-
【视觉预训练】《BEIT: BERT Pre-Training of Image Transformers》 ICLR 2022
《BEIT: BERT Pre-Training of Image Transformers》
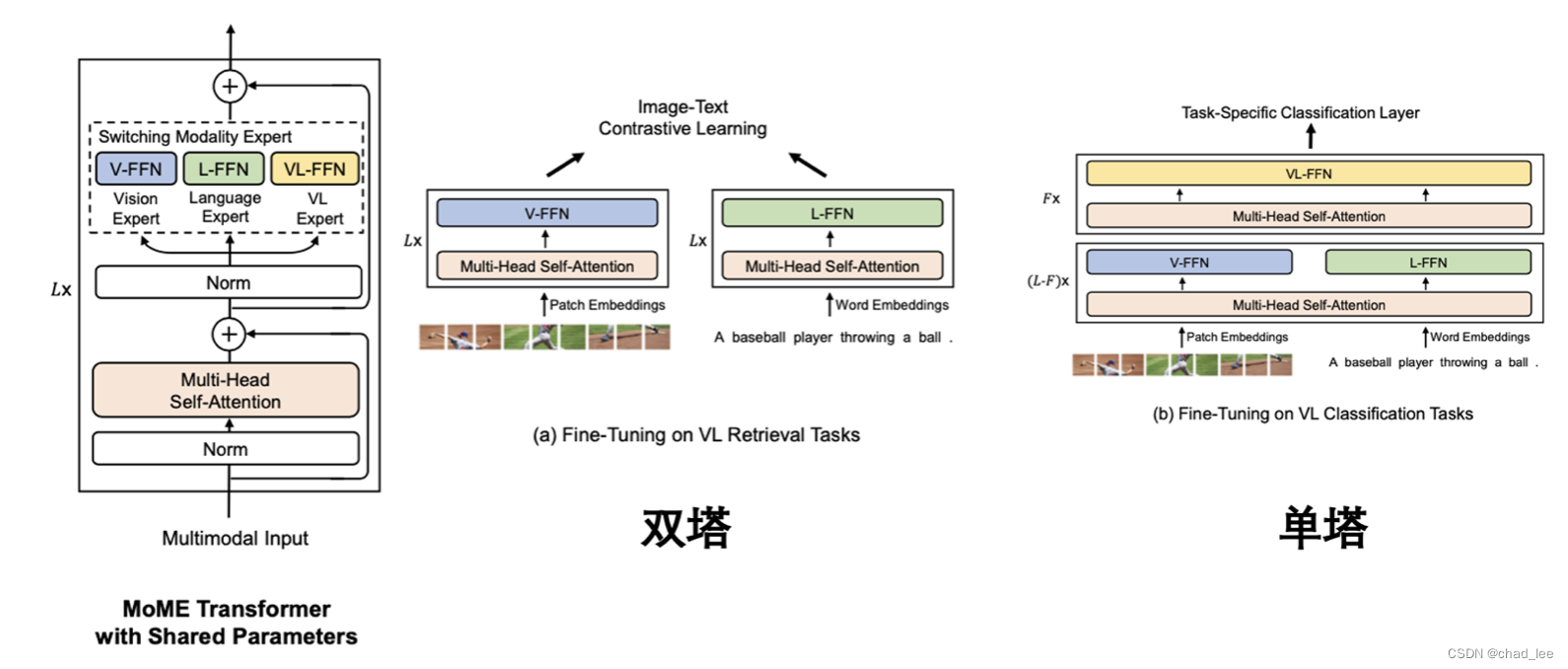
回顾 VLMo
BERT 回顾
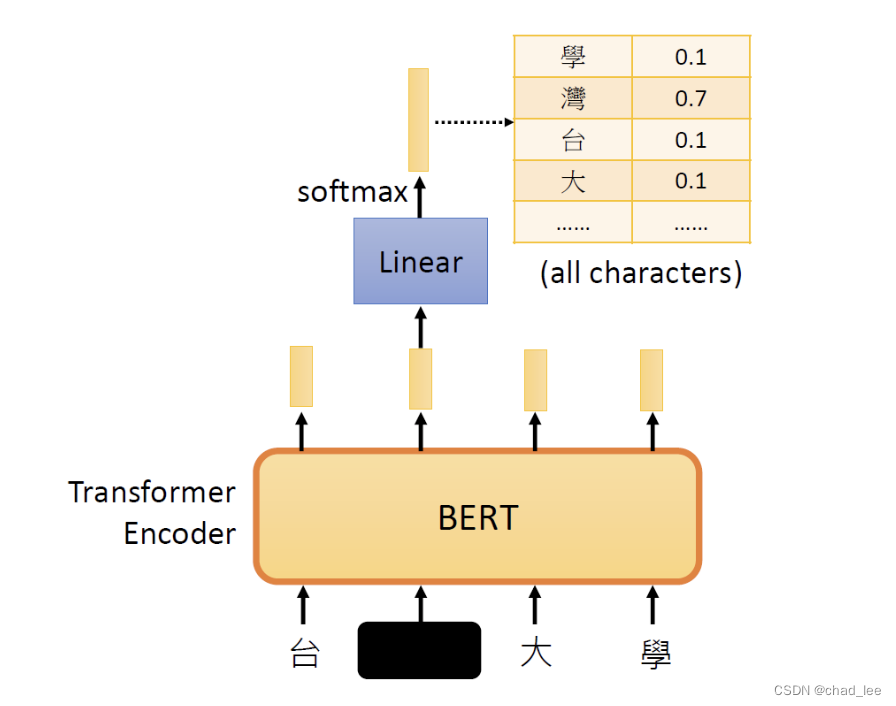
在BERT中,每个单词或者字会分配一个 token,所以模型的输入是一系列 token id。MLM训练方式是 mask 一个位置的token,然后经过BERT之后预测这个位置的 token是什么。由于mask 的位置是我们自己选的,所以我们是有预测任务的 Ground Truth的,因此可以来优化模型参数
BERT应用于视觉任务
BERT应用在视觉任务上最大的困难是:视觉任务没有一个大的词汇表(vocabulary),比如上图 mask “湾”,softmax 预测 “湾” 的token id就好了。但是在CV任务中,mask一块patch,预测的Ground Truth是什么呢?
其实也有Ground Truth,直接恢复原图像patch的pixel。但是这样像素级别的恢复任务的缺点是 把模型的建模能力浪费在了 short-range dependencies 和 high-frequency details
为了解决这个问题,本文提出的这个方法叫做 BEIT,很明显作者是想在 CV 领域做到和 NLP 领域的 BERT 一样的功能。训练好的 BERT 模型相当于是一个 Transformer 的 Encoder,它能够把一个输入的 sentence 进行编码,得到一堆 tokens。 BEIT 也是在做类似的事情,即能够把一个输入的 image 进行编码,得到一堆 vectors,并且这些个 vectors 也结合了 image 的上下文。
