 1
- 2
- 3
- 4
[root@hadoop01 bin]# pwd /home/presoftware/sqoop-1.4.4/bin [root@hadoop01 bin]# sh sqoop export --connect jdbc:mysql://192.168.253.129:3306/weblog --username root --password root --export-dir '/user/hive/warehouse/weblog.db/tongji' --table tongji -m 1 --fields-terminated-by '|'- 1
- 2
- 3
- 4
- 5
结果
mysql> select * from tongji; +------------+------+------+------+--------+-------+---------+-----------+---------+ | reporttime | pv | uv | vv | br | newip | newcust | avgtime | avgdeep | +------------+------+------+------+--------+-------+---------+-----------+---------+ | 2022-09-29 | 60 | 16 | 17 | 0.7647 | 0 | 13 | 1665.5882 | 1.2353 | +------------+------+------+------+--------+-------+---------+-----------+---------+ 1 row in set (0.00 sec)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
连线处理数据完成
=========================
zk kafka sparkstreaming整合
实时处理
服务启动
zk 集群启动(3个)[root@hadoop01 bin]# sh zkServer.sh start [root@hadoop01 bin]# sh zkServer.sh status- 1
- 2
- 3
kafka启动(一台)
[root@hadoop02 bin]# pwd /home/presoftware/kafka_2.11-1.0.0/bin- 1
- 2
- 3
如果用一台kafka,需要把zk上注册的kafka服务清除,然后重启Kafka,就是一台Kafka服务了

[zk: localhost:2181(CONNECTED) 0] ls / [cluster, brokers, zookeeper, log, yarn-leader-election, hadoop-ha, admin, isr_change_notification, log_dir_event_notification, controller_epoch, rmstore, consumers, latest_producer_id_block, config, hbase] [zk: localhost:2181(CONNECTED) 1] rmr /cluster [zk: localhost:2181(CONNECTED) 2] rmr /brokers [zk: localhost:2181(CONNECTED) 3] rmr /admin [zk: localhost:2181(CONNECTED) 4] rmr /isr_change_notification [zk: localhost:2181(CONNECTED) 5] rmr /log_dir_event_notification [zk: localhost:2181(CONNECTED) 6] rmr /controller_epoch [zk: localhost:2181(CONNECTED) 7] rmr /consumers [zk: localhost:2181(CONNECTED) 8] rmr /latest_producer_id_block [zk: localhost:2181(CONNECTED) 9] rmr /config [zk: localhost:2181(CONNECTED) 10] ls / [zookeeper, log, yarn-leader-election, hadoop-ha, rmstore, hbase] [zk: localhost:2181(CONNECTED) 11]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
清除Kafka日志
[root@hadoop01 kafka_2.11-1.0.0]# ls bin config kafka-logs libs LICENSE logs NOTICE site-docs [root@hadoop01 kafka_2.11-1.0.0]# rm -rf kafka-logs- 1
- 2
- 3
- 4
Kafka单机启动
#启动 [root@hadoop01 bin]#sh kafka-server-start.sh ../config/server.properties #查看主题(刚安装的kafka或者删除kafka数据此刻查不到主题存在) [root@hadoop01 bin]# sh kafka-topics.sh --list --zookeeper hadoop01:2181- 1
- 2
- 3
- 4
- 5
新建一个Scala项目
注意引入jar包–spark源码里边的包引入
还有spark-streaming-kafka-0-8_2.11-2.2.0
引入Kafka源码里边的libs包,需要删除非jar包文件(.asc结尾)注意Kafka配置
[root@hadoop01 config]# vim server.properties log.dirs=/home/presoftware/kafka_2.11-1.0.0/kafka-logs zookeeper.connect=hadoop01:2181,hadoop02:2181,hadoop03:2181- 1
- 2
- 3
kakfa创建一个主题,生产者生产----Linux控制台输入数据
#创建主题 sh kafka-topics.sh --create --zookeeper hadoop01:2181 --replication-factor 1 --partitions 1 --topic enbook #生产者生产数据---控制台输入数据 sh kafka-console-producer.sh --broker-list hadoop01:9092 --topic enbook- 1
- 2
- 3
