-
C++之STL基础概念、容器、数据结构
目录
什么是STL?
全英文是standard template library,标准模板库
下面说一下stl的几个特点:
1.内置在c++编译中,不需要额外内容
2.不需要了解具体实现,只需要会用就可以
3.高复用性,可移植性,高性能
STL六大组件
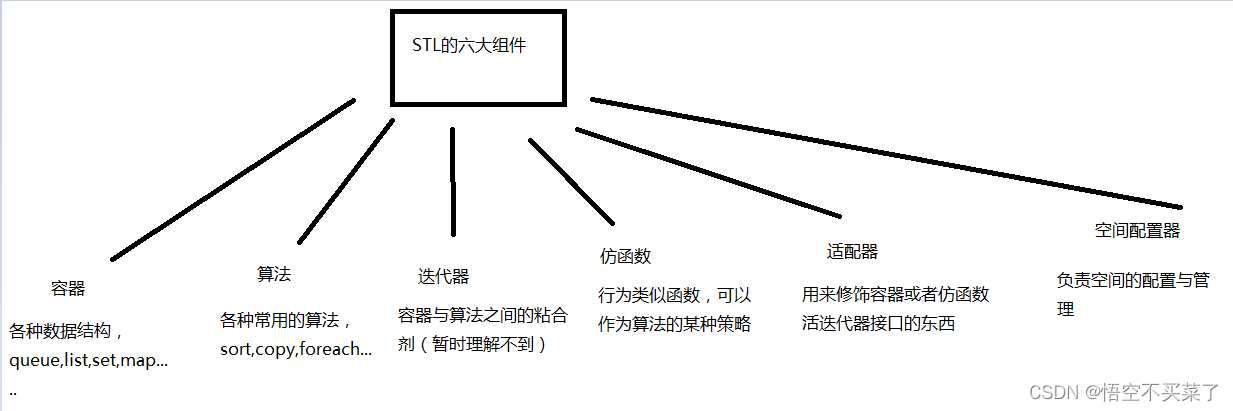
说一下这六大组件的依赖关系
容器通过空间配置器获得数据的存储空间,算法通过迭代器存储容器中的内容,仿函数协助算法完成不同的策略变化,适配器可以修饰仿函数
容器的划分、算法、迭代器种类
容器的划分
1.序列式容器
强调对值的排序,在这个容器中每个元素都有固定位置,除非通过删除或者插入改变这个位置
比如vector容器、Deque容器、list容器
2.关联式容器(有个key起到了索引作用)
非线性结构,类似于二叉树的结构,每一个元素没有明显物理上的关系,关联式容器有一个最大的特点就是,就是在这个值里面选择一个作为关键字,这个关键字对值起到索引作用,方便查找。比如multiset容器、multimap容器
算法
1.质变算法
这个是在运算过程中,会更改元素内容,比如拷贝、替换、删除
2.非质变算法
在运算过程中,不会更改元素内容,比如查找、计数、遍历
迭代器的种类

vector容器
vector是一个不定长的数组,它封装了一些常用的操作,可以把看成一个模板类
定义一个vector容器:vector
v,这个数据类型就是在我们定义的时候指定的 常见的方法:
1.指向容器第一个元素的迭代器,可以理解成为一个指针
vector
::iteratror itBegin = v.begin(); 2.指向容器最后一个元素的下一个位置,这也可以理解成为一个指针
vector
::iterator itEnd = v.end(); 3.利用algorithm头文件中的for_each来遍历容器

