-
手撕code
手撕code
11 迷宫最短路径及路线输出
给定一个 n × m 的二维整数数组,用来表示一个迷宫,数组中只包含 0 或 1 ,其中 0 表示可以走的路,1 表示不可通过的墙壁。
最初,有一个人位于左上角 (1, 1) 处,已知该人每次可以向上、下、左、右任意一个方向移动一个位置。
请问,该人从左上角移动至右下角 ( n, m ) 处,至少需要移动多少次。
数据保证 (1, 1) 处和 ( n, m ) 处的数字为 0 ,且一定至少存在一条通路。
Input
第一行包含两个整数 n 和 m 。1 ≤ n, m ≤ 100
接下来 n 行,每行包含 m 个整数( 0 或 1 ),表示完整的二维数组迷宫。
Output
输出一个整数,表示从左上角移动至右下角的最少移动次数以及移动路径。
Sample Input
5 5
0 1 0 0 0
0 1 0 1 0
0 0 0 0 0
0 1 1 1 0
0 0 0 1 0Sample Output
8
1 1
2 1
3 1
3 2
3 3
3 4
3 5
4 5
5 5dfs
#include#include using namespace std; vector<pair<int, int>> path; //当前搜索到的路径 vector<pair<int, int>> res; //记录的最短的路径 int minLength = INT_MAX; void dfs(vector<vector<int>>& grid, int x, int y, int step) { if (x == grid.size() - 1 && y == grid[0].size() - 1) { //搜索到目的地点 if (res.size() == 0 || res.size() > path.size()) res = path; if (step < minLength) minLength = step; return; } int dx[4] = {0, 1, 0, -1}; //右下左上 int dy[4] = {1, 0, -1, 0}; for (int i = 0; i < 4; i++) { int nx = x + dx[i]; int ny = y + dy[i]; if (nx < 0 || nx >= grid.size() || ny < 0 || ny >= grid[0].size() || grid[nx][ny] != 0) continue;// 边界判定一定要在前面!!! grid[nx][ny] += 5; //将迷宫路径置为其他值 不走重复路 未设置原先的grid[x][y]但是不受影响 在下一个坐标会把x、y覆盖 path.push_back({nx, ny}); dfs(grid, nx, ny, step + 1); //小循环 path.pop_back(); grid[nx][ny] -= 5; //恢复现场 因为有可能其他路与之前的路径会有重叠路径 若不恢复现场 则此次走过的路 在下一个大小循环中不能再走 } } int main() { int row, col; cin >> row >> col; vector<vector<int>> grid(row, vector<int> (col)); for (int i = 0; i < row; i++) { for (int j = 0; j < col; j++) { cin >> grid[i][j]; } } dfs(grid, 0, 0, 0); // 大循环 cout << "minLength is " << minLength << endl; for (int i = 0; i < res.size(); i++) { cout << res[i].first << " " << res[i].second << endl; } system("pause"); return 0; } 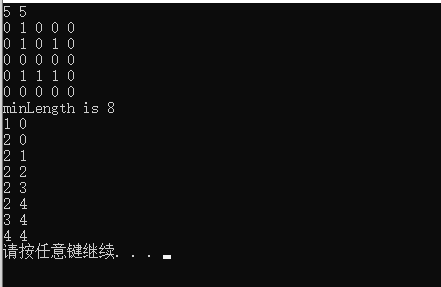
bfs
#include#include #include using namespace std; int minLength = 0; void print(int x,int y, vector<vector<int>>& fax, vector<vector<int>>& fay){ if(x==0 && y==0){ cout << "(" << x << ", " << y << ")" <<endl; return; } print(fax[x][y], fay[x][y], fax, fay); // 从最后一个坐标递归回溯到前一个坐标 cout << "(" << x << ", " << y << ")" << endl; } void bfs(vector<vector<int>>& grid, vector<vector<int>>& visited, int