-
【斯坦福大学公开课CS224W——图机器学习】六、图神经网络1:GNN模型
【斯坦福大学公开课CS224W——图机器学习】六、图神经网络1:GNN模型
文章目录
- 【斯坦福大学公开课CS224W——图机器学习】六、图神经网络1:GNN模型
- 1. Deep Learning for Graphs
- 在这里插入图片描述](https://img-blog.csdnimg.cn/20210608213029130.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1BvbGFyaXNSaXNpbmdXYXI=,size_16,color_FFFFFF,t_70)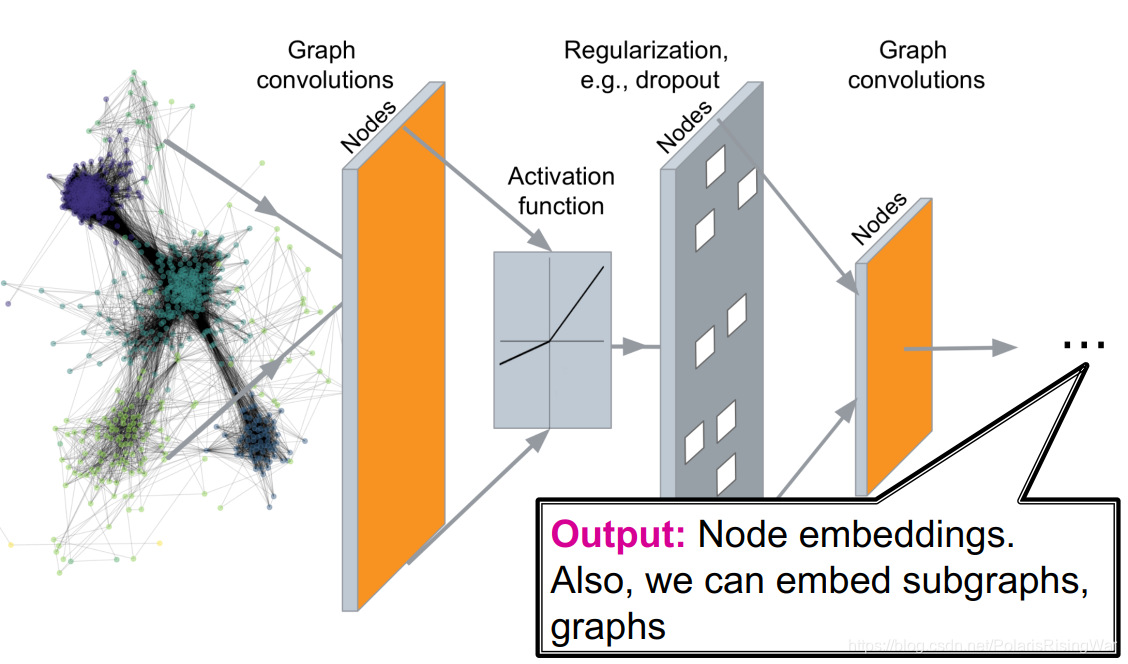