上面的意思就是传入两个迭代器,然后传入一个处理方法的函数,这个函数,会去反复调用然后去处理容器中的每一个元素
4.利用v.size()可以获取容器中当前元素的个数
5.利用v.resize()可以改变容器大小
6.v.push_back()可以向尾部添加相应的元素
7.v.pop_back()删除最后一个元素
vector容器的常用操作
1.vector容器构造函数
vectorv; //采用模板实现类实现,默认构造函数
vector(v.begin(), v.end());//将v[begin(), end())区间中的元素拷贝给本身。
vector(n, elem);//构造函数将n个elem拷贝给本身。
vector(const vector &vec);//拷贝构造函数。//例子 使用第二个构造函数 我们可以...
int arr[] = {2,3,4,1,9};//迭代器就是一个指向数据元素的指针
vectorv1(arr, arr + sizeof(arr) / sizeof(int)); 2.vector容器常用操作
assign(beg, end);//将[beg, end)区间中的数据拷贝赋值给本身。
assign(n, elem);//将n个elem拷贝赋值给本身。
vector& operator=(const vector &vec);//重载等号操作符
swap(vec);// 将vec与本身的元素互换。3.vector容器大小操作
size();//返回容器中元素的个数
empty();//判断容器是否为空
resize(int num);//重新指定容器的长度为num,若容器变长,则以默认值填充新位置。如果容器变短,则末尾超出容器长度的元素被删除。
resize(int num, elem);//重新指定容器的长度为num,若容器变长,则以elem值填充新位置。如果容器变短,则末尾超出容器长>度的元素被删除。
capacity();//容器的容量
reserve(int len);//容器预留len个元素长度,预留位置不初始化,元素不可访问。
reverse 翻转
4.vector容器数据存取操作
at(int idx); //返回索引idx所指的数据,如果idx越界,抛出out_of_range异常。
operator[];//返回索引idx所指的数据,越界时,运行直接报错
front();//返回容器中第一个数据元素
back();//返回容器中最后一个数据元素
*/测试代码
- #include
- #include
- #include
- using namespace std;
- //打印vector容器的函数
- void print_vector(vector<int> v)
- {
- vector<int>::iterator it_begin = v.begin();
- vector<int>::iterator it_end = v.end();
- //采用for循环的方式
- for(it_begin;it_begin != it_end;it_begin++) {
- printf("%d ",*it_begin);
- }
- }
- void test01()
- {
- vector<int> v1;
- //添加元素
- v1.push_back(2);
- v1.push_back(8);
- v1.push_back(10);
- v1.push_back(9);
- //v1赋值给v2
- vector<int>v2(v1);
- //将v1赋值给v3
- vector<int>v3(v1.begin(),v1.end());
- print_vector(v1);
- printf("\n------------\n");
- print_vector(v2);
- printf("\n------------\n");
- //重新指定容器长度
- v1.resize(10,100);//后面这个100就是默认值,这里设置了十个长度,不够的用默认值填充
- print_vector(v1);//打印v1这个容器
- //现在重亲指定一下长度
- v1.resize(3);//这个时候超出长度的数据,会被截取
- //重新打印
- printf("\n--------------\n");
- print_vector(v1);//只保留前三个元素
- }
- int main()
- {
- test01();
- return 0;
- }
string容器
这个容器是放在头文件string里面,常见的也是如下操作
1.构造函数








string查找和替换
int find(const string& str, int pos = 0) const; //查找str第一次出现位置,从pos开始查找
int find(const char* s, int pos = 0) const; //查找s第一次出现位置,从pos开始查找
int find(const char* s, int pos, int n) const; //从pos位置查找s的前n个字符第一次位置
int find(const char c, int pos = 0) const; //查找字符c第一次出现位置
int rfind(const string& str, int pos = npos) const;//查找str最后一次位置,从pos开始查找
int rfind(const char* s, int pos = npos) const;//查找s最后一次出现位置,从pos开始查找
int rfind(const char* s, int pos, int n) const;//从pos查找s的前n个字符最后一次位置
int rfind(const char c, int pos = 0) const; //查找字符c最后一次出现位置
string& replace(int pos, int n, const string& str); //替换从pos开始n个字符为字符串str
string& replace(int pos, int n, const char* s); //替换从pos开始的n个字符为字符串s
//替换
//string& replace(int pos, int n, const string& str); //替换从pos开始n个字符为字符串str
str.replace(1, 3, "11111");
//a11111efgdestring比较操作
compare函数在>时返回 1,<时返回 -1,==时返回 0。
比较区分大小写,比较时参考字典顺序,排越前面的越小。
大写的A比小写的a小。int compare(const string &s) const;//与字符串s比较
int compare(const char *s) const;//与字符串s比较string子串
string substr(int pos = 0, int n = npos) const;//返回由pos开始的n个字符组成的字符串
compare函数在>时返回 1,<时返回 -1,==时返回 0。
比较区分大小写,比较时参考字典顺序,排越前面的越小。
大写的A比小写的a小。int compare(const string &s) const;//与字符串s比较
int compare(const char *s) const;//与字符串s比较

deque容器
deque容器:这个把它和vector容器进行对比,大部分用法都相同。
不同点在于就是,deque是一个双端数组,头插与尾插的速度会比较快一些
对于vector容器来说,头部插入是非常慢的,尾部插入输入正常,因为它相当于就是涉及到数组的大量移动

