-
C++打怪升级(二)- 引用详解

前言
引用,是C++中重要的概念,它贯穿着C++的学习。不好好理解引用,接下来的路会不太好走哦!
不过别担心,看完这一篇问题就不大了。
引用是什么
概念
引用
reference是为已经存在的变量取另外一个名字,是该变量的别名。
在C++语法角度:编译器不会为引用变量开辟内存空间,它和所引用的变量共用同一块内存空间。
引用类型是**复合类型,**格式数据类型& 引用变量名(对象名) = 引用实体;
与指针类型类似数据类型* 指针变量名 = 对象的地址
简单举例
#include//只是为了说明引用在干嘛 int main(){ int a = 10; int &ra = a;//ra对a的引用 int &rra = ra;//rra对ra的引用,而ra是a的别名,故rra是a的引用 a++; ra++; rra++; return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
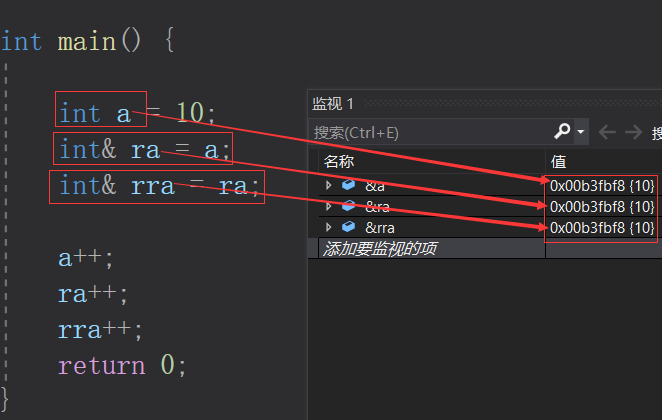
可以看到变量a的地址与引用ra的地址、引用rra的地址相同。
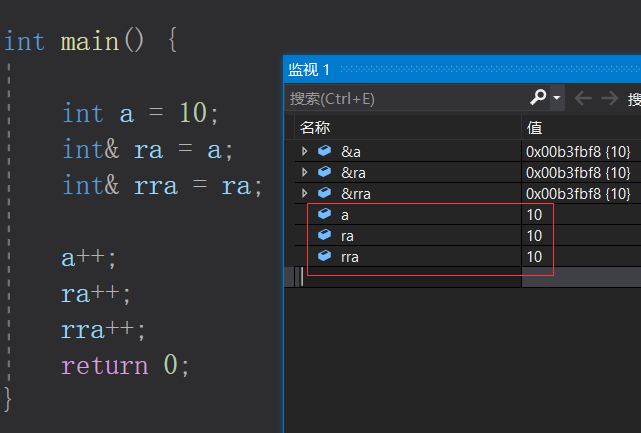
初始a、ra、rra都是10
程序往下执行
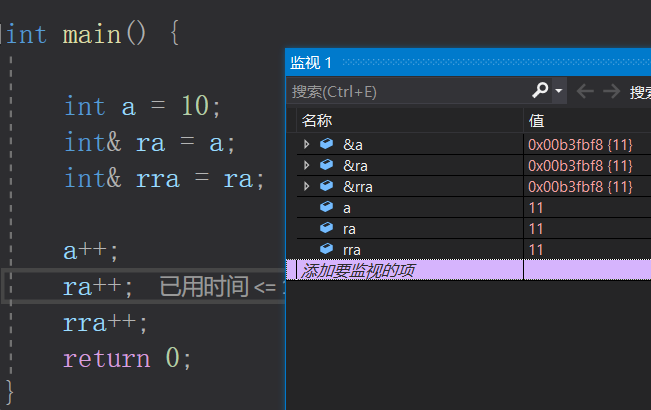
a++;
a、ra、rra同时+1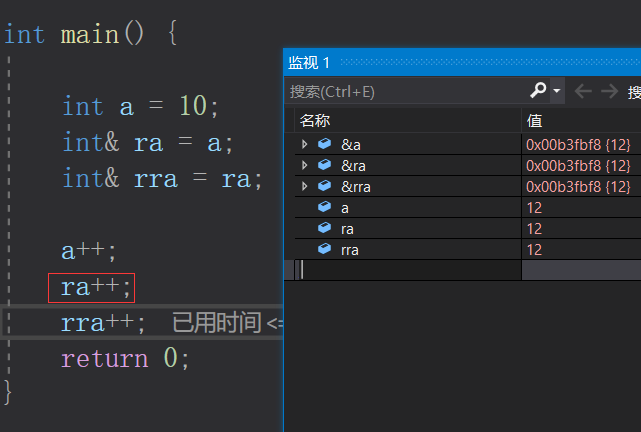
程序往下执行
ra++;
a、ra、rra再同时+1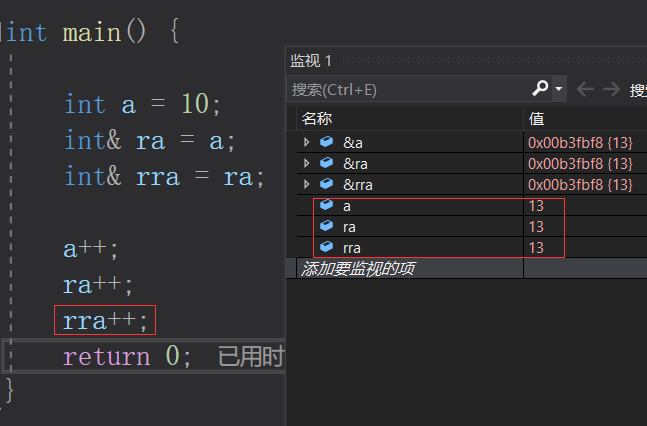
最后程序执行
ra++;
a、ra、rra同时+1
引用特性
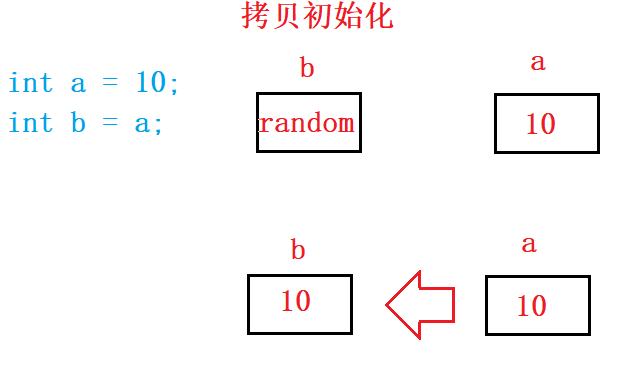
一般变量在初始化时是把初始值拷贝到变量(对象)中,而引用变量在初始化时是把引用变量和它的初始值绑定在了一起,并且无法重新绑定到另外一个对象。

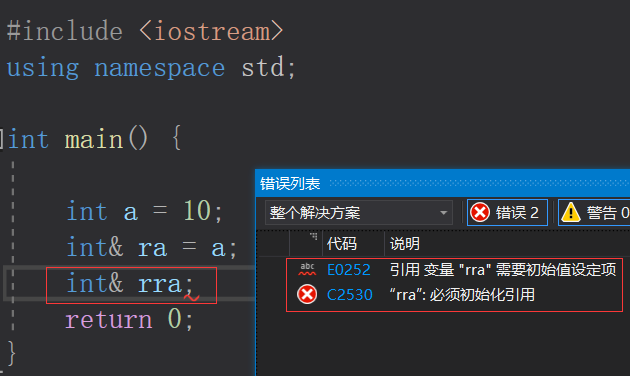
1.引用在定义时必须初始化
- 一个变量可以有多个引用
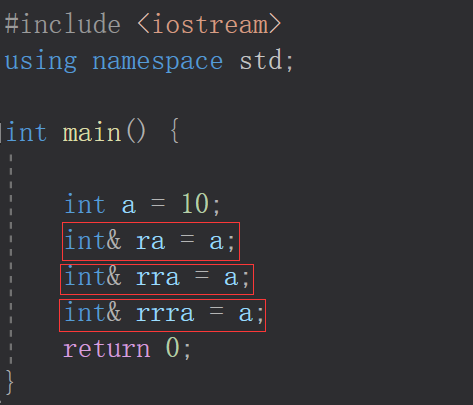
- 引用一旦引用了一个实体,在本次程序执行中就不能再引用其它实体了
- 引用类型一般和引用实体是同种类型且严格匹配的,但是例外情况。
引用的真正用途
引用做函数参数