- 4
- 5
总结:通过连接zk,监听Kafka上生产者生产的数据到sparkstreaming
====================================
flume 和 Kafka 整合
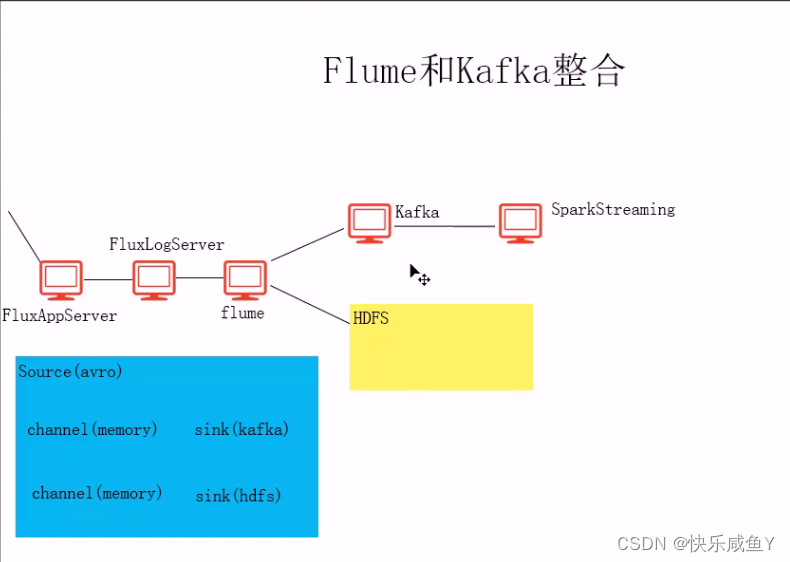
flum修改[root@hadoop01 data]# vim web.conf a1.sources=s1 #加入c2 k2 a1.channels=c1 c2 a1.sinks=k1 k2 a1.sources.s1.type=avro a1.sources.s1.bind=0.0.0.0 a1.sources.s1.port=44444 a1.source.s1.interceptors=i1 a1.source.s1.interceptors.i1.type=timestamp a1.channels.c1.type=memory a1.channels.c1.capacity=1000 a1.channels.c1.transactionCapacity=100 #加入c2 a1.channels.c2.type=memory a1.channels.c2.capacity=1000 a1.channels.c2.transactionCapacity=100 a1.sinks.k1.type=hdfs a1.sinks.k1.hdfs.path=hdfs://hadoop01:9000/weblog/reporttime=%Y-%m-%d a1.sinks.k1.hdfs.rollInterval=30 a1.sinks.k1.hdfs.fileType=DataStream a1.sinks.k1.hdfs.rollSize=0 a1.sinks.k1.hdfs.rollCount=0 a1.sinks.k1.hdfs.useLocalTimeStamp = true #k2配置 a1.sinks.k2.type=org.apache.flume.sink.kafka.KafkaSink #如果是多个kafka则用逗号接上其他的Kafka a1.sinks.k2.brokerList=hadoop01:9092 a1.sinks.k2.topic=weblog #加入c2 a1.sources.s1.channels=c1 c2 a1.sinks.k1.channel=c1 #建立连接 a1.sinks.k2.channel=c2- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
启动flume
#data目录 ../bin/flume-ng agent -n a1 -c ./ -f ./web.conf -Dflum.root.logger=INFO,console- 1
- 2
kafka创建主题(首先kafka是启动状态)
#bin目录 sh kafka-topics.sh --create --zookeeper hadoop01:2181 --replication-factor 1 --partitions 1 --topic weblog- 1
- 2
启动前端tomcat
十月 01, 2022 8:57:18 下午 org.apache.coyote.AbstractProtocol start 信息: Starting ProtocolHandler ["http-bio-8080"] 十月 01, 2022 8:57:18 下午 org.apache.coyote.AbstractProtocol start 信息: Starting ProtocolHandler ["ajp-bio-8009"] 十月 01, 2022 8:57:18 下午 org.apache.catalina.startup.Catalina start- 1
- 2
- 3
- 4
- 5
最后sparkstreaming监听zk,或者Kafka的数据,输出打印台
package cn.tedu.kafka.streaming import org.apache.spark.SparkConf import org.apache.spark.SparkContext import org.apache.spark.streaming.StreamingContext import org.apache.spark.streaming.Seconds import org.apache.spark.streaming.kafka.KafkaUtils object Driver { def main(args: Array[String]): Unit = { //如果是本地模式,消费Kafka数据,启动的线程数至少是2个 //其中一个线程负责SparkStreaming,另外一个线程负责从Kafka消费 //如果只启动一个线程,则无法从kafka消费数据 val conf=new SparkConf().setMaster("local[2]").setAppName("kafkastreaming") val sc=new SparkContext(conf) val ssc=new StreamingContext(sc,Seconds(5)) //-指定zookeeper集群地址 val zkHosts="hadoop01:2181,hadoop02:2181,hadoop03:2181" val group="gp1" //key是主题名, value是消费的线程数,可以指定多对kv对(即消费多个主题) val topics=Map("enbook"->1,"weblog"->1) //通过工具类,从kafka消费数据 val kafkaStream=KafkaUtils.createStream(ssc, zkHosts, group, topics) .map{x=>x._2} kafkaStream.print() ssc.start() ssc.awaitTermination() } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
