-
多线程之四(锁策略+CAS+synchronized)
目录
1. 常见的锁策略
1.1 乐观锁 & 悲观锁
乐观锁:假设数据一般情况下不会产生并发冲突,所以在数据进行提交更新的时候,才会正式对数据是否产生并发冲突进行检测,如果发现并发冲突了,则让返回用户错误的信息,让用户决定如何去做。悲观锁:总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这 样别人想拿这个数据就会阻塞直到它拿到锁。比如说,我们这里去年12月那个时候出现疫情了,悲观的人认为会封城(封城相当于“加锁”),而乐观的人就认为不会封城再比如,我想下午3点去租车行,想租一辆某品牌的的车(租车行这个品牌的车只有一辆),悲观的话,“那就是我考虑到万一下午3点这辆车被别人租走了,我就会租不到”,所以我提前给租车行打个电话提前预约这辆车(相当于加锁),如果预约成功了,才会真的去租车行取车,如果没预约成功,那就下次预约个时间租这辆车。乐观的话,“那就是我认为租车行,这辆车应该是没人租的”,所以我直接取租车行,去租这辆车(没加锁,直接访问资源),如果确实没人租,那我就可以直接租到,如果已经被人租走了,那就下次找个时间来租吧(虽然没加锁,但是能够识别出数据访问冲突)Synchronized 初始使用乐观锁策略. 当发现锁竞争比较频繁的时候, 就会自动切换成悲观锁策略.乐观锁的一个重要功能就是要检测出数据是否发生访问冲突. 我们可以引入一个 "版本号" 来解决.1.2 读写锁 & 普通互斥锁
普通的互斥锁:就如同synchroized,当两个线程竞争同一把锁,就会产生等待
读写锁:有两种情况,加读锁/加写锁
多个线程同时读同一个数据,线程安全没问题
多个线程都要写一个数据,线程安全就有问题
多个线程既要读也要写,线程安全也有问题
线程安全有问题就会涉及到 "互斥",也就会产生线程的挂起等待. 一旦线程挂起, 再次被唤醒就不知道隔了多久,因此尽可能减少 "互斥" 的机会, 就是提高效率的重要途径.读写锁特别适合于 "频繁读, 不频繁写" 的场景中.注意:Synchronized 不是读写锁,是普通互斥锁1.3 重量级锁 & 轻量级锁
轻量级锁:加锁解锁开销是比较小的 (纯用户态的加锁逻辑,开销是比较小的)
重量级锁,加锁解锁开销是比较大的 (进入内核态的加锁逻辑,开销是比较大的)
需要注意的是
重量级锁和轻量级锁,是从结果的角度看的,最终加锁解锁操作消耗的时间是少还是多
而乐观锁和悲观锁,是从加锁的过程上看的,加锁解锁过程中干的工作是少还是多
通常情况下,干的工作多,消耗的时间就多
所以,一般乐观锁比较轻量,悲观锁比较重量,但这也不绝对
synchronized 开始是一个轻量级锁. 如果锁冲突比较严重, 就会变成重量级锁1.4 自旋锁 & 挂起等待锁
自旋锁:是轻量级锁的一种典型实现
(如果获取锁失败, 立即再尝试获取锁, 无限循环, 直到获取到锁为止. 第一次获取锁失败, 第二次的尝试会在极短的时间内到来.自旋就类似于这样的“忙等”,消耗大量的CPU,反复询问当前锁是否就绪)
挂起等待锁:是重量级锁的一种典型实现
(如果获取失败,就一直在等待,可能会在很久之后才可以获取到锁)
自旋锁:优点 : 没有放弃 CPU, 不涉及线程阻塞和调度 , 一旦锁被释放 , 就能第一时间获取到锁 .缺点 : 如果锁被其他线程持有的时间比较久 , 那么就会持续的消耗 CPU 资源 . ( 而挂起等待的时候是不消耗 CPU 的 ).乐观锁的部分是基于自旋锁实现的,悲观锁部分是基于挂起等待锁实现的synchronized 中的轻量级锁策略大概率就是通过自旋锁的方式实现的.1.5 公平锁 & 非公平锁