减少拷贝,提高传参效率
#includeusing namespace std; //交换两个整数 void Swap(int& a, int& b) { int tmp = a; a = b; b = tmp; } int main() { int x = 10; int y = 20; cout << "前x: " << x; cout << " y: " << y << endl; Swap(x, y); cout << "后x: " << x; cout << " y: " << y << endl; return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
使用函数交换两个数,以前我们使用的方法是传入待交换两个数的地址
本质是仍是传值调用,函数形参是指针类型;void Swap(int* pa, int* pb) { int tmp = *pa; *pa = *pb; *pb = tmp; }- 1
- 2
- 3
- 4
- 5
现在我们学习了引用,交换两个数我们只让函数形参变为引用类型
传引用调用,只需要传入待交换两个数本身即可完成交换。因为引用是引用对象的别名,引用形参接受实参,对引用的改变就是对实参的改变,相当于传入的是实参本身。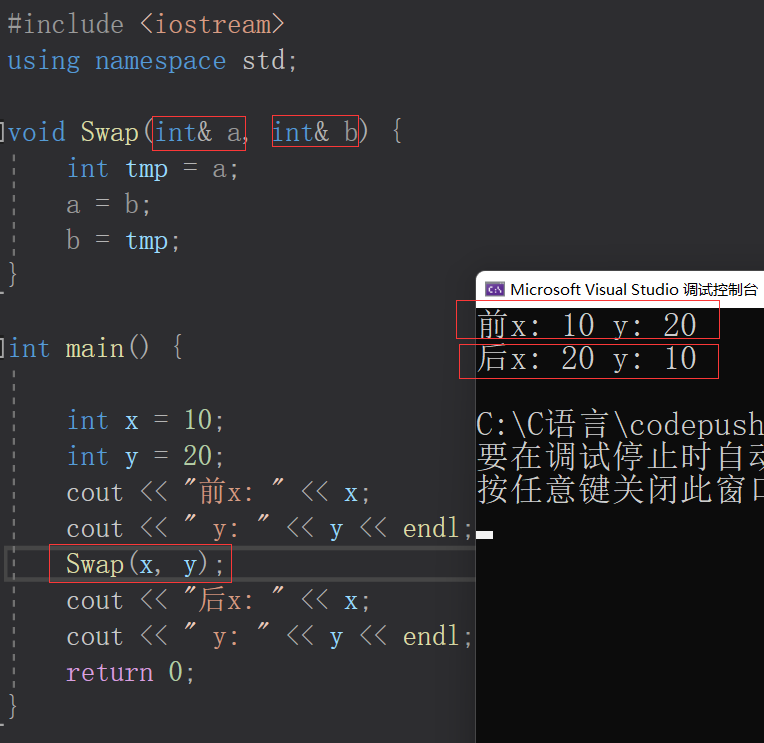
做输出型参数,直接修改实参
对于某些参数传入的目的不只是为了本函数使用,更是为了在本函数调用结束后能够反映到外界(主调函数等),函数调用结束返回时又只能返回一个变量,一个解决办法是使用引用做输出型参数,不作为返回值返回。
关于做输出型参数这一点指针类型也可以实现,引用则使得输出型参数更简化和方便。
举个例子:比如说在我们写oj题时就可能会遇到输出型参数
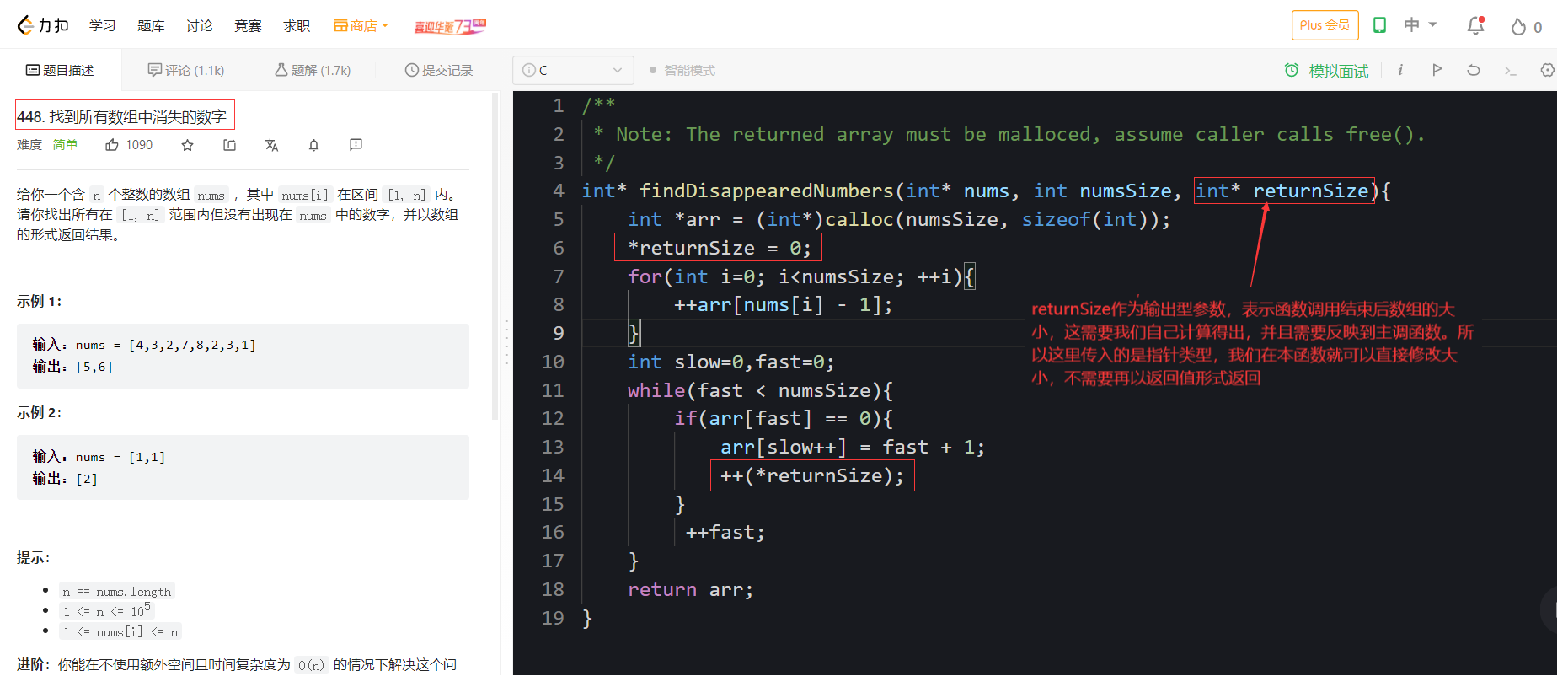
引用做返回值
先上结论:引用做返回值返回的是要返回那个变量本身,而不是那个变量的匿名拷贝。
#includeusing namespace std; int& Count(){ static int n = 0; n++; return n; } int main() { int& ret = Count(); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
关于函数返回时的一些讨论
我们先来看看**非引用返回(传值返回)**时,函数返回发生了什么:
#includeusing namespace std; int Count(){ static int n = 0; n++; return n; } int main() { int ret = Count(); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
我们知道,调用函数时就会创建对应的函数栈帧。首先系统首先为
main函数开辟了一块栈帧,接着在main函数内部,调用Count函数并为Count函数开辟一块栈帧空间。
static修饰变量生命周期延长到了程序运行期间,其并没有放在Count函数栈帧里面,而是在程序运行开始就放在了静态区。
Count函数执行完相关操作后返回int型变量,但是像这种传值返回的情况,返回的并不是待返回变量本身,本例中返回的不是静态变量n本身,而是分为两种情况:- 如果待返回的变量所占字节很小(
小于4byte),会存放到寄存器中,由寄存器随着栈帧的销毁而返回到上一层栈帧; - 如果返回的变量字节较大,在开辟上一层栈帧时(本例为main函数栈帧)会事先为根据返回类型预留足够的空间,在
Count函数返回栈帧销毁时,在main函数栈帧创建一个匿名临时变量,这个临时变量有着待返回变量的拷贝。
总结来说,函数传值返回,返回的是待返回变量的拷贝;而待返回变量如果在待返回的函数栈帧里就会作为局部变量被销毁,尽管本例中待返回变量
n不在待销毁栈帧里,而是在静态区,生命周期一直到程序结束,在函数Count销毁后,静态变量也不能够使用了因为其作用域在Count函数内部。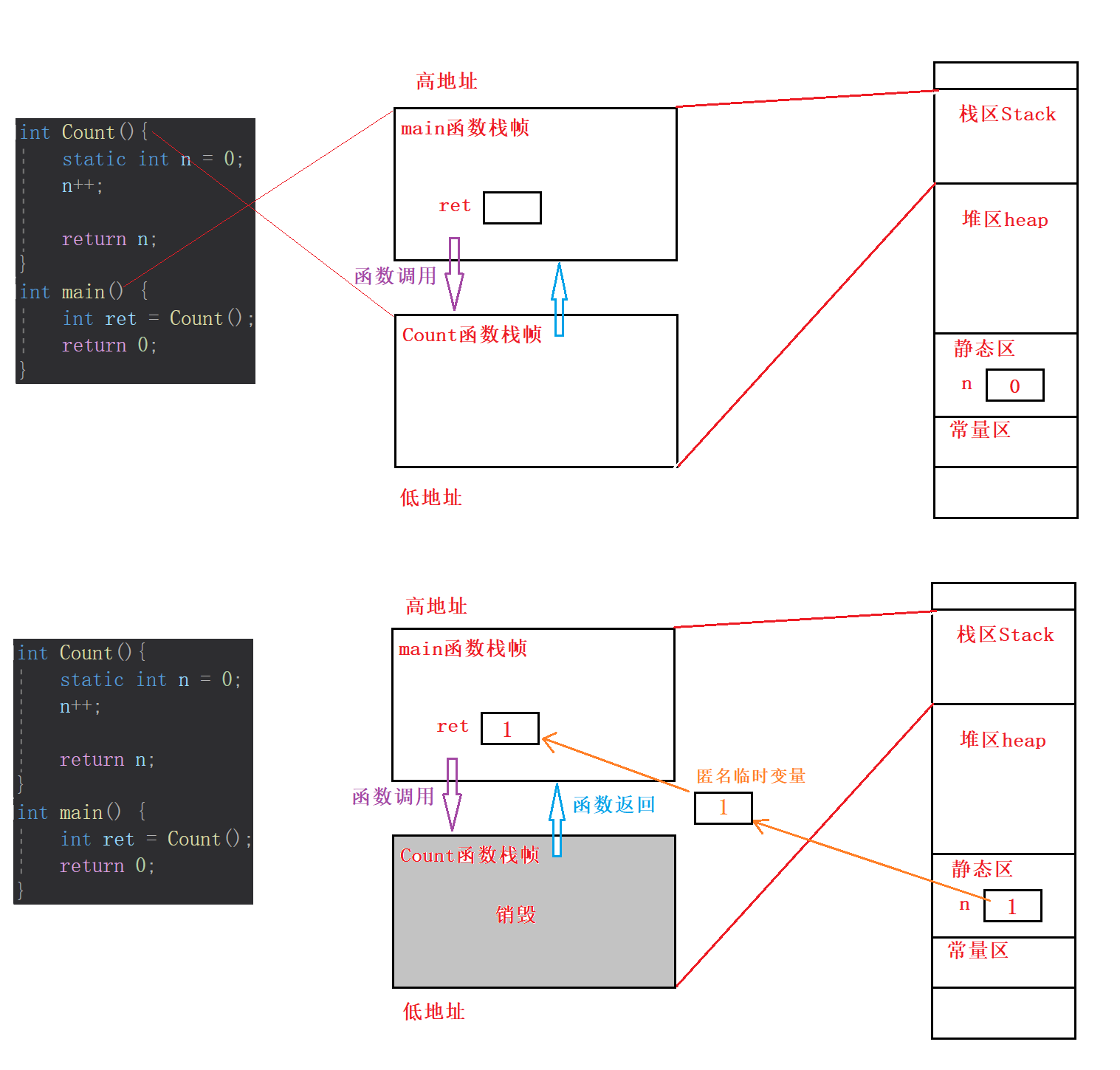
再来看看传引用返回时发生了什么:
#includeusing namespace std; int& Count(){ static int n = 0; n++; return n; } int main() { int& ret = Count(); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
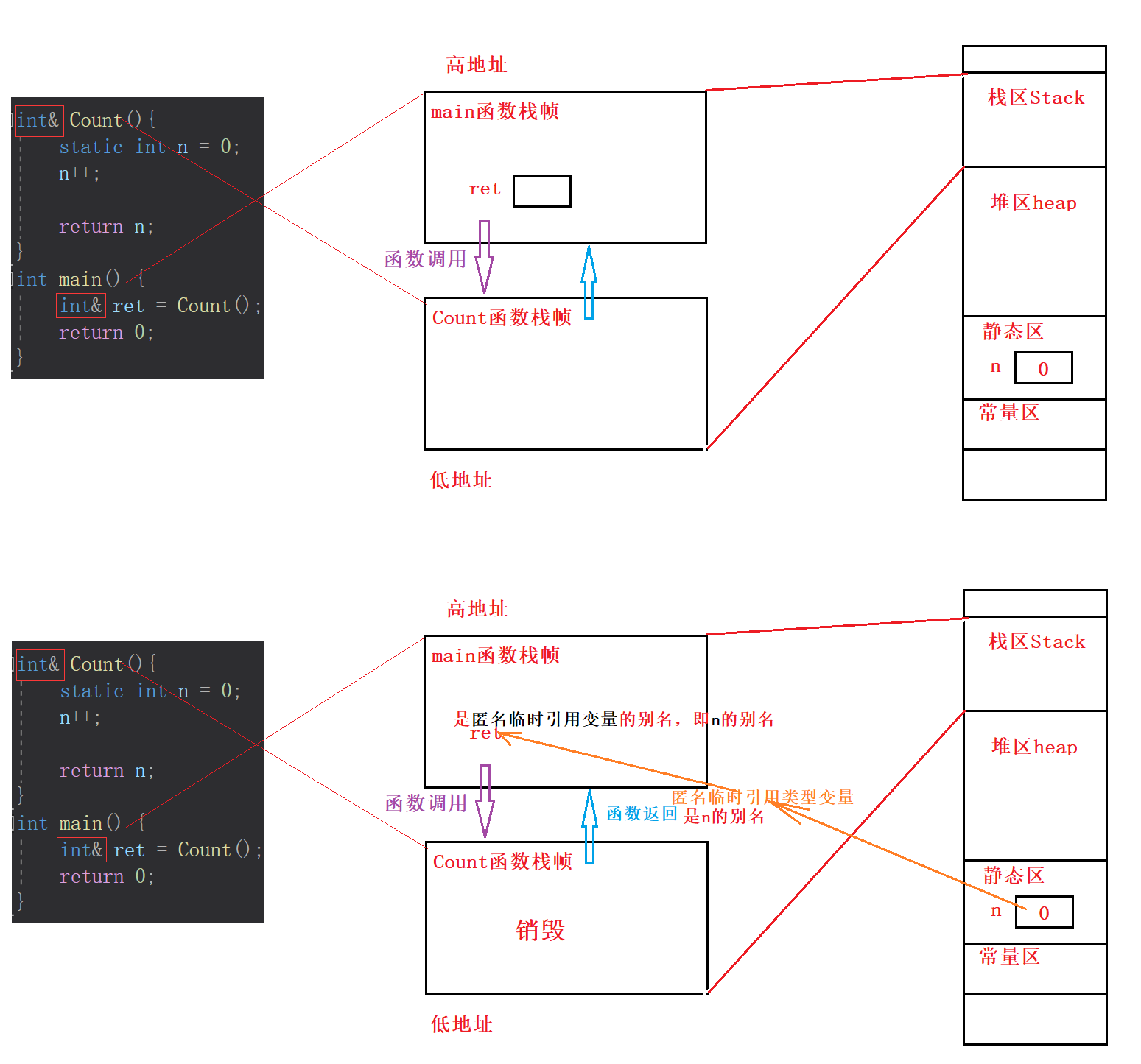
这里需要注意的主要是
函数Count栈帧销毁前,其返回的到底是什么。
可以认为是变量n创建了一个匿名临时引用变量,该匿名引用变量是变量n的引用,即n的别名,并作为真正的返回值返回到main函数栈帧里,main函数内部引用遍历ret接受,即ret是匿名临时变量的别名,而匿名临时变量又是变量n的别名,所以ret是变量n的别名。
