-
数据结构之跳表
写在前面
跳表,链表版本的二分查找,具备高效的数据插入,查找,删除,范围查询等优点。是一种高效的数据结构。本文一起来看下。
1:什么是跳表
我们知道数组具备随机访问的特性,因此使用其可以很方便的实现二分查找算法,但是链表是不支持随机访问的,但是如果我们对链表增加索引,让其支持随机访问
(这里的随机是一定程度上的随机,也可以说是假随机),那么这种经过了一定改造之后的链表,我们就可以称之为跳表。接下来看下这个索引是怎么加的,又是如何实现高效的查找的,假设我们有一个链表,如下:
此时如果是我们要查找16,则需要查找10个节点,为
1->3->4->5->7->8->9->10->13->16,这个时候我们想一下,如果是此时的数据结构是数组,使用二分是怎么查找的呢?肯定是arr[6]=9,这样我们就跳过了{0,5}的元素,避免对其进行无效的遍历,那么链表如何实现这个arr[6]=9的效果呢?,如果是在第一个元素有一个指向位置6的引用,即我们在原始链表的基础上再抽象出一层索引,如下图: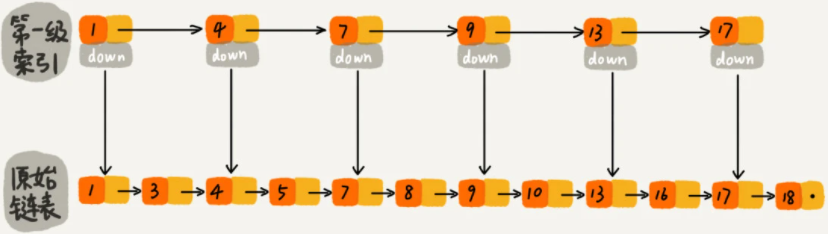
那么此时查找16的步骤就是
1->4->7->9->13->13(通过down访问)->16,这样子就只需要访问7个节点,因为这里我们数据少,所以效果还不是很明显,试想一下,假设在1和4之间有1001个节点,4和7之间有1001个节点,则原始访问的节点数就是2010,此时相比于增加了索引后访问的节点数16是不是就少多了。当然实际上当数据量比较多时,我们就需要增加多层索引,比如像下面这样增加3层索引: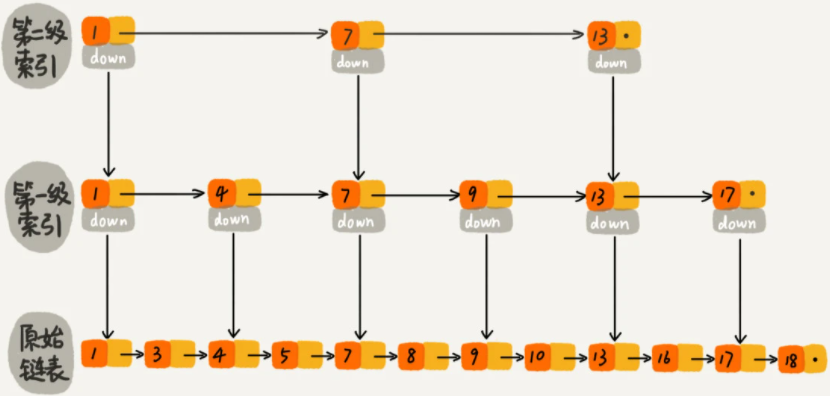
可以看到了,上面这种在链表的基础上增加了索引的数据结构,就是跳表。
1.1:查询的时间复杂度
O(logn)。
1.2:空间复杂度
O(n),这样看起来是空间消耗会增加一倍,但是实际上,索引节点中并非存储所有的数据,比如原始节点存储的是(userid,username,age),在索引中存储的可能仅仅是(userid),所以实际的空间消耗肯定是远远小于原始空间的一倍的,另外在实际的工组中,这种空间换时间的方案也是我们采取最多的,因为空间一般都是非常充足的。
1.3:程序实现
源码 。
程序实现可以参考下图:

其中最左侧的一列对应的就是程序中的
dongshi.daddy.skiplist.SkipList#insert的SkipListNode[] updates = new SkipListNode[MAX_LEVEL];,是核心,用来发起查找的过程。写在后面
-
相关阅读:
Spring 趣玩
公共政策学试题库
第6集丨ObjectScript JSON 中 %JSON 方法汇总
【TA 工具积累】参考图展示 PureRef | 截图 Snipaste
javaweb狂神版(待更新)
MATLAB算法实战应用案例精讲-【目标检测】机器视觉-工业相机
【Mysql】复合查询
JVM:(八)运行时数据区之方法区
C语言生成随机数、C++11按分布生成随机数学习
SQL预编译中order by后为什么不能参数化原因
- 原文地址:https://blog.csdn.net/wang0907/article/details/127107229