-
AWK用法全解与sed去掉sql最后一个字段哪一行的逗号
AWK用法全解
一、awk介绍
awk是Linux自带的一个逐行扫描的文本处理工具,支持正则表达式、循环控制、条件判断、格式化输出。AWK自身带有一些变量,可以在书写脚本时调用。
awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理, 因为切开的部分使用awk可以定义变量,运算符, 使用流程控制语句进行深度加工与分析。
创始人 Alfred V. Aho、Peter J. Weinberger和Brian W. Kernighan awk由来是姓氏的首字母.
基本语法格式:
awk [options] ‘pattern{action}’ {filenames}
pattern:表示AWK在数据中查找的内容,就是匹配模式
action:在找到匹配内容时所执行的一系列命令二、基本语法格式
2.1、在shell中使用awk
awk [option] 代码块 文件名
- option的选项及含义
选项 含义 使用演示 演示说明 -F 指定文件分隔符 awk -F “\n” 按 \n 做分隔符 -f 使用文件中的内容作为命令输入 awk -f script.txt 使用 script.txt 文件中的内容作为命令 -v 给变量赋值,支持多个v赋值 awk -v Num=num
−v Num1=num
−v Num1=num1把num的值给Num、num1的值给Num1 - awk内置变量
内置变量 含义 ARGC 命令行参数个数 ARGV 命令行参数排列 ENVIRON 支持队列中系统环境变量的使用 FILENAME awk浏览的文件名 FNR 浏览文件的记录数 (行数) FS 设置输入域分隔符,等价于命令行 -F选项 NF 浏览记录的域的个数, 根据分隔符分割后的列数 NR 已读的记录数, 也是行号 OFS 输出域分隔符 ORS 输出记录分隔符 RS 控制记录分隔符 $n $0 变量是指整条记录。 $1 表示当前行的第一个域, $2 表示当前行的第二个域,…
以此类推。$NF $NF是number finally,表示最后一列的信息,跟变量NF是有区别的,变量NF统计
的是每行列的总数数据准备
cp /etc/passwd ./- 1
示例 : 默认每行空格切割数据
命令
echo "abc 123 456" | awk '{print $1"&"$2"&"$3}'- 1
示例: 切割ip
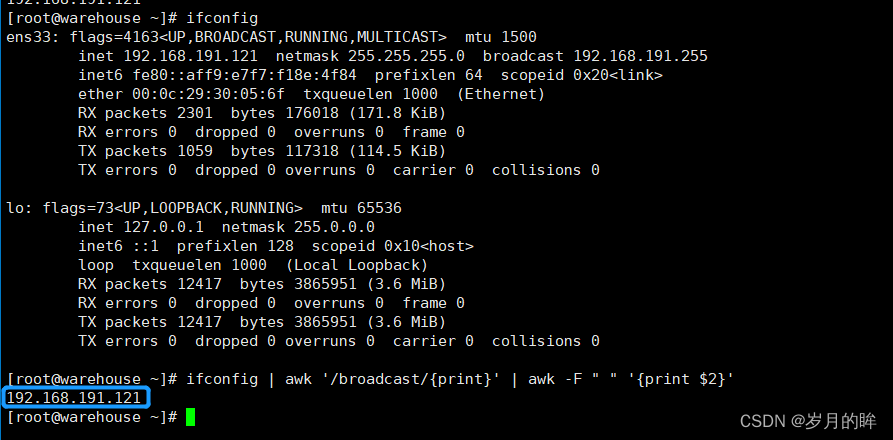
-
ifconfig | awk '/broadcast/{print}' | awk -F " " '{print $2}'- 1
-
运行效果
示例: 打印含有匹配信息的行
搜索passwd文件有root关键字的所有行
awk '/root/' passwd # '/root/' 是查找匹配模式, 没有action命令, 默认输出所有符合的行数据- 1
- 2
示例: 打印匹配行中第7列数据
搜索passwd文件有root关键字的所有行, 然后以":"拆分并打印输出第7列
awk -F: '/root/{print $7}' passwd # -F: 以':'分隔符拆分每一个列(域)数据- 1
- 2
示例: 打印文件每行属性信息
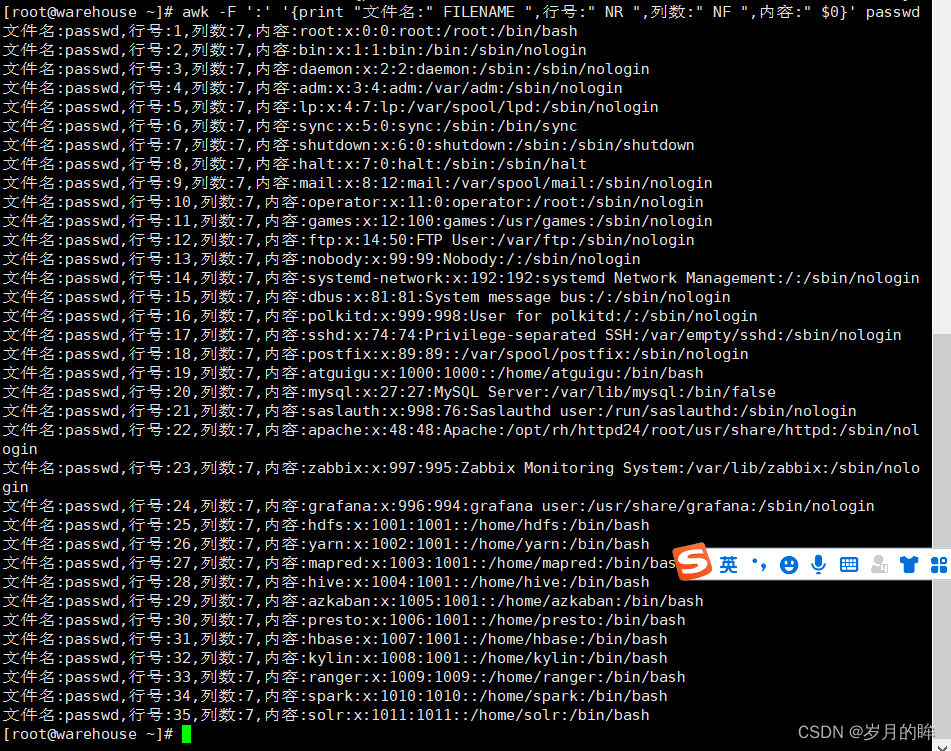
统计passwd: 文件名,每行的行号,每行的列数,对应的完整行内容:
awk -F ':' '{print "文件名:" FILENAME ",行号:" NR ",列数:" NF ",内容:" $0}' passwd # "文件名:" 用于拼接字符串- 1
- 2
- 3
使用printf替代print,可以让代码阅读型更好
awk -F ':' '{printf("文件名:%5s,行号:%2s, 列数:%1s, 内容:%2s\n",FILENAME,NR,NF,$O)}' passwd # printf(格式字符串,变量1,变量2,...) # 格式字符串: %ns 输出字符串,n 是数字,指代输出几个字符, n不指定自动占长度 # 格式字符串: %ni 输出整数,n 是数字,指代输出几个数字 # 格式字符串: %m.nf 输出浮点数,m 和 n 是数字,指代输出的整数位数和小数位数。如 %8.2f 代 表共输出 8 位数,其中 2 位是小数,6 位是整数;- 1
- 2
- 3
- 4
- 5
- 6
示例: 打印第二行信息
打印/etc/passwd/的第二行信息