再来看一个非引用返回的局部变量的例子:
#includeusing namespace std; int Count(){ int n = 0; n++; return n; } int main() { int ret = Count(); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
前面我们分析过了,
Count函数返回类型是int,返回的是变量n的拷贝(临时变量)。唯一不同的是,这次n是局部变量,不在静态区,在函数Count返回时随栈帧销毁而销毁了,但这是无所谓的,因为n的值已经安全返回了。一个不恰当的的引用使用:
#includeusing namespace std; int& Count(){ int n = 0; n++; return n; } int main() { int& ret = Count(); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
Count函数的返回类型是int&,是引用类型,返回的是变量n的别名(匿名临时引用变量)。唯一不同是,n是局部变量,不在静态区,在函数Count返回时随栈帧销毁而销毁了。
但是不要忘了,main函数内ret接收后就是变量n的别名了,改变ret就是改变n,也就是改变n所在空间的内容。可是,n此时(Count函数返回后)已经销毁了,但是ret却还能够访问到n销毁前所在的空间,进而修改或读取该空间的内容,这是非法访问内存了。
ret访问到的是什么也是未知的。
所以这是一个错误的例子,引用作为返回值但不能这么使用。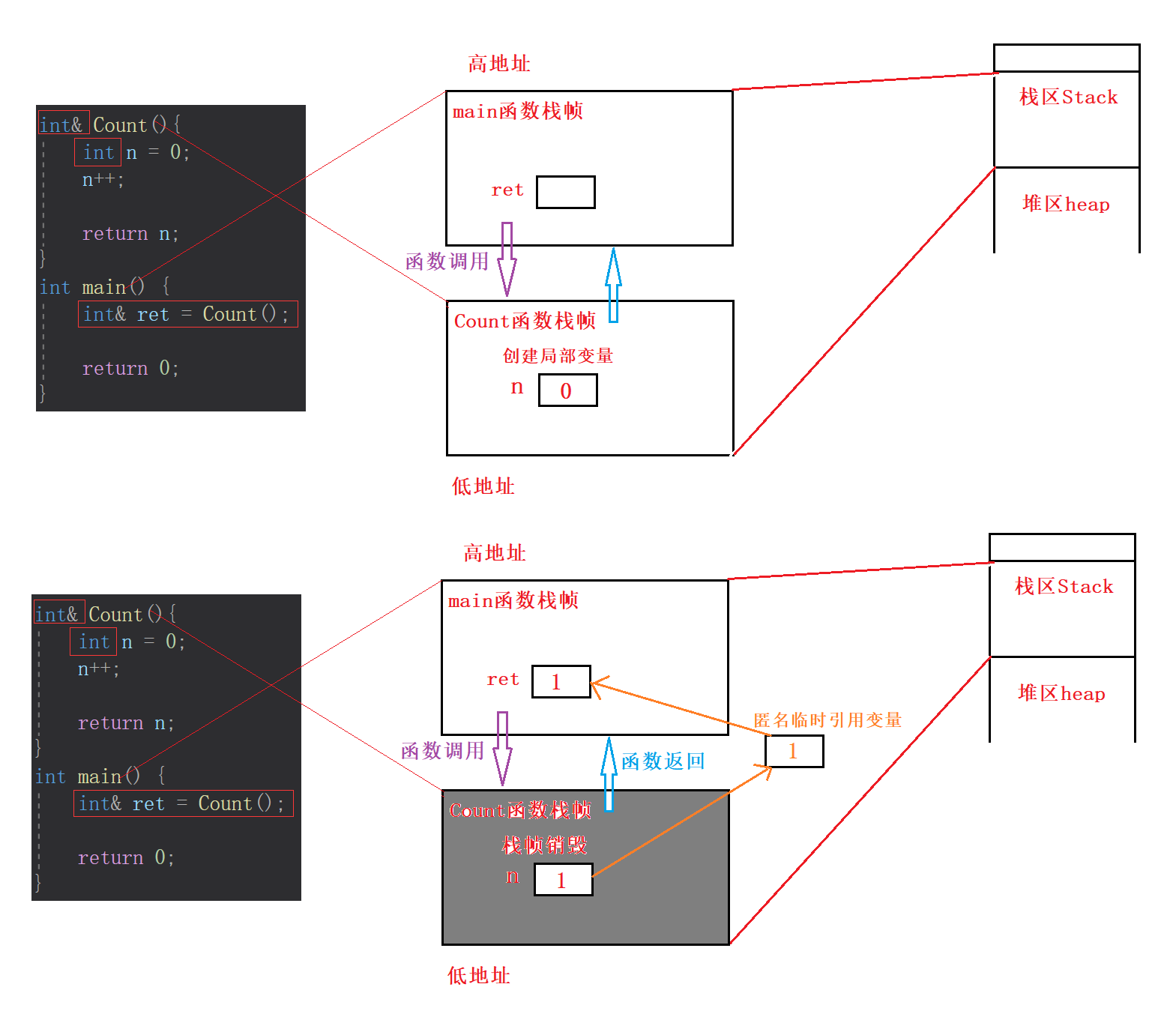
结论
出了函数作用域,返回变量不存在了
在栈区,则不能用引用返回,因为引用返回的结果是未定义的;
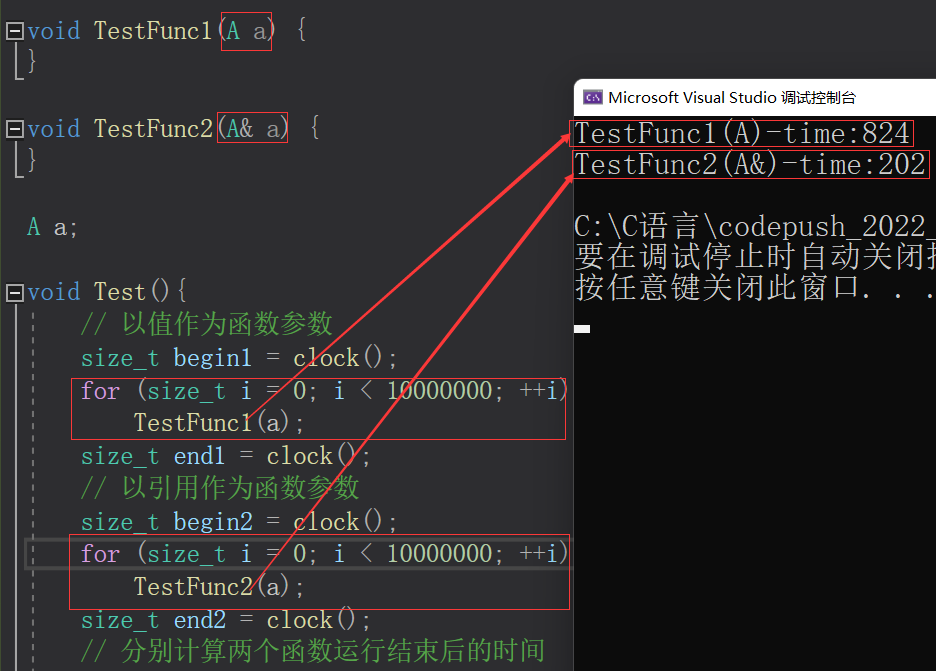
出了作用域,返回变量存在在堆区、静态区、常量区才能用引用返回。传值、传引用效率比较
以值作为参数或者返回值类型,在传参和返回期间,函数不会直接传递实参或者将变量本身直
接返回,而是传递实参或者返回变量的一份临时的拷贝,因此用值作为参数或者返回值类型,效