通过网络可以解决的任务有:
- 节点分类:预测节点的标签
- 链接预测:预测两点是否相连
- 社区发现:识别密集链接的节点簇
- 网络相似性:度量图/子图间的相似性
1. Deep Learning for Graphs
我们可能很直接地想到,将邻接矩阵和特征合并在一起应用在深度神经网络上(如图,直接一个节点的邻接矩阵+特征合起来作为一个观测)。这种方法的问题在于:
需要 O(|V|)的参数
不适用于不同大小的图
对节点顺序敏感(我们需要一个即使改变了节点顺序,结果也不会变的模型)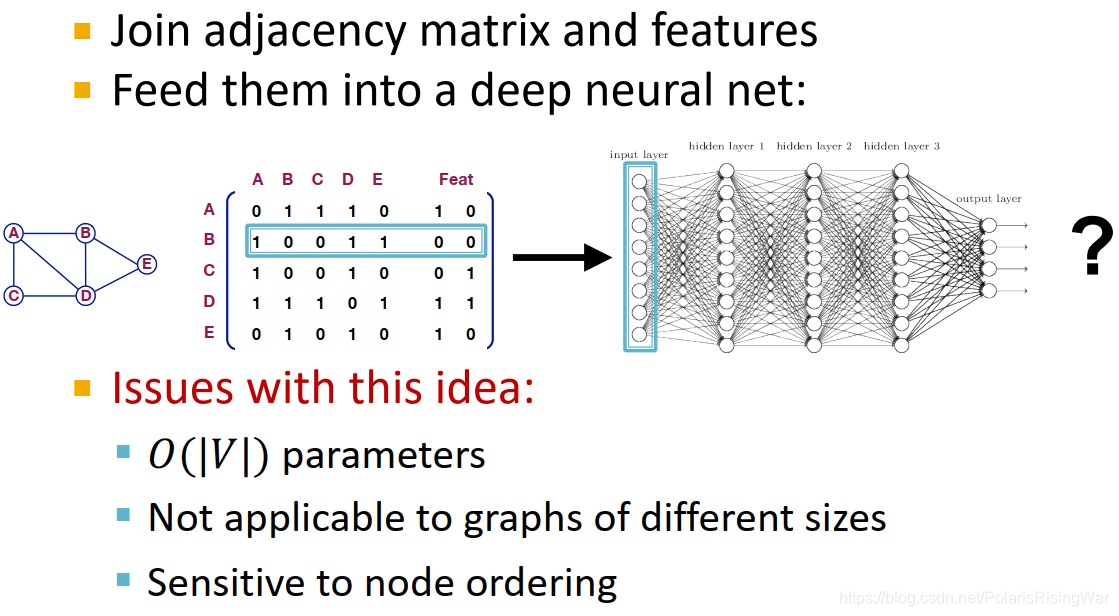