x, int y, vector<vector<int>>& fax, vector<vector<int>>& fay) { queue<pair<int, int>> q; if (grid[x][y] != 0) return; // 判断起点是否合法 q.push(make_pair(x, y)); //队列q中存起点坐标x y //bfs注意一定不能重复走!!!! int dx[4] = {0, 1, 0, -1}; int dy[4] = {1, 0, -1, 0}; while (!q.empty()) { int size = q.size(); for (int i = 0; i < size; i++) { int row = q.front().first; int col = q.front().second; q.pop(); if (row == grid.size() - 1 && col == grid[0].size() - 1) { print(grid.size() - 1, grid[0].size() - 1, fax, fay); return; // 只要遍历到结果一定是最短路 } for (int i = 0; i < 4; i++) { int nx = row + dx[i]; int ny = col + dy[i]; if (nx < 0 || nx >= grid.size() || ny < 0 || ny >= grid[0].size() || grid[nx][ny] != 0 || visited[nx][ny] != 0) continue; visited[nx][ny] = visited[row][col] + 1; // 走过的节点进行赋值 保证不走重复路 可用grid[nx][ny] = 1代替 q.push(make_pair(nx, ny)); fax[nx][ny] = row; fay[nx][ny] = col; } } minLength++; // 代表遍历的层数 } } int main() { int row, col; cin >> row >> col; vector<vector<int>> grid(row, vector<int> (col)); for (int i = 0; i < row; i++) { for (int j = 0; j < col; j++) { cin >> grid[i][j]; } } vector<vector<int>> visited(row, vector<int> (col, 0)); vector<vector<int>> fax(row, vector<int> (col, -1)); vector<vector<int>> fay(row, vector<int> (col, -1)); bfs(grid, visited, 0, 0, fax, fay); cout << "minLength is " << minLength << endl; //或者visited[row - 1][col - 1] cout << "------------------------------------" << endl; for (int i = 0; i < row; i++) { for (int j = 0; j < col; j++) { cout << fax[i][j] << " "; } cout << endl; } cout << "------------------------------------" << endl; for (int i = 0; i < row; i++) { for (int j = 0; j < col; j++) { cout << fay[i][j] << " "; } cout << endl; } system("pause"); return 0; } /* 求输出路径方法 开两个二维数组fax 和 fay 然后 分别记录上一个位置的x 和 y */ 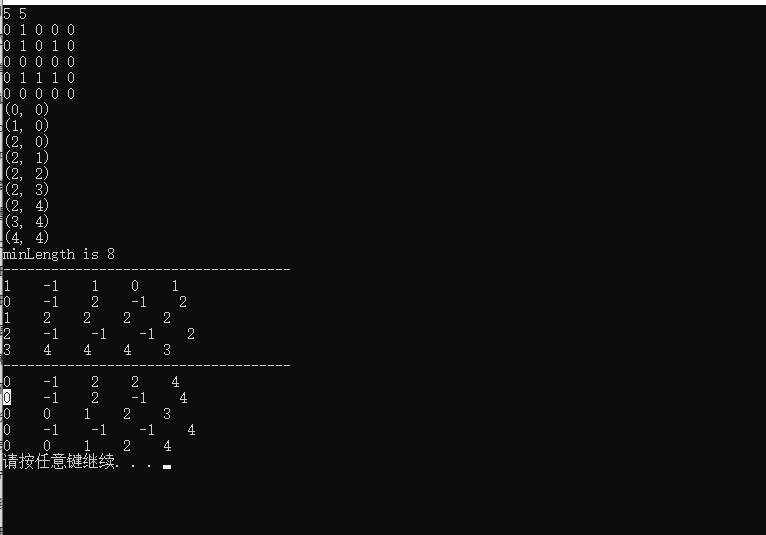
12 线程池
线程池原理
对于web服务器、email服务器以及数据库服务器,都需要在单位时间内处理大量的请求。传统的方法是即时创建,即时销毁,虽然相比于创建进程已经快了很多,但是当线程执行时间较短时,会导致服务器不断忙于创建线程、销毁线程的状态。
线程池的引入减少了创建线程的个数,它采用了预创建的技术,在应用程序启动后,将立即创建一定数量的线程,放到空闲队列中,这些线程都属于阻塞状态,不消耗CPU,但是占用较小的内存空间。当任务到来时,将任务传入线程中执行。当所有线程都在处理任务时,会自动创建一定数量的新线程,用于处理任务,处理完毕后不会退出,在线程池中等待下一次任务。当系统比较空闲,大部分线程处于暂停状态,线程池会自动销毁一部分线程。
