-
【pytorch】有关nn.EMBEDDING的简单介绍
1. 引例
假设有一本字典,就一共只有10单词,每个单词有5个字母组成。 每一页上只写一个单词,所以这10页纸上分别写了这10个单词。
内如如下,
[ [a,p,p,l,e], # page 0 [g,r,e,e,n], # page 1 [s,m,a,l,l], # page 2 [w,a,t,c,h], # page 3 [b,a,s,i,c], # page 4 [e,n,j,o,y], # page 5 [c,l,a,s,s], # page 6 [e,m,b,e,d], # page 7 [h,a,p,p,y], # page 8 [p,l,a,t,e] # page 9 ]我们假定这本字典叫embeding(10,5), 这里的10和5即上面介绍的含义,10个单词,每个单词5个字母;
现在我要查看第2页和第3页(从0开始),那么我会得到 [s,m,a,l,l], [w,a,t,c,h] 内容。
假定我们约定一个暗号,你告诉我页数,我就返回对应页数的单词。
如,你发给我暗号 [ [2,3], [1,0], [8,6] ] (即 shape为(3,2)的LongTensor)
我通过查询字典,告诉你
[ [ [s,m,a,l,l], [w,a,t,c,h] ], [ [g,r,e,e,n], [a,p,p,l,e] ], [ [h,a,p,p,y], [c,l,a,s,s] ] ]这里的字典就是embeding table,而暗号就是查询这个table的索引值。
2. 为什么需要embeding?
有的时候我们直观看到的不一定就是事物的本质,我们需要透过现象看到“本质特征”或“隐藏特征”。 那么怎么透过呢? 或者说什么是“隐藏特征”呢?
embeding就是做这个事情,它将一句话,或者一段音通过查询“embeding table”来获取到“隐藏特征”。
embeding table一般是一组浮点型数值,它跟CNN,LSTM网络中一样,属于网络可学习的参数。
所以它的值不是人为定义的,人也定义不了这样的“字典”,它是通过深度学习网络中逐渐学习到的。
3. 回到pytoch
pytorch中的nn.Embeding提供了这样的实现;
下面是一个例子
import torch # 如同上面例子中的page索引 a = torch.LongTensor([[1,2], [5,2]]) # 一个10个单词,每个单词5个字母的字典 emb = torch.nn.Embedding(10,5) print(emb.weight, emb.weight.shape) # 同过索引查询embeding内容 y = emb(a) print(y, y.shape)
可以看到“字典”不再是单词,而是一些浮点数,这些浮点数表示的就是隐藏特征。
4. 官方API
4.1参数介绍
4.1.1 num_embedding和embedding_dim
num_embedding, embedding_dim就是上文中介绍 “单词”和“每个单词字母个数”,它表示了字典中embedding个数,以及每个embedding的维度。
4.1.2 padding_idx
padding_idx,是不更新梯度的“单词”的index;可以在字典中指定一个不被训练的embedding。
看下面的例子:import torch a = torch.LongTensor([[1,2], [5,2]]) emb = torch.nn.Embedding(10,5, padding_idx=0) print(emb.weight, emb.weight.shape) y = emb(a) print(y, y.shape)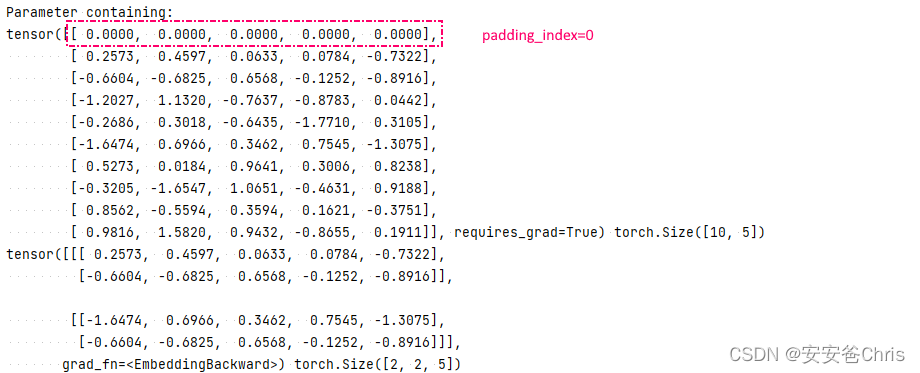
这里的padding_index=0,它表示该index下的embedding不会学习更新,初始化的时候默认也是0.4.1.3 max_norm和norm_type
max_norm,norm_type是获取到embedding后做正则化;
norm_type 的可取值为1,2. 分别表示范式1和范式2,默认是2.max_norm是定义范式中的最大值,如果embeding中的值大于这个阈值,则会重新做一下norm
-
相关阅读:
什么是杜邦分析?杜邦分析法的公式及示例
前端例程20221102:黑暗模式(Dark Mode)
vue的函数式组件
HOOPS Communicator对3D大模型轻量化加载与渲染的4种解决方案
Advanced .Net Debugging 4:基本调试任务(对象检查:内存、值类型、引用类型、数组和异常的转储)
云原生架构实践前言
最新Workerman 在线客服系统源码/附搭建教程-ThinkPHP网站在线客服系统源码
如何创建多语言WordPress网站[专家建议]
DailyPractice.2023.10.22
一体成型PFA尖头镊子高纯特氟龙材质镊子适用半导体新材料
- 原文地址:https://blog.csdn.net/mimiduck/article/details/127095433
