-
VL (Vision and Language) 任务简介及数据集
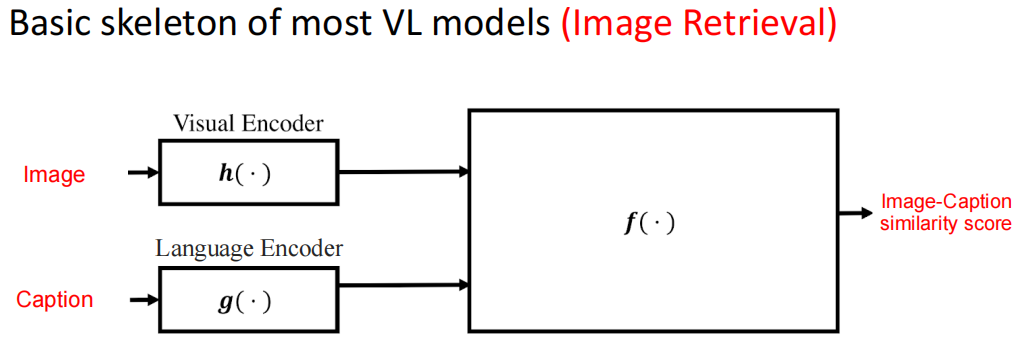
Image Retrieval(图像检索)

基本模型结构:
Grounding Referring Expression(在图像中找到自然语言对应描述的物体)

基本模型结构:
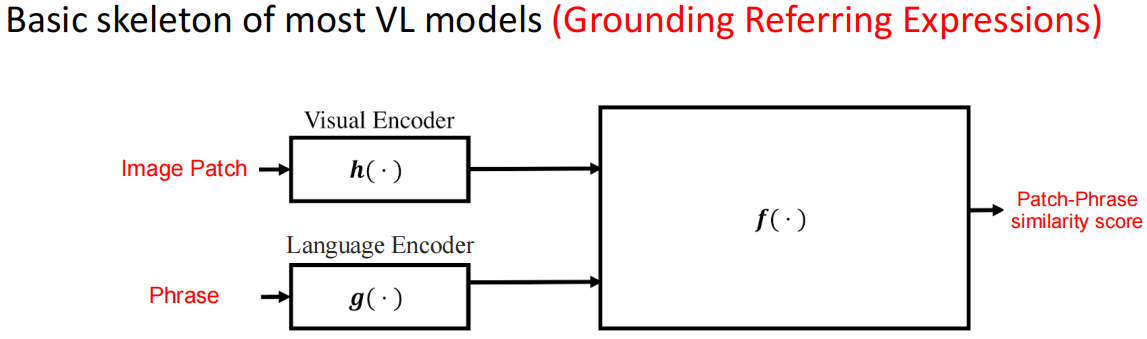
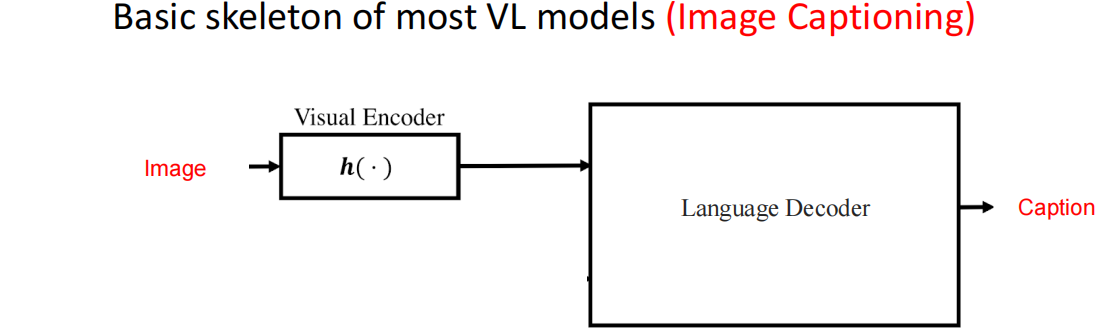
Image Captioning(图像描述)

基本模型结构:
数据集: COCO
Visual Question Answering(VQA,视觉问答)