awk -F ':' 'NR==2{printf("filename:%s,%s\n",FILENAME,$0)}' passwd- 1
示例: 查找以c开头的资源
awk过滤的使用, 查找当前目录下文件名以c开头的文件列表
ls -a | awk '/^c/'- 1
示例: 打印第一列
按照":" 分割查询第一列打印输出
awk -F ':' '{print $1}' passwd- 1
示例: 打印最后1列
按照":" 分割查询最后一列打印输出
awk -F: '{print $NF}' passwd- 1
示例: 打印倒数第二列
按照":" 分割查询倒数第二列打印输出
awk -F: '{print $(NF-1)}' passwd # $(NF-N) N是几, 就是倒数第几列- 1
- 2
示例: 打印10到20行的第一列
获取第10到20行的第一列的信息
awk -F: '{if(NR>=10 && NR<=20) print $1}' passwd- 1
示例: 多分隔符使用
one:two/three"字符串按照多个分隔符":“或者”/" 分割, 并打印分割后每个列数据
echo "one:two/three" | awk -F '[:/]' '{printf("%s\n%s\n%s\n%s\n",$0,$1,$2,$3)}'- 1
- 2
示例: 添加开始与结束内容
给数据添加开始与结束
echo -e "abc\nabc" | awk 'BEGIN{print "开始..."} {print $0} END{print "结 束..."}' # BEGIN 在所有数据读取行之前执行;END 在所有数据执行之后执行。- 1
- 2
- 3
- 4
示例: 操作指定数字运算
将passwd文件中的用户id增加数值1并输出
echo "2.1" | awk -v i=1 '{print $0+i}'- 1
- 代码块的说明:
条件判断’{要执行的内容}’ 注:条件判断与“{”之间不带空格,{}的两侧要使用单引号"'’"包围。
条件判断为真则执行{}中的内容,条件判断为假则不执行{}中的内容。
例如 :
awk -F "," NR==2'{print $1}' awktest.txt- 1
#将awktest.txt文件中的文本以",",如果行号为2则打印第一列内容。
awk -F "," NR==10'{print "这是第"NR"行","第1列是:"$1,"第2列是:"$2}' awktest.txt- 1
hive 日期和时间戳互相转化
一 . 日期转时间戳
1 unix_timestamp() 获取当前时间戳
select unix_timestamp(); --1636462239- 1
2 unix_timestamp() 输入日期参数 输入的时间格式必须符合 yyyy-MM-dd HH:mm:ss
select unix_timestamp('2021-11-11 11:11:11'); --1636600271- 1
3 unix_timestamp() 输入日期参数,并指定日期格式 时间格式指定错 返回null
select unix_timestamp('2021-08-15','yyyy-MM-dd'); --1628956800 --15号零点时间戳 select unix_timestamp('2021-08-15 15','yyyy-MM-dd HH');- 1
- 2
- 3
二. 时间戳转日期
1 from_unixtime() 将时间戳转化为指定的时间格式
select from_unixtime(1628956800,'yyyy-MM-dd'); --2021-08-15 select from_unixtime(1628956800,'yyyy-MM-dd HH-mm'); 2021-08-15 00-00- 1
- 2
- 3
2 同理获取当前时间
select from_unixtime(unix_timestamp(),'yyyy-MM-dd HH:mm:ss'); 2021-11-09 21:13:56- 1
在工作中遇到使用awk配合sed处理SQL的问题
怎样使用sed删除sql最后一行的逗号
- 示例获取某个xxx.flg数据文件中的表结构,然后使用sed替换处理和去掉最后一个字段行的逗号