模型输入
在 BEIT 眼里,图片有 2 种表示的形式,即可以看作 image patches,又可以看作 visual tokens,在预训练的过程中,它们分别被作为模型的输入和输出,如下图所示:
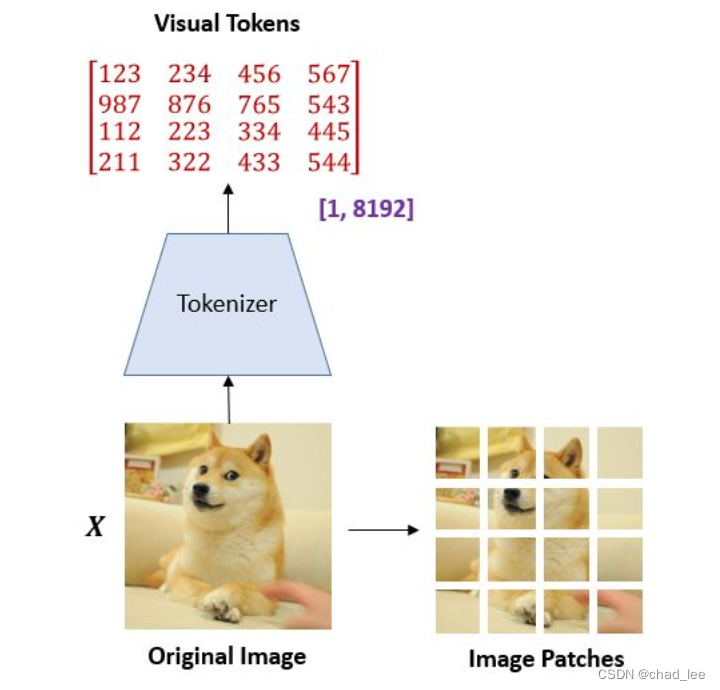
将图片表示为 image patches 这个操作和 Vision Transformer 对图片的处理手段是一致的。将 x ∈ R H × W × C x \in \mathbb{R}^{H \times W \times C} x∈RH×W×C 的图片拉成 x p ∈ R N × ( P 2 C ) x^p \in \mathbb{R}^{N \times\left(P^2 C\right)} xp∈RN×(P2C) 的输入。
然后利用dVAE的 image tokenizer,把一张图片 x ∈ R H × W × C x \in \mathbb{R}^{H \times W \times C} x∈RH×W×C 离散成 tokens z = [ z 1 , … , z N ] ∈ V h × w z=\left[z_1, \ldots, z_N\right] \in \mathcal{V}^{h \times w} z=[z1,…,zN]∈Vh×w,字典 V = { 1 , … , ∣ V ∣ } \mathcal{V}=\{1, \ldots,|\mathcal{V}|\} V={ 1,…,∣V∣} 包含了所有离散索引。具体而言,作者训练了一个 discrete variational autoencoder (dVAE),训练的过程如下:
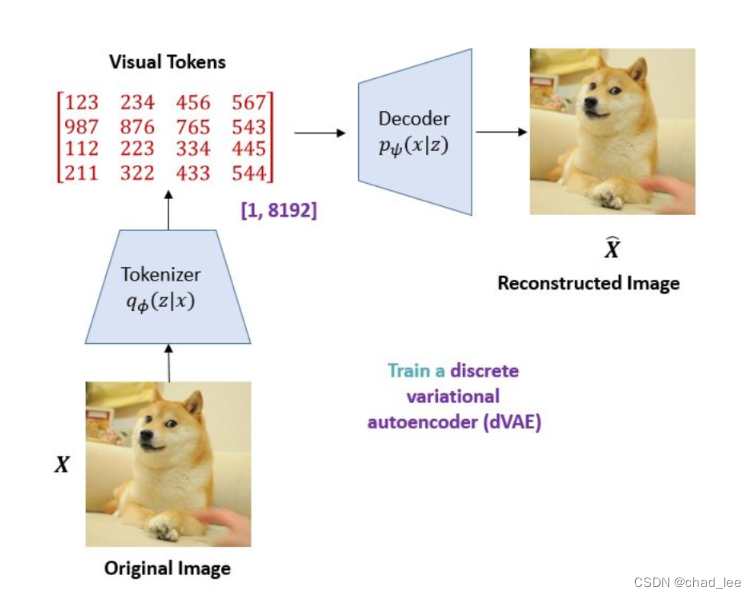
