-
【XGBoost】第 5 章:XGBoost 揭幕
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】

🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
在本章中,您将最终看到Extreme Gradient Boosting或XGBoost的原样。XGBoost 是在我们建立的机器学习叙述的背景下呈现的,从决策树到梯度提升。本章的前半部分侧重于 XGBoost 为树集成算法带来的明显进步背后的理论。下半场的重点是在Finding the Higgs boson Kaggle 竞赛中构建 XGBoost 模型,向世界展示了 XGBoost。
具体来说,您将确定使 XGBoost 更快的速度增强,发现 XGBoost 如何处理缺失值,并学习 XGBoost正则化参数选择背后的数学推导。您将建立用于构建 XGBoost 分类器和回归器的模型模板。最后,您将查看发现希格斯玻色子的大型强子对撞机,您将在其中权衡数据并使用原始 XGBoost Python API 进行预测。
本章涵盖以下主要主题:
-
设计 XGBoost
-
分析 XGBoost 参数
-
构建 XGBoost 模型
-
Finding the Higgs boson——案例研究
设计 XGBoost
XGBoost 是一个重要的从梯度提升升级。在本节中,您将确定 XGBoost 区别于梯度提升和其他树集成算法的关键特性。
历史叙述
随着大数据的加速,寻找真棒机器学习算法的探索开始产生准确、最优的预测。决策树产生的机器学习模型过于准确,无法很好地推广到新数据。通过bagging和boosting组合许多决策树,集成方法被证明更有效。从树集成轨迹中出现的领先算法是梯度提升。
梯度提升的一致性、力量和出色的结果说服了华盛顿大学的陈天琪提升其能力。他将新算法称为 XGBoost,是Extreme Gradient Boosting的缩写。Chen 的梯度提升新形式包括内置的正则化和令人印象深刻的速度提升。
在 Kaggle 比赛中取得初步成功后,2016 年,Tianqi Chen 和 Carlos Guestrin 撰写了XGBoost: A Scalable Tree Boosting System,向更大的机器学习社区展示他们的算法。您可以在https://arxiv.org/pdf/1603.02754.pdf查看原始论文。以下部分总结了关键点。
设计特点
正如第 4 章,从梯度提升到 XGBoost中所指出的,对更快算法的需求是在处理大数据时很明显。Extreme Gradient Boosting中的Extreme意味着将计算极限推向极致。突破计算极限不仅需要模型构建知识,还需要磁盘读取、压缩、缓存和内核知识。
尽管本书的重点仍然是构建 XGBoost 模型,但我们将深入了解 XGBoost 算法,以区分关键的进步,例如处理缺失值、速度增益和准确度增益,从而使 XGBoost 更快、更准确、更准确。更可取。接下来让我们看看这些关键的进步。
处理缺失值
你在第 1 章“机器学习领域”中花费了大量时间,练习了纠正空值的不同方法。这是所有机器学习从业者的必备技能。
但是,XGBoost 能够为您处理缺失值。缺少一个可以设置为任何值的超参数。当给定一个缺失的数据点时,XGBoost 会对不同的分割选项进行评分,并选择具有最佳结果的选项。
获得速度
XGBoost 专为提高速度而设计。速度增益允许机器学习模型更快地构建,这在处理数百万、数十亿或数万亿行数据时尤为重要。这在大数据世界中并不少见,每天,工业和科学积累的数据比以往任何时候都多。以下新设计功能使 XGBoost 在速度上比同类集成算法具有很大优势:
-
近似分裂查找算法
-
稀疏感知分裂发现
-
并行计算
-
缓存感知访问
-
块压缩和分片
让我们更详细地了解这些功能。
近似分裂查找算法
决定树需要最优的分割来产生最优的结果。贪心算法在每一步选择最佳分割,并且不会回溯查看先前的分支。请注意,决策树分裂通常以贪婪的方式执行。
XGBoost 提出了一种精确的贪心算法以及一种新的近似分裂查找算法。这拆分查找算法使用分位数(拆分数据的百分比)来提出候选拆分。在全局提案中,在整个训练过程中使用相同的分位数,在局部提案中,为每一轮拆分提供新的分位数。
一个以前知道的分位数草图算法适用于同等加权的数据集。XGBoost 提出了一种新颖的基于合并和修剪的加权分位数草图,并具有理论保证。尽管该算法的数学细节超出了本书的范围,但我们鼓励您查看原始 XGBoost 论文的附录,网址为https://arxiv.org/pdf/1603.02754.pdf。
稀疏感知分裂发现
出现稀疏数据当大多数条目为 0 或 null 时。当数据集主要由空值组成或它们已被一次性编码时,可能会发生这种情况。在第 1 章,机器学习领域,您使用pd.get_dummies将分类列转换为数值列。这导致了一个更大的数据集,其中许多值为 0。这种将分类列转换为数值列的方法,其中 1 表示存在,0 表示不存在,通常称为 one-hot e编码。您将在第 10 章XGBoost模型部署中获得一次热编码的练习。
稀疏矩阵是旨在仅存储具有非零和非空值的数据点。这节省了宝贵的空间。稀疏感知拆分表示在寻找拆分时,XGBoost 更快,因为它的矩阵是稀疏的。
根据原始论文XGBoost: A Scalable Tree Boosting System ,稀疏感知分裂查找算法在All-State-10K数据集上的执行速度比标准方法快 50 倍。
并行计算
提升对于并行计算来说并不理想,因为每棵树都依赖于前一棵树的结果。然而,也有可能发生并行化的机会。
并行计算发生当多个计算单元同时处理同一个问题时。XGBoost 将数据排序并压缩成块。这些块可以分布到多台机器上,也可以分布到外部存储器(内核外)。
使用块对数据进行排序更快。拆分查找算法利用了块,并且由于块的原因,分位数的搜索速度更快。在每种情况下,XGBoost 都提供并行计算以加快模型构建过程。
缓存感知访问
这您计算机上的数据分为高速缓存和主内存。您最常使用的缓存是为高速内存保留的。您不经常使用的数据被保留用于低速内存。不同的缓存级别具有不同数量级的延迟,如下所述:https ://gist.github.com/jboner/2841832 。
在梯度统计方面,XGBoost 使用缓存感知预取。XGBoost 分配一个内部缓冲区,获取梯度统计信息,并使用小批量执行累积。根据XGBoost: A Scalable Tree Boosting System,对于具有大量行的数据集,预取会延长读/写依赖性并减少大约 50% 的运行时间。
块压缩和分片
块压缩通过压缩列来帮助计算昂贵的磁盘读取。堵塞分片通过将数据分片到读取数据时交替的多个磁盘来减少读取时间。
精度增益
XGBoost添加内置正则化以实现超越的准确性增益梯度提升。正则化是添加信息以减少方差和防止过拟合的过程。
虽然数据可以通过超参数微调进行正则化,但也可以尝试正则化算法。例如,Ridge和Lasso是LinearRegression的正则化机器学习替代方案。
与梯度提升和随机森林相比,XGBoost 将正则化作为学习目标的一部分。正则化参数惩罚复杂性并平滑最终权重以防止过度拟合。XGBoost 是梯度提升的正则化版本。
在下一节中,您将了解 XGBoost 学习目标背后的数学原理,即将正则化与损失函数相结合。虽然您不需要了解数学即可有效使用 XGBoost,但数学知识可能会提供更深入的理解。如果需要,您可以跳过下一部分。
分析 XGBoost 参数
在本节中,我们将分析 XGBoost 用于创建具有数学推导的最先进机器学习模型的参数。
我们将保持参数和超参数之间的区别,如第 2 章“深度决策树”中所述。在训练模型之前选择超参数,而在训练模型时选择参数。换句话说,参数是模型从数据中学到的。
以下推导取自 XGBoost 官方文档Introduction to Boosted Trees,位于Introduction to Boosted Trees — xgboost 1.7.0-dev documentation。
学习目标
学习机器学习模型的目标决定了模型对数据的拟合程度。在 XGBoost 的情况下,学习目标由两部分组成:损失函数和正则化项。
在数学上,XGBoost 的学习目标可以定义如下:

