-
进程地址空间--Linux
目录
🚩前言
谈及进程,我们对进程的概念并不陌生,但对于进程所在的地方,我们得搞清楚。那么我们平常写的程序运行起来之后,所在的进程是直接放在了内存上吗?其实并不是,我们平常所看到的进程地址空间是程序地址空间,也叫虚拟地址空间。
这种地址空间处理实际上是对内存空间的高效利用和保护,我们后面再讲。
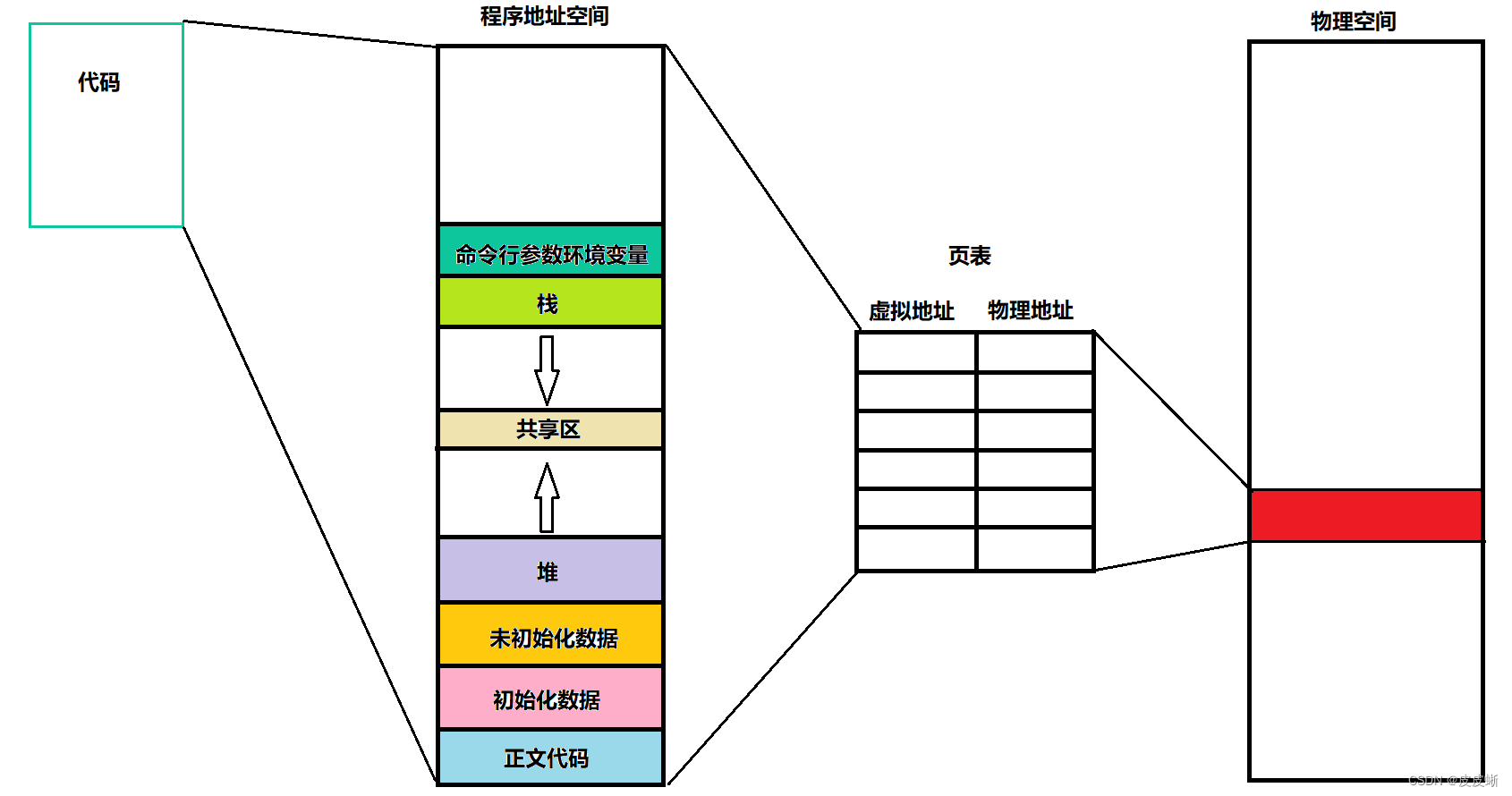
🚩程序(虚拟)地址空间
为什么叫虚拟地址空间呢?
原因在于每个进程不可能完全占有整个内存空间,往往只需要一部分就够了。为了保证内存空间的高效利用,操作系统每次只会给进程一部分内存空间,并让进程以为自己拥有了完整的内存空间--虚拟地址空间诞生。
图解

