-
GC(垃圾回收)
- 常见的垃圾回收算法有标记清除(Mark-Sweep) 和引用计数(Reference Count)
- Python采用的是引用计数+标记清除并扩展了分代回收。
- Go 语言采用的是标记清除算法,并在此基础上使用了三色标记法和写屏障技术。
什么是 GC,有什么作用?
- GC ,全称 Garbage Collection ,即垃圾回收,是一种自动内存管理的机制。
- 当程序向操作系统申请的内存不再需要时,垃圾回收主动将其回收并供其他代码进行内存申请时候复用,或者将其归还给操作系统,这种针对内存级别资源的自动回收过程,即为垃圾回收。而负责垃圾回收的程序组件,即为垃圾回收器。
- 一方面,程序员受益于 GC,无需操心、也不再需要对内存进行手动的申请和释放操作,GC 在程序运行时自动释放残留的内存。另一方面,GC 对程序员几乎不可见,仅在程序需要进行特殊优化时,通过提供可调控的 API,对 GC 的运行时机、运行开销进行把控的时候才得以现身。
- 通常,垃圾回收器的执行过程被划分为两个半独立的组件:
- 赋值器(Mutator):这一名称本质上是在指代用户态的代码。因为对垃圾回收器而言,用户态的代码仅仅只是在修改对象之间的引用关系,也就是在对象图(对象之间引用关系的一个有向图)上进行操作。
- 回收器(Collector):负责执行垃圾回收的代码。
根对象到底是什么?
根对象在垃圾回收的术语中又叫做根集合,它是垃圾回收器在标记过程时最先检查的对象,包括:
- 全局变量:程序在编译期就能确定的那些存在于程序整个生命周期的变量。
- 执行栈:每个 goroutine 都包含自己的执行栈,这些执行栈上包含栈上的变量及指向分配的堆内存区块的指针。
- 寄存器:寄存器的值可能表示一个指针,参与计算的这些指针可能指向某些赋值器分配的堆内存区块。
常见的 GC 实现方式有哪些?Go 语言的 GC 使用的是什么?
所有的 GC 算法其存在形式可以归结为追踪(Tracing)和引用计数(Reference Counting)这两种形式的混合运用。
- 追踪式 GC
从根对象出发,根据对象之间的引用信息,一步步推进直到扫描完毕整个堆并确定需要保留的对象,从而回收所有可回收的对象。Go、 Java、V8 对 JavaScript 的实现等均为追踪式 GC。 - 引用计数式 GC
每个对象自身包含一个被引用的计数器,当计数器归零时自动得到回收。因为此方法缺陷较多,在追求高性能时通常不被应用。Python、Objective-C 等均为引用计数式 GC。
目前比较常见的 GC 实现方式包括:
- 追踪式,分为多种不同类型,例如:
- 标记清扫:从根对象出发,将确定存活的对象进行标记,并清扫可以回收的对象。
- 标记整理:为了解决内存碎片问题而提出,在标记过程中,将对象尽可能整理到一块连续的内存上。
- 增量式:将标记与清扫的过程分批执行,每次执行很小的部分,从而增量的推进垃圾回收,达到近似实时、几乎无停顿的目的。
- 增量整理:在增量式的基础上,增加对对象的整理过程。
- 分代式:将对象根据存活时间的长短进行分类,存活时间小于某个值的为年轻代,存活时间大于某个值的为老年代,永远不会参与回收的对象为永久代。并根据分代假设(如果一个对象存活时间不长则倾向于被回收,如果一个对象已经存活很长时间则倾向于存活更长时间)对对象进行回收。
- 引用计数:根据对象自身的引用计数来回收,当引用计数归零时立即回收。
对于 Go 而言,Go 的 GC 目前使用的是无分代(对象没有代际之分)、不整理(回收过程中不对对象进行移动与整理)、并发(与用户代码并发执行)的三色标记清扫算法。原因[1]在于:
-
对象整理的优势是解决内存碎片问题以及“允许”使用顺序内存分配器。但 Go 运行时的分配算法基于 tcmalloc,基本上没有碎片问题。 并且顺序内存分配器在多线程的场景下并不适用。Go 使用的是基于 tcmalloc 的现代内存分配算法,对对象进行整理不会带来实质性的性能提升。
-