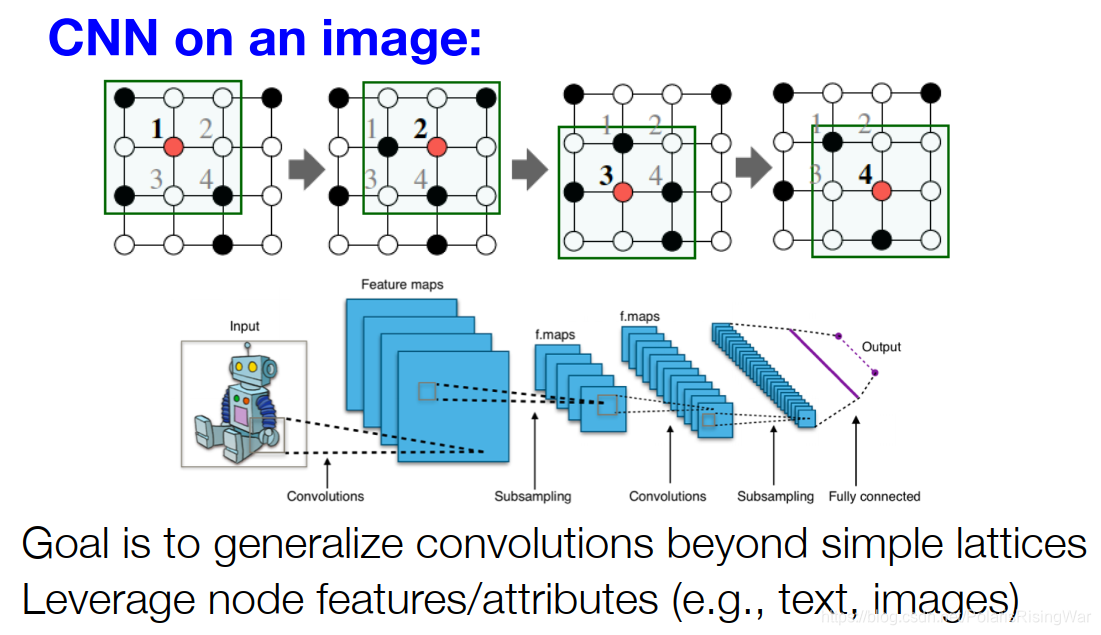
Idea: 将网格上的卷积神经网络泛化到图上,并应用到节点特征数据
1.1 Graph Convolutional Networks
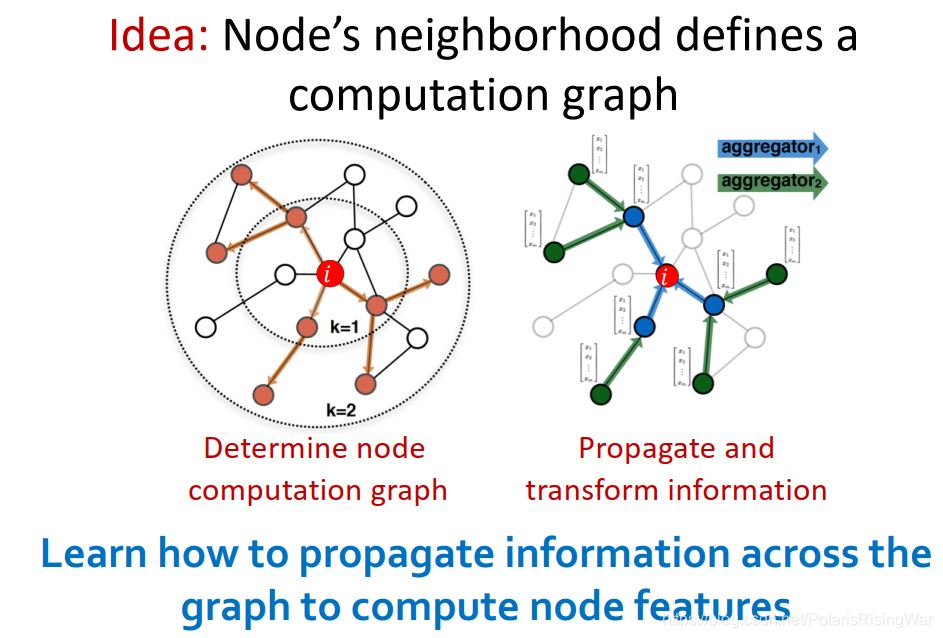
通过节点邻居定义其计算图,传播并转换信息,计算出节点表示(可以说是用邻居信息来表示一个节点)
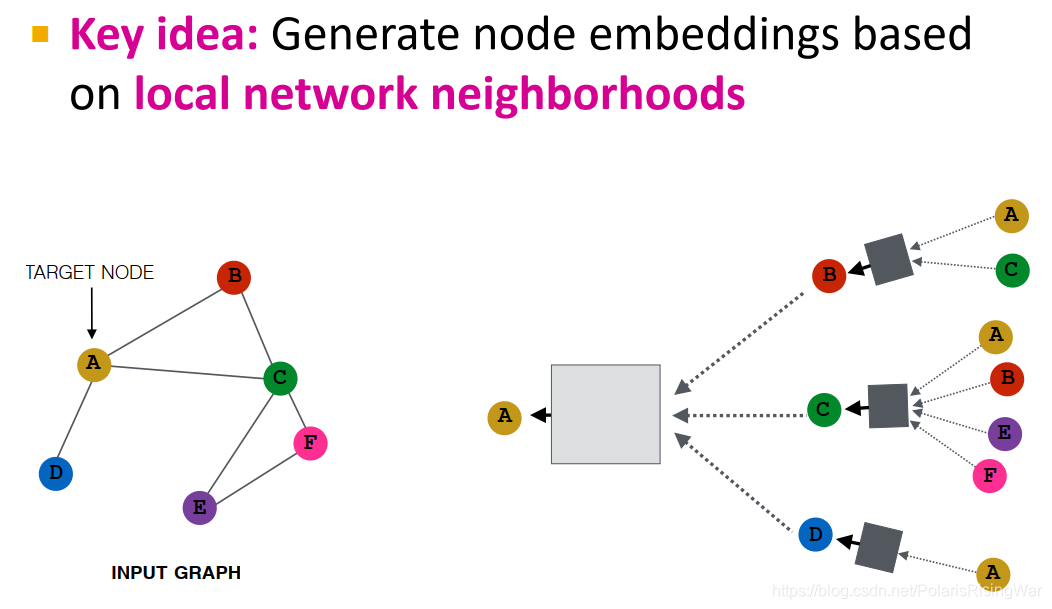
核心思想:通过聚合邻居来生成节点嵌入
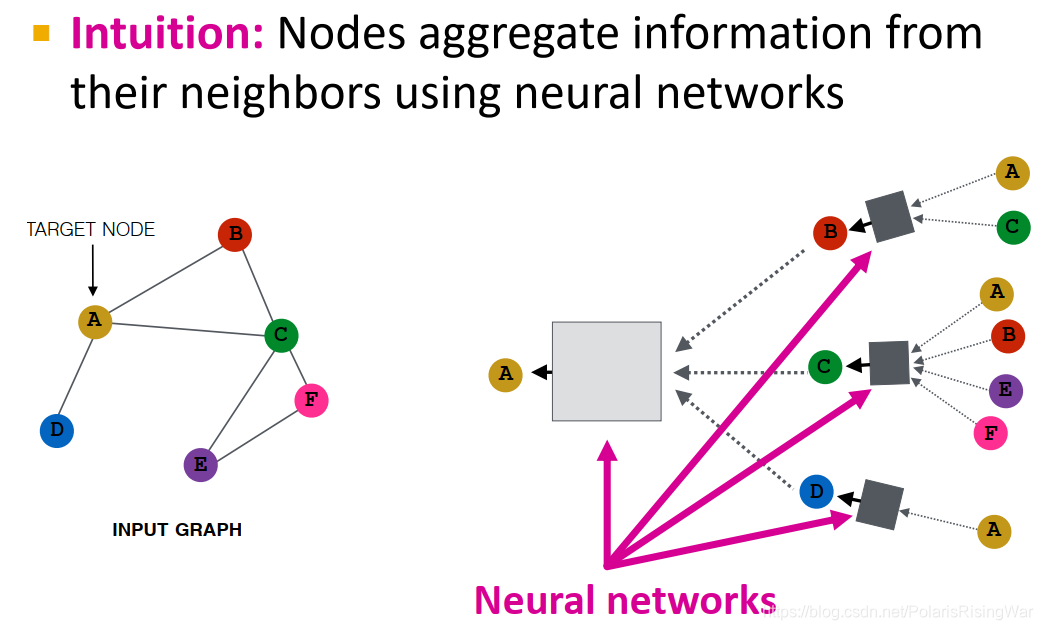
直觉:通过神经网络聚合邻居信息
