-
pix2pix-论文阅读笔记
pix2pix
论文地址:Image-to-Image Translation with Conditional Adversarial Networks-ReadPaper论文阅读平台
论文结构
- Introduction
- Related work
- Method
3.1 Objective
3.2 Network architectures
3.2.1 Generator with skips
3.2.2 Markovian discriminator
(PatchGAN)
3.3 Optimization and inference - Experiments
4.1 Evaluation metrics
4.2 Analysis of the objective function
4.3 Analysis of the generator architecture
4.4 From PixelGANs to PatchGANs to ImageGANs
4.5 Perceptual validation
4.6 Semantic segmentation
4.7 Community-driven Research - Conclusion
摘要
原文
We investigate conditional adversarial networks as a general-purpose solution to image-to-image translation problems. These networks not only learn the mapping from input image to output image, but also learn a loss function to train this mapping. This makes it possible to apply the same generic approach to problems that traditionally would require very different loss formulations. We demonstrate that this approach is effective at synthesizing photos from label maps, reconstructing objects from edge maps, and colorizing images, among other tasks. Indeed, since the release of the pix2pix software associated with this paper, a large number of internet users (many of them artists) have posted their own experiments with our system, further demonstrating its wide applicability and ease of adoption without the need for parameter tweaking. As a community, we no longer hand-engineer our mapping functions, and this work suggests we can achieve reasonable results without hand-engineering our loss functions either.
核心
- 研究条件生成式对抗网络在图像翻译任务中的通用解决方案
- 网络不仅学习从输入图像到输出图像的映射,还学习了用于训练该映射的损失函数
- 证明了这种方法可以有效应用在图像合成、图像上色等多种图像翻译任务中
- 使用作者发布的pix2pix软件,大量用户已经成功进行了自己的实验,进一步证明了此方法的泛化性
- 这项工作表明可以在不手工设计损失函数的情况下,也能获得理想的结果
背景
数字图像任务
- 计算机视觉(Computer Vision)
模仿人眼和大脑对视觉信息的处理和理解图像分类,目标检测,人脸识别 - 计算机图形学(Computer Graphics )
在数字空间中模拟物理世界的视觉感知动画制作,3D建模,虚拟现实 - 数字图像处理(Digital Image Processing)
依据先验知识,对图像的展现形式进行转换图像增强,图像修复,相机ISP

图像翻译(Image Translation)
图像与图像之间以不同形式的转换。根据 source domain 的图像生成 target domain 中的对应图像,约束生成的图像和 source 图像的分布在某个维度上尽量一致

- 图像修复
- 视频插帧
- 图像编辑
- 风格迁移
- 超分辨率
研究成果




模型结构
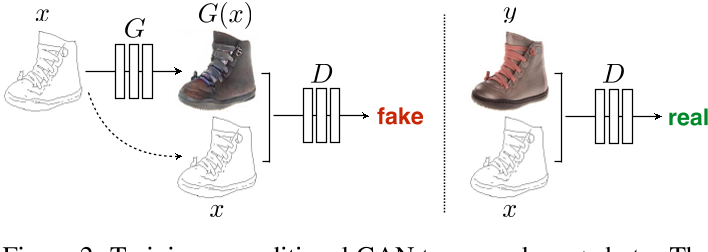
Generator
Unet
- 基于经典的Encoder-decoder结构
- 在很多图像翻译任务中,输出和输出图像外观看起来不同,但结构信息是相同的
- 在Encode过程中,feature map的尺寸不断减小,低级特征将会丢失
- 在第 i 层与第 n–i 层间加入skip-connection,把 i 层的特征直接传到第 n–i 层

Discriminator
PatchGAN
- 像素级的l1 loss能很好的捕捉到图像中的低频信息,GAN的判别器只需要关注高频信息
- 把图像切成 N*N 的patch,其中N显著小于图像尺寸
- 假设在大于N时,像素之间是相互独立的,从而可以把图像建模成马尔科夫随机场
- 把判别器在所有patch上的推断结果,求平均来作为最终输出
- 可以把PatchGAN理解为对图像 纹理/style损失 的计算
- PatchGAN具有较少的参数,运行得更快,并且可以应用于任意大的图像
训练细节
- 采用原始GAN的loss替换技巧,把最小化 log(1-D(x, G(x, z)) ,替换成最大化 logD(x, G(x, z))
- 生成器和判别器的训练次数为1:1,训练速度为2:1,稍稍降低判别器的优化速度
- 使用Adam优化器,学习速率为2e-4
- Batch size在 1-10 之间,不同的数据集上有所区别
- 推断时保留dropout,来增加输出的随机性
- 推断时使用batch为1的batch normalization,实际是就是 instance normalization
- instance normalization 仅在图像内部进行操作,可以保留不同生成图像之间的独立性
目标函数
- Loss由 传统像素loss 和 Gan loss组成
- l1 loss 比l2 loss 更能减少生成图像的模糊
- 初始层的随机噪声z,在训练过程中会被忽略,导致网络的条件输入只对应固定的输出
- 在推断时,通过保留dropout来产生轻微的随机性
- 如何得到更大随机性的生成结果,更完整的去拟合输入的分布,仍然有待研究