率较低,尤其是当参数或者返回值类型非常大时,效率就很低。#include#include using namespace std; #include struct A { int a[10000]; }; //传值 void TestFunc1(A a) { } //传引用 void TestFunc2(A& a) { } void Test(){ A a; // 以值作为函数参数 size_t begin1 = clock(); for (size_t i = 0; i < 1000000; ++i) TestFunc1(a); size_t end1 = clock(); // 以引用作为函数参数 size_t begin2 = clock(); for (size_t i = 0; i < 1000000; ++i) TestFunc2(a); size_t end2 = clock(); // 分别计算两个函数运行结束后的时间 cout << "TestFunc1(A)-time:" << end1 - begin1 << endl; cout << "TestFunc2(A&)-time:" << end2 - begin2 << endl; } int main() { Test(); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
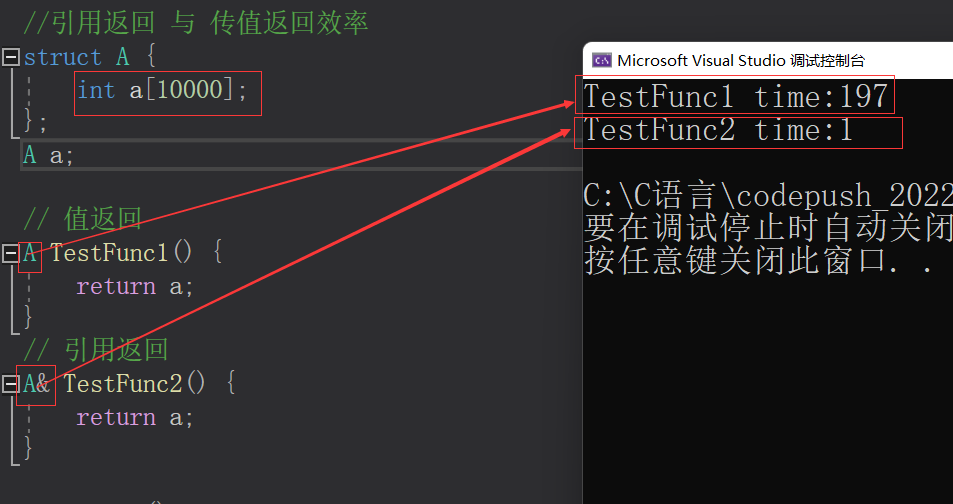
#include#include using namespace std; //引用返回 与 传值返回效率 struct A { int a[10000]; }; A a; // 值返回 A TestFunc1() { return a; } // 引用返回 A& TestFunc2() { return a; } void Test() { // 以值作为函数的返回值类型 size_t begin1 = clock(); for (size_t i = 0; i < 100000; ++i) TestFunc1(); size_t end1 = clock(); // 以引用作为函数的返回值类型 size_t begin2 = clock(); for (size_t i = 0; i < 100000; ++i) TestFunc2(); size_t end2 = clock(); // 计算两个函数运算完成之后的时间 cout << "TestFunc1 time:" << end1 - begin1 << endl; cout << "TestFunc2 time:" << end2 - begin2 << endl; } int main() { Test(); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