分代 GC 依赖分代假设,即 GC 将主要的回收目标放在新创建的对象上(存活时间短,更倾向于被回收),而非频繁检查所有对象。但 Go 的编译器会通过逃逸分析将大部分新生对象存储在栈上(栈直接被回收),只有那些需要长期存在的对象才会被分配到需要进行垃圾回收的堆中。也就是说,分代 GC 回收的那些存活时间短的对象在 Go 中是直接被分配到栈上,当 goroutine 死亡后栈也会被直接回收,不需要 GC 的参与,进而分代假设并没有带来直接优势。并且 Go 的垃圾回收器与用户代码并发执行,使得 STW 的时间与对象的代际、对象的 size 没有关系。Go 团队更关注于如何更好地让 GC与用户代码并发执行(使用适当的 CPU 来执行垃圾回收),而非减少停顿时间这一单一目标上。
Python(引用计数,标记清楚,分代回收)
2个结构体
- PyObject,此结构体中包含3个元素。
- _PyObject_HEAD_EXTRA,用于构造双向链表。
- ob_refcnt,引用计数器。
- *ob_type,数据类型。
- PyVarObject,次结构体中包含4个元素(ob_base中包含3个元素)
- ob_base,PyObject结构体对象,即:包含PyObject结构体中的三个元素。
- ob_size,内部元素个数。
3个宏定义
- PyObject_HEAD,代指PyObject结构体。
- PyVarObject_HEAD,代指PyVarObject对象。
- _PyObject_HEAD_EXTRA,代指前后指针,用于构造双向队列。
Python中所有类型创建对象时,底层都是与PyObject和PyVarObject结构体实现,一般情况下由单个元素组成对象内部会使用PyObject结构体(float)、由多个元素组成的对象内部会使用PyVarObject结构体(str/int/list/dict/tuple/set/自定义类),因为由多个元素组成的话是需要为其维护一个 ob_size(内部元素个数)。
对于Float对象
- float对象在创建对象时会把为其开辟内存并初始化引用计数器为1,然后将其加入到名为 refchain 的双向链表中;
- float对象在增加引用时,会执行 Py_INCREF在内部会让引用计数器+1;
- 最后执行销毁float对象时,会先判断float内部free_list中缓存的个数,如果已达到300个,则直接在内存中销毁,否则不会真正销毁而是加入free_list单链表中,以后后续对象使用,销毁动作的最后再在refchain中移除即可。
引用计数器
每个对象内部都维护了一个值,该值记录这此对象被引用的次数,如果次数为0,则Python垃圾回收机制会自动清除此对象。
import sys name = "Generalzy" print(sys.getrefcount(name)) ref_name = name print(sys.getrefcount(name)) del ref_name print(sys.getrefcount(name))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

def getrefcount(): # real signature unknown; restored from __doc__ """ Return the reference count of object. The count returned is generally one higher than you might expect, because it includes the (temporary) reference as an argument to getrefcount(). """ pass- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
循环引用问题
