-
分类分析——作业
作业1——二分类:信贷风险评估
我们想知道银行贷款审批中是否存在种族歧视,这是一个非常典型的“推断”问题,于是可采用线性回归分类模型对该问题进行探究。本次习题使用数据loanapp.dta,所使用的变量解释如下:
因变量:
· approve:贷款是否被批准(0为不批准、1为批准)
自变量:
· white:种族哑变量(0为黑人,1为白人)
· obrat:债务占比
由于数据集含有缺失值,我们先去除含有缺失值的样本(非习题)
loan=pd.read_stata(‘./data/loanapp.dta’)# 选取要用的变量组成新的数据集 loan=loan[["approve","white","hrat","obrat","loanprc","unem","male","married","dep","sch","cosign","chist","pubrec","mortlat1","mortlat2","vr"]] loan.dropna() #去除含缺失值样本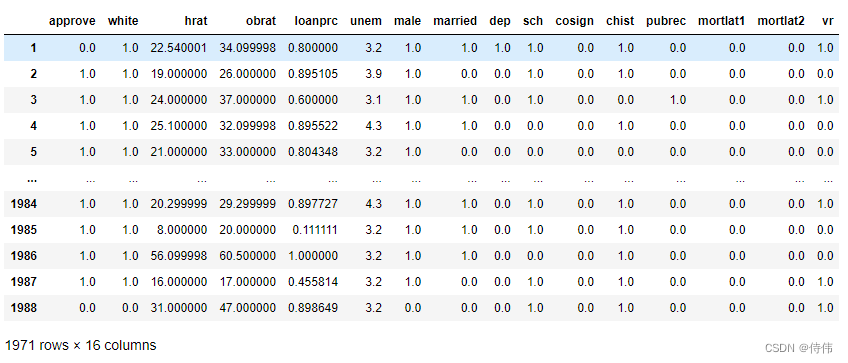
使用python进行实操并回答以下问题
(1):先考虑一个线性概率模型
a p p r o v e = β 0 + β 1 w h i t e + u approve = \beta_0+\beta_1white+u approve=β0+β1white+u
如果存在种族歧视,那么 β 1 \beta_1 β1的符号应如何?如果存在种族歧视,那么 β 1 \beta_1 β1的符号应该为正,代表白人更容易被批准贷款。
(2):用OLS估计上述模型,解释参数估计的意义,其显著性如何?在该模型下种族歧视的影响大吗?
approve_lm=sm.formula.ols('approve~white+obrat',data=loan).fit() print(approve_lm.summary())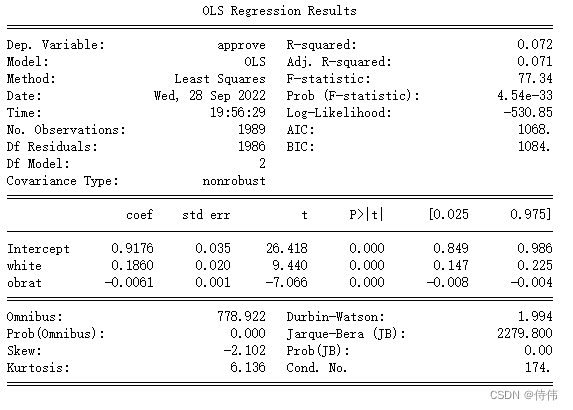
white参数为正,并且显著,代表白人更容易被批准贷款;
obrat参数为负,并且显著,代表债务占比越高,越不容易被批准贷款。
在该模型下,种族歧视有影响,但系数不大。(3):在上述模型中加入数据集中的其他所有自变量,此时white系数发生了什么变化?我们仍然可以认为存在黑人歧视现象吗?