引用和指针的联系与区别
在语法概念上引用就是一个别名,没有独立空间,和其引用实体共用同一块空间。
**在底层实现上实际是有空间的,因为引用是按照指针方式来实现的。 **
见visual stdio 2019反汇编
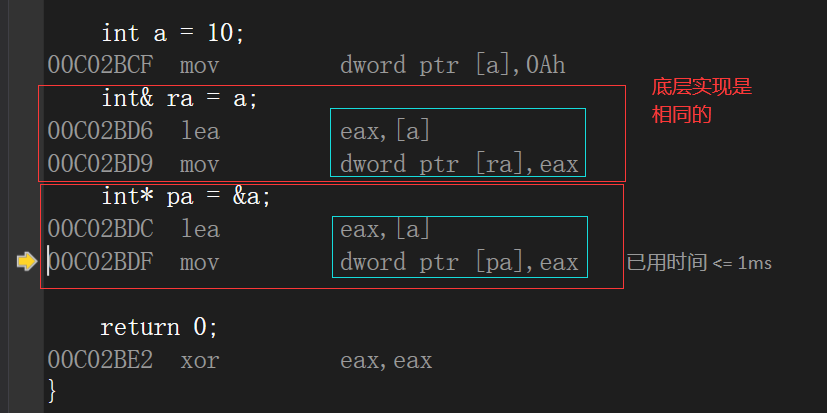
联系:- 引用的出现简化了很多使用指针导致复杂的情况,但是由于引用不能改变引用的对象,所以在C++中引用并不能够完全代替指针的地位。
- 有时引用和指针都能完成同一功能,二者得使用是交叉的。
- 存在指针的引用,但不存在引用的指针。因为指针是一个实体,而引用不是一个实体,没有对应的地址。
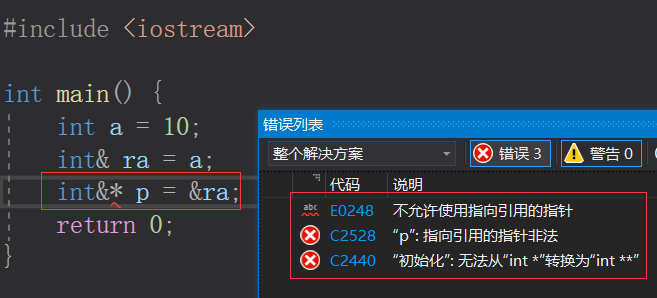
引用和指针的不同点:
1. 引用概念上定义一个变量的别名,指针存储一个变量地址;
2. 引用在定义时必须初始化,指针没有要求;
3. 引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何
一个同类型实体;
4. 没有NULL引用,但有NULL指针;
5. 在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32
位平台下占4个字节);
6. 引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小;
7. 有多级指针,但是没有多级引用;
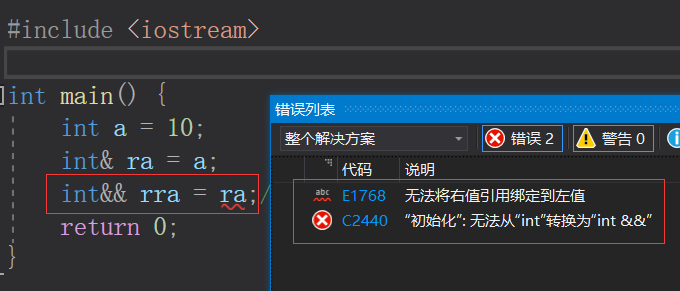
8. 访问实体方式不同,指针需要显式解引用,引用编译器自己处理;
9. 引用比指针使用起来相对更安全 。
常引用
是使用
const限定符修饰的引用,我们应该对const不会陌生,指针常量、常量指针、常变量等等我们都遇到过。一个变量
a,使用const限定符修饰后就成为了只读变量,权限从可读可写被限制。
需要注意a仍然可以参与许多运算,只要不改变a本身即可,否则程序会出错(编译错误)。这里涉及到读写访问权限的问题:
指针和引用在赋值中,权限可以缩小(如可读可写变只读),但是不能放大(如只读变可读可写)。
