-
【ML07】Linear Regression using Scikit-Learn
Linear Regression using Scikit-Learn
Scikit-Learn 是一个非常重要的、开源的机器学习工具包,其中集成了很多算法,使得无需手写算法,直接输入参数以及函数可以得到结果。
详情访问: https://scikit-learn.org/stable/index.html

下载data
我的资源池,0积分下载,如无法下载可留言,收到后转发给你。
S1: 加载数据集数据
数据来源:吴恩达《ML》实验室house数据,仅用于学习交流。
import numpy as np def load_house_data(): data = np.loadtxt("./data/houses.txt", delimiter=',', skiprows=1) X = data[:,:4] y = data[:,4] return X, y X_train, y_train = load_house_data() # print(X_train) X_features = ['size(sqft)','bedrooms','floors','age']- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
S2: 对数据进行处理
StandardScaler类: 用于处理数据归一化和标准化。
fit_transform(a)方法: 找出a的均值和方差。
np.ptp(a)方法: 对a中所有数据计算最大值和最小值的差值。x = ( x − μ ) σ ,其中 σ 为方差的值, μ 为平均值 x = \frac{(x-μ)}σ,其中 σ 为方差的值,μ 为平均值 x=σ(x−μ),其中σ为方差的值,μ为平均值
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() # 用于处理数据归一化和标准化 X_norm = scaler.fit_transform(X_train) # 找出a的均值和方差,计算公式a得到结果 print(np.ptp(X_train,axis=0)) # 打印X_train中最大值与最小值的差 print(np.ptp(X_norm,axis=0)) # 打印X_norm中最大值与最小值的差- 1
- 2
- 3
- 4
- 5
- 6
S3: 创建和拟合模型
随机梯度下降英文是 Stochastic gradient descend (SGD) 。
而在scikit-learn中,随机梯度下降被叫做 SGDRegressor。
SGD与BGD(批量梯度下降) 比较,区别在于 SGD 是每选取一个样本,进行计算然后更新参数;而BGD则是将所有样本数据都计算完成后再更新参数。from sklearn.linear_model import SGDRegressor sgdr = SGDRegressor(max_iter=1000) sgdr.fit(X_norm, y_train) print(f"完成的迭代次数: {sgdr.n_iter_}, 权重更新次数: {sgdr.t_}")- 1
- 2
- 3
- 4
- 5

# 接上 b_norm = sgdr.intercept_ w_norm = sgdr.coef_ print(f"参数 w: {w_norm}, 参数 b:{b_norm}") print( "之前实验室的模型参数 w: [110.56 -21.27 -32.71 -37.97], 参数 b: 363.16")- 1
- 2
- 3
- 4
- 5
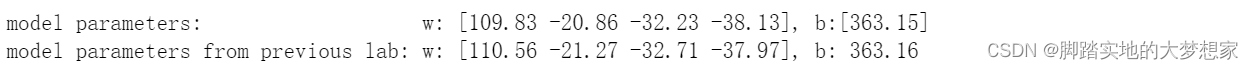
S4: 做预测
sgdr.predict: 用sgdr做预测,预测出测试集的预测值
np.dot: 用numpy的求w向量和x向量的数量积,具体见博客:https://blog.csdn.net/weixin_43098506/article/details/127090413y_pred_sgd = sgdr.predict(X_norm) y_pred = np.dot(X_norm, w_norm) + b_norm print(f"使用 np.dot() 是否与 sgdr.predict 匹配: {(y_pred == y_pred_sgd).all()}") print(f"预测值:\n{y_pred[:4]}" ) print(f"实际值 \n{y_train[:4]}")- 1
- 2
- 3
- 4
- 5
- 6

end->>>
What’s more
在plt上展示出!
# plot predictions and targets vs original features fig,ax=plt.subplots(1,4,figsize=(12,3),sharey=True) for i in range(len(ax)): ax[i].scatter(X_train[:,i],y_train, label = 'target') ax[i].set_xlabel(X_features[i]) ax[i].scatter(X_train[:,i],y_pred,color=dlc["dlorange"], label = 'predict') ax[0].set_ylabel("Price"); ax[0].legend(); fig.suptitle("target versus prediction using z-score normalized model") plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
-
相关阅读:
1097:画矩形(信奥)
离线部署NFS文件系统
Gralloc ION DMABUF in Camera & Display
灰色预测GM(1.1)模型及matlab程序负荷预测
AI赋能程序员(学生免费申请流程):Pycharm安装copilot让AI帮忙写python代码
【牛客 - 剑指offer】JZ84 二叉树中和为某一值的路径(三)
「Qt中文教程指南」如何创建基于Qt Widget的应用程序(一)
SinoDB数据库资源分析
Python算法图解——递归(二):打印从10循环到1
tslib編译和安装
- 原文地址:https://blog.csdn.net/weixin_43098506/article/details/127136507