程序地址空间验证

代码:
- #include
- #include
- #include
- int init_val=100;
- int uninit_val;
- int main(int argc, char* argv[],char* env[])
- {
- const char* c_str="abcdef";
- printf("code addr :%p\n",main);//代码区
- printf("read_only addr :%p\n",c_str);//常量区
- printf("init_val addr :%p\n",&init_val);//初始化变量
- printf("uninit_val addr :%p\n",&uninit_val);//未初始化变量
- int* p1=(int*)malloc(sizeof(int)*10);
- int* p2=(int*)malloc(sizeof(int)*10);
- int* p3=(int*)malloc(sizeof(int)*10);
- int* p4=(int*)malloc(sizeof(int)*10);
- printf("heap addr :%p\n",p1);//堆区
- printf("heap addr :%p\n",p2);
- printf("heap addr :%p\n",p3);
- printf("heap addr :%p\n",p4);
- printf("stack addr :%p\n",&p1);//栈区
- printf("stack addr :%p\n",&p2);
- printf("stack addr :%p\n",&p3);
- printf("stack addr :%p\n",&p4);
- int i=0;
- for(i=0;i
- {
- printf("argv addr :%p\n",argv[i]);
- }
- for(i=0;env[i];++i)//环境变量
- {
- printf("env addr :%p\n",env[i]);
- }
- return 0;
- }
运行结果:

从上面的图片可以看出:我们自己写的程序的地址空间,刚好和程序地址空间的布局相同。
注:每个进程都有属于自己独有的地址空间!并且在用户看来,每个进程的地址空间都是4G。这显然是不可能的,具体的处理方式是什么呢?答案在于页表这个特殊的结构里!
🚩页表
既然我们知道了以往的地址空间是虚拟的 ,那么它是怎么和真实存在的物理空间连接起来的呢?
这里我们就要引入页表这个概念了。
将程序加载到内存中并转换为进程时,操作系统会自动生成一个对应进程的页表。
页表的结构
页表的作用
当调度器把相应的进程加载到cpu时,cpu会访问该进程中的地址来运行和计算,但是虚拟的地址是不可能被直接访问的,被访问的还是真实存在的物理空间。因此这中间的连接转化工作就交给了页表。
页表其实保存了两种数据:虚拟地址和物理地址。并且这两个地址严格左右对照。每次cpu访问进程的地址时,都是通过页表先找到虚拟地址,再访问对应着的物理地址。
挨个访问4G虚拟地址会怎样?
🔺非法访问!
我们在写代码的时候,经常会出现非法指针访问的现象。原因就在于,我们此时访问的地址页表里面很有可能没有,也就是没有真实的物理空间对应着。这样肯定是会报错的。
同时也可以看出,页表相当于是一个检查站,只有合格的地址访问,才会被允许。否则内存随便访问的风险就太大了一点。
🚩父子进程的地址空间理解
我们知道,父进程和子进程是共用一套代码的。那我们是不是可以合理地推测父子进程的地址空间也同样是共用的呢?
大部分情况下,上述猜测是成立的。但有一种情况比较特殊,就是涉及到对程序进行写入操作时,父子进程的地址就会稍微有点出入了。
对进程进行写入操作
- #include
- #include
- #include
- int main()
- {
- int g_val=10;
- pid_t id=fork();
- if(id==0)//子进程
- {
- while(1)
- {
- printf("子进程:pid:%d ppid:%d g_val:%d &g_val:%p\n",getpid(),getppid(),g_val,&g_val);
- g_val+=10;//相当于写入改变数据
- sleep(1);
- }
- }
- else//父进程
- {
- while(1)
- {
- printf("父进程:pid:%d ppid:%d g_val:%d &g_val:%p\n",getpid(),getppid(),g_val,&g_val);
- sleep(1);
- }
- }
- return 0;
- }
运行结果:

可以看出g_val的地址一样,但是却出现了不一样的值。是不是似曾相识?这不是和fork()函数返回值一样吗?
原因其实很简单,在发生写入操作时,为了避免写入部分造成未写入进程的逻辑发生变化(例:子进程的一个变量在父进程中充当条件语句的判别值),写入时会进行写时拷贝,将被写入的数据再另开辟一个。
因为是在物理空间上直接开辟,反映到虚拟地址上时,仍是和原来一样的地址空间,因此在我们看来,一样的地址空间里存了两个不同的值。
父子进程地址图解

🚩总结
进程之间的独立性
由于写时拷贝的存在,虽然父子进程共用一套地址空间,但只要一方写入,就会自动进行拷贝分离,这样就不会出现地址冲突的问题。
虚拟地址设计思路
让进程或者程序可以以种统一的视角看待内存!方便以统一的方式来编译和加载所有的可执行程序。
虚拟地址的作用
1.以页表为隔离层,将物理内存保护起来。
2.使内存申请和内存使用分离,通过虚拟地址空间来屏蔽底层内存申请的过程(进程也不再关心该过程),从而达到进程和操作系统进行内存管理操作,将进程调度和内存管理进行解耦。
3.由设计思路可知,虚拟地址可以提高cpu的运行效率,每个进程在cpu看来都是一样的地址空间和处理方式。
自我感受
虚拟地址是学习进程地址空间的重点,要理解虚拟地址的高效内存空间利用率。内容就到这里了,拜拜~😋
-
相关阅读:
[附源码]计算机毕业设计JAVA超市收银系统论文
MySQL最基本的常识
C++——string的模拟实现+详细讲解
mac为什么不支持ntfs,mac读取ntfs移动硬盘软件有哪些
计算机网络核心概念——名词解释
[Spring Boot] 集成Nacos
JVM 基础篇:类加载器
学生HTML个人网页作业作品 基于HTML+CSS+JavaScript明星个人主页(15页)
涂鸦Wi-Fi&BLE SoC开发幻彩灯带(5)----烧录授权
香港电信级中立机房服务器租赁服务——跨境互联新篇章
- 原文地址:https://blog.csdn.net/qq_63412763/article/details/127129619