这里,
 是损失函数,即回归的均方误差( MSE ),或分类的对数损失,
是损失函数,即回归的均方误差( MSE ),或分类的对数损失, 是正则化函数,是防止过拟合的惩罚项。将正则化项作为目标函数的一部分将 XGBoost 与大多数树集成区分开来。
是正则化函数,是防止过拟合的惩罚项。将正则化项作为目标函数的一部分将 XGBoost 与大多数树集成区分开来。让我们通过考虑回归的 MSE 来更详细地看一下目标函数。
损失函数
损失函数,定义为回归的 MSE,可以用求和符号写成,如下所示:

这里,
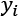 是第
是第 th行的目标值,
th行的目标值,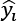 是第th行机器学习模型预测的值。
是第th行机器学习模型预测的值。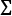 求和符号表示以i = 1 行数开头和i = n结尾的所有行求和。
求和符号表示以i = 1 行数开头和i = n结尾的所有行求和。给定树的预测 ,
需要一个从树根开始到叶子结束的函数。在数学上,这可以表示如下:
这里,x i是一个向量,其条目是第
th行的列, 表示该函数F是f的成员,所有可能的 CART 函数的集合。CART是分类和回归树的首字母缩写。CART 为所有叶子提供了真正的价值,即使是分类算法也是如此。
表示该函数F是f的成员,所有可能的 CART 函数的集合。CART是分类和回归树的首字母缩写。CART 为所有叶子提供了真正的价值,即使是分类算法也是如此。在梯度提升中,确定第
th行预测的函数包括所有先前函数的总和,如第 4 章从梯度提升到 XGBoost 中所述。因此,可以编写以下内容:
这里,T是数字提升树木。换句话说,要获得第
th树的预测,除了对新树的预测之外,还要对先前树的预测求和。 该符号坚持函数属于F,所有可能的 CART 函数的集合。
该符号坚持函数属于F,所有可能的 CART 函数的集合。第
th提升树的学习目标现在可以重写如下:
由于 boosted trees 将先前树的预测相加,因此除了新树的预测之外,它必须是
 这就是附加训练背后的想法。
这就是附加训练背后的想法。通过将其代入前面的学习目标,我们得到以下结果:

对于最小二乘回归情况,这可以重写如下:

将多项式相乘,我们得到以下结果:

这里,C是一个不依赖于 的常数项。就多项式而言,这是一个二次带变量
 的方程。回想一下,目标是找到 的最优值,即映射根(样本)到叶(预测)的最优函数。
的方程。回想一下,目标是找到 的最优值,即映射根(样本)到叶(预测)的最优函数。任何足够平滑的函数,例如二次多项式(二次),都可以是由泰勒多项式近似。XGBoost 使用牛顿法和二阶泰勒多项式获得以下结果:
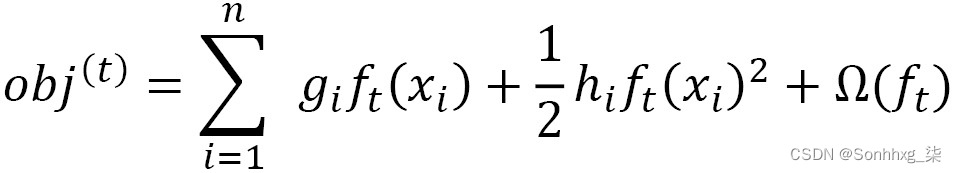
在这里,
 和
和 可以写成以下偏导数:
可以写成以下偏导数:

有关 XGBoost 如何使用泰勒展开的一般讨论,请查看optimization - XGBoost Loss function Approximation With Taylor Expansion - Cross Validated。
XGBoost 实现这个学习目标函数是通过一个只使用
 和作为输入的求解器来实现的。由于损失函数是通用的,因此可以使用相同的输入进行回归和分类。
和作为输入的求解器来实现的。由于损失函数是通用的,因此可以使用相同的输入进行回归和分类。这留下了正则化函数,
 。
。正则化函数
让w成为叶子的向量空间。然后,f,将树根映射到叶子的函数,可以根据 w重铸,如下所示:

这里,q是将数据点分配给叶子的函数,T是叶子的数量。
经过实践和实验,XGBoost 确定以下作为正则化函数,其中
 和
和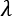 是惩罚常数,以减少过拟合:
是惩罚常数,以减少过拟合:
目标函数

我们可以定义分配给第jth叶的数据点的索引集,
如下所示:

目标函数可以写成如下:

最后,设置
 和
和 ,在重新排列索引并组合相似项之后,我们得到目标函数的最终形式,如下:
,在重新排列索引并组合相似项之后,我们得到目标函数的最终形式,如下:
通过求导数
 并将左侧设为零来最小化目标函数,我们得到以下结果:
并将左侧设为零来最小化目标函数,我们得到以下结果:
这可以代回反对函数中,得到以下结果:

这是 XGBoost 用来确定模型与数据的拟合程度的结果。
恭喜您完成了漫长而具有挑战性的推导!
构建 XGBoost 模型
在前两节中,您了解了 XGBoost 如何通过参数推导、正则化、速度增强和新功能(例如用于补偿空值的缺失参数)在后台工作。
在本书中,我们主要使用 scikit-learn 构建 XGBoost 模型。scikit-learn XGBoost 包装器于 2019 年发布。在完全沉浸于 scikit-learn 之前,构建 XGBoost 模型需要更陡峭的学习曲线。例如,将 NumPy 数组转换为dmatrices是利用 XGBoost 框架的必要条件。
然而,在 scikit-learn 中,这些转换发生在幕后。正如您在本书中所经历的那样,在 scikit-learn 中构建 XGBoost 模型与在 scikit-learn 中构建其他机器学习模型非常相似。除了train_test_split、cross_val_score、GridSearchCV和RandomizedSearchCV等基本工具外,所有标准 scikit-learn 方法(如.fit和.predict )都可用。
在本节中,您将开发用于构建 XGBoost 模型的模板。展望未来,这些模板可以作为构建 XGBoost 分类器和回归器的起点。
我们将为两个经典数据集构建模板:用于分类的Iris 数据集和用于回归的糖尿病数据集。这两个数据集都很小,内置在 scikit-learn 中,并且已经在整个机器学习社区中进行了频繁的测试。作为模型构建过程的一部分,您将明确定义为 XGBoost 提供高分的默认超参数。这些超参数是明确定义的,因此您可以了解它们的含义为今后调整它们做准备。
鸢尾花数据集
鸢尾花数据集,主食机器学习社区的标准,由统计学家 Robert Fischer 于 1936 年引入。其易于访问、体积小、数据干净和值的对称性使其成为测试分类算法的流行选择。
我们将通过使用带有load_iris()方法的datasets库直接从 scikit-learn 下载 Iris 数据集来介绍 Iris 数据集,如下所示:
- import pandas as pd
- import numpy as np
- from sklearn import datasets
- iris = datasets.load_iris()
Scikit-learn 数据集存储为NumPy 数组,这是机器学习算法选择的数组存储方法。pandas DataFrames 更多地用于数据分析和数据可视化。将 NumPy 数组视为 DataFrame 需要pandas DataFrame方法。这个 scikit-learn 数据集被预先分成预测列和目标列。将它们组合在一起需要在转换之前将 NumPy 数组与代码np.c_连接起来。还添加了列名,如下所示:
- df = pd.DataFrame(data= np.c_[iris['data'],
- iris['target']],columns= iris['feature_names'] + ['target'])
您可以使用df.head()查看 DataFrame 的前五行:
df.head()生成的 DataFrame 将如下所示:

图 5.1 – Iris 数据集
预测器列是不言自明的,测量萼片和花瓣的长度和宽度。根据 scikit-learn 文档The Iris Dataset — scikit-learn 1.1.2 documentation,目标列由三种不同的鸢尾花组成:setosa、versicolor和virginica。有 150 行。
要为机器学习准备数据,请导入train_test_split,然后相应地拆分数据。您可以使用原始 NumPy 数组iris['data']和iris['target']作为train_test_split的输入:
- from sklearn.model_selection import train_test_split
- X_train, X_test, y_train, y_test = train_test_split(iris['data'], iris['target'], random_state=2)
现在我们已经拆分了数据,让我们构建分类模板。
XGBoost 分类模板
以下模板用于构建 XGBoost 分类器,假设数据集已经分为X_train、X_test、y_train和y_test集:
-
从xgboost库导入XGBClassifier :
from xgboost import XGBClassifier -
根据需要导入分类评分方法。
虽然accuracy_score是标准的,但其他评分方法,例如auc(曲线下面积),将是稍后讨论:
from sklearn.metrics import accuracy_score -
使用超参数初始化 XGBoost 分类器。
微调超参数是第 6 章XGBoost超参数的重点。在本章中,最重要的默认超参数在前面明确说明:
- xgb = XGBClassifier(booster='gbtree', objective='multi:softprob',
- max_depth=6, learning_rate=0.1,
- n_estimators=100, random_state=2, n_jobs=-1)
a) booster='gbtree':booster 是基础学习器。它是在每一轮提升过程中构建的机器学习模型。您可能已经猜到“gbtree”代表梯度提升树,即 XGBoost 默认的基础学习器。与其他基础学习者一起工作并不常见,但可以,这是我们在第 8 章XGBoost替代基础学习者中采用的策略。
b) objective='multi:softprob':可以在 XGBoost 官方文档https://xgboost.readthedocs.io/en/latest/parameter.html的Learning Task Parameters下查看目标的标准选项。当数据集包含多个类时,multi:softprob目标是binary:logistic的标准替代方案。它计算分类概率并选择最高的一个。如果没有明确说明,XGBoost 通常会为您找到正确的目标。
c) max_depth=6:一棵树的max_depth决定了每棵树的分支数。它是进行平衡预测时最重要的超参数之一。XGBoost 使用默认值6,这与随机森林不同,它不提供值,除非明确编程。
d) learning_rate=0.1:在 XGBoost 中,这个超参数通常被称为eta。这个超参数通过将每棵树的权重降低到给定百分比来限制方差。learning_rate超参数在第 4 章,从 Gradient Boosting 到 XGBoost中进行了详细探讨。
e) n_estimators=100:在集成方法中流行,n_estimators是模型中提升树的数量。在降低learning_rate的同时增加这个数字可以导致更稳健的结果。
-
使分类器适合数据。
这就是魔法发生的地方。整个 XGBoost 系统,前两节探讨的细节,优化参数的选择,包括正则化约束,以及速度增强,例如近似拆分查找算法,以及分块和分片,都发生在 scikit 的这一强大行中- 学习代码:
xgb.fit(X_train, y_train) -
将y值预测为y_pred:
y_pred = xgb.predict(X_test) -
通过比较y_pred和y_test对模型进行评分:
score = accuracy_score(y_pred, y_test) -
显示你的结果:
- print('Score: ' + str(score))
- # Score: 0.9736842105263158
不幸的是,没有正式的 Iris 数据集分数列表。太多了,无法在一个地方编译。使用默认超参数在 Iris 数据集上获得97.4 %的初始分数非常好(请参阅SERPRO - Iris | Kaggle)。
XGBoost 分类器前面段落中提供的模板并不意味着确定性,而是一个前进的起点。
糖尿病数据集
现在你是熟悉 scikit-learn 和 XGBoost 后,您正在开发相当快速地构建和评分 XGBoost 模型的能力。在本节中,使用带有 scikit-learn 的糖尿病数据集的cross_val_score提供了一个 XGBoost 回归器模板。
在构建模板之前,将预测列导入为X并将目标列导入为y,如下所示:
X,y = datasets.load_diabetes(return_X_y=True)现在我们已经导入了预测器和目标列,让我们开始构建模板。
XGBoost 回归器模板(交叉验证)
这里有假设已定义预测列X和目标列y ,使用交叉验证在 scikit-learn 中构建 XGBoost 回归模型的基本步骤:
-
导入XGBRegressor和cross_val_score:
- from sklearn.model_selection import cross_val_score
- from xgboost import XGBRegressor
-
初始化XGBRegressor。
在这里,我们使用MSE Objective='reg:squarederror'初始化XGBRegressor。明确给出了最重要的超参数默认值:
- xgb = XGBRegressor(booster='gbtree', objective='reg:squarederror',
- max_depth=6, learning_rate=0.1,
- n_estimators=100, random_state=2, n_jobs=-1)
-
使用cross_val_score 拟合并评分回归量。
使用cross_val_score,使用模型、预测列、目标列和评分作为输入一步完成拟合和评分:
scores = cross_val_score(xgb, X, y, scoring='neg_mean_squared_error', cv=5) -
显示结果。
分数为回归通常显示为均方根误差( RMSE ),以保持单位相同:
- rmse = np.sqrt(-scores)
- print('RMSE:', np.round(rmse, 3))
- print('RMSE mean: %0.3f' % (rmse.mean()))
结果如下:
- RMSE: [63.033 59.689 64.538 63.699 64.661]
- RMSE mean: 63.124
没有比较基准,我们不知道这个分数是什么意思。使用.describe()方法将目标列y转换为pandas DataFrame将给出预测列的四分位数和一般统计信息,如下所示:
pd.DataFrame(y).describe()这是预期的输出:

图 5.2 – 描述糖尿病目标列 y 的统计数据
63.124的分数小于 1 个标准差,这是一个可观的结果。
您现在拥有 XGBoost可用于构建模型的分类器和回归器模板。
现在您已经习惯了在 scikit-learn 中构建 XGBoost 模型,是时候深入研究高能物理了。
Finding the Higgs boson——案例研究
在本节中,我们将回顾 Higgs Boson Kaggle 竞赛,该竞赛将 XGBoost 带入机器学习的聚光灯下。为了做好准备,在进行模型开发之前先给出历史背景。我们构建的模型包括 XGBoost 在比赛时提供的默认模型和 Gabor Melis 提供的获胜解决方案的参考。本文不需要 Kaggle 帐户,因此我们不会花时间向您展示如何提交。如果您有兴趣,我们提供了指南。
物理背景
在流行文化中,希格斯玻色子被称为上帝粒子。理论化Peter Higgs 在 1964 年引入了希格斯玻色子来解释为什么粒子有质量。
2012 年,在欧洲核子研究中心(瑞士日内瓦)的大型强子对撞机中发现了希格斯玻色子。诺贝尔奖被授予,物理学的标准模型,这个模型解释了除了引力之外的所有物理学已知的力,比以往任何时候都高。
希格斯玻色子是通过将质子以极高的速度相互撞击并观察结果而发现的。观测来自ATLAS探测器,该探测器记录每秒数亿次质子-质子碰撞产生的数据,根据比赛的技术文档,学习发现:希格斯玻色子机器学习挑战,https://higgsml.lal.in2p3 .fr/files/2014/04/documentation_v1.8.pdf。
发现希格斯玻色子后,下一步就是精确测量其衰变特征。ATLAS 实验发现,希格斯玻色子从包裹在背景噪声中的数据中衰变为两个tau粒子。为了更好地理解数据,ATLAS 呼吁机器学习社区。
Kaggle 比赛
Kaggle 比赛是一项旨在解决特定问题的机器学习竞赛。机器学习竞赛在 2006 年一举成名,当时 Netflix 提供 100 万美元给任何可以将电影推荐提高 10% 的人。2009 年,100 万美元的奖金被授予BellKor的Pragmatic Chaos团队(BellKor’s Pragmatic Chaos Wins $1 Million Netflix Prize by Mere Minutes | WIRED)。
许多企业、计算机科学家、数学家和学生开始意识到机器学习在社会中的价值越来越大。机器学习竞赛火爆,公司东道主和机器学习从业者互惠互利。从 2010 年开始,许多早期采用者前往 Kaggle 尝试参加机器学习比赛。
2014 年,Kaggle 宣布了与 ATLAS的希格斯玻色子机器学习挑战赛( Higgs Boson Machine Learning Challenge | Kaggle )。凭借 13,000 美元的奖金池,1,875 支队伍参加了比赛。
在 Kaggle 比赛中,提供了训练数据以及所需的评分方法。团队在提交结果之前基于训练数据构建机器学习模型。未提供测试数据的目标列。但是,允许多次提交,并且返回分数,以便参赛者可以在最后日期之前改进他们的模型。
Kaggle 比赛是测试机器学习算法的沃土。与工业界不同,Kaggle 比赛吸引了成千上万的参赛者,使得获奖的机器学习模型得到了很好的测试。
XGBoost 和希格斯挑战
XGBoost 发布2014 年 3 月 27 日,即希格斯挑战前 6 个月向公众公开。在比赛中,XGBoost 一路飙升,帮助参赛者在 Kaggle 排行榜上攀升,同时节省了宝贵的时间。
让我们访问数据,看看竞争对手在使用什么。
数据
代替使用 Kaggle 提供的数据,我们使用其来源的 CERN 开放数据门户提供的原始数据:http: //opendata.cern.ch/record/328。CERN 数据和 Kaggle 数据的区别在于 CERN 数据集要大得多。我们将选择前 250,000 行并进行一些修改以匹配 Kaggle 数据。
你可以直接从https://github.com/PacktPublishing/Hands-On-Gradient-Boosting-with-XGBoost-and-Scikit-learn/tree/master/Chapter05下载 CERN 希格斯玻色子数据集。
将atlas-higgs-challenge-2014-v2.csv.gz文件读入pandas DataFrame。请注意,我们仅选择前 250,000 行,并且使用了compression=gzip参数,因为数据集被压缩为csv.gz文件。访问数据后,查看前五行,如下:
- df = pd.read_csv('atlas-higgs-challenge-2014-v2.csv.gz',nrows=250000, compression='gzip')
- df.head()
输出的最右侧列应如以下屏幕截图所示:

图 5.3 – CERN 希格斯玻色子数据 – 包括 Kaggle 列
注意Kaggleset和KaggleWeight列。由于 Kaggle 数据集较小,Kaggle 对其权重列使用了不同的数字,在上图中表示为KaggleWeight。Kaggleset下的t值表明它是训练集的一部分Kaggle 数据集。换句话说,这两列Kaggleset和KaggleWeight是 CERN 数据集中的列,旨在包含将用于 Kaggle 数据集的信息。在本章中,我们将把我们的 CERN 数据子集限制在 Kaggle 训练集上。
为了匹配 Kaggle 训练数据,我们删除Kaggleset和Weight列,将KaggleWeight转换为'Weight',并将'Label'列移动到最后一列,如下:
- del df[‹Weight›]
- del df[‹KaggleSet›]
- df = df.rename(columns={«KaggleWeight»: «Weight»})
移动标签列的一种方法是将其存储为变量,删除该列,然后通过将其分配给新变量来添加新列。每当将新列分配给 DataFrame 时,新列都会出现在末尾:
- label_col = df['Label']
- del df['Label']
- df['Label'] = label_col
现在所有更改都已完成,CERN 数据与 Kaggle 数据匹配。继续查看前五行:
df.head()图 5.4 – CERN 希格斯玻色子数据 – 物理专栏
许多列未显示,并且在多个位置出现异常值-999.00 。
EventId之外的列包括以 PRI 为前缀的变量,PRI代表原语,它们是检测器在碰撞期间直接测量的值。相比之下,标记为DER的列是这些测量值的数值推导。
所有列名和类型都由df.info()显示:
df.info()这是输出示例,中间列被截断以节省空间:
- <class 'pandas.core.frame.DataFrame'>
- RangeIndex: 250000 entries, 0 to 249999
- Data columns (total 33 columns):
- # Column Non-Null Count Dtype
- --- ------ -------------- -----
- 0 EventId 250000 non-null int64
- 1 DER_mass_MMC 250000 non-null float64
- 2 DER_mass_transverse_met_lep 250000 non-null float64
- 3 DER_mass_vis 250000 non-null float64
- 4 DER_pt_h 250000 non-null float64
- …
- 28 PRI_jet_subleading_eta 250000 non-null float64
- 29 PRI_jet_subleading_phi 250000 non-null float64
- 30 PRI_jet_all_pt 250000 non-null float64
- 31 Weight 250000 non-null float64
- 32 Label 250000 non-null object
- dtypes: float64(30), int64(3)
- memory usage: 62.9 MB
所有列都有非空值,只有最后一列Label是非数字的。列可以是分组如下:
-
第0列:EventId – 与机器学习模型无关。
-
第1-30列:来自 LHC 碰撞的物理列。这些列的详细信息可以在Documentation | The Higgs Machine Learning Challenge的技术文档链接中找到。这些是机器学习预测器列。
-
第31列:权重- 此列用于缩放数据。这里的问题是希格斯玻色子事件非常罕见,因此准确率达到 99.9% 的机器学习模型可能无法找到它们。权重补偿了这种不平衡,但权重不适用于测试数据。处理权重的策略将在本章后面和第 7 章“使用 XGBoost 发现系外行星”中讨论。
-
第32列:标签——这是目标列,标记为s表示信号,b表示背景。训练数据是从真实数据中模拟出来的,因此可以找到比其他方式更多的信号。信号是希格斯玻色子衰变的发生。
数据的唯一问题是目标列Label不是数字。通过将s值替换为1并将b值替换为0 ,将Label列转换为数值列,如下所示:
df['Label'].replace(('s', 'b'), (1, 0), inplace=True)现在所有列是具有非空值的数字,您可以将数据拆分为预测列和目标列。回想一下,预测列的索引为 1-30,而目标列是最后一列,索引为32(或 -1)。请注意,不应包含Weight列,因为它不适用于测试数据:
- X = df.iloc[:,1:31]
- y = df.iloc[:,-1]
计分
希格斯挑战不是你的平均 Kaggle 比赛。除了对特征工程的高能物理理解困难(这条路线我们不会追求)之外,评分方法也不标准。希格斯挑战需要优化近似中位数显着性( AMS )。
AMS 定义如下:

这里,s是真阳性率,b是假阳性率,
 是一个常数正则化项,给出为10。
是一个常数正则化项,给出为10。好在XGBoost为比赛提供了AMS评分方法,所以不需要正式定义。高 AMS 源于许多真阳性和少量假阴性。在http://higgsml.lal.in2p3.fr/documentation的技术文档中给出了 AMS 而非其他评分方法的理由。
小费
可以构建自己的评分方法,但通常不需要。在极少数情况下您需要构建自己的评分方法,您可以查看3.3. Metrics and scoring: quantifying the quality of predictions — scikit-learn 1.1.2 documentation了解更多信息。
权重(Weights)
在建立一个之前希格斯玻色子的机器学习模型,理解和利用权重很重要。
在机器学习中,权重可用于提高不平衡数据集的准确性。考虑希格斯挑战中的s(信号)和b(背景)列。实际上,s << b,因此信号在背景噪声中非常罕见。例如,假设信号比背景噪声少 1000 倍。您可以创建一个权重列,其中b = 1 和s = 1/1000 以补偿这种不平衡。
根据比赛的技术文档,权重列是一个比例因子,当求和时,它给出了 2012 年数据收集期间信号和背景事件的预期数量。这意味着预测需要权重来表示现实。否则,模型将预测太多的 s(信号)事件。
由于测试数据提供了测试集生成的信号和背景事件的预期数量,因此应首先调整权重以匹配测试数据。测试数据有 550,000 行,是训练数据提供的 250,000 行 ( len(y) ) 的两倍多。缩放权重以匹配测试数据可以通过将权重列乘以增加的百分比来实现,如下所示:
df['test_Weight'] = df['Weight'] * 550000 / len(y)接下来,XGBoost 提供了一个超参数scale_pos_weight,它考虑了缩放因子。比例因子是背景噪声权重之和除以信号权重之和。可以使用pandas条件表示法计算比例因子,如下所示:
- s = np.sum(df[df['Label']==1]['test_Weight'])
- b = np.sum(df[df['Label']==0]['test_Weight'])
在前面的代码中,df[df['Label']==1]将 DataFrame 缩小到Label列所在的行等于1,然后np.sum使用test_Weight列添加这些行的值。
最后,要查看实际速率,将b除以s:
- b/s
- # 593.9401931492318
总之,权重表示数据生成的信号和背景事件的预期数量。我们缩放权重以匹配测试数据的大小,然后将背景权重的总和除以信号权重的总和以建立scale_pos_weight=b/s超参数。
小费
有关权重的更详细讨论,请查看 KDnuggets 的精彩介绍,网址为Machine Learning 101: The What, Why, and How of Weighting - KDnuggets。
这个模型
是时候构建 XGBoost 了模型来预测信号——即模拟希格斯玻色子衰变的发生。
在比赛的时候,XGBoost 是新的,scikit-learn 包装器还不可用。即使在今天(2020 年),关于在 Python 中实现 XGBoost 的大部分在线信息都是 pre-scikit-learn。由于您很可能会在网上遇到 pre-scikit-learn XGBoost Python API,而这是所有竞争对手在 Higgs Challenge 中使用的,因此我们仅在本章中使用原始 Python API 提供代码。
以下是为希格斯挑战构建 XGBoost 模型的步骤:
-
将xgboost导入为xgb:
import xgboost as xgb -
初始化 XGBoost模型作为DMatrix填充缺失值和权重。
在 scikit-learn 之前,所有 XGBoost 模型都被初始化为 DMatrix。scikit-learn 包装器会自动为您将数据转换为 DMatrix。XGBoost 针对速度优化的稀疏矩阵是 DMatrices。
根据文档,所有设置为-999.0的值都是未知值。在 XGBoost 中,可以将未知值设置为缺失的超参数,而不是将这些值转换为中值、均值、众数或其他空值替换。在模型构建阶段,XGBoost 会自动选择导致最佳分割的值。
-
权重超参数可以等于权重部分中定义的新列df['test_Weight'] :
xgb_clf = xgb.DMatrix(X, y, missing=-999.0, weight=df['test_Weight']) -
设置额外的超参数。
以下超参数是 XGBoost 为比赛提供的默认值:
a) 初始化一个名为param的空白字典:
param = {}b) 将目标定义为'binary:logitraw'。
这意味着从逻辑回归概率创建二元模型。该目标将模型定义为分类器,并允许对目标列进行排名,这是此特定 Kaggle 比赛提交所必需的:
param['objective'] = 'binary:logitraw'c) 使用背景权重除以信号权重来缩放正样本。这将有助于模型在测试集上表现更好:
param['scale_pos_weight'] = b/sd) 学习率eta为0.1:
param['eta'] = 0.1e) max_depth为6:
param['max_depth'] = 6f) 将评分方法设置为“auc”以进行显示:
param['eval_metric'] = 'auc'尽管将打印 AMS 分数,但评估指标以auc给出,它代表曲线下面积。auc是真阳性与假阳性曲线,即当它等于1时完美。与准确度类似,auc是分类的标准评分指标,尽管它通常优于准确度,因为不平衡数据集的准确度受到限制,如第 7 章“使用 XGBoost 发现系外行星”中所述。
-
创建一个包含上述各项的参数列表,以及评估指标 ( auc ) 和ams@0.15,XGBoost 使用 15% 的阈值实现 AMS 分数:
plst = list(param.items())+[('eval_metric', 'ams@0.15')] -
创建一个包含初始化分类器和“训练”的监视列表,以便您可以在树继续提升时查看分数:
watchlist = [ (xg_clf, 'train') ] -
将增强轮数设置为120:
num_round = 120 -
训练并保存模型。通过将参数列表、分类器、轮数和观察列表作为输入来训练模型。使用save_model方法保存模型,这样您就不必再次进行耗时的训练过程。然后,运行代码并观察分数如何随着树的提升而提高:
- print ('loading data end, start to boost trees')
- bst = xgb.train( plst, xgmat, num_round, watchlist )
- bst.save_model('higgs.model')
- print ('finish training')
- [110] train-auc:0.94505 train-ams@0.15:5.84830
- [111] train-auc:0.94507 train-ams@0.15:5.85186
- [112] train-auc:0.94519 train-ams@0.15:5.84451
- [113] train-auc:0.94523 train-ams@0.15:5.84007
- [114] train-auc:0.94532 train-ams@0.15:5.85800
- [115] train-auc:0.94536 train-ams@0.15:5.86228
- [116] train-auc:0.94550 train-ams@0.15:5.91160
- [117] train-auc:0.94554 train-ams@0.15:5.91842
- [118] train-auc:0.94565 train-ams@0.15:5.93729
- [119] train-auc:0.94580 train-ams@0.15:5.93562
- finish training
恭喜您构建了一个可以预测希格斯玻色子衰变的 XGBoost 分类器!
该模型以94.58 %的auc和5.9的 AMS 执行。就 AMS 而言,比赛的最高价值在前三名。当与测试数据一起提交时,该模型的 AMS 约为3.6 。
您刚刚构建的模型是陈谈奇在比赛期间为 XGBoost 用户提供的基准。比赛的获胜者 Gabor Melis 使用这个基线来构建他的模型。从GitHub - melisgl/higgsml: The winning solution to the The Higgs Boson Machine Learning Challenge.查看获胜解决方案并单击xgboost-scripts可以看出,对基线模型所做的更改并不显着。与大多数 Kaggle 竞争对手一样,Melis 也执行了特征工程以将更多相关列添加到数据中,我们将在第 9 章XGBoost Kaggle Masters中讨论这种做法。
可以在截止日期后构建和训练自己的模型并通过 Kaggle 提交。对于 Kaggle 比赛,提交的内容必须进行排名、正确索引,并与需要进一步解释的 Kaggle API 主题一起交付。如果你想提交模型进行实际比赛,XGBoost在https://github.com/dmlc/xgboost/blob/master/demo/kaggle-higgs/higgs-pred.py中提供了您可能会发现有用的排名代码。
概括
在本章中,您了解了 XGBoost 是如何设计用于提高梯度提升的准确性和速度的,包括缺失值、稀疏矩阵、并行计算、分片和阻塞。您学习了确定梯度下降和正则化参数的 XGBoost 目标函数背后的数学推导。您从经典的 scikit-learn 数据集构建了 XGBClassifier和XGBRegressor模板,获得了非常好的分数。最后,您构建了 XGBoost 为 Higgs Challenge 提供的基线模型,该模型导致了获胜的解决方案并将 XGBoost 提升到了聚光灯下。
现在您已经对 XGBoost 的整体叙述、设计、参数选择和模型构建模板有了扎实的了解,在下一章中,您将微调 XGBoost 的超参数以获得最佳分数。
-
-
相关阅读:
详解 ClickHouse 的语法优化规则
maven下载使用及环境变量配置步骤【非常详细】
让锅碗瓢盆变成我们生活的快乐插曲
编写TypeScript的库
C#里氏替换
【Java基础面试三十四】、接口中可以有构造函数吗?
Node.js 实现抢票小工具&短信通知提醒
合并文件解决HiveServer2内存溢出方案
[Redis] Spring Boot 使用Redis---RedisTemplate泛型约束乱码问题
核心实验17_IRF堆叠_H3C
- 原文地址:https://blog.csdn.net/sikh_0529/article/details/127106507