#includeusing namespcae std; int main() { //对于指针和引用:在赋值时需要考虑权限 //a定义为可读可写变量 int a = 0; //权限平移 - ra完全获得a的权限 int& ra = a; //权限缩小 - rra只获得a的读权限 const int& rra = a; //b定义为只读变量 const int b = 10; //权限放大,出错 - rb企图获得超过b本身的权限 //int& rb = b; //权限平移 - rrb获得读权限 const int& rrb = b; return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
作为函数参数
问题:
#includeusing namespace std; void function(int& x) { ; } int main() { //a定义为可读可写变量 int a = 0; int& ra = a; const int& rra = a; function(a);//true function(ra);//true function(rra);//error function(10);//error return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
可以看到
function引用参数x只能接收实参a和ra,不能接收rra和10。即x可以作为a和ra的引用,但是不能作为rra和10的引用。原因就是x是可读可写的,a和ra也是可读可写的,x权限没有放大。而rra和10是只读的,导致x是权限放大的,所以出错。改进:
#includeusing namespace std; void function(const int& x) { ; } int main() { //a定义为可读可写变量 int a = 0; int& ra = a; const int& rra = a; function(a);//true function(ra);//true function(rra);//true function(10);//true return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
x是只读的,a和ra是可读可写的,x权限没有放大。而rra和10也是只读的,x的权限也没有放大的,正确。
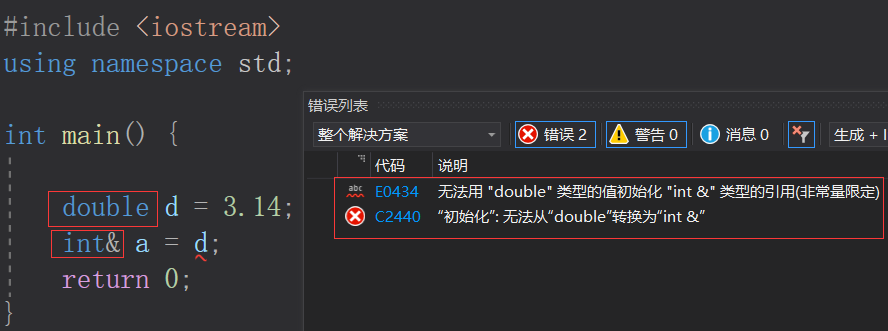
对引用不能引用不同类型变量的进一步探究
