-
大数据技术基础实验五:Zookeeper实验——部署ZooKeeper
大数据技术基础实验五:Zookeeper实验——部署ZooKeeper
一、前言
本期我们将学习Hadoop项目下的另一个子项目——ZooKeeper,这个分布式服务框架在我们的后续实验中也会经常用到,它也是Hadoop中一个非常重要的组件。
二、实验目的与要求
- 掌握ZooKeeper集群安装部署,加深对ZooKeeper相关概念的理解,熟练ZooKeeper的一些常用Shell命令。
- 部署三个节点的ZooKeeper集群,通过ZooKeeper客户端连接ZooKeeper集群,并用Shell命令练习创建目录,查询目录等。
三、实验原理
ZooKeeper 分布式服务框架是 Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。
ZooKeeper是以Fast Paxos算法为基础的。
ZooKeeper集群的初始化过程:集群中所有机器以投票的方式(少数服从多数)选取某一台机器作为leader(领导者),其余机器作为follower(追随者)。如果集群中只有一台机器,那么就这台机器就是leader,没有follower。
ZooKeeper集群与客户端的交互:客户端可以在任意情况下ZooKeeper集群中任意一台机器上进行读操作;但是写操作必须得到leader的同意后才能执行。
ZooKeeper选取leader的核心算法思想:如果某服务器获得N/2 + 1票,则该服务器成为leader。N为集群中机器数量。为了避免出现两台服务器获得相同票数(N/2),应该确保N为奇数。因此构建ZooKeeper集群最少需要3台机器。
四、实验步骤
本实验主要介绍ZooKeeper的部署,ZooKeeper一般部署奇数个节点,部署方法包主要含安装JDK、修改配置文件、启动测试三个步骤。
1、安装JDK
学校服务器内已经安装JDK了所以不需要配置,而且一般的云服务器都会自带Java和Python环境,如果是自己本地的虚拟机的话就需要配置环境。
简单的讲一下配置JDK的过程:
- 首先去到Oracle官网下载对应的jdk版本的压缩包
- 然后通过Xftp工具将jdk压缩包上传到虚拟机上
- 然后再虚拟机内解压刚才的jdk压缩包
- 然后就是进入 etc/profile文件内配置jdk环境变量
- 最后重启虚拟机并检查jdk环境是否配置成功
2、修改ZooKeeper配置文件
首先配置master,slave1和slave2之间的免密登录和各虚拟机的/etc/hosts文件,这个步骤请参考我之前的一篇博客,里面有详细过程:
然后修改ZooKeeper的配置文件,步骤如下:
首先进入解压目录下,把conf目录下的zoo_sample.cfg赋值成zoo.cfg文件。
cd /usr/cstor/zookeeper/conf cp zoo_sample.cfg zoo.cfg然后打开zoo.cfg并修改和添加配置项目:
# The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # the port at which the clients will connect clientPort=2181 # the directory where the snapshot is stored. dataDir=/usr/cstor/zookeeper/data dataLogDir=/usr/cstor/zookeeper/log server.1=master:2888:3888 server.2=slave1:2888:3888 server.3=slave2:2888:3888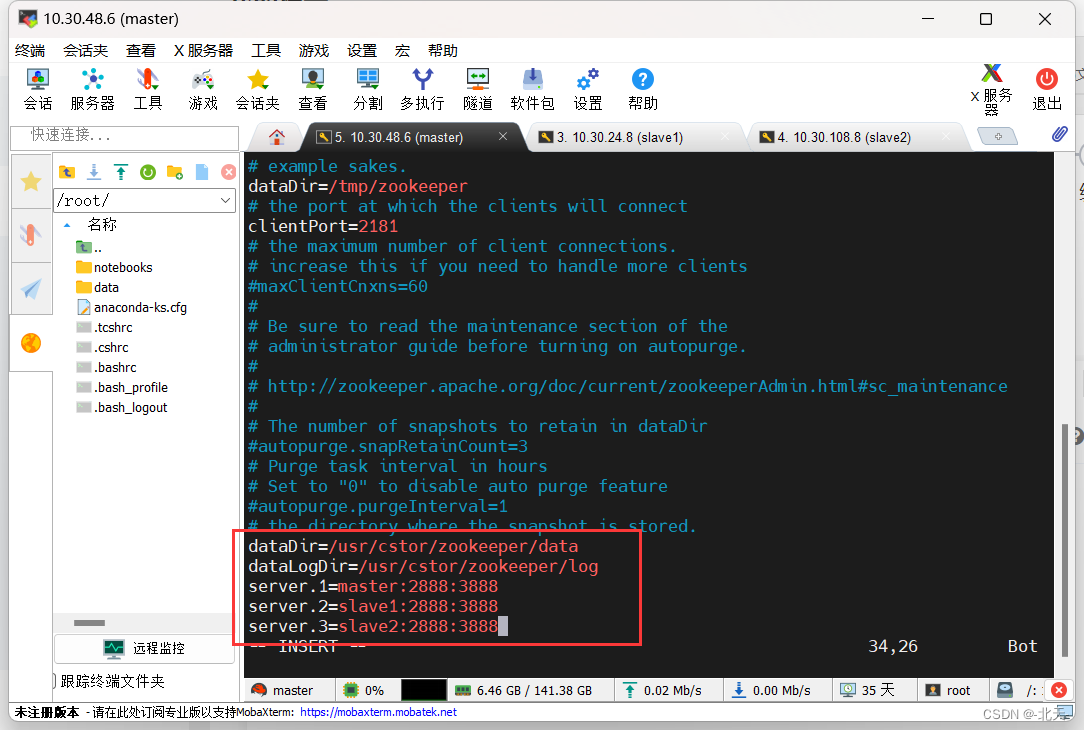
然后新建两个目录:
mkdir /usr/cstor/zookeeper/data mkdir /usr/cstor/zookeeper/log将/usr/cstor/zookeeper目录传到另外两台机器上。
scp -r /usr/cstor/zookeeper root@slave1:/usr/cstor scp -r /usr/cstor/zookeeper root@slave2:/usr/cstor
然后分别在三个节点上的/usr/local/zookeeper/data目录下创建一个文件:myid。
vi /usr/cstor/zookeeper/data/myid分别在myid上按照配置文件的server. 中id的数值,在不同机器上的该文 件中填写相应过的值,如下:
master 的myid内容为1
slave1 的myid内容为2
slave2 的myid内容为3