线程池,最简单的就是生产者消费者模型了。池里的每条线程,都是消费者,他们消费并处理一个个的任务,而任务队列就相当于生产者了。
线程池最简单的形式是含有一个固定数量的工作线程来处理任务,典型的数量是std::thread::hardware_concurrency()。
创建前提:线程本身的开销与线程执行任务相比不可忽略。
如果线程本身的开销相对于线程任务执行开销而言是可以忽略不计的,那么此时线程池所带来的好处是不明显的,比如对于FTP服务器以及Telnet服务器,通常传送文件的时间较长,开销较大,那么此时,我们采用线程池未必是理想的方法,我们可以选择“即时创建,即时销毁”的策略。
适用场景:
(1)单位时间内处理任务频繁而且任务处理时间短
(2)对实时性要求较高。如果接受到任务后再创建线程,可能满足不了实时要求,因此必须采用线程进行预创建。
简单线程池代码
参考链接:
https://blog.csdn.net/leacock1991/article/details/109779578?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522166432946816782412579013%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=166432946816782412579013&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_ecpm_v1~rank_v31_ecpm-9-109779578-null-null.nonecase&utm_term=%E7%BA%BF%E7%A8%8B%E6%B1%A0c%2B%2B&spm=1018.2226.3001.4450源码:
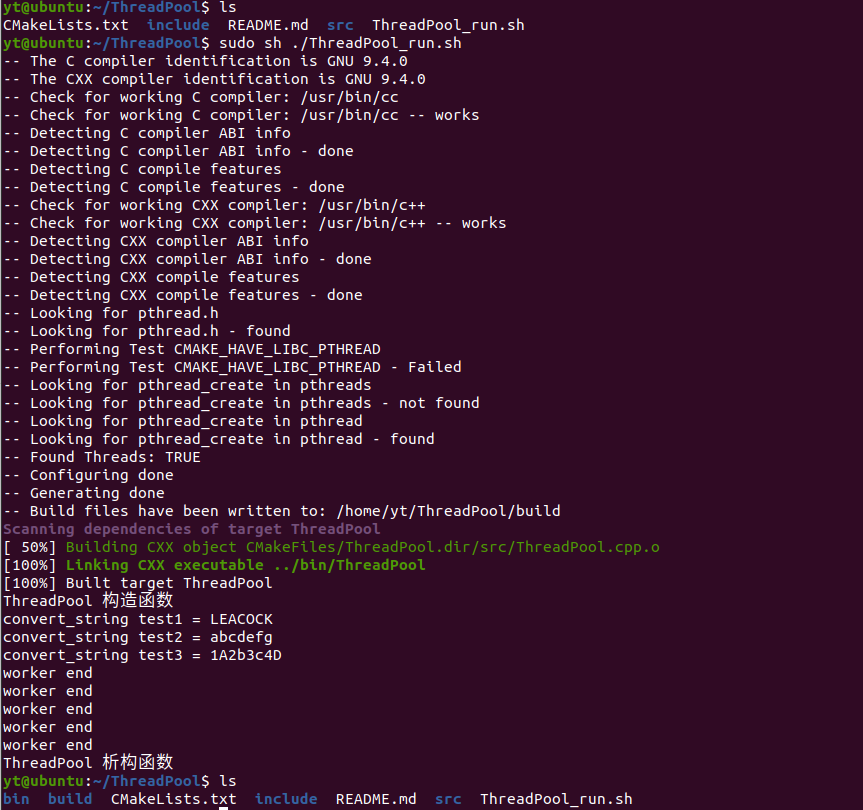
#include#include #include #include #include #include /// 对任务进行封装, 线程池中见到的就是一个个任务类 class Task { public: /// 构造函数 将传入的具体执行函数 与 参数 打包成一个处理任务,这里需要使用 可变参函数模板 ///参看 https://www.cnblogs.com/qicosmos/p/4325949.html /// template explicit Task(Func_T func, ARGS ...args) { /// 将 传入的 函数 参数 bind 到 function实例 /// std::forward 保持类型信息, 参见 https://blog.csdn.net/coolwriter/article/details/80970718 this->func = std::bind(func, std::forward (args)...); /// this->func = std::bind(func, args...); } void run() { this->func(); } /// 类模版std::function是一种通用、多态的函数封装 参见 https://blog.csdn.net/hzy925/article/details/79676085 /// std::function的实例可以对任何可以调用的目标实体进行存储、复制、和调用操作,这些目标实体包括普通函数、Lambda表达式、函数指针、以及其它函数对象等。 /// 这里实例 目标实体 是个 函数 std::function > class ThreadPool { public: /// 构造函数 创建 n 个线程 explicit ThreadPool(size_t n){ std::cout << "ThreadPool 构造函数" < #include#include #include "ThreadPool.hpp" char convert_char(char c) { if ( 'A' <= c && c <= 'Z') return c + 32; // 转换小写 else if ( 'a' <= c && c <= 'z') return c - 32; // 转换大写 else return c; // 其他不变 } void convert_string(const int lengh, char* buff ) { for (int i = 0; i < lengh; ++i) { buff[i] = convert_char(buff[i]); } } 测试任务封装 //int main() { // std::cout << "Hello, World!" << std::endl; // char test[1024] = "leacock"; // int len = strlen(test); // Task t1(convert_string, len, test), // t2(convert_string, len, test); // t1.run(); // std::cout << "t1.run() , test = " << test << std::endl; // t2.run(); // std::cout << "t2.run() , test = " << test << std::endl; // return 0; //} // 测试任务封装 int main() { /// 队列可以自己实现 ThreadPool<std::queue<Task *>> tp(5); std::this_thread::sleep_for(std::chrono::seconds(2)); char test1[24] = "leacock"; char test2[24] = "ABCDEFG"; char test3[24] = "1a2B3C4d"; tp.addOneTask(new Task(convert_string, strlen(test1), test1)); tp.addOneTask(new Task(convert_string, strlen(test2), test2)); tp.addOneTask(new Task(convert_string, strlen(test3), test3)); std::this_thread::sleep_for(std::chrono::seconds(2)); std::cout << "convert_string test1 = " << test1 << std::endl; std::cout << "convert_string test2 = " << test2 << std::endl; std::cout << "convert_string test3 = " << test3 << std::endl; return 0; } 运行结果:

13 内存池
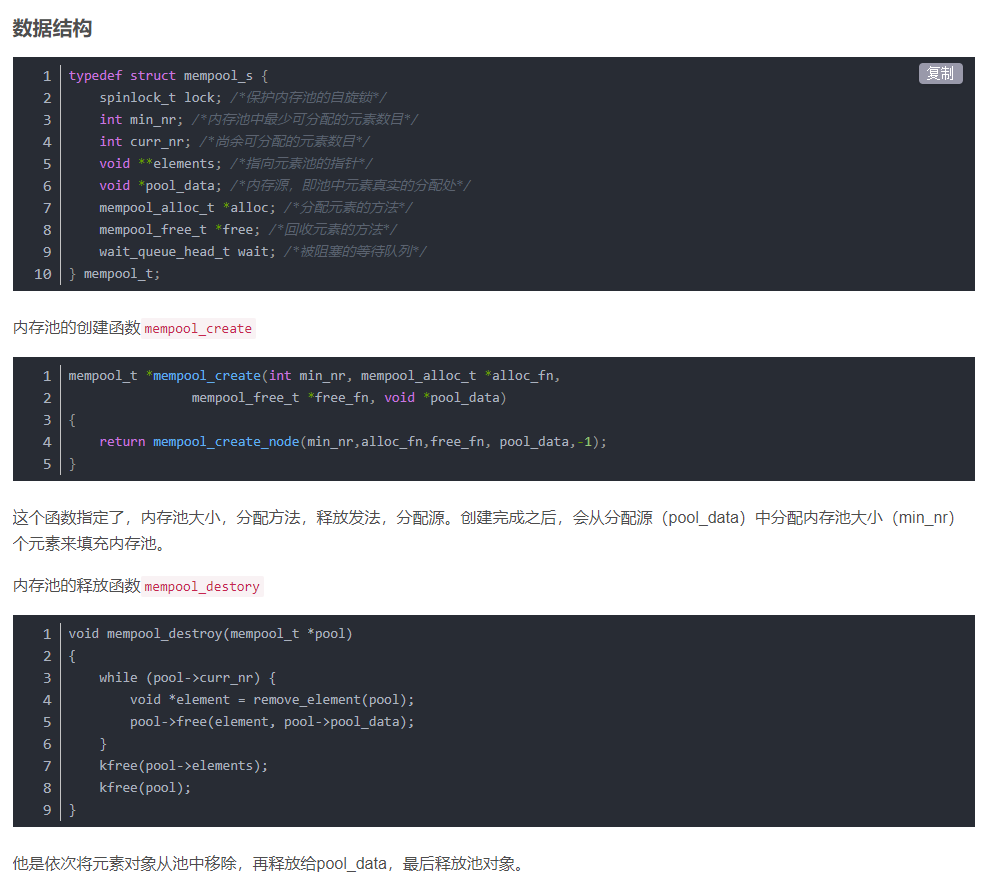
内存池原理
程序可以通过系统的内存分配方法预先分配一大块内存来做一个内存池,之后程序的内存分配和释放都由这个内存池来进行操作和管理,当内存池不足时再向系统申请内存。
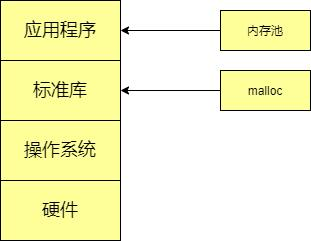
我们通常使用malloc等函数来为用户进程分配内存。它的执行过程通常是由用户程序发起malloc申请内存的动作,在标准库找到对应函数,对不满128k的调用brk()系统调用来申请内存(申请的内存是堆区内存),接着由操作系统来执行brk系统调用。
我们知道malloc是在标准库,真正的申请动作需要操作系统完成。所以由应用程序到操作系统就需要3层。内存池是专为应用程序提供的专属的内存管理器,它属于应用程序层。所以程序申请内存的时候就不需要通过标准库和操作系统,明显降低了开销。
工作原理
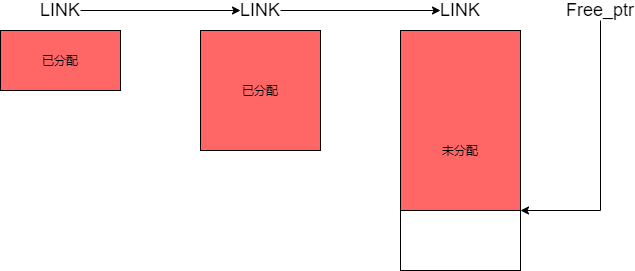
固定内存池的内存块实际上是由链表连接起来的,前一个总是后一个的2倍大小。当内存池的大小不够分配时,向系统申请内存,大小为上一个的两倍,并且使用一个指针来记录当前空闲内存单元的位置。当我们要需要一个内存单元的时候,就会随着链表去查看每一个内存块的头信息,如果内存块里有空闲的内存单元,将该地址返回,并且将头信息里的空闲单元改成下一个空闲单元。
当应用程序释放某内存单元,就会到对应的内存块的头信息里修改该内存单元为空闲单元。Linux内存池
在内核中有不少地方内存分配不允许失败。内存池作为一个在这些情况下确保分配的方式,内核开发者创建了一个已知为内存池(或者是 “mempool” )的抽象,内核中内存池真实地只是相当于后备缓存,它尽力一直保持一个空闲内存列表给紧急时使用,而在通常情况下有内存需求时还是从公共的内存中直接分配,这样的做法虽然有点霸占内存的嫌疑,但是可以从根本上保证关键应用在内存紧张时申请内存仍然能够成功。
参考链接
https://blog.csdn.net/weixin_48101150/article/details/121336318?ops_request_misc=&request_id=&biz_id=102&utm_term=%E5%86%85%E5%AD%98%E6%B1%A0&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-0-121336318.nonecase&spm=1018.2226.3001.4187
14 二分查找
升序、无重复数组的二分查找(迭代写法)
