核函数是将低维特征映射成为高维特征的方法;
全连接层:全连接层的所有神经元都有权重进行连接
卷积层:又称卷积核|滤波器|内核,用于对输入的图像结构进行特征提取
通道:指滤波器的个数,输出的通道层数只与当前滤波器的通道个数有关
步长:滤波器每次移动的步长
池化:池化(pooling) 的本质就是下采样。Pooling 对于输入的 Feature Map,选择某种方式对其进行降维压缩,以加快运算速度,
局部连接:卷积核的参数与输入的局部进行连接
全局共享:全局都用了卷积核的参数
填充值:避免了边缘信息被一步步舍弃而引入的填充值,Feature Map的尺寸等于:(input_size + 2 * padding_size − filter_size)/stride+1
激励层:把卷积层的结果做非线性映射,常用的激励函数有Sigmoid,Tanh, ReLU,Leaky ReLU,ELU,Maxout
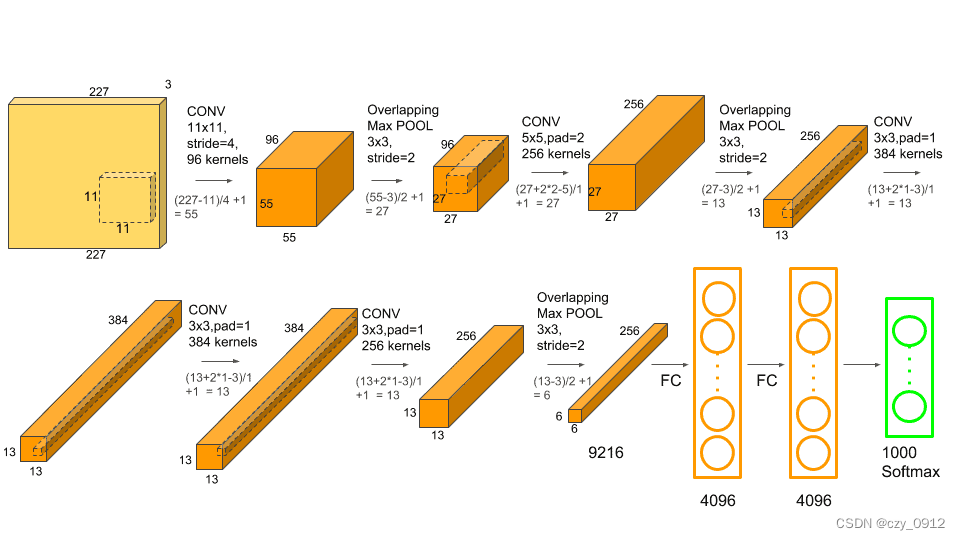
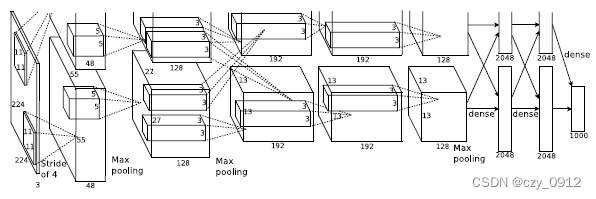
AlexNet网络的流程:
第一次卷积是先将图片缩放成2272273的图片,然后用96个步长为4,填充值为0的11113的卷积核进行过滤得到555596的输出,然后利用RELU对其特征图进行处理,再在此输出的基础上利用33步长为2的池化单元进行了最大池化得到272796的特征图,至此第一次卷积完成。
第二次卷积则是在2727256的基础上用256个步长为1,填充值为2的55256的卷积核进行过滤得到2727256的特征图,然后利用RELU对其特征图进行处理,再在此输出的基础上利用33步长为2的池化单元进行最大池化得到1313256的特征图,至此第二次卷积完成。
第三次卷积则是在1313256的基础上用384个步长为1,填充值为1313256的卷积核进行过滤得到1313384的特征图后输入到ReLU函数中。将输出分成两组,每组FeatureMap大小是13x13x192,分别位于单个GPU上。
第四次卷积则是在两组1313196的基础上用192个步长为1,填充值为1的33192的卷积核进行过滤得到1313384的特征图,后输入到ReLU函数中;仍输出两组,每组FeatureMap大小是13x13x192,分别位于单个GPU上。
第五次卷积则是在两组1313192的基础上用256个步长为1,填充值为1的33192的卷积核,进行过滤得到两组1313128的特征图,然后利用RELU对其特征图进行处理,再在此输出的基础上利用33步长为2的池化单元进行了最大池化得到两组66*128的特征图,至此第五次卷积完成。
第一个全连接层输入为6×6×256,使用4096个6×6×256的卷积核进行卷积得到1x1x4096的输出,然后利用激活函数RELU以及dropout对其特征图进行处理,随机的断开全连接层某些神经元的连接,通过不激活某些神经元的方式防止过拟合。4096个神经元也被均分到两块GPU上进行运算。
第二个全连接层输入为1x1x4096,利用激活函数RELU以及dropout对其特征图进行处理,随机的断开全连接层某些神经元的连接,通过不激活某些神经元的方式防止过拟合。4096个神经元也被均分到两块GPU上进行运算。
输出层的输入为4096个神经元,通过Softmax函数中,输出1000个类别对应的预测概率值,输出是1000个神经元。这1000个神经元即对应1000个检测类别。