3、启动ZooKeeper集群
分别在三个节点进入bin目录,启动ZooKeeper服务进程:
cd /usr/cstor/zookeeper/bin ./zkServer.sh start


在各机器上依次执行脚本,查看ZooKeeper状态信息,两个节点是follower状态,一个节点是leader状态:
./zkServer.sh status

在其中一台机器上执行客户端脚本:
./zkCli.sh -server master:2181,slave1:2181,slave2:2181
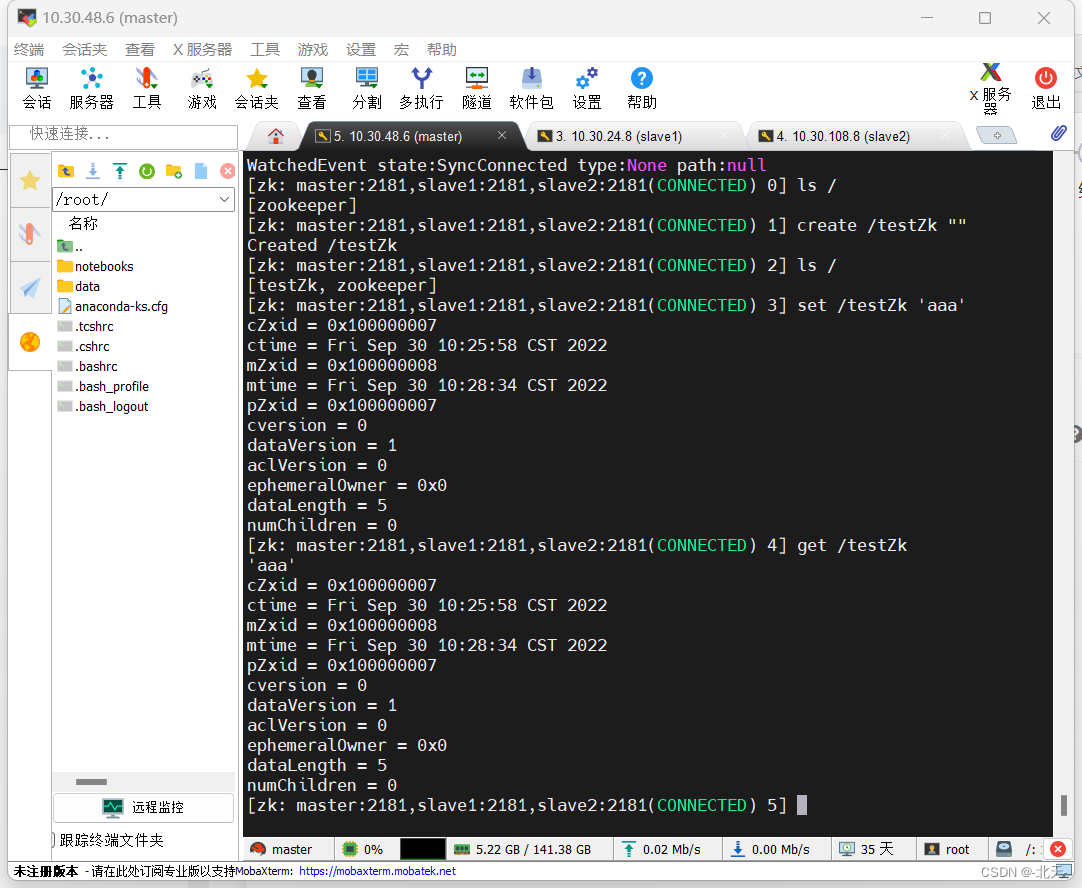
在客户端shell下执行创建目录命令:
create /testZk ""然后再向/testZk目录写数据:
set /testZk 'aaa'然后再读取/testZk目录数据:
get /testZk最后删除/testZk目录并退出客户端:
rmr /testZk quit
4、查看java进程和ZooKeeper集群目录
查看java进程:
- master:

-
slave1:

-
slave2:

查看ZooKeeper集群目录:
五、最后我想说
本期有关ZooKeeper部署的实验就结束了,后续就会开始学习HBase,HBase中也会用到ZooKeeper,所以大家可以多多练习如何成功部署并启动Zookeeper。
-
相关阅读:
建造者模式
postgresql逻辑备份工具pg_dump和pg_resotre学习
python:OderedDict函数
面试算法24:反转链表
常见七大SMD器件布局基本要求,你掌握了几点?
刷爆 LeetCode 双周赛 100,单方面宣布第一题最难
动态内存开辟(上)
Vue中this指向问题
内核实战教程第1期|数据库系统概述,带你走近 OceanBase 研发环境!
点与线段的关系
- 原文地址:https://blog.csdn.net/qq_52417436/article/details/127119864