class Solution { public: int search(vector<int>& nums, int target) { int left = 0, right = nums.size() - 1; while (left <= right) { int mid = left + (right - left) / 2; if (nums[mid] > target) { right = mid - 1; } else if (nums[mid] < target) { left = mid + 1; } else { return mid; } } return -1; } };
升序、有重复数组的二分查找
class Solution { public: vector<int> searchRange(vector<int>& nums, int target) { int leftBorder = getLeftBorder(nums, target); int rightBorder = getRightBorder(nums, target); if (leftBorder == -2 || rightBorder == -2) return {-1, -1}; if (rightBorder - leftBorder > 1) return {leftBorder + 1, rightBorder - 1}; return {-1, -1}; } private: int getLeftBorder(vector<int>& nums, int target) { int left = 0; int right = nums.size() - 1; int leftBorder = -2; while (left <= right) { int mid = left + (right - left) / 2; if (nums[mid] < target) { left = mid + 1; } else { right = mid - 1; leftBorder = right; } } return leftBorder; } int getRightBorder(vector<int>& nums, int target) { int left = 0, right = nums.size() - 1; int rightBorder = -2; while (left <= right) { int mid = left + (right - left) / 2; if (nums[mid] <= target) { left = mid + 1; rightBorder = left; } else { right = mid - 1; } } return rightBorder; } };15 链表
单链表
#includeusing namespace std; class MyLinkedList { public: struct ListNode { int val; ListNode* next; ListNode(int val) : val(val) , next(nullptr) {} }; MyLinkedList() { node_ = new ListNode(0); size_ = 0; } int get(int index) { if (index >= size_ || index < 0) return -1; ListNode* cur = node_; while (index--) { cur = cur->next; } cur = cur->next; return cur->val; } void addAtHead(int val) { ListNode* newNode = new ListNode(val); newNode->next = node_->next; node_->next = newNode; size_++; } void addAtTail(int val) { ListNode* newNode = new ListNode(val); ListNode* cur = node_; while (cur->next != nullptr) { cur = cur->next; } cur->next = newNode; size_++; } void addAtIndex(int index, int val) { if (index > size_ || index < 0) return; // index可以为size_ ListNode* newNode = new ListNode(val); ListNode* cur = node_; while (index--) { cur = cur->next; } newNode->next = cur->next; cur->next = newNode; size_++; } void deleteAtIndex(int index) { if (index >= size_ || index < 0) return; ListNode* cur = node_; while (index--) { cur = cur->next; } ListNode* temp = cur->next; cur->next = cur->next->next; delete temp; size_--; } void show() { ListNode* cur = node_->next; while (cur != nullptr) { cout << cur->val << " "; cur = cur->next; } cout << endl; } private: int size_; ListNode* node_; }; int main() { MyLinkedList link; link.addAtHead(7); link.addAtHead(2); link.addAtHead(1); link.addAtTail(8); link.show(); link.deleteAtIndex(2); link.show(); system("pause"); return 0; } 
双链表
双向链表
#includeusing namespace std; struct Node { int data_; Node* pre_; Node* next_; Node(int data) : data_(data) , pre_(nullptr) , next_(nullptr) {} Node() { pre_ = nullptr; next_ = nullptr; } }; class DoubleLink { public: DoubleLink() { head_ = new Node(); } ~DoubleLink() { Node* p = head_; while (p != nullptr) { head_ = head_->next_; delete p; p = head_; } } public: void insert_head(int val) { Node* node = new Node(val); node->next_ = head_->next_; node->pre_ = head_; if (head_->next_ != nullptr) head_->next_->pre_ = node; //原来链表里有第一个节点 确认head后面一个不为空 head_->next_ = node; } // 尾插法 void InsertTail(int val) { Node* p = head_; while (p->next_ != nullptr) { p = p->next_; } Node* node = new Node(val); node->pre_ = p; p->next_ = node; } void Remove(int val) { Node* p = head_->next_; while (p != nullptr) { if (p->data_ == val) { p->pre_->next_ = p->next_; if (p->next_ != nullptr) p->next_->pre_ = p->pre_; delete p; return; } else { p = p->next_; } } } bool Find(int val) { Node* p = head_->next_; while (p != nullptr) { if (p->data_ == val) { return true; } else { p = p->next_; } } } void show() { Node* p = head_->next_; while (p != nullptr) { cout << p->data_ << " "; p = p->next_; } cout << endl; } private: Node* head_; }; int main() { DoubleLink dlink; dlink.InsertTail(20); dlink.InsertTail(23); dlink.InsertTail(89); dlink.InsertTail(15); dlink.InsertTail(36); dlink.InsertTail(78); dlink.InsertTail(56); dlink.InsertTail(41); dlink.InsertTail(32); dlink.show(); dlink.insert_head(200); dlink.show(); dlink.Remove(200); dlink.show(); dlink.Remove(78); dlink.show(); system("pause"); return 0; } 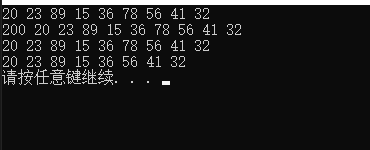
