-
【ML04】Multiple Variable Linear Regression
(一)概述 & Notation
f w , b ( x ) = w 1 x 1 + w 2 x 2 + . . . + w n x n + b f_{\mathbf{w,b}}(\mathbf{x}) = w_1x_1+ w_2x_2+...+w_nx_n + b fw,b(x)=w1x1+w2x2+...+wnxn+b
项目 Value 意义 w w w [ w 1 , w 2 , . . . , w n ] [w_1,w_2,...,w_n] [w1,w2,...,wn] parameters of the model b b b b number x x x [ x 1 , x 2 , . . . , x n ] [x_1,x_2,...,x_n] [x1,x2,...,xn] vector
(二)vectorization
f w , b ( x ) = w 1 x 1 + w 2 x 2 + . . . + w n x n + b f_{\mathbf{w,b}}(\mathbf{x}) = w_1x_1+ w_2x_2+...+w_nx_n + b fw,b(x)=w1x1+w2x2+...+wnxn+b
import numpy as np # 表达式 f = np.dot(w,x)+b- 1
- 2
- 3
This numpy function(dor) uses parallel hardware to efficiently calculuate the dot product, which make much faster!
(三)Gradient Descent
Gradient Descent for multiple features
w 1 = w 1 − a 1 m ∑ i = 1 m ( f w , b ( x ( i ) − y ( i ) ) x ( i ) w_1 = w_1-a\frac1 m\sum\limits_{i = 1}^{m} (f_{w,b}(x^{(i)}-y^{(i)})x^{(i)} w1=w1−am1i=1∑m(fw,b(x(i)−y(i))x(i)
w 2 = w 2 − a 1 m ∑ i = 1 m ( f w , b ( x ( i ) − y ( i ) ) x ( i ) w_2 = w_2-a\frac1 m\sum\limits_{i = 1}^{m} (f_{w,b}(x^{(i)}-y^{(i)})x^{(i)} w2=w2−am1i=1∑m(fw,b(x(i)−y(i))x(i)
…
w n = w n − a 1 m ∑ i = 1 m ( f w , b ( x ( i ) − y ( i ) ) x ( i ) w_n = w_n-a\frac1 m\sum\limits_{i = 1}^{m} (f_{w,b}(x^{(i)}-y^{(i)})x^{(i)} wn=wn−am1i=1∑m(fw,b(x(i)−y(i))x(i)
b = b − a 1 m ∑ i = 1 m ( f w , b ( x ( i ) − y ( i ) ) b = b-a\frac1 m\sum\limits_{i = 1}^{m} (f_{w,b}(x^{(i)}-y^{(i)}) b=b−am1i=1∑m(fw,b(x(i)−y(i))
(四)Python With Gradient Descent
4.1 引入与初始化数据集
import copy, math import numpy as np import matplotlib.pyplot as plt X_train = np.array([[2104, 5, 1, 45], [1416, 3, 2, 40], [852, 2, 1, 35]]) y_train = np.array([460, 232, 178]) b_init = 785.1811367994083 w_init = np.array([ 0.39133535, 18.75376741, -53.36032453, -26.42131618])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
4.2 返回线性回归函数公式
f w , b ( x ) = w 1 x 1 + w 2 x 2 + . . . + w n x n + b = w x + b f_{\mathbf{w,b}}(\mathbf{x}) = w_1x_1+ w_2x_2+...+w_nx_n + b=wx+b fw,b(x)=w1x1+w2x2+...+wnxn+b=wx+b
def predict(x, w, b): p = np.dot(x, w) + b return p- 1
- 2
- 3
4.3 计算多元线性回归损失函数
J ( w , b ) = 1 2 m ∑ i = 1 m ( f w , b ( x ( i ) − y ( i ) ) 2 J_{(w,b)} = \frac1 {2m}\sum\limits_{i = 1}^{m} (f_{w,b}(x^{(i)}-y^{(i)})^{2} J(w,b)=2m1i=1∑m(fw,b(x(i)−y(i))2
def compute_cost(X, y, w, b): m = X.shape[0] cost = 0.0 for i in range(m): f_wb_i = np.dot(X[i], w) + b cost = cost + (f_wb_i - y[i]) ** 2 cost = cost / (2 * m) return cost- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

4.4 计算parameters的导数
w j = w j − α ∂ J ( w , b ) ∂ w j w_j = w_j - \alpha \frac{\partial J(\mathbf{w},b)}{\partial w_j} wj=wj−α∂wj∂J(w,b)
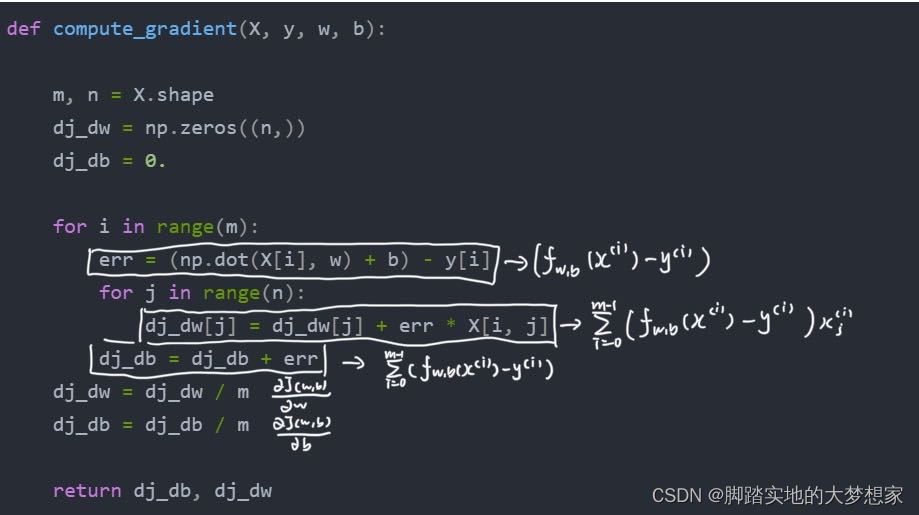