import gc import objgraph class Foo(object): def __init__(self): self.data = None # 在内存创建两个对象,即:引用计数器值都是1 obj1 = Foo() obj2 = Foo() # 两个对象循环引用,导致内存中对象的应用+1,即:引用计数器值都是2 obj1.data = obj2 obj2.data = obj1 # 删除变量,并将引用计数器-1。 del obj1 del obj2 # 关闭垃圾回收机制,因为python的垃圾回收机制是:引用计数器、标记清除、分代回收 配合已解决循环引用的问题,关闭他便于之后查询内存中未被释放对象。 gc.disable() # 至此,由于循环引用导致内存中创建的obj1和obj2两个对象引用计数器不为0,无法被垃圾回收机制回收。 # 所以,内存中Foo类的对象就还显示有2个。 print(objgraph.count('Foo'))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27

为了解决循环引用的问题,Python又在引用计数器的基础上引入了标记清除和分代回收的机制。标记清除&分代回收
Python为了解决循环引用,针对 lists, tuples, instances, classes, dictionaries, and functions 类型,每创建一个对象都会将对象放到一个双向链表中,每个对象中都有 _ob_next 和 _ob_prev 指针,用于挂靠到链表中。
/* Nothing is actually declared to be a PyObject, but every pointer to * a Python object can be cast to a PyObject*. This is inheritance built * by hand. Similarly every pointer to a variable-size Python object can, * in addition, be cast to PyVarObject*. */ typedef struct _object { _PyObject_HEAD_EXTRA # 双向链表 Py_ssize_t ob_refcnt; struct _typeobject *ob_type; } PyObject; typedef struct { PyObject ob_base; Py_ssize_t ob_size; /* Number of items in variable part */ } PyVarObject; /* Define pointers to support a doubly-linked list of all live heap objects. */ #define _PyObject_HEAD_EXTRA \ struct _object *_ob_next; \ struct _object *_ob_prev;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
随着对象的创建,该双向链表上的对象会越来越多。
-
当对象个数超过 700个 时,Python解释器就会进行垃圾回收。
-
当代码中主动执行 gc.collect() 命令时,Python解释器就会进行垃圾回收。
import gc gc.collect()- 1
- 2
-
Python解释器在垃圾回收时,会遍历链表中的每个对象,如果存在循环引用,就将存在循环引用的对象的引用计数器 -1,同时Python解释器也会将计数器等于0(可回收)和不等于0(不可回收)的一分为二,把计数器等于0的所有对象进行回收,把计数器不为0的对象放到另外一个双向链表表(即:分代回收的下一代)。GC
# 默认情况下三个阈值为 (700,10,10) ,也可以主动去修改默认阈值。 import gc gc.set_threshold(threshold0[, threshold1[, threshold2]])- 1
- 2
- 3
go(三色标记法)
三色标记法是什么?
- 三色抽象只是一种描述追踪式回收器的方法,在实践中并没有实际含义,它的重要作用在于从逻辑上严密推导标记清理这种垃圾回收方法的正确性。
- 谈及三色标记法时,通常指标记清扫的垃圾回收。