------------------------------------------- Time: 1664629180000 ms ------------------------------------------- http://localhost:8080/FluxAppServer/a.jsp|a.jsp|页面A|UTF-8|1920x1080|24-bit|en|0|1||0.6180031581372263||Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36|59844165863196852806|3977599915_0_1664629156259|0:0:0:0:0:0:0:1 http://localhost:8080/FluxAppServer/b.jsp|b.jsp|页面B|UTF-8|1920x1080|24-bit|en|0|1||0.9027473128062127|http://localhost:8080/FluxAppServer/a.jsp|Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36|59844165863196852806|3977599915_2_1664629167133|0:0:0:0:0:0:0:1 http://localhost:8080/FluxAppServer/a.jsp|a.jsp|页面A|UTF-8|1920x1080|24-bit|en|0|1||0.7683067045194791||Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36|59844165863196852806|3977599915_1_1664629166068|0:0:0:0:0:0:0:1- 1
- 2
- 3
- 4
- 5
- 6
- 7
hbase启动(zk启动的情况下,第一台启动即可)
[root@hadoop01 bin]# sh start-hbase.sh- 1
进入客户端
[root@hadoop01 bin]# sh hbase shell- 1
建表
hbase(main):001:0>create 'tb1','cf1'- 1
执行插入命令
package cn.tedu.spark.hbase import org.apache.spark.SparkConf import org.apache.spark.SparkConf import org.apache.spark.SparkContext import org.apache.hadoop.hbase.mapreduce.TableOutputFormat import org.apache.hadoop.mapreduce.Job import org.apache.hadoop.hbase.io.ImmutableBytesWritable import org.apache.hadoop.fs.shell.find.Result import org.apache.hadoop.hbase.client.Put object WriteDriver { def main(args: Array[String]): Unit = { val conf=new SparkConf().setMaster("local[2]").setAppName("writeHBase") val sc=new SparkContext(conf) //设置zookeeper集群地址 sc.hadoopConfiguration.set("hbase.zookeeper.quorum", "hadoop01,hadoop02,hadoop03") //-设置zookeeper端口号 sc.hadoopConfiguration.set("hbase.zookeeper.property.clientPort", "2181") //设置写出的HBase表名 sc.hadoopConfiguration.set(TableOutputFormat.OUTPUT_TABLE,"tb1") val job=new Job(sc.hadoopConfiguration) //指定输出key类型 job.setOutputKeyClass(classOf[ImmutableBytesWritable]) //指定输出value类型 job.setOutputValueClass(classOf[Result]) //指定输出的表类型 job.setOutputFormatClass(classOf[TableOutputFormat[ImmutableBytesWritable]]) //1.准备RDD[(key , value)] //2.执行插入HBase val r1=sc.makeRDD(List("1 tom 18","2 rose 25","3 jim 20")) val hbaseRDD=r1.map { line => val info=line.split(" ") val id=info(0) val name=info(1) val age=info(2) //创建一个HBase 行对象,并指定行键 val put=new Put(id.getBytes) //①参:列族名②参:列名③参:列值 put.add("cf1".getBytes, "name".getBytes, name.getBytes) put.add("cf1".getBytes, "age".getBytes, age.getBytes) (new ImmutableBytesWritable,put) } //执行插入 hbaseRDD.saveAsNewAPIHadoopDataset(job.getConfiguration) } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
查表
hbase(main):004:0> scan 'tb1' ROW COLUMN+CELL 1 column=cf1:age, timestamp=1664632469722, value=18 1 column=cf1:name, timestamp=1664632469722, value=tom 2 column=cf1:age, timestamp=1664632469722, value=25 2 column=cf1:name, timestamp=1664632469722, value=rose 3 column=cf1:age, timestamp=1664632469722, value=20 3 column=cf1:name, timestamp=1664632469722, value=jim 3 row(s) in 0.1510 seconds- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
读取hbase的操作案例(tb1表)