双向循环链表
#includeusing namespace std; struct Node { int data_; Node* pre_; Node* next_; Node(int data) : data_(data) , pre_(nullptr) , next_(nullptr) {} Node() { pre_ = nullptr; next_ = nullptr; } }; class DoubleCircleLink { public: DoubleCircleLink() { head_ = new Node(); head_->next_ = head_; head_->pre_ = head_; } ~DoubleCircleLink() { Node* p = head_->next_; while (p != head_) { head_->next_ = p->next_; p->next_->pre_ = head_; delete p; p = head_->next_; } delete head_; head_ = nullptr; } public: void insert_head(int val) { Node* node = new Node(val); node->next_ = head_->next_; node->pre_ = head_; if (head_->next_ != nullptr) head_->next_->pre_ = node; //原来链表里有第一个节点 确认head后面一个不为空 head_->next_ = node; } // 尾插法 void InsertTail(int val) { Node* p = head_->pre_; Node* node = new Node(val); node->pre_ = p; p->next_ = node; node->next_ = head_; head_->pre_ = node; } void Remove(int val) { Node* p = head_->next_; while (p != head_) { if (p->data_ == val) { p->pre_->next_ = p->next_; p->next_->pre_ = p->pre_; delete p; return; } else { p = p->next_; } } } bool Find(int val) { Node* p = head_->next_; while (p != head_) { if (p->data_ == val) { return true; } else { p = p->next_; } } } void show() { Node* p = head_->next_; while (p != head_) { cout << p->data_ << " "; p = p->next_; } cout << endl; } private: Node* head_; }; int main() { DoubleCircleLink dlink; dlink.InsertTail(20); dlink.InsertTail(23); dlink.InsertTail(89); dlink.InsertTail(15); dlink.InsertTail(36); dlink.InsertTail(78); dlink.InsertTail(56); dlink.InsertTail(41); dlink.InsertTail(32); dlink.show(); dlink.insert_head(200); dlink.show(); dlink.Remove(200); dlink.show(); dlink.Remove(78); dlink.show(); system("pause"); return 0; } 
-
相关阅读:
29-Gin框架中间件详解
记录:树莓派 安装opencv 完整的艰辛过程
使用MTR排查网络
IDEA中debug启动报错Method breakpoints may dramatically slow down debugging
C++简单实现红黑树
Item 38: Be aware of varying thread handle destructor behavior.
【服务器数据恢复】华为某型号服务器raid6数据恢复案例
Rust模式匹配
UE5在UI上播放视频带声音的解决方案
智能车电磁组元素处理(圆环、三岔、路障)
- 原文地址:https://blog.csdn.net/qq_41945053/article/details/127119575