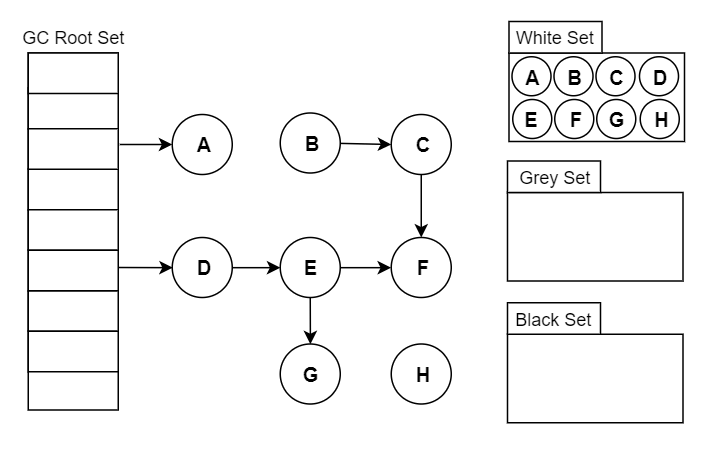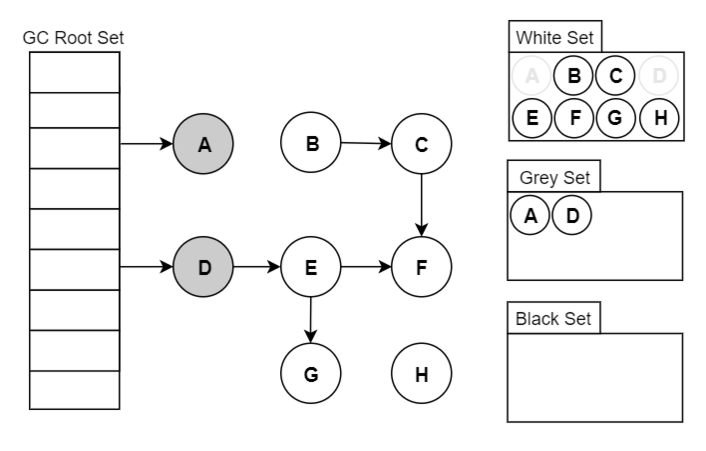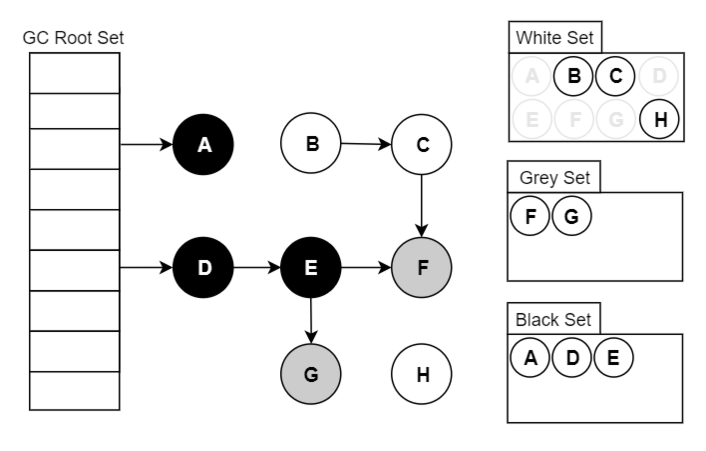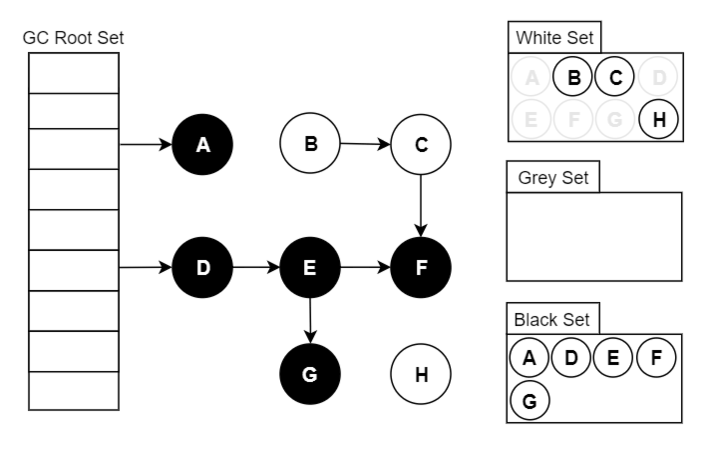
当垃圾回收开始时,只有白色对象。随着标记过程开始进行时,灰色对象开始出现(着色),这时候波面便开始扩大。当一个对象的所有子节点均完成扫描时,会被着色为黑色。当整个堆遍历完成时,只剩下黑色和白色对象,这时的黑色对象为可达对象,即存活;而白色对象为不可达对象,即死亡。这个过程可以视为以灰色对象为波面,将黑色对象和白色对象分离,使波面不断向前推进,直到所有可达的灰色对象都变为黑色对象为止的过程。如下图所示:
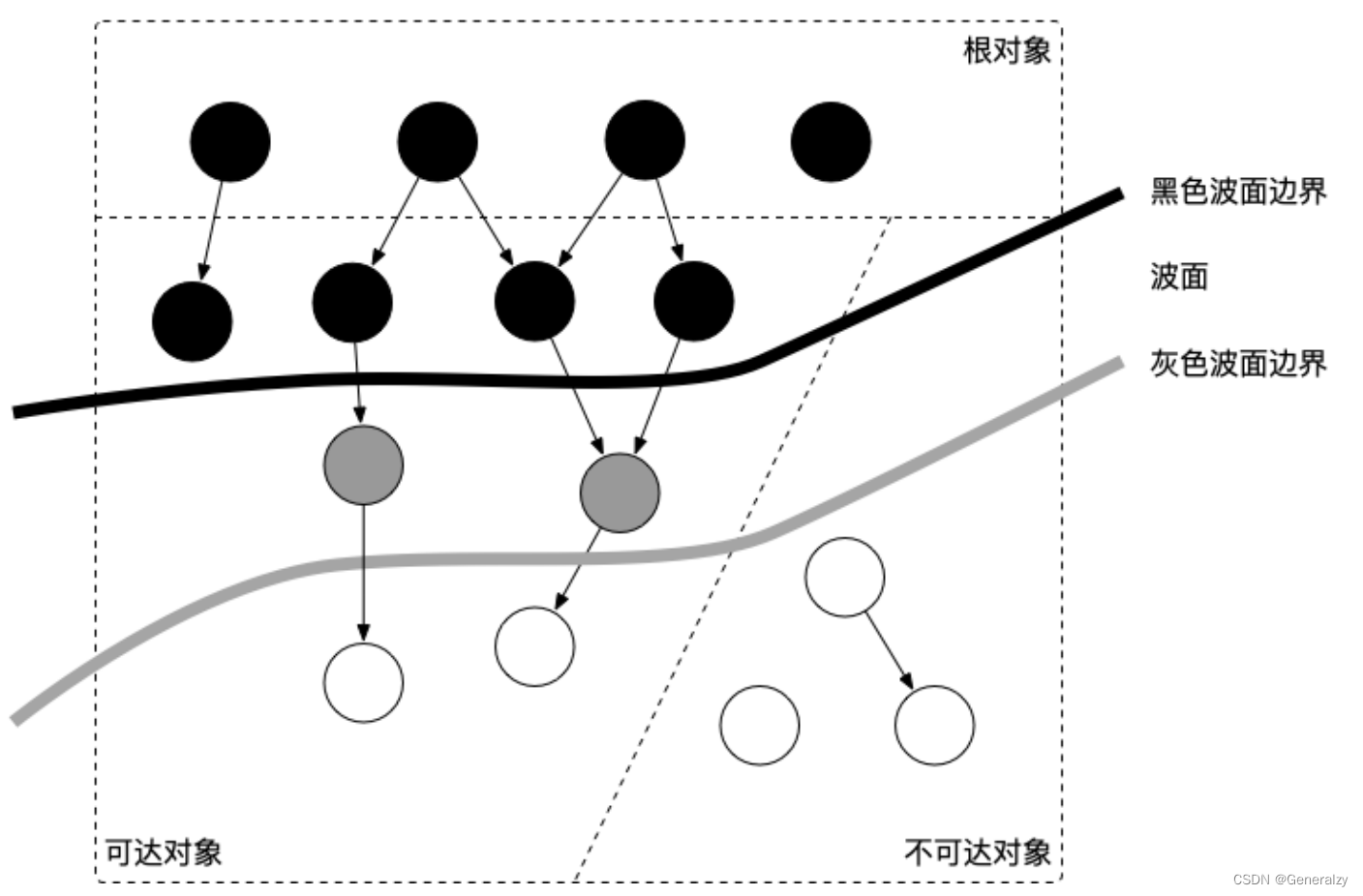
三色标记算法将程序中的对象分成白色、黑色和灰色三类。
白色:不确定对象。
灰色:存活对象,子对象待处理。
黑色:存活对象。- 标记开始时,所有对象加入白色集合(这一步需 STW )。
- 首先将根对象标记为灰色,加入灰色集合
- 垃圾搜集器取出一个灰色对象,将其标记为黑色,并将其指向的对象标记为灰色,加入灰色集合。
- 重复这个过程,直到灰色集合为空为止,标记阶段结束。
- 白色对象即可清理的对象,而黑色对象均为根可达的对象,不能被清理。
三色标记法因为多了一个白色的状态来存放不确定对象,所以后续的标记阶段可以并发地执行。当然并发执行的代价是可能会造成一些遗漏,因为那些早先被标记为黑色的对象可能目前已经是不可达的了。所以三色标记法是一个 false negative(假阴性)的算法。
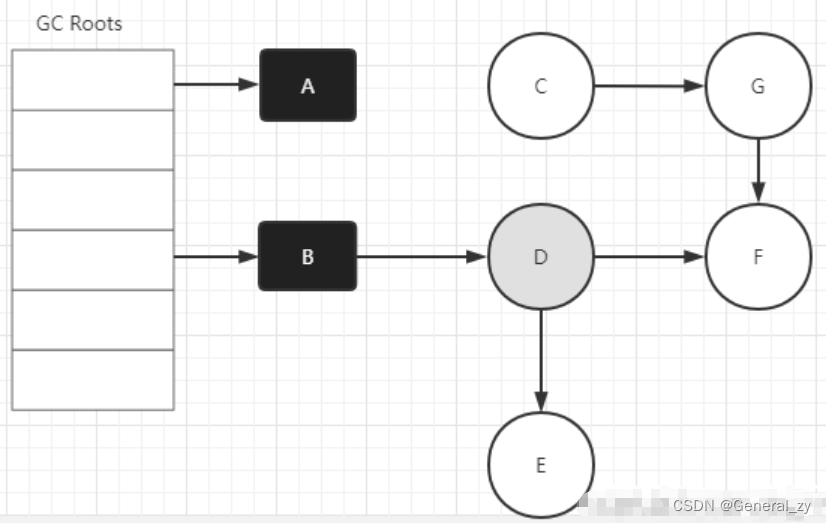
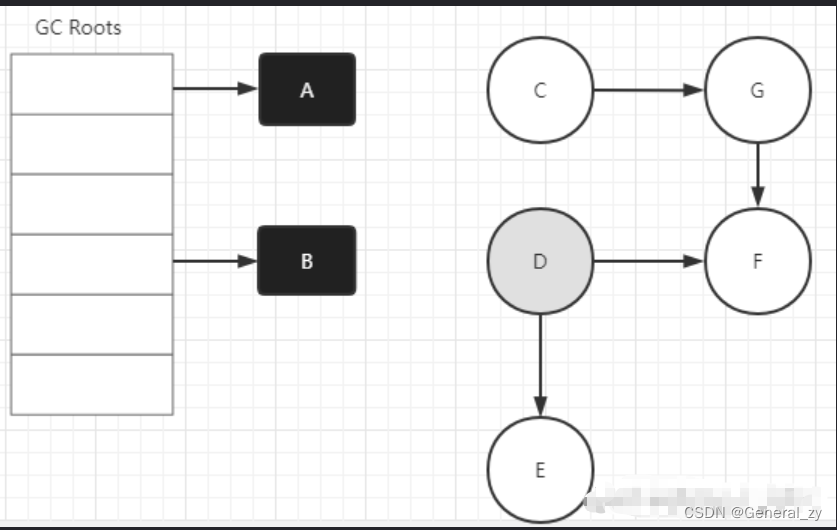
B->D的引用没了,D应该是白色,但是因为先前D已经被标记成灰色了,所以D对象仍然会被当成存活对象遍历下去。最终结果:这部分对象仍然会被标记为存活对象,本轮GC不会回收他们的内存。这部分因为并发而造成的本应该回收但是没有回收的对象被称为"浮动垃圾",浮动垃圾不会影响应用程序的正确性,只需要等到下一轮GC到来就会被回收了。
STW 是什么意思?
- STW 可以是 Stop the World 的缩写,也可以是 Start the World 的缩写。通常意义上指指代从 Stop
the World 这一动作发生时到 Start the World 这一动作发生时这一段时间间隔,即万物静止。STW 在垃圾回收过程中为了保证实现的正确性、防止无止境的内存增长等问题而不可避免的需要停止赋值器进一步操作对象图的一段过程。 - 在这个过程中整个用户代码被停止或者放缓执行, STW 越长,对用户代码造成的影响(例如延迟)就越大,早期 Go 对垃圾回收器的实现中 STW 长达几百毫秒,对时间敏感的实时通信等应用程序会造成巨大的影响。
package main import ( "runtime" "time" ) func main() { go func() { for { } }() time.Sleep(time.Millisecond) runtime.GC() println("OK") }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
上面的这个程序在 Go 1.14 以前永远都不会输出 OK ,其罪魁祸首是进入 STW 这一操作的执行无限制的被延长。
原因:
- GC 在需要进入 STW 时,需要通知并让所有的用户态代码停止,但是 for {} 所在的 goroutine 永远都不会被中断,从而始终无法进入 STW 阶段。当程序的某个 goroutine 长时间得不到停止,强行拖慢进入 STW 的时机,这种情况下造成的影响就是卡死。
- 在自 Go 1.14 之后,这类 goroutine 能够被异步地抢占,从而使得进入 STW 的时间不会超过抢占信号触发的周期,程序也不会因为仅仅等待一个 goroutine 的停止而停顿在进入 STW 之前的操作上。
有了 GC,为什么还会发生内存泄露?