set集合容器
每个元素最多只出现一次,并且是从小到大排序
set构造函数
setst;//set默认构造函数:
mulit setmst; //multiset默认构造函数: set(const set &st);//拷贝构造函数
set赋值操作
set& operator=(const set &st);//重载等号操作符
swap(st);//交换两个集合容器
set大小操作
size();//返回容器中元素的数目
empty();//判断容器是否为空set插入和删除操作
insert(elem);//在容器中插入元素。
clear();//清除所有元素
erase(pos);//删除pos迭代器所指的元素,返回下一个元素的迭代器。
erase(beg, end);//删除区间[beg,end)的所有元素 ,返回下一个元素的迭代器。
erase(elem);//删除容器中值为elem的元素。
set查找操作
find(key);//查找键key是否存在,若存在,返回该键的元素的迭代器;若不存在,返回set.end();
count(key);//查找键key的元素个数
lower_bound(keyElem);//返回第一个key>=keyElem元素的迭代器。(也就是指针位置)
upper_bound(keyElem);//返回第一个key>keyElem元素的迭代器。
equal_range(keyElem);//返回容器中key与keyElem相等的下上限的两个迭代器。这里我们穿插一下pair对组的一种常见的创建方式

可以当成一个只有两个属性的对象处理,默认调用了一个构造方法为两个属性赋值,这两个属性是不是都是泛型呢,也就是一个T的类型,你传的时候,可以传入相应的类型。
下面还有另外一种方式来创建pair对组对象

上面就是利用了一个make_pair的方法来创建一个对组
下面我们直接上一段测试代码
- #include
- #include
- #include
//这个头文件才包含了set容器 - #include
- using namespace std;
- //打印一下容器
- //这里说的是set容器
- void print_set(set<int>&s)
- {
- for(set<int>::iterator it = s.begin();it != s.end();it++) {
- printf("%d ",*it);
- }
- printf("\n-----------\n");
- }
- //主要测试equal_range(key_elem)的用法
- //返回与key_elem上下限迭代器 上限>key_elem第一个元素
- //下限>=key_elem的第一个元素
- void test01()
- {
- set<int>s;
- //下面插入一些数据
- s.insert(10);
- s.insert(50);
- s.insert(30);
- s.insert(20);
- s.insert(40);
- //打印一下这个数据
- print_set(s);
- //因为这里涉及到多个元素,利用对组来保存多个元素
- pair
- //对组可以接收两个数据
- //打印规则两个属性第一个first 第二个second
- //先找下限lower_bound
- if(ret.first != s.end()) {
- printf("%d ",*ret.first);
- } else {
- printf("找不到\n");
- }
- //在找上限up
- if(ret.second != s.end()) {
- printf("%d ",*ret.second);
- } else {
- printf("没有找到\n");
- }
- }
- int main()
- {
- test01();
- return 0;
- }
运行结果:

map映射集合容器
从key到value的映射
map构造函数
map
map(const map &mp);//拷贝构造函数
map赋值操作
map& operator=(const map &mp);//重载等号操作符
swap(mp);//交换两个集合容器map大小操作
size();//返回容器中元素的数目
empty();//判断容器是否为空
map插入数据元素操作
map.insert(...); //往容器插入元素,返回pair
map
// 第一种 通过pair的方式插入对象
mapStu.insert(pair
// 第二种 通过pair的方式插入对象
mapStu.inset(make_pair(-1, "校长"));
// 第三种 通过value_type的方式插入对象
mapStu.insert(map
// 第四种 通过数组的方式插入值
mapStu[3] = "小刘";
mapStu[5] = "小王";map集合不能插入相同的键,不然前面的键值会覆盖后面的键值
- #include
- #include
- #include
- using namespace std;
- //打印map集合
- void print_map(map<int,int>m)
- {
- for(map<int,int>::iterator it = m.begin();it != m.end();it++) {
- printf("%d->%d\n",it->first,it->second);
- }
- printf("\n-----------\n");
- }
- void test01()
- {
- //创建一个map集合对象
- map<int,int> m;
- //下面用四种方式插入一下数据
- //通过pair方式插入对象
- m.insert(pair<int,int>(2,20));
- m.insert(pair<int,int>(4,80));
- print_map(m);
- //下面用另外一种方法插入数据
- //通过make_pair来创建map集合
- m.insert(make_pair(8,90));
- m.insert(make_pair(10,340));
- //下面还是利用迭代器遍历出来
- /*for(map
- //也就是打印对组中的内容
- //内部就是一个pair对象嘛
- //printf("%d %d\n",it->first,it->second);
- printf("%d %d\n",(*it).first,(*it).second);
- }*/
- //调用打印函数
- print_map(m);
- //第三种方式
- m.insert(map<int,int>::value_type(11,90));
- //第四种插入方式,直接用数组进行赋值
- m[19] = 30;
- //上面这种方式,如果我们访问一个没有指定的key,就会默认生成一个value为0的值
- print_map(m);
- }
- int main()
- {
- test01();
- return 0;
- }
运行结果:
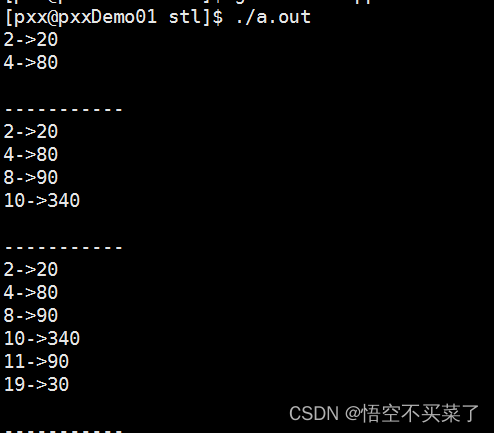
STL提供的3种特殊数据结构
1.栈
stack构造函数
stackstkT;//stack采用模板类实现, stack对象的默认构造形式:
stack(const stack &stk);//拷贝构造函数
stack赋值操作
stack& operator=(const stack &stk);//重载等号操作符
stack数据存取操作
push(elem);//向栈顶添加元素
pop();//从栈顶移除第一个元素
top();//返回栈顶元素
stack大小操作
empty();//判断堆栈是否为空
size();//返回堆栈的大小
*/2.queue队列容器

3.优先对列
优先队列的说的简单一点就是一种按照某种规定排序的队列,本质上来说,它是一个堆,用数组来模拟的完全二叉树
它的默认排序是从大到小的一个比较规则,也就是大顶堆,也就是数值越大优先级就越高,当然,我们还可以通过改变规则换成小顶堆,也就是数值越小,优先级越高。换句话说,在我们输入一组数据当中,这组数据必须要有相应的比较规则,如果数据本身没有显著的比较规则,比如他不是int类型,它是一个struct类型,就要进行运算符重载,来添加相应的比较规则。
上面就是一些文字描述,下面说一下具体实操。
1.优先队列的头文件也是
它的定义priority_queue
que,就是一个模板类 2.说一些具体的处理方法
size()元素数量
push插入
pop 删除优先级高的元素(默认,你没有改变规则的时候),没有返回
top 访问优先级别最高的元素(默认,你没有改变规则的时候),返回值
empty()判断是否为空
先上测试代码
demo10.cpp
- #include
- #include
- #include
- #include
//包含一个优先队列在里面 - using namespace std;//你要是不加std,就会提示一个priority_queue的一个未声明
- //简单来说这个优先队列的声明和这个std作用域还是有一定的关系
- int main()
- {
- priority_queue<int> que;
- que.push(5);
- que.push(8);
- que.push(10);
- que.push(7);
- que.push(21);
- printf("%d\n",que.size());
- //遍历上面的数据元素
- while(!que.empty()) {
- printf("%d ",que.top());
- //弹一个删一个
- que.pop();
- }
- return 0;
- }
运行结果:

上面默认数据就是按照大顶堆存储打印,那我们把它变成小顶堆呢,这里就要用到优先队列模板参的第2个和第3个参数
先来说一下这两个参数的各自表示的意义
第2个参数:用什么容器装这些数据,比如vector容器,set容器等等
第3个参数:表示比较方法,这是一种规定,less表示也就是<表示大顶堆,greater >大于表示小顶堆,至于为什么是这样,后面再说。
当然还有一种方法是我也可以不加模板的第二个和第三个参数,那么默认就要进行运算符重载,找到一种新的比较规则
现在先用第一种方法利用模板参来实现小顶堆,默认是大顶堆嘛
demo11.cpp
- #include
- #include
- #include
- #include
- using namespace std;
- int main()
- {
- //声明一个优先对列,加入了第二个,第三个模板参数
- //参数2:用什么类型的容器存放数据
- //参数3:用什么样的比较规则来排序容器中的元素,less < 大顶堆 greater > 大顶堆
- priority_queue<int ,vector<int>,greater<int> > que;
- que.push(5);
- que.push(8);
- que.push(10);
- que.push(7);
- que.push(21);
- //直接遍历出元素
- while(!que.empty()) {
- printf("%d ",que.top());//获取堆顶元素
- que.pop();//弹出元素,删除
- }
- return 0;
- }
运行结果:

上面就按照小顶堆打印数据了。
然后我们采用第二种做法来做,也就是重载运算符,这个可以用于无明显比较规则的数据 ,比如一个类,一个结构体中
demo12.cpp
- #include
- #include
- #include
- #include
- using namespace std;
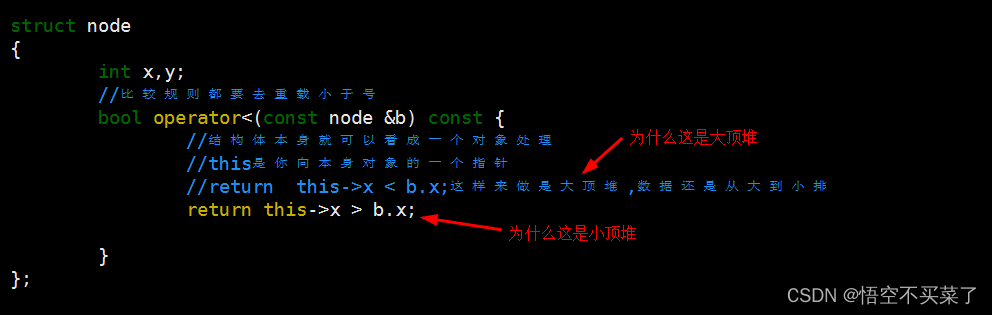
- struct node
- {
- int x,y;
- //比较规则都要去重载小于号
- bool operator<(const node &b) const {
- //结构体本身就可以看成一个对象处理
- //this是你向本身对象的一个指针
- //return this->x < b.x;这样来做是大顶堆,数据还是从大到小排
- return this->x > b.x;
- }
- };
- int main()
- {
- priority_queue
que; - node n1 = {0,7};
- node n2 = {6,3};
- node n3 = {9,10};
- node n4 = {-8,-9};
- que.push(n1);
- que.push(n2);
- que.push(n3);
- que.push(n4);
- //遍历优先队列中的数据
- while(!que.empty()) {
- node n = que.top();//不停弹出栈顶元素
- printf("%d,%d\n",n.x,n.y);
- que.pop();//删除栈顶元素
- }
- return 0;
- }
运行结果
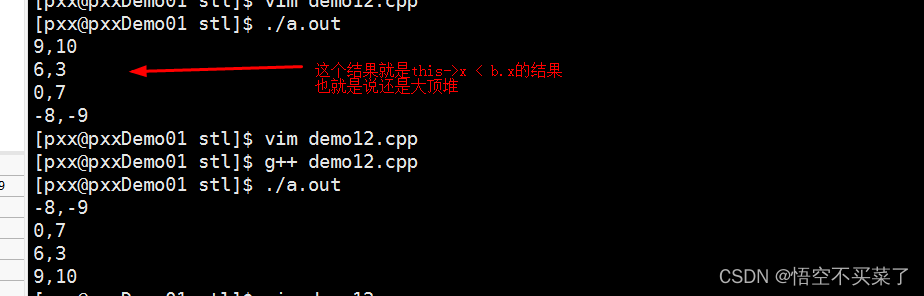
下面来说一下它的原理
大家应该是学过排序的,就拿冒泡排序来说,比如
int arr[] = {0, 6, 9, -8}
把里面的核心代码拿出来分析一下

好了,说到这,祝早安、午安、晚安
-
相关阅读:
typescript错误代码 error TS2451: 无法重新声明块范围变量“age”。ts(2451)
美国市场三星手机超苹果 中国第一属华为
Redis 图形化界面下载及使用超详细教程(带安装包)! redis windows下客户端下载
web技术——HTML文档基础部分(1)
day25可变参数&综合练习
一文教会你如何用 Python 分割合并大文件
如何利用Java爬取网站数据?
动态内存管理知识点
如何通过akshare获取ETF历史数据?
Android 自定义View - 柱状波形图 wave view
- 原文地址:https://blog.csdn.net/Pxx520Tangtian/article/details/126764518