package cn.tedu.spark.hbase import org.apache.spark.SparkConf import org.apache.spark.SparkContext import org.apache.hadoop.hbase.HBaseConfiguration import org.apache.hadoop.hbase.mapreduce.TableInputFormat import org.apache.hadoop.hbase.io.ImmutableBytesWritable import org.apache.hadoop.hbase.client.Result object ReadDriver01 { def main(args: Array[String]): Unit = { val conf=new SparkConf().setMaster("local[2]").setAppName("readHBase") val sc=new SparkContext(conf) //创建HBase环境参数对象 val hbaseConf=HBaseConfiguration.create() // hbaseConf.set("hbase.zookeeper.quorum", "hadoop01,hadoop02,hadoop03") // hbaseConf.set("hbase.zookeeper.property.clientPort", "2181") //指定读取的HBase表名 hbaseConf.set(TableInputFormat.INPUT_TABLE,"tb1") //①参:HBase环境参数对象②参∶读取表类型③参:输入key类型4参∶输入value //sc.newAPIHadoopRDD执行读取,并将结果返回到RDD中 val result=sc.newAPIHadoopRDD(hbaseConf, classOf[TableInputFormat], classOf[ImmutableBytesWritable], classOf[Result]) result.foreach{x=> //获取每行数据的对象 val row=x._2 //①参:列族名②参:列名 val name=row.getValue("cf1".getBytes, "name".getBytes) val age=row.getValue("cf1".getBytes, "age".getBytes) // println(new String(name)+":"+new String(age)) } // } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
读表student的案例(扫描功能和过滤功能)
package cn.tedu.spark.hbase import org.apache.spark.SparkConf import org.apache.spark.SparkContext import org.apache.hadoop.hbase.HBaseConfiguration import org.apache.hadoop.hbase.mapreduce.TableInputFormat import org.apache.hadoop.hbase.client.Scan import org.apache.hadoop.hbase.mapreduce.TableInputFormat import org.apache.hadoop.hbase.protobuf.ProtobufUtil import org.apache.hadoop.hbase.util.Base64 import org.apache.hadoop.hbase.io.ImmutableBytesWritable import org.apache.hadoop.hbase.client.Result import org.apache.hadoop.hbase.filter.PrefixFilter object ReadDriver02 { def main(args: Array[String]): Unit = { val conf=new SparkConf().setMaster("local[2]").setAppName("readHBase") val sc=new SparkContext(conf) //创建HBase环境参数对象 val hbaseConf=HBaseConfiguration.create() // hbaseConf.set("hbase.zookeeper.quorum", "hadoop01,hadoop02,hadoop03") // hbaseConf.set("hbase.zookeeper.property.clientPort", "2181") //指定读取的HBase表名 hbaseConf.set(TableInputFormat.INPUT_TABLE,"student") //创建HBase扫描对象 val scan=new Scan() //设定扫描范围 // scan.setStartRow("s99988".getBytes) // scan.setStopRow("s99989".getBytes) // val filter=new PrefixFilter("s9997".getBytes) //设置filter生效 scan.setFilter(filter) //创建HBase前缀过滤器,下面表示匹配所有行键以s9997开头的行数据 hbaseConf.set(TableInputFormat.SCAN,Base64.encodeBytes(ProtobufUtil.toScan(scan).toByteArray())) //①参:HBase环境参数对象②参∶读取表类型③参:输入key类型4参∶输入value //sc.newAPIHadoopRDD执行读取,并将结果返回到RDD中 val result=sc.newAPIHadoopRDD(hbaseConf, classOf[TableInputFormat], classOf[ImmutableBytesWritable], classOf[Result]) result.foreach{x=> val row=x._2 val id=row.getValue("basic".getBytes, "id".getBytes) println(new String(id)) } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
p0.56
-
相关阅读:
使用 KubeBlocks 为 K8s 提供稳如老狗的数据库服务
USB学习(3):USB描述符和USB类设备
5G端到端网络切片进展与挑战分析
如何打开html格式文件?Win11打开html文件的方法
7.2-CM46 合法括号序列判断
国际经济合作真题全集
唐诗的四个阶段
第一百三十回 Flutter与原生平台通信
FPGA 学习笔记:Vivado 2019.1 工程创建
大规模 IoT 边缘容器集群管理的几种架构-3-Portainer
- 原文地址:https://blog.csdn.net/yygyj/article/details/127134784