常说的内存泄漏,用严谨的话来说应该是:预期的能很快被释放的内存由于附着在了长期存活的内存上、或生命期意外地被延长,导致预计能够立即回收的内存而长时间得不到回收。
在 Go 中,由于 goroutine 的存在,所谓的内存泄漏除了附着在长期对象上之外,还存在多种不同的形式。
预期能被快速释放的内存因被根对象引用而没有得到迅速释放
当有一个全局对象时,可能不经意间将某个变量附着在其上,且忽略的将其进行释放,则该内存永远不会得到释放。例如:
var cache = map[interface{}]interface{}{} func keepalloc() { for i := 0; i < 10000; i++ { m := make([]byte, 1<<10) cache[i] = m } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
package main import ( "os" "runtime/trace" ) func main() { f, _ := os.Create("trace.out") defer f.Close() trace.Start(f) defer trace.Stop() keepalloc() }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
对生成的out文件执行
go tool trace trace.out,
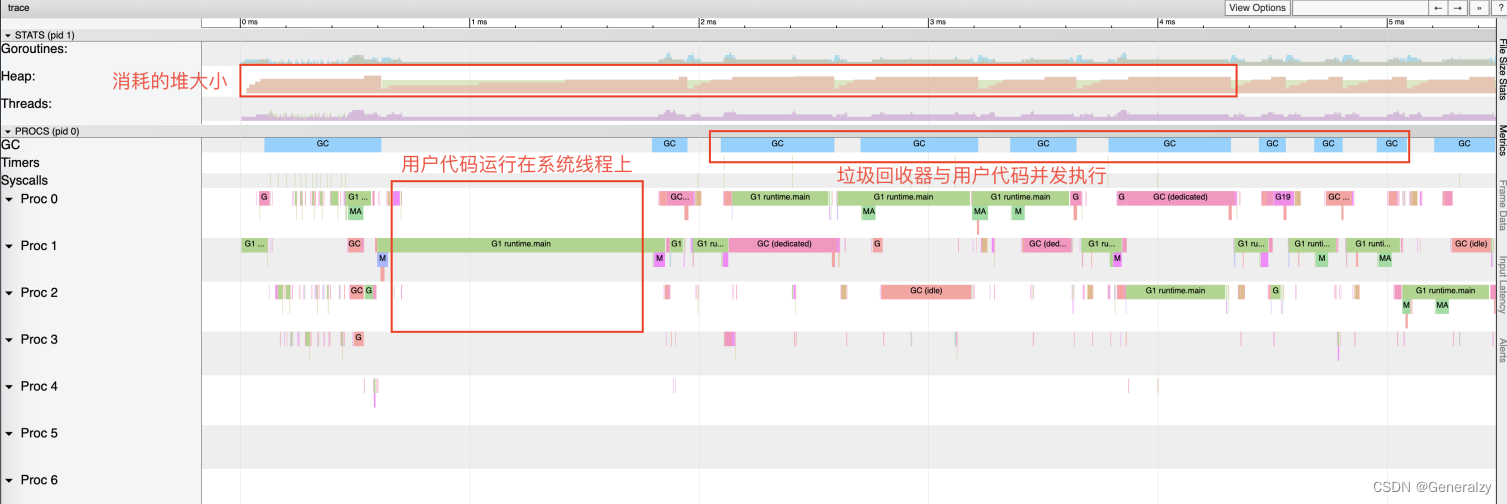
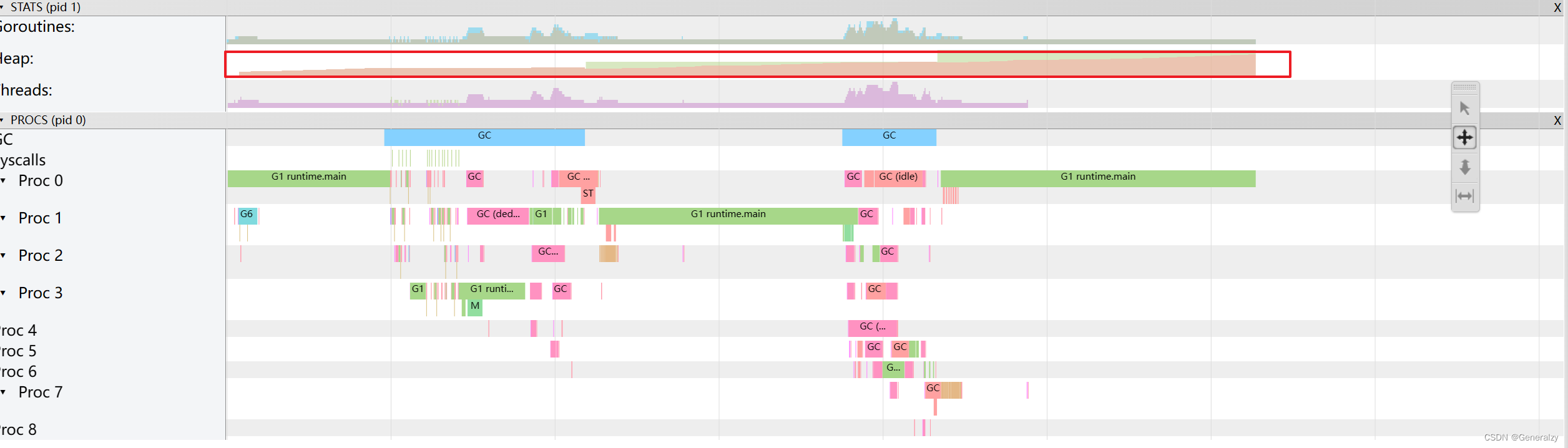
可以看到,途中的 Heap 在持续增长,没有内存被回收,产生了内存泄漏的现象。
goroutine 泄漏
Goroutine 作为一种逻辑上理解的轻量级线程,需要维护执行用户代码的上下文信息。在运行过程中也需要消耗一定的内存来保存这类信息,而这些内存在目前版本的 Go 中是不会被释放的。因此,如果一个程序持续不断地产生新的 goroutine、且不结束已经创建的 goroutine 并复用这部分内存,就会造成内存泄漏的现象。
func keepalloc2() { for i := 0; i < 100000; i++ { go func() { select {} }() } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
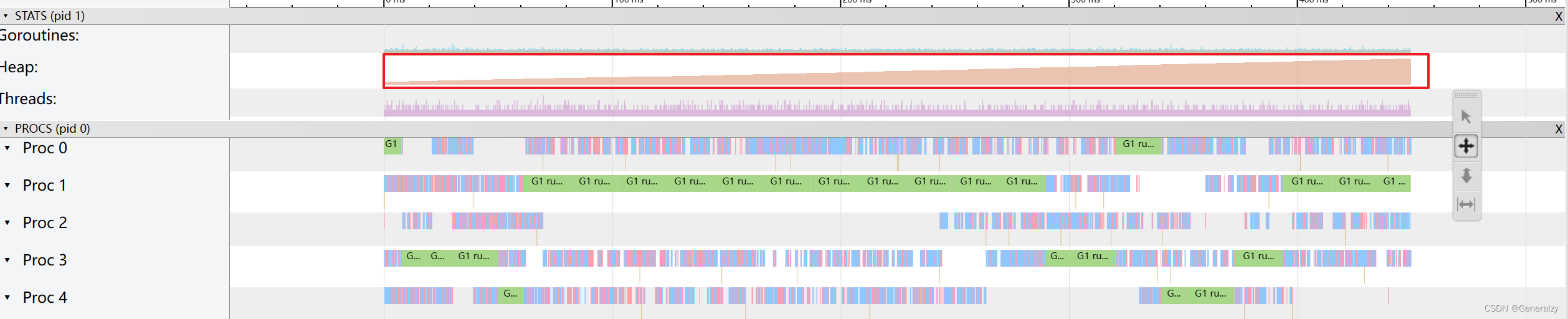
可以看到,途中的 Heap 在持续增长,没有内存被回收,产生了内存泄漏的现象。并发标记清除法的难点是什么?