TH_PS_INFO.20220819.000000.0000.dat 38478500 20500 2022-08-19 13:52:09 FILENAME-TH_PS_INFO.20220819.000000.0000.dat.gz FILESIZE-1006432 ROWCOUNT=20500 CREATEDATETIME=2022-08-19 13:52:08 SQL=select* from pv.th_ps_info where block_date ='2022-08-18' ROWLENGTH=1876 COLUMNCOUNT=25 COLUMNDESCRIPTTON= 1$$id$$varchar(64)$$(1,64) 2$$channel$$varchar(64)$$(65,128) 3$$block_date$$varchar(32)$$(129,160) 4$$ps_id$$varchar(64)$$(161,224) 5$$capacity$$Sbigint$$(225,244) 6$scity_code$$varchar(32)$$(245,276) 7$scity_name$$varchar(64)$$(277,340) 8$$etotal$$decimal(50,2)$$(341,392) 9$$init_time$$varchar(32)$$(393,424) 1o$$lat$$decimal(10,7)$$(425,436) 11$$lng$$decimal(10, 7)$$(437,448) 12$$loan_status$$varchar(4)$$(449, 452) 13$$name$$varchar(256)$$(453,708) 14$$offline_time$$varchar(32)$$(709,740) 15$$owner$$varchar(256)$$(741,996) 16$$phone$$varchar(16)$$(997,1012) 17$$power$$decimal(50,2)$$(1013,1064) 18$$power_time$$varchar(32)$$(1065,1096) 19$$province_code$$varchar(32)$$(1097,1128) 20$$province_name$$varchar(64)$$(1129,1192) 21$$ps_code$$varchar(64)$$(1193,1256) 22$$region_code$$varchar(32)$$(1257,1288) 23$$region_name$$varchar(64)$$(1289,1352) 24$$sn_list$$varchar(512)$$(1353,1864) 25$$statusSSint$$(1865,1876)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 使用awk截取表结构
cat /cib/j042x0/sftp/data/share/TH_PS_INFO.20220819.000000.0000.flg | grep '^[0-9]'| awk -F'$' '{print $3"\t"$5","}'| sed 's/decimal(50,/decimal(38,/'| sed '$/varchar([0-9]*./string/' | sed 's/^DATE$/\`DATE\`/' |sed 's/^date$/\`date\`/' |sed 's/^TIMESTAMP$/\`TIMESTAMP\`/' | sed 's/^timestamp$/\`^timestamp\`/' |sed 's/^_time$/\`^_time$\`/' |sed 's/^_TIME$/^\`_TIME\`/' | sed 's/^MORE$/\`MORE\`/' | sed 's/^more$/\`more\`/' | sed '$s/.$//'- 1

sed获取sql字段的最后一行去掉逗号sed '$s/.$//'- 1
-
相关阅读:
文本生成系列之retrieval augmentation(进阶篇Atlas)
带你了解什么是 Web3.0
第十三篇【传奇开心果系列】Python的文本和语音相互转换库技术点案例示例:Microsoft Azure的Face API开发人脸识别门禁系统经典案例
leetcode 简单
Python VScode 配置
【算法专题】哈希表
HTTP协议分析
flutter系列之:在flutter中自定义themes
Control的Invoke和BeginInvoke
Day12 尚硅谷JUC——集合的线程安全
- 原文地址:https://blog.csdn.net/m0_46168848/article/details/127128405