直觉:通过节点邻居定义计算图(它的邻居是子节点,子节点的邻居又是子节点们的子节点……)
****
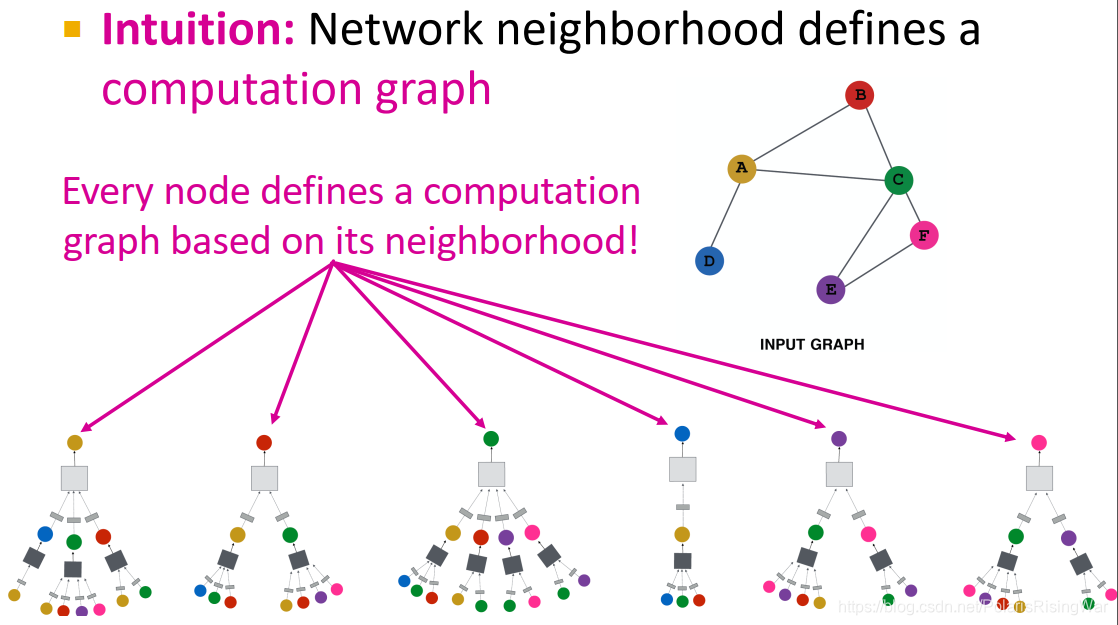
深度模型就是有很多层。
节点在每一层都有不同的表示向量,每一层节点嵌入是邻居上一层节点嵌入再加上它自己(相当于添加了自环)的聚合。
第0层是节点特征,第k层是节点通过聚合k hop邻居所形成的表示向量。
在这里就没有收敛的概念了,直接选择跑有限步(k)层邻居信息聚合neighborhood aggregation
neighborhood aggregation方法必须要order invariant或者说permutation invariant。
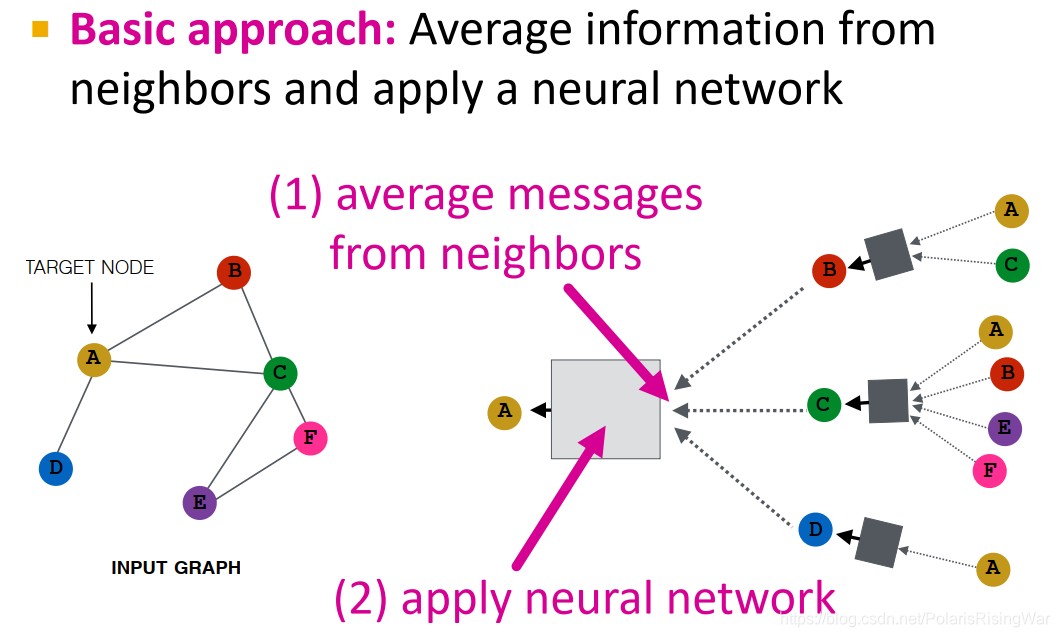