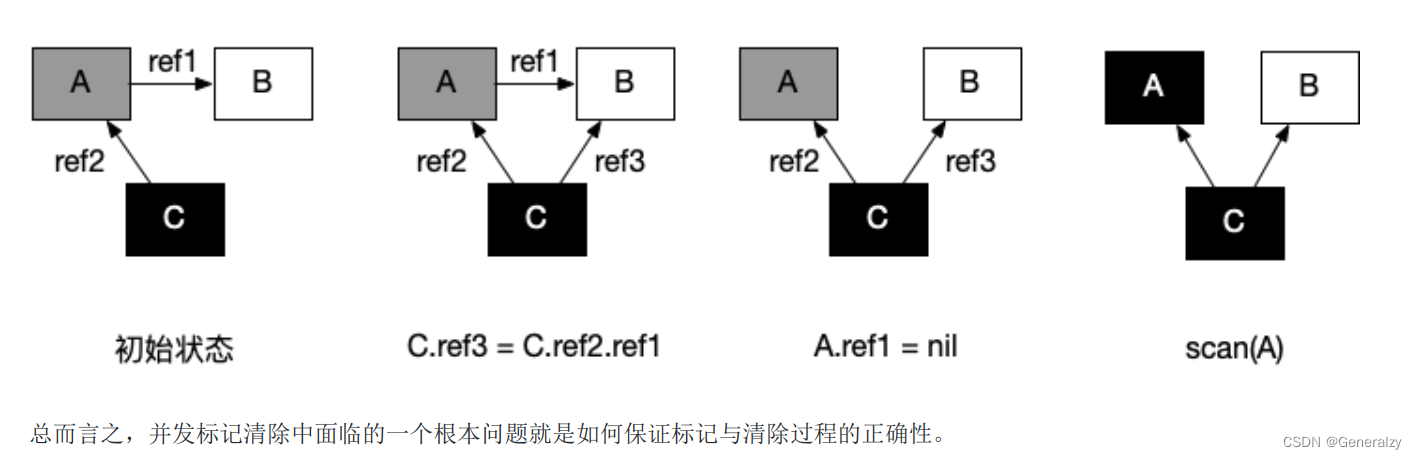
用户态代码在回收过程中会并发地更新对象图,从而造成赋值器和回收器可能对对象图的结构产生不同的认知。
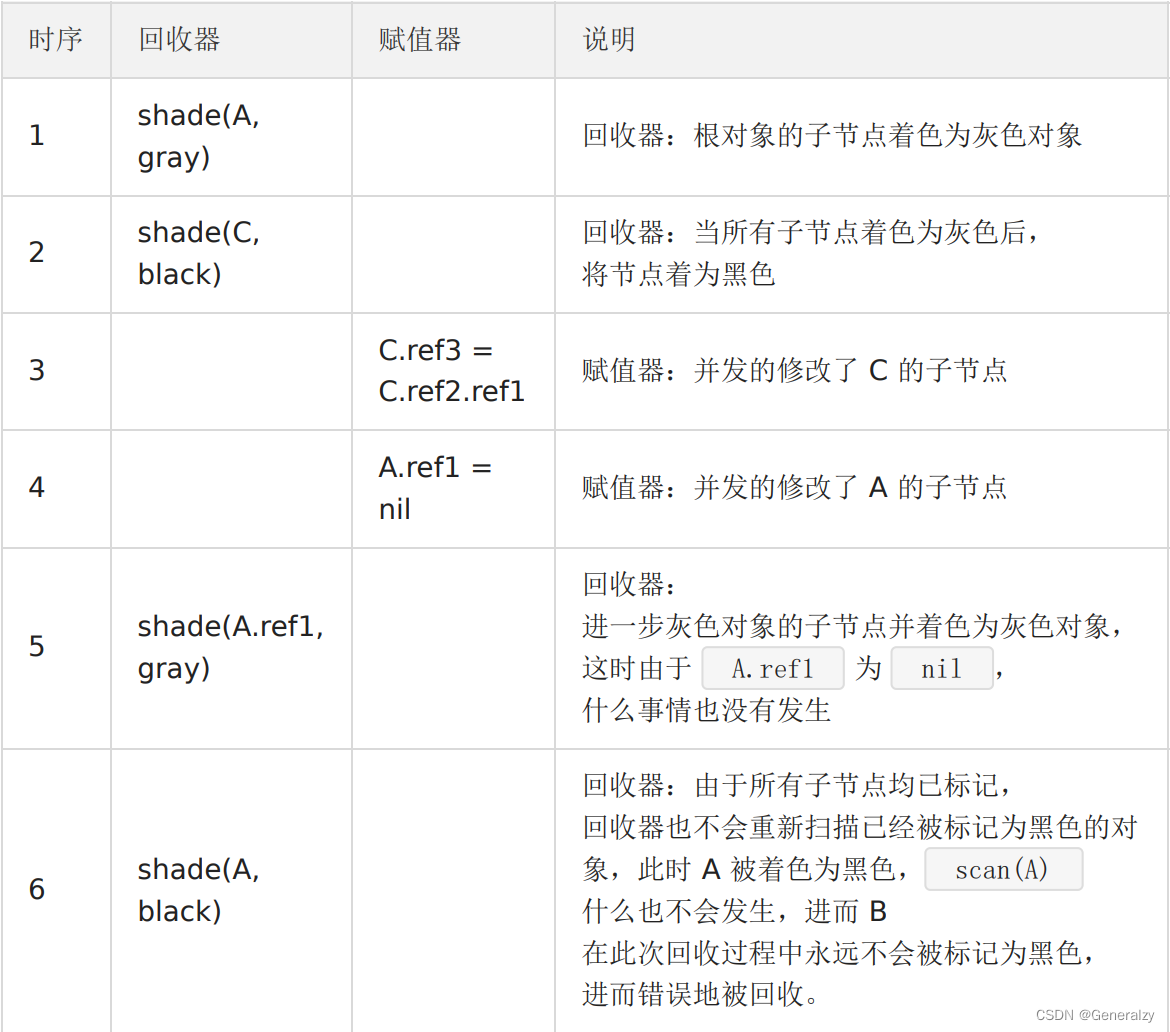
- 初始状态:假设某个黑色对象 C 指向某个灰色对象 A ,而 A 指向白色对象 B;
- C.ref3 = C.ref2.ref1 :赋值器并发地将黑色对象 C 指向(ref3)了白色对象 B;
- A.ref1 = nil :移除灰色对象 A 对白色对象 B 的引用(ref2);
- 最终状态:在继续扫描的过程中,白色对象 B 永远不会被标记为黑色对象了(回收器不会重新扫描黑色对象),进而对象B 被错误地回收。
什么是写屏障、混合写屏障,如何实现?
写屏障是一个在并发垃圾回收器中才会出现的概念,垃圾回收器的正确性体现在:不应出现对象的丢失,也不应错误的回收还不需要回收的对象。
可以证明,当以下两个条件同时满足时会破坏垃圾回收器的正确性:
- 条件 1: 赋值器修改对象图,导致某一黑色对象引用白色对象;
- 条件 2: 从灰色对象出发,到达白色对象的、未经访问过的路径被赋值器破坏。
只要能够避免其中任何一个条件,则不会出现对象丢失的情况,因为:
- 如果条件 1 被避免,则所有白色对象均被灰色对象引用,没有白色对象会被遗漏;
- 如果条件 2 被避免,即便白色对象的指针被写入到黑色对象中,但从灰色对象出发,总存在一条没有访问过的路径,从而找到到达白色对象的路径,白色对象最终不会被遗漏。
- 当满足原有的三色不变性定义(或上面的两个条件都不满足时)的情况称为强三色不变性(strong tricolor
invariant) - 当赋值器令黑色对象引用白色对象时(满足条件 1 时)的情况称为弱三色不变性(weak tricolor invariant)
当赋值器进一步破坏灰色对象到达白色对象的路径时(进一步满足条件 2 时),即打破弱三色不变性,
也就破坏了回收器的正确性;或者说,在破坏强弱三色不变性时必须引入额外的辅助操作。
弱三色不变形的好处在于:只要存在未访问的能够到达白色对象的路径,就可以将黑色对象指向白色对象。如果我们考虑并发的用户态代码,回收器不允许同时停止所有赋值器,就是涉及了存在的多个不同状态的赋值器。为了对概念加以明确,还需要换一个角度,把回收器视为对象,把赋值器视为影响回收器这一对象的实际行为(即影响 GC 周期的长短),从而引入赋值器的颜色:
- 黑色赋值器:已经由回收器扫描过,不会再次对其进行扫描。
- 灰色赋值器:尚未被回收器扫描过,或尽管已经扫描过但仍需要重新扫描。
赋值器的颜色对回收周期的结束产生影响:
- 如果某种并发回收器允许灰色赋值器的存在,则必须在回收结束之前重新扫描对象图。
- 如果重新扫描过程中发现了新的灰色或白色对象,回收器还需要对新发现的对象进行追踪,但是在新追踪的过程中,赋值器仍然可能在其根中插入新的非黑色的引用,如此往复,直到重新扫描过程中没有发现新的白色或灰色对象。
于是,在允许灰色赋值器存在的算法,最坏的情况下,回收器只能将所有赋值器线程停止才能完成其跟对象的完整扫描,也就是我们所说的 STW。
为了确保强弱三色不变性的并发指针更新操作,需要通过赋值器屏障技术来保证指针的读写操作一致。因此我们所说的 Go 中的写屏障、混合写屏障,其实是指赋值器的写屏障,赋值器的写屏障作为一种同步机制,使赋值器在进行指针写操作时,能够“通知”回收器,进而不会破坏弱三色不变性。
有两种非常经典的写屏障:Dijkstra 插入屏障和 Yuasa 删除屏障。
Dijkstra 插入屏障
灰色赋值器的 Dijkstra 插入屏障的基本思想是避免满足条件 1:
// 灰色赋值器 Dijkstra 插入屏障 func DijkstraWritePointer(slot *unsafe.Pointer, ptr unsafe.Pointer) { shade(ptr) *slot = ptr }- 1
- 2
- 3
- 4
- 5
为了防止黑色对象指向白色对象,应该假设 *slot 可能会变为黑色,为了确保 ptr 不会在被赋值到 *slot
前变为白色, shade(ptr) 会先将指针 ptr 标记为灰色,进而避免了条件 1。如图所示:
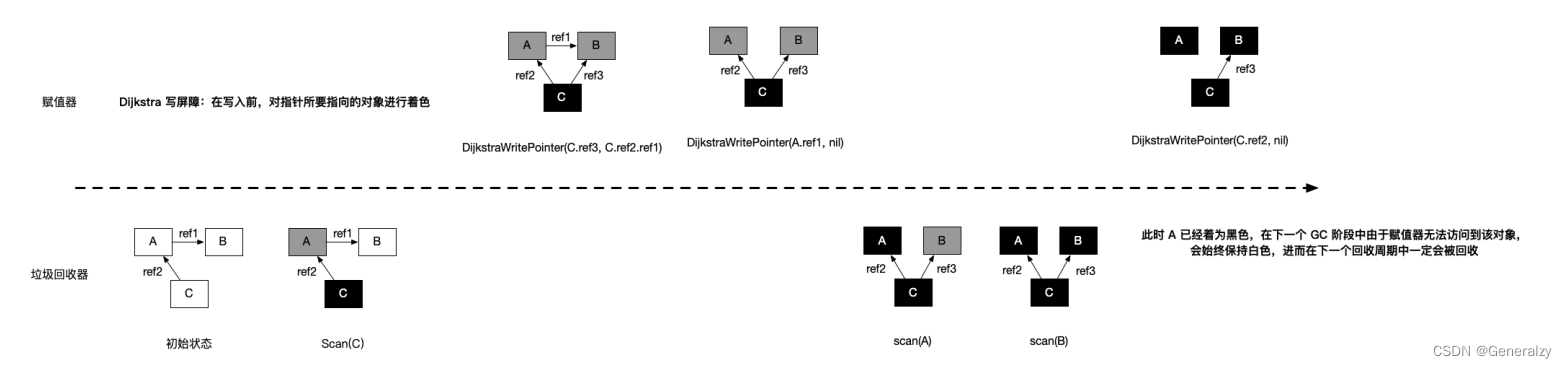
Dijkstra 插入屏障的好处在于可以立刻开始并发标记。但存在两个缺点:
- 由于 Dijkstra 插入屏障的“保守”,在一次回收过程中可能会残留一部分对象没有回收成功,只有在下一个回收过程中才会被回收;