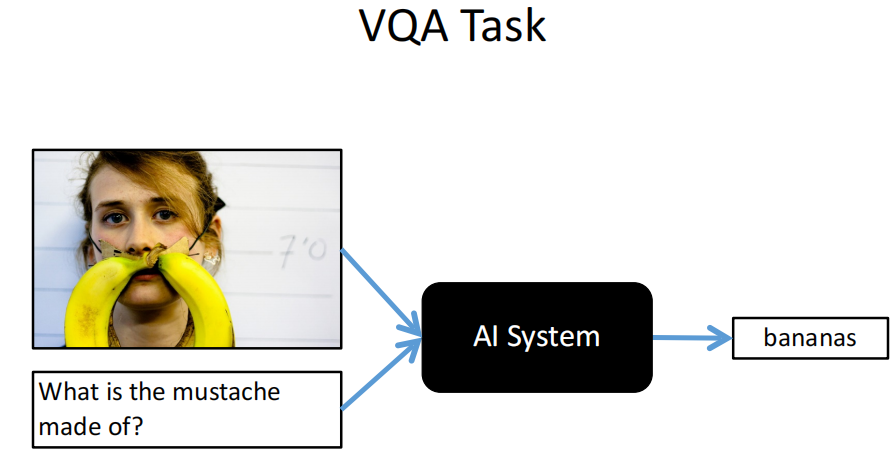
基本模型结构:
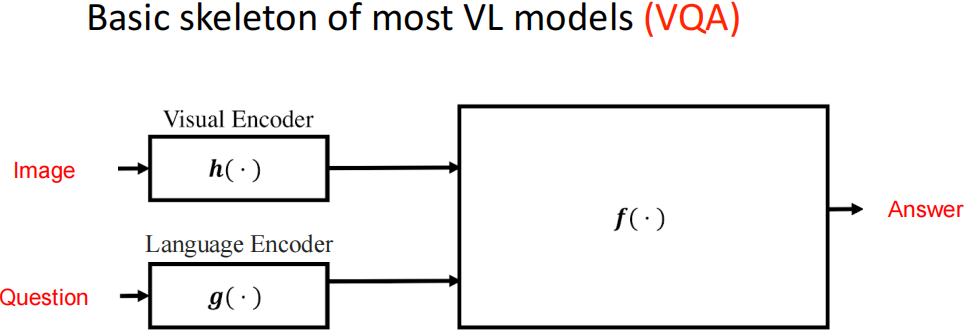
两通道 VQA 模型:

数据集: VQA v1, VQA v2, Visual Genome, GQA
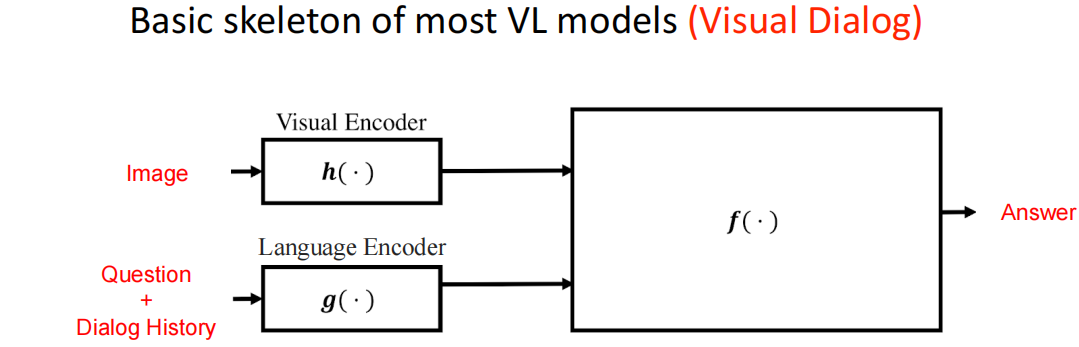
Visual Dialog(VD,视觉对话)


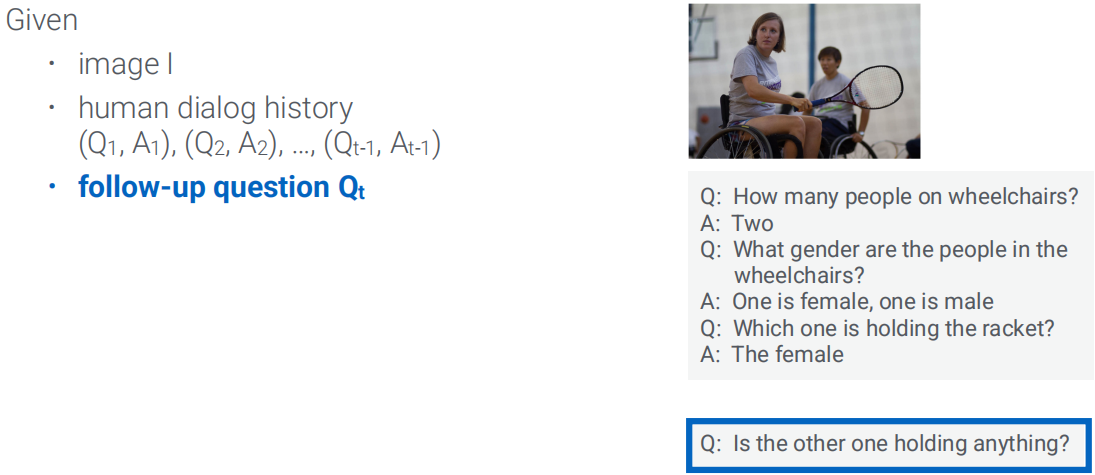

基本模型结构:
数据集: Visual Dialog, GuessWhat?!
demo
ViLBERT: https://vilbert.cloudcv.org/
本文参考于 ACL 2022 tutorial:Vision-Language Pretraining: Current Trends and the Future
-
相关阅读:
JavaScript 之数组的方法使用
基于《环境影响评价技术导则生态影响》(HJ 19—2022)下的生态环境影响评价技术方法及图件制作与案例
如何封禁大量恶意IP?
贪心:区间问题
Haul truck运输卡车专为矿用设计
STA series --- 8.Timing Verification (PARTI)
React 15~18每个阶段更新了什么
10年测试经验,在35岁的生理年龄面前,一文不值
加密的手机号,如何模糊查询?
场景案例│数字员工在物流行业的落地应用
- 原文地址:https://blog.csdn.net/Friedrichor/article/details/127126679