-
Python实现DBSCAN膨胀聚类模型(DBSCAN算法)项目实战
说明:这是一个机器学习实战项目(附带数据+代码+文档+视频讲解),如需数据+代码+文档+视频讲解可以直接到文章最后获取。

1.项目背景
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种基于密度的空间聚类算法。该算法将具有足够密度的区域划分为簇,并在具有噪声的空间数据库中发现任意形状的簇,DBSCAN算法将“簇”定义为密度相连的点的最大集合。
DBSCAN算法是密度聚类算法,所谓密度聚类算法就是说这个算法是,根据样本的紧密程度来进行聚类。
2.数据获取
本次建模数据来源于网络(本项目撰写人整理而成),数据项统计如下:
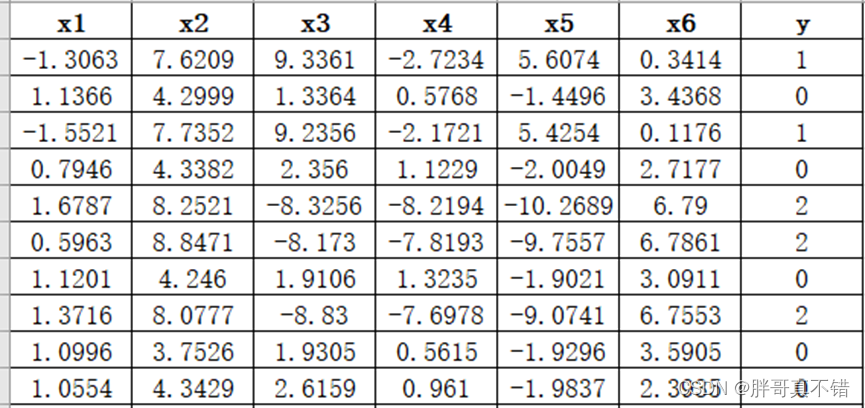
数据详情如下(部分展示):
部分数据展示:
3.数据预处理
3.1 用Pandas工具查看数据
使用Pandas工具的head()方法查看前五行数据:

从上图可以看到,总共有7个字段。
关键代码:

3.2缺失值统计
使用Pandas工具的info()方法统计每个特征缺失情况:
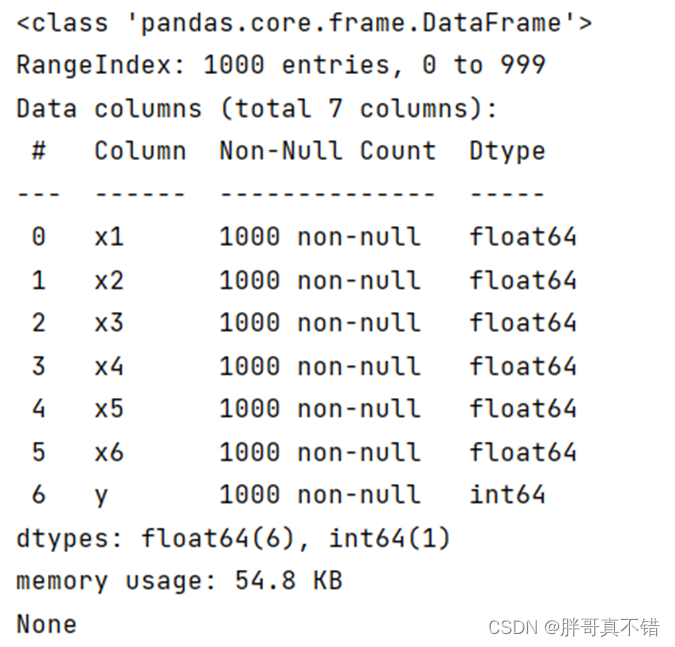
从上图可以看到,数据不存在缺失值,总数据量为1000条。
关键代码:

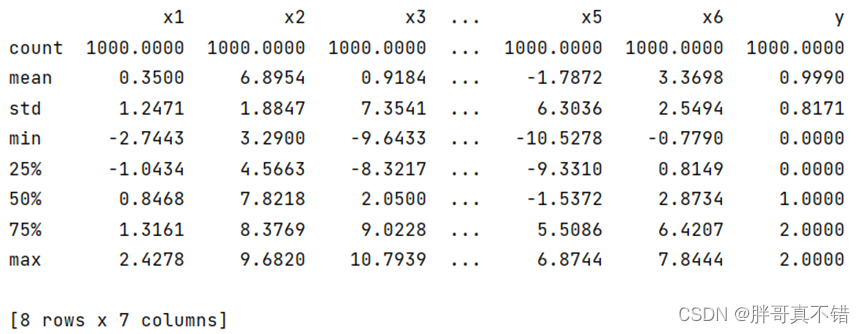
3.3变量描述性统计分析
通过Pandas工具的describe()方法来来统计变量的平均值、标准差、最大值、最小值、分位数等信息:
关键代码如下:

4.探索性数据分析
4.1.绘制散点图
通过Matplotlib工具针对x1 x2两个特征绘制分类散点图,如下图所示:

4.2 相关性分析
通过Pandas工具的corr()方法和seaborn工具的heatmap()方法绘制相关性热力图:
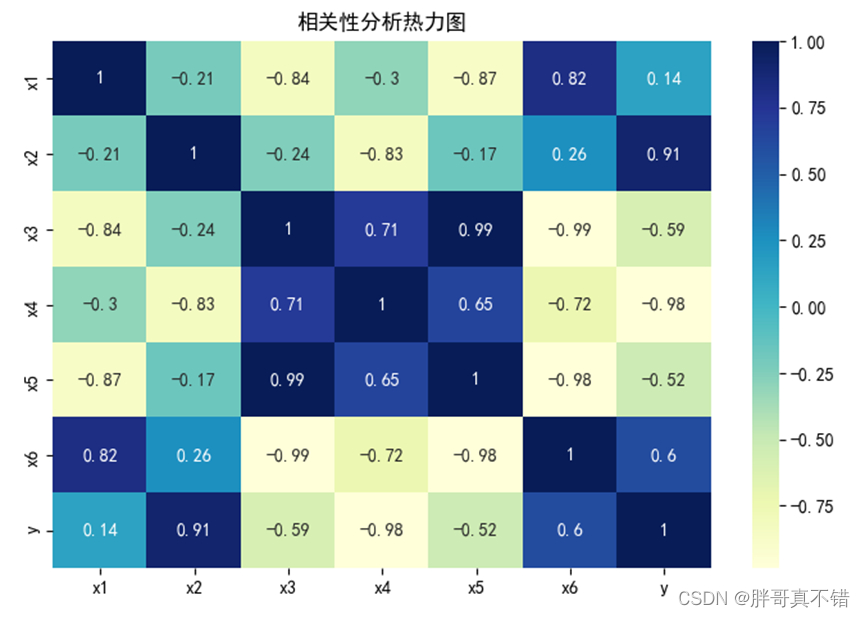
从图中可以看到,正数为正相关,负数为负相关,绝对值越大相关性越强。
5.特征工程
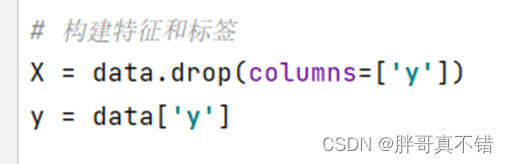
5.1 建立特征数据和标签数据
y为标签数据,除y之外的为特征数据。关键代码如下:
5.2 数据标准化
sklearn包下的StandardScaler函数进行特征数据的标准化,关键代码如下:

6.构建聚类模型
主要使用DBSCAN聚类算法,用于目标聚类分析。
6.1 建立DBSCAN聚类模型

6.2 获取聚类类别数和噪声样本数

关键代码如下:

7.模型评估
7.1评估指标及结果
评估指标主要包括聚类结果同质性、完整性、调和平均值、调整的兰德系数、互信息、轮廓系数等等。

通过上表可以看到,整体的模型效果良好。
7.2 聚类结果可视化
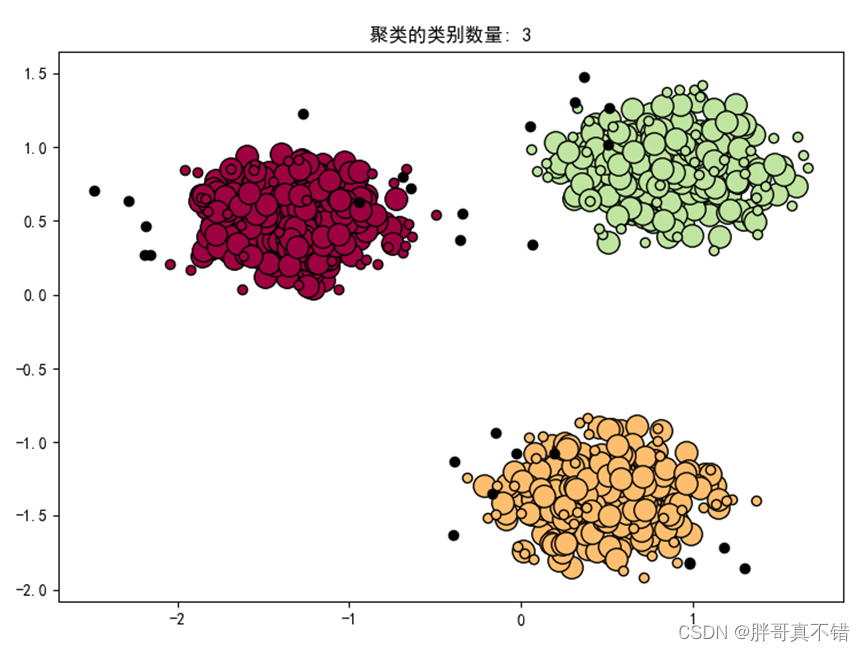
从上图可以看到,聚成了3类,黑色的点代表有噪声的聚类标签样本。
8.结论与展望
综上所述,本项目采用DBSCAN聚类算法进行聚类,最终证明了我们提出的模型效果良好,可用于日常生活中进行建模预测,以提高生产价值。
- # 本次机器学习项目实战所需的资料,项目资源如下:
- 链接:https://pan.baidu.com/s/1TyMNQbTFJMgfjB1IlBHekA
- 提取码:81hc
- # 用Pandas工具查看数据
- print(data.head())
- # 数据缺失值统计
- print('****************************************')
- print(data.info())
- print('****************************************')
- print(data.describe().round(4)) # 保留4位小数点
- # 可视化特征数据集:绘制散点图
- plt.scatter(data['x1'].values, data['x2'].values, c=data['y'].values, s=50, cmap="rainbow") # rainbow彩虹色
- plt.xticks([]) # 空列表 不显示x轴刻度
- plt.yticks([]) # 空列表 不显示y轴刻度
- plt.show()
- # 数据的相关性分析
- plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
- plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
-
相关阅读:
H-吐泡泡_ Java解法_牛客竞赛语法入门班数组栈、队列和stl习题
荣威 D7 正式亮相,新能源江湖再战
二进制安装部署k8s
计算机网络全篇知识学习打卡
基于单片机的胎压监测系统的设计
自动驾驶中的SLAM
如何才能实现批量抠图?一键批量抠图的办法
Js 对于一个时间戳,只改变其年份,求改变之后的时间戳。
来看看安卓机的几个应用程序
循环(while do...while for)介绍
- 原文地址:https://blog.csdn.net/weixin_42163563/article/details/127133164