- 在标记阶段中,每次进行指针赋值操作时,都需要引入写屏障,这无疑会增加大量性能开销;为了避免造成性能问题,Go团队在最终实现时,没有为所有栈上的指针写操作,启用写屏障,而是当发生栈上的写操作时,将栈标记为灰色,但此举产生了灰色赋值器,将会需要标记终止阶段 STW 时对这些栈进行重新扫描。
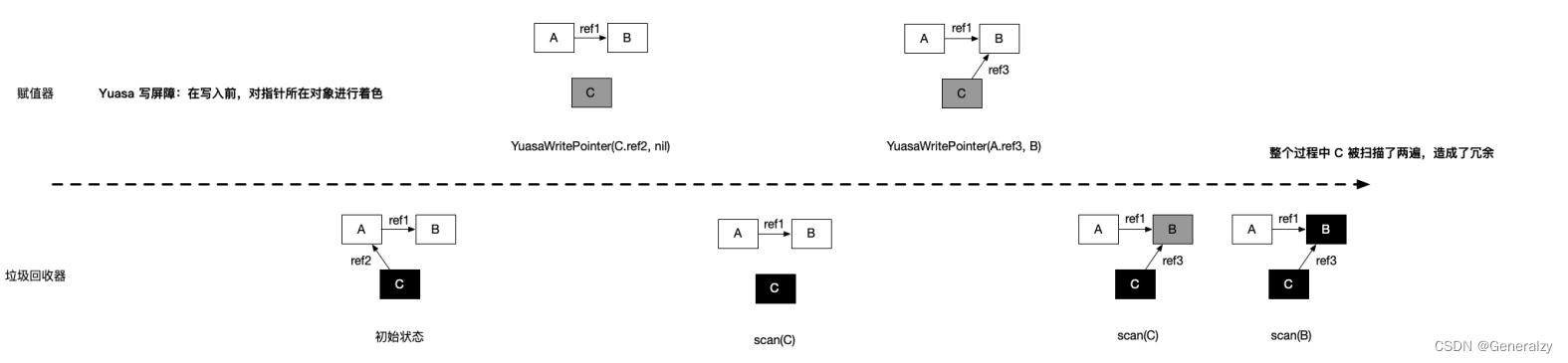
Yuasa 删除屏障
其基本思想是避免满足条件 2:
// 黑色赋值器 Yuasa 屏障 func YuasaWritePointer(slot *unsafe.Pointer, ptr unsafe.Pointer) { shade(*slot) *slot = ptr }- 1
- 2
- 3
- 4
- 5
为了防止丢失从灰色对象到白色对象的路径,应该假设 *slot 可能会变为黑色,为了确保 ptr 不会在被赋值到
*slot 前变为白色, shade(*slot) 会先将 *slot 标记为灰色,进而该写操作总是创造了一条灰色到灰色或
者灰色到白色对象的路径,进而避免了条件 2。Yuasa 删除屏障的优势则在于不需要标记结束阶段的重新扫描,结束时候能够准确的回收所有需要回收的白色对象。缺陷是Yuasa 删除屏障会拦截写操作,进而导致波面的退后,产生“冗余”的扫描:
Go 在 1.8 的时候为了简化 GC 的流程,同时减少标记终止阶段的重扫成本,将 Dijkstra 插入屏障和 Yuasa 删除屏障进行混合,形成混合写屏障。该屏障提出时的基本思想是:对正在被覆盖的对象进行着色,且如果当前栈未扫描完成,则同样对指针进行着色。…
参考文档(来源)
-
相关阅读:
Go数据库操作插件-xorm
趋势分析是什么?市场趋势分析的经典方法,从数据中识别机会
【Qt系列】QtableWidget表格列宽自适应表格大小
OpenCV:01图片&视频的加载显示
027-从零搭建微服务-搜索服务(一)
【Qt】顶层窗口和普通窗口区别以及用法
智能运维,为新型数据中心注入科技动能
C语言——函数的嵌套调用
#力扣:LCR 182. 动态口令@FDDLC
Visual Studio 2022 cmake编译 PP-OCRv4
- 原文地址:https://blog.csdn.net/General_zy/article/details/127135014