公平锁:遵守“先来后到”的规则来获取锁非公平锁:遵守“一起竞争”的规则来获取锁比如,三个线程A B C ,A先尝试获取锁,获取成功后,B想再获取锁,就会失败,阻塞等待;C下面也尝试获取锁,C也获取失败,阻塞等待。当A释放锁时,公平锁就是,先来后到,那么B就先比C获取到锁非公平锁就是,一起竞争,那么B C都有可以获取到锁操作系统内部的线程调度就可以视为是随机的 . 如果不做任何额外的限制, 锁就是非公平锁. 如果要想实现公平锁, 就需要依赖 额外的数据结构 , 来记录线程们的先后顺序 .synchronized 是非公平锁.1.6 可重入锁 & 不可重入锁
可重入锁:允许同一个线程多次获取同一把锁,不会死锁不可重入锁:不允许同一个线程多次获取同一把锁,会死锁Java里只要以 Reentrant 开头命名的锁都是可重入锁,而且 JDK 提供的所有现成的 Lock 实现类,包括 synchronized关键字锁都是可重入的。而 Linux 系统提供的 mutex 是不可重入锁.synchronized 是可重入锁1.7 synchronized的锁策略
synchronized 自适应锁,既是乐观锁,也是悲观锁;既是轻量级锁 ,也是重量级锁 ;
轻量级锁部分是基于自旋锁实现,重量级锁时基于挂起等待锁实现;不是读写锁;
是非公平锁;是可重入锁;
2. CAS
2.1 理解CAS
CAS全称 “compare and swap”(比较并交换)
一个CAS操作
(a)把内存中的某个值,和CPU寄存器A中的值,进行比较,
(b)如果两个值相同,就把另一个寄存器B中的值和内存的值进行交换,
(把内存的值放到寄存器B,同时把寄存器B的值写给内存)
(c)返回操作是否成功
再通俗一些就是,
假设内存中的原数据V,旧的预期值A,和需要修改的新值B
(a)比较旧的预期值A,和原数据V是否相等
(b)如果比较相等,就需要将原数据V修改为新的值B
(c)返回操作是否成功
需要注意这组操作,是通过一个CPU指令完成的,是原子的
所以线程安全,并且高效
当多个线程同时对某个资源进行 CAS 操作,只能有一个线程操作成功,但是并不会阻塞其他线程 , 其他线程只会收到操作失败的信号。(可以将CAS看成乐观锁的一种实现方式)2.2 CAS的应用
(1)实现原子类
在多线程之二中,count++在多线程环境下,线程是不安全的,要想安全就要加锁,加锁性能就会降低,此时我们就可以基于CAS操作来实现“原子”的++,从而保证线程安全并且高效
下面看一下伪代码

(2)实现自旋锁
纯用户态的轻量级锁,当发现锁被其他线程占有时,另外的线程不会挂起等待,而是会反复询问,看当前的锁是否被释放了
自旋锁时属于消耗CPU资源,但换来的是第一时间获取到锁,如果当时预期锁竞争不太激烈时,就非常适合自旋锁了
自旋锁是轻量级锁,也是一个乐观锁

2.3 CAS的ABA问题
ABA就属于CAS的缺陷
在CAS中,进行比较时,寄存器A和内存M的值相同,
我们无法判断是M始终没变,或者是M变了,但又变回来了
ABA在大部分情况下都没问题,能提高效率还能保证线程安全,但也有这种特殊情况,比如
我有1000元存款,想去银行ATM机上取500,ATM机上创建了两个线程,都并发的执行-500操作
正常情况下肯定是,一个线程执行-500,另一个线程-500失败 阻塞等待
如果使用CAS就会出现这样的问题
a)存款1000,线程1获取到当前存款值为1000,希望更新为500;线程1获取到当前存款值为1000,期望更新为500
b)线程1扣款成功,存款被改为了500,线程2 阻塞等待中
c)在线程2执行之前,我朋友给我转账了500,此时账户余额又变为了1000
d)轮到线程 2执行时,发现当前存款为1000,和之前读到的1000相同,再次进行扣款操作
此时,扣款操作被执行了两次,这个就是CAS中的ABA问题
解决方法
只要有一个记录,能够记录上 内存 中数据的变化,就可以解决ABA的问题了
记录就是
另外搞一个内存,保存M的“修改次数”(版本号)或者是“上次修改时间”通过这个方法,就可以解决ABA问题
此时前面的修改操作,就不是把账户余额读到寄存器A中了,比较的时候也不是比较账户余额,而是比较版本号/上次修改时间