approve_lm1=sm.formula.ols('approve~white+obrat+hrat+loanprc+unem+male+married+dep+sch+cosign+chist+pubrec+mortlat1+mortlat2+\ +vr',data=loan).fit() print(approve_lm1.summary())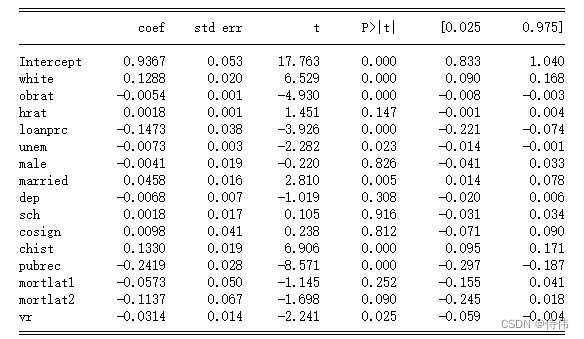
white系数变小了,仍然为正,并且显著,可以认为存在黑人歧视现象。(4):允许种族效应与债务占比(obrat)有交互效应,请问交互效应显著吗?请解读这种交互效应。
approve_lm2=sm.formula.ols('approve~white+obrat+hrat+loanprc+unem+male+married+dep+sch+cosign+chist+pubrec+mortlat1+mortlat2+\ +vr+I(white*obrat)',data=loan).fit() print(approve_lm2.summary())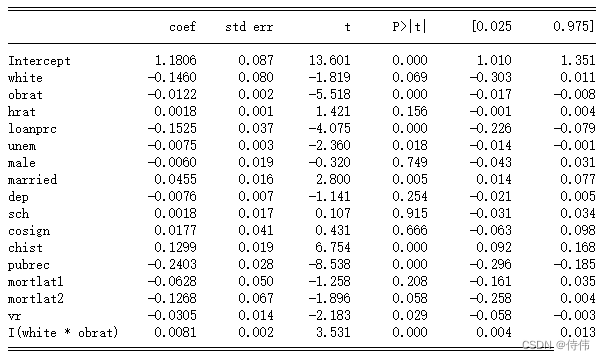
交互效应显著,此时白人系数不显著,但白人且负债的效应显著,并为正,说明白人负债对贷款的影响比黑人小。(5):使用logit模型与probit模型重新(3)中的模型,观察变量系数及其显著性的变化。
approve_logit=sm.formula.logit('approve~white+obrat+hrat+loanprc+unem+male+married+dep+sch+cosign+chist+pubrec+mortlat1+mortlat2+\ +vr',data=loan).fit() print(approve_logit.summary())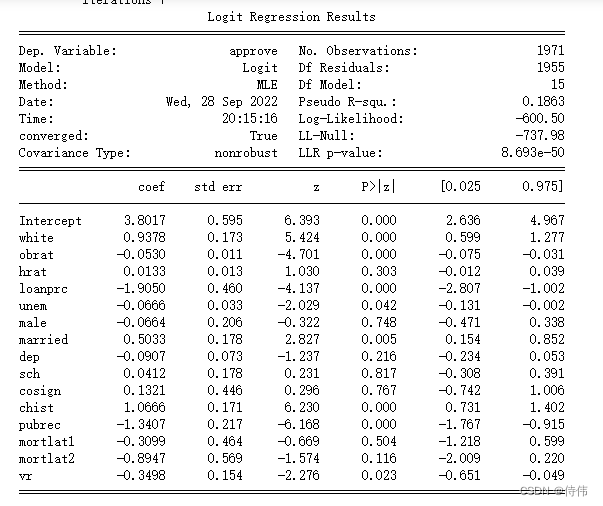
approve_probit=sm.formula.probit('approve~white+obrat+hrat+loanprc+unem+male+married+dep+sch+cosign+chist+pubrec+mortlat1+mortlat2+\ +vr',data=loan).fit() print(approve_probit.summary())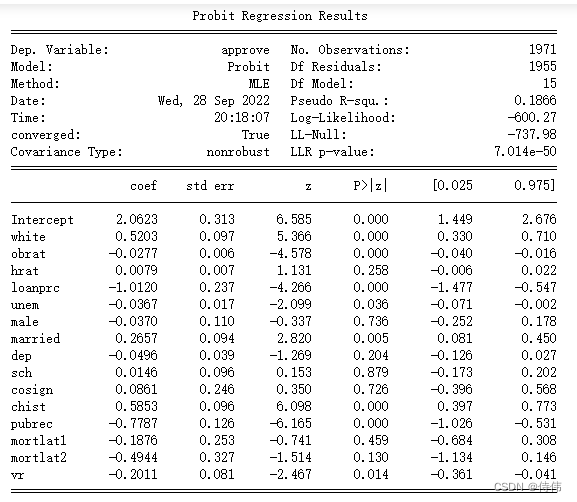
作业2——多分类:鸢尾花分类问题
鸢尾花分类问题是经典的多分类问题,我们使用sklearn的logisticRegression求解该问题。
# 下载数据集 from sklearn.datasets import load_iris iris_dataset=load_iris() # 提取数据集中的自变量集与标签集 iris_data=iris_dataset['data'] # 自变量 iris_target=iris_dataset['target'] # 标签集使用python进行实操并回答以下问题
(1):将原数据集划分为训练集与测试集,两者样本比例为3:1。# 加载函数 from sklearn.model_selection import train_test_split # 数据集切分 X_train,X_test,y_train,y_test=train_test_split(iris_data,iris_target,test_size=0.25,random_state=0) # test_size为测试集数据量占原始数据的比例 print('train_size',len(X_train)/len(iris_data)) print('test_size',len(X_test)/len(iris_data))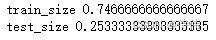