模型评估
人工评价
-
Amazon Mechanical Turk(AMT)
任务:地图生成,航拍照片生成,图像上色 -
限制观看时间,每张图像停留一秒钟,答题时间不限
-
每次评测只针对一个算法,包含50张图像
-
前10张图像为练习题,答题后提供反馈,后40张为正式标注
-
每批评测数据由50个标注者标注,每个评测者只能参与一次评测
评测不包含测验环节
FCN-score
-
判断图像的类别是否能被模型识别出来,类似于Inception Score
-
使用应用于语义分割任务的流行网络结构——FCN-8s,并在cityscapes数据集上进行训练
-
根据网络分类的精度,来对图像的质量进行打分由于图像翻译不太关注生成图像的多样性,所以不需要像 Inception Score 一样关注总体生成图
像的分布
实验分析
目标函数分析
- 只使用L1 loss,结果合理但模糊
- 只使用cGAN loss,结果锐利但存在artifacts
- 通过对L1 loss和cGAN loss进行一定的加权
(100:1),可以结合两者的优点 - 只使用GAN loss,生成图像发生模式崩溃
- 使用GAN + L1,结果与CGAN + L1 类似

- 光谱维度中的情况,与像素维度上的情况类似
- 只使用L1 loss,更倾向于生成平均的浅灰色;使用cGAN loss,生成的色彩更接近真实情况

生成器分析
Encoder-Decoder VS U-Net
在两种loss下,U-net的效果都显著优于Encoder-Decoder

判别器分析
比较不同的Patch大小的差异,默认使用L1 + cGAN loss
11的Patch相比于L1 loss,只是增强了生成图像的色彩使用1616的Patch,图像锐度有所提升,但存在显著的tiling artifacts
使用70*70的Patch,取得了最佳效果
使用286286的完整图像输入,生成结果比7070的要差,
因为网络的参数量大很多,训练更难以收敛
应用分析
Map-Photo
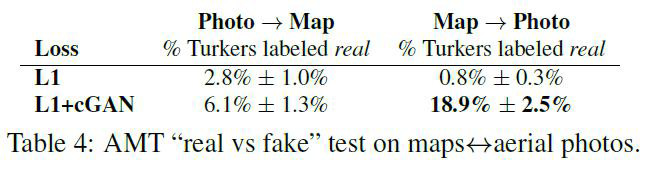
- Map to Photo,L1 + cGan loss的结果显著优于 L1 loss
- Photo to Map,L1 + cGan loss的结果接近于只使用 L1 loss
- 这可能是因为Map相比对Photo,几何特性要显著的多
图像上色
- L1 + cGan loss的结果,与只使用L2 loss的结果较为接近
- 相比此前专门针对图像上色问题的方法,效果仍有较大差距

语义分割

-
只使用cGAN loss时,生成的效果和模型准确度还可以接受
-
使用L1 + cGAN loss,效果反而不如只使用 L1 loss
-
说明对于CV领域的问题,传统loss可能就够了,加入GAN loss无法获得增益
结论
- 条件对抗网络在许多图像翻译任务上都非常有应用潜力
- 特别是在高度结构化图形输出的任务上
- 使用不同的数据集训练pix2pix,可以用于各种图像翻译任务
-
相关阅读:
10年程序员,想对新人说什么?
九、MySQL之视图的介绍
Java——泛型与通配符的详解
MySqL速成教程笔记系列九
Nginx的Map模块
spark基础
Java中set集合简介说明
C#中使用list封装多个同类型对象以及组合拓展实体的应用
arima模型python代码
Linux学习笔记(7) -- 文件管理(中)
- 原文地址:https://blog.csdn.net/weixin_43499292/article/details/127102905