我们知道一种类型的引用不能引用另一种类型的变量。
double a = 3.14; double& ra = a;//true int& rra = a;//error- 1
- 2
- 3
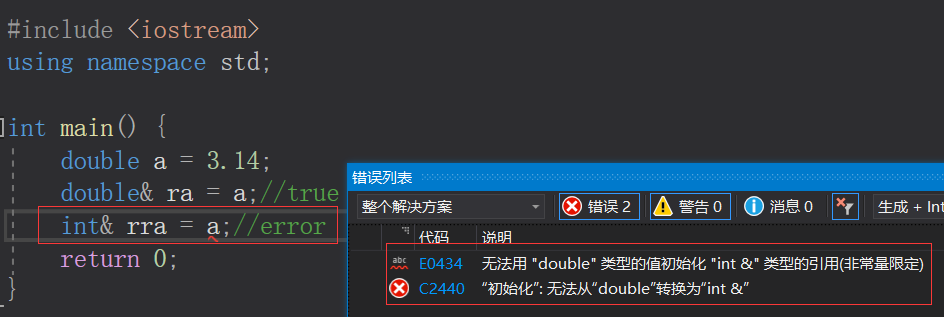
那么我们再来看看这种形式:double a = 3.14; const int& rra = a;//true- 1
- 2
为什么加上
const修饰后就不报错了呢?
接下来揭示原因:这里的代码实际上等价于
double a = 3.14; const int tmp = (int)a; const int& rra = tmp;- 1
- 2
- 3
在引用之前,实际上还有一步转换:浮点型变量
a先发生类型转换,转换为整型中间临时变量tmp(实际上是匿名的,这里假设了一个名字给匿名临时变量)。
整型常引用rra实际上是中间临时变量tmp的引用,而与浮点型a没有啥关系。看一看
a和rra的地址即可知道:
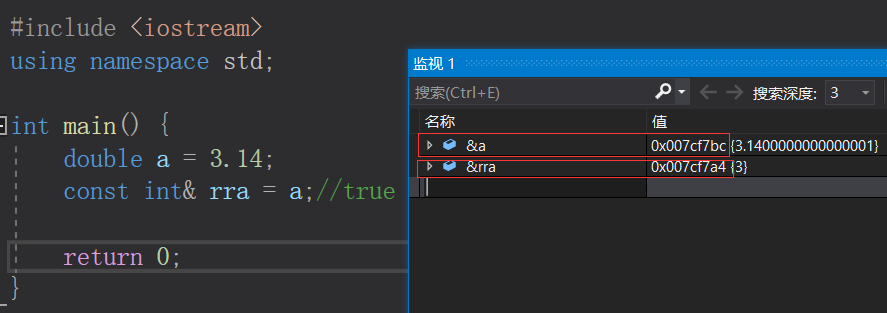
所以产生的中间变量是具有常性
const修饰的中间临时变量,这也解释了一般一种引用类型不能作为另一种变量的引用原因:引用的是中间变量,但该中间变量是const修饰的,是只读的,而一般的引用是可读可写的,导致了权限放大(从只读->可读可写),这是不允许的,所以出错。
类似的临时变量的产生也是非常常见的,只是我们可能没有注意:
比如说:隐式类型转换、强制类型转换、算数转换等都会产生中间临时变量,改变的并不是变量本身。
结语
本节主要介绍引用的概念和一些用法,并对引用的用途进行了比较详细的分析。下次再见!
E N D END END
-
相关阅读:
吐槽记~(这个帖子是我的垃圾桶)~哈哈
Aspect 切入点 @Pointcut 语法详解
哈夫曼树构建、编码、译码C++实现
Leetcode刷题笔记5
【iOS】—— 单例模式
武汉某母婴用品公司 - 集简云连接ERP和营销系统,实现库存管理的自动化
网络安全(黑客)自学
(a)Spring注解式开发,注册组件的@Repository,@Service,@Controller,@Component使用及说明
VSCode 配置C语言环境 全程记录 ,配置成功
FANUC机器人socket通讯硬件配置
- 原文地址:https://blog.csdn.net/weixin_64904163/article/details/127136346