(2):使用训练集数据训练logistic回归模型,并分别对训练集与测试集数据进行预测,并将预测的结果分别储存在两个自定义的变量中。from sklearn.linear_model import LogisticRegression # 使用训练集进行训练 iris_logit_multi=LogisticRegression(multi_class='multinomial').fit(X_train,y_train) # 使用测试集进行预测 y_pred=iris_logit_multi.predict(X_test) # 查看预测结果 print(y_pred)[2 1 0 2 0 2 0 1 1 1 2 1 1 1 1 0 1 1 0 0 2 1 0 0 2 0 0 1 1 0 2 1 0 2 2 1 0
2]# 使用训练集进行预测 y_train_pred=iris_logit_multi.predict(X_train) # 查看预测结果 print(y_train_pred)[1 1 2 0 2 0 0 1 2 2 2 2 1 2 1 1 2 2 2 2 1 2 1 0 2 1 1 1 1 2 0 0 2 1 0 0 1
0 2 1 0 1 2 1 0 2 2 2 2 0 0 2 2 0 2 0 2 2 0 0 2 0 0 0 1 2 2 0 0 0 1 1 0 0
1 0 2 1 2 1 0 2 0 2 0 0 2 0 2 1 1 1 2 2 1 2 0 1 2 2 0 1 1 2 1 0 0 0 2 1 2
0](3):使用函数接口计算出:模型对训练集数据的分类正确率、模型对测试集数据的分类正确率,比较它们孰高孰低,并思考为什么会有这样的差异。
# 查看分类精度 print('测试集分类精度',iris_logit_multi.score(X_test,y_test)) # 传入需要进行预测数据集自变量与真实标签集 # 查看分类精度 print('训练集分类精度',iris_logit_multi.score(X_train,y_train)) # 传入需要进行训练数据集自变量与真实标签集测试集分类精度 0.9736842105263158
训练集分类精度 0.9821428571428571训练集的精度更高,因为在训练集上会产生过拟合现象。
(4):给出测试集数据的混淆矩阵以及精确率、召回率、f分数的综合报告。
# 混淆矩阵 display(confusion_matrix(y_test,y_pred)) # 综合指标 print(classification_report(y_test,y_pred))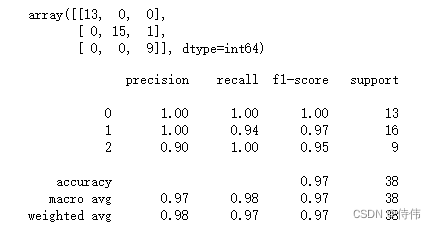
感谢Datawhale
感谢Gitmodel
参考文献
【教程地址】https://github.com/Git-Model/Modeling-Universe/tree/main/Data%20Analysis%20and%20Statistical%20Modeling
【备用gitee地址】https://gitee.com/mr-yinbob/Modeling-Universe/tree/main/Data%20Analysis%20and%20Statistical%20Modeling
————————————————
版权声明:本文为CSDN博主「侍伟」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_43595036/article/details/127029337 -
相关阅读:
node.js的模块化
【React】02-React面向组件编程
高效模拟,灵活扩展!GNSS模拟器的多实例应用浅析(二)
Spring基础篇:MVC框