如果当前版本号和读到的版本号相同 , 则修改数据 , 并把版本号 + 1.如果当前版本号高于读到的版本号 . 就操作失败 ( 认为数据已经被修改过了 ).还是上面的例子,不过这次我们在CAS中引入版本号,来解决ABA问题我还是有1000存款,想去银行ATM机上取500,ATM机上创建了两个线程,都并发的执行-500操作a)存款1000,线程1获取到存款值为1000,版本号为1,期望更新为500;线程2获取到存款值为1000,版本号为1,期望更新为500b)线程1扣款成功,存款被修改为500,版本号改为2,线程2阻塞等待中c)在线程2执行之前,我朋友给我转账500,账户余额变为1000,版本号为3d)等到线程2执行之前,发现当前存款1000,和之前读到的1000相同,但是当前版本号为3,之前读到的版本号为1,版本号小于当前版本,认为操作失败3. synchronized原理
synchronized的作用就是“加锁”,当两个线程针对同一个对象加锁时,就会出现锁竞争
后面尝试加锁的线程就要阻塞等待,直到前一个线程释放锁
3.1 加锁过程
synchronized加锁的具体过程
(1)偏向锁
(2)轻量级锁
(3)重量级锁
synchroized更多的是考虑降低程序员使用负担,所以内部就实现了“自适应”的操作
如果当前场景中,锁竞争不激烈,则是以轻量级锁状态来进行工作(自旋)第一时间拿到锁
如果当前场景中,锁竞争激烈,则是以重量级锁状态来进行工作的(挂起等待),拿到锁不太及时,但节省了CPU开销
偏向锁
偏向锁类似于“懒汉模式”,必要时再加锁,能不加就不加
但标记还是得做,否则无法区分何时需要真正加锁
偏向锁不是真加锁,而是只是设置一个状态(偏向锁的标记),记录这个锁属于哪个线程
如果没发生锁竞争就,避免了加锁解锁的开销
当真的发生锁竞争时,就取消原来的偏向状态,进入轻量级锁状态(前面已经记录了,当前锁属于哪个线程,就很容易识别是不是之前记录的)

无竞争,偏向锁
有竞争,轻量级锁
竞争激烈,重量级锁
锁升级/锁碰撞,JVM实现synchronized的时候,为了方便程序员使用,引入的一些优化机制
3.2 其他的优化操作
(1)锁消除
JVM自动判断,发现这个地方的代码,不必加锁,如果你写了synchronized就会自动的把锁去掉
比如,当前虽然有多个线程 ,多个线程不涉及修改同一个变量,如果代码中写了synchronized,此时synchronized加锁操作,就会直接被JVM给优化了
synchrozied加锁虽然是先偏向锁,而偏向锁只是改了个标志位,这个的开销应该不大吧,但即使是这样,如果能够消除,这样的开销还是要省的
锁消除是一种编译器优化的行为,而编译器优化,不一定非常准确
所以如果代码的锁100%能够消除,那就消除。如果这个代码的锁,判断不准确不知道能不能消除,那就还是不消除了
锁消除只有在编译器/JVM有十足把握时才能够进行
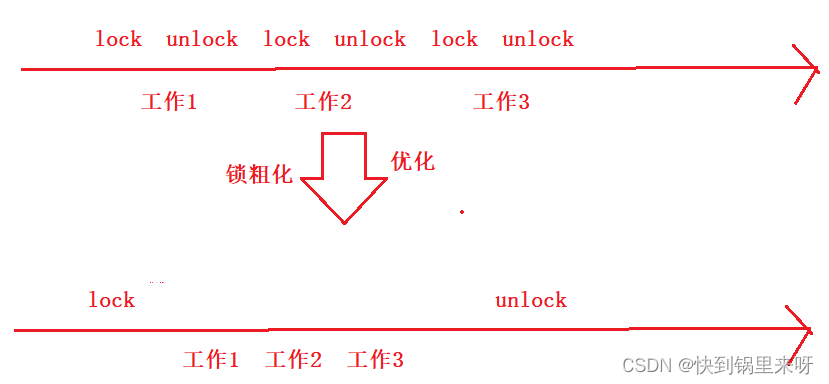
(2)锁粗化
锁的粒度,synchronized对应的代码块包含多少代码
包含的代码少,粒度细;包含的代码多,粒度粗
锁粗化就是,把细粒度的加锁,转化为粗粒度的加锁
-
相关阅读:
【面试:并发篇26:多线程:两阶段终止模式】volatile版本
Ceres学习笔记001--初识Ceres
每日一练Day04:寻找单身狗
MySQL34道例题
线性代数之矩阵
SpringBoot Redis 基础使用
【JavaEE初阶】 CSS相关属性,元素显示模式,盒模型,弹性布局,Chrome 调试工具||相关讲解
1个小时!从零制作一个! AI图片识别WEB应用!
Visual Studio 2022开发小技巧----内置任务列表
Ubuntu22.04配置WiFi
- 原文地址:https://blog.csdn.net/m0_58761900/article/details/126966562