所以一张 224×224 的输入图片通过 Tokenizer 变成了 14×14 个 visual token,每个 visual token 是一个位于[1,8192]之间的数。就像有个 image 的词汇表一样,这个词汇表里面有 8192 个词,每个 16×16 的image patch会经过 Tokenizer 映射成 |V| 里面的一个词。因为 visual token 是离散的数,所以优化时没法求导,所以采用了 gumbel softmax 技巧。
BEIT模型
BEIT 的总体结构如下,BEIT 的 Encoder 结构就是 Transformer 的 Encoder,模型架构是一样的。图片在被分成 N = H W / P 2 N=H W / P^2 N=HW/P2 个展平的2D块 x p ∈ R N × ( P 2 C ) x^p \in \mathbb{R}^{N \times\left(P^2 C\right)} xp∈RN×(P2C) 之后,通过线性变换得到 E x i p \boldsymbol{E} x_i^p Exi
-
相关阅读:
VUE UI组件ui-libs.vercel.app 花了太长时间进行响应怎么解决?
C#开发-集合使用和技巧(八)集合中的排序Sort、OrderBy、OrderByDescending
Golang笔记:使用serial包进行串口通讯
电脑重装系统后wifi间歇性断网该怎么解决
贪心之跳跃
vscode调教配置:快捷修复和格式化代码
【Python&GIS】矢量数据投影转换(坐标转换)
【Leetcode】2418. Sort the People
【深入理解Kotlin协程】协程的创建、启动、挂起函数【理论篇】
面试题 16.16. 部分排序-双指针法
- 原文地址:https://blog.csdn.net/yanguang1470/article/details/127119988