b = b − α ∂ J ( w , b ) ∂ b b = b - \alpha \frac{\partial J(\mathbf{w},b)}{\partial b} b=b−α∂b∂J(w,b)∂ J ( w , b ) ∂ w j = 1 m ∑ i = 0 m − 1 ( f w , b ( x ( i ) ) − y ( i ) ) x j ( i ) \frac{\partial J(\mathbf{w},b)}{\partial w_j} = \frac{1}{m} \sum\limits_{i = 0}^{m-1} (f_{\mathbf{w},b}(\mathbf{x}^{(i)}) - y^{(i)})x_{j}^{(i)} ∂wj∂J(w,b)=m1i=0∑m−1(fw,b(x(i))−y(i))xj(i)
∂ J ( w , b ) ∂ b = 1 m ∑ i = 0 m − 1 ( f w , b ( x ( i ) ) − y ( i ) ) \frac{\partial J(\mathbf{w},b)}{\partial b} = \frac{1}{m} \sum\limits_{i = 0}^{m-1} (f_{\mathbf{w},b}(\mathbf{x}^{(i)}) - y^{(i)}) ∂b∂J(w,b)=m1i=0∑m−1(fw,b(x(i))−y(i))def compute_gradient(X, y, w, b): m, n = X.shape dj_dw = np.zeros((n,)) dj_db = 0. for i in range(m): err = (np.dot(X[i], w) + b) - y[i] for j in range(n): dj_dw[j] = dj_dw[j] + err * X[i, j] dj_db = dj_db + err dj_dw = dj_dw / m dj_db = dj_db / m return dj_db, dj_dw- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
4.5 计算损失函数J的变化
def gradient_descent(X, y, w_in, b_in, cost_function, gradient_function, alpha, num_iters): J_history = [] w = copy.deepcopy(w_in) # avoid modifying global w within function b = b_in for i in range(num_iters): dj_db, dj_dw = gradient_function(X, y, w, b) w = w - alpha * dj_dw b = b - alpha * dj_db if i < 100000: J_history.append(cost_function(X, y, w, b)) if i % math.ceil(num_iters / 10) == 0: print(f"Iteration {i:4d}: Cost {J_history[-1]:8.2f} ") return w, b, J_history- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
# print J with Gradient Descent initial_w = np.zeros_like(w_init) initial_b = 0. iterations = 1000 alpha = 5.0e-7 # run gradient descent w_final, b_final, J_hist = gradient_descent(X_train, y_train, initial_w, initial_b, compute_cost, compute_gradient, alpha, iterations) print(f"b,w found by gradient descent: {b_final:0.2f},{w_final} ") m,_ = X_train.shape for i in range(m): print(f"prediction: {np.dot(X_train[i], w_final) + b_final:0.2f}, target value: {y_train[i]}")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
数据来源:(吴恩达《ML》Lab02 Multiple Variable LR)

4.6 展示J的变化
自行 plt 绘图
# plot cost versus iteration fig, (ax1, ax2) = plt.subplots(1, 2, constrained_layout=True, figsize=(12, 4)) ax1.plot(J_hist) ax2.plot(100 + np.arange(len(J_hist[100:])), J_hist[100:]) ax1.set_title("Cost vs. iteration"); ax2.set_title("Cost vs. iteration (tail)") ax1.set_ylabel('Cost') ; ax2.set_ylabel('Cost') ax1.set_xlabel('iteration step') ; ax2.set_xlabel('iteration step') plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
end – >>
-
相关阅读:
心行知合一
面试题:MySQL事务的ACID如何实现?
Python--循环中的两大关键词 break 与 continue
系统平台:新店如何打造爆款
echarts-折线图配置详解
IT入门知识第八部分《云计算》(8/10)
Jackson
linux下如何hook第三方播放器的视频数据?
WZOI-260近在咫尺
语法基础(函数)
- 原文地址:https://blog.csdn.net/weixin_43098506/article/details/127131218