基础方法:从邻居获取信息求平均,再应用神经网络
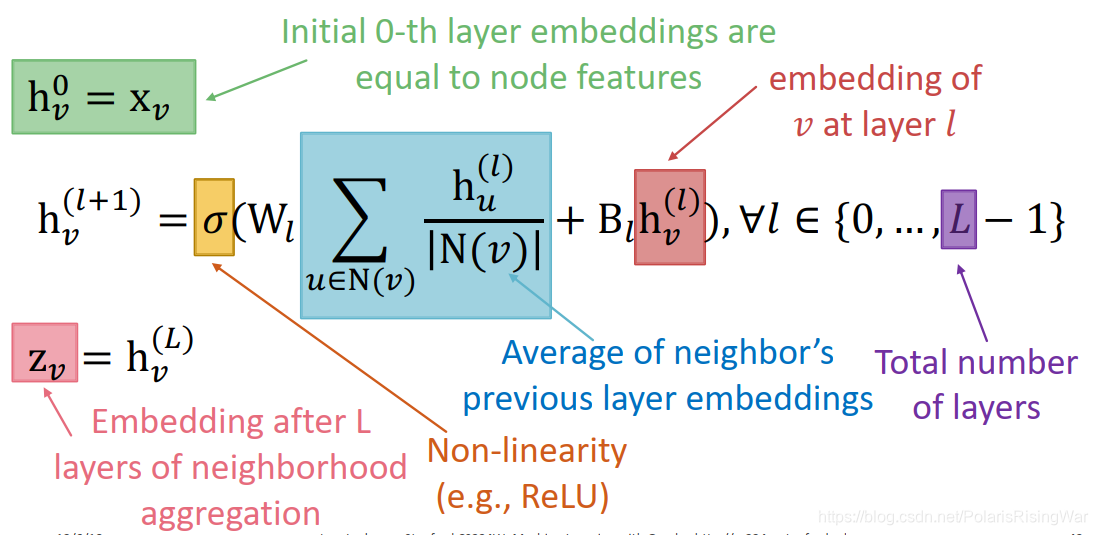
这种deep encoder的数学公式:
矩阵形式
很多种聚合方式都可以表示为(稀疏)矩阵操作的形式,如这个基础方法可以表示成图中这种形式:
1.2 如何训练GNN


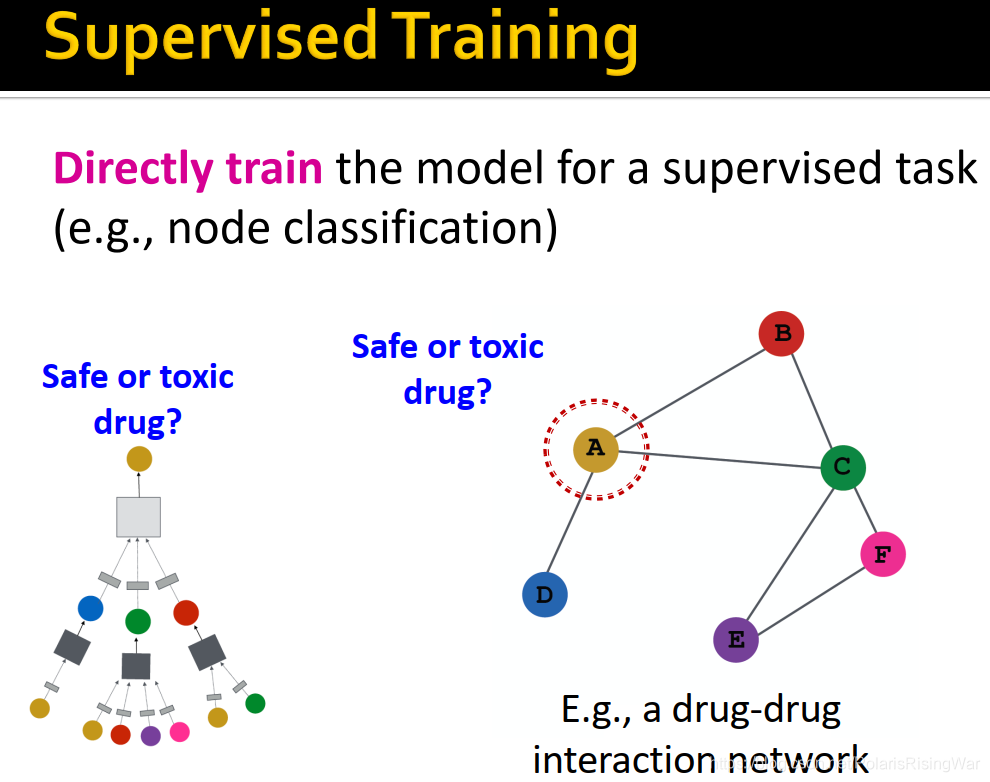
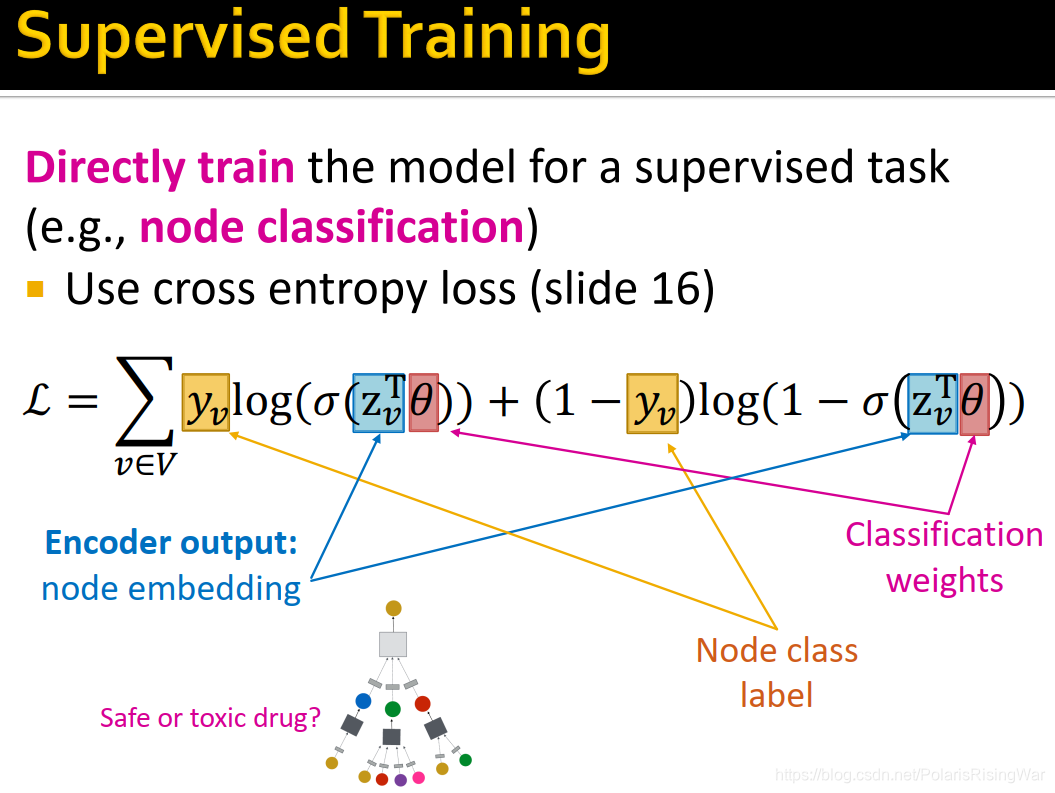
2. 模型设计
- 定义邻居聚合函数
- 定义节点嵌入上的损失函数
- 在节点集合(如计算图的batch)上做训练
- 训练后的模型可以应用在训练过与没有训练过的节点上
2.1 inductive capability
因为聚合邻居的参数在所有节点之间共享,所以训练好的模型可以应用在没见过的节点/图上。比如动态图就有新增节点的情况。
模型参数数量是亚线性sublinear于 |V|的(仅取决于嵌入维度和特征维度)(矩阵尺寸就是下一层嵌入维度×上一层嵌入维度,第0层嵌入维度就是特征维度嘛)3. Graph Convolutional Networks and GraphSAGE


GCN vs. GraphSAGE
核心思想:基于local neighborhoods产生节点嵌入,用神经网络聚合邻居信息
GCN:邻居信息求平均,叠网络层
GraphSAGE:泛化neighborhood aggregation所采用的函数 -
相关阅读:
奇思妙想构造题 ARC145 D - Non Arithmetic Progression Set
TCP/IP模型原理(理论)
django项目从本地迁移到linux服务器
LeetCode·每日一题·1455.检查单词是否为句中其他单词的前缀·模拟
SSL加速是什么,有什么优势?
源码构建LAMP环境-1
golang学习笔记——select 判断语句
JS 数据结构:队列
Banana Pi BPI-W3 RK3588开发板基本使用文档
web容器之NGINX
- 原文地址:https://blog.csdn.net/qq_45955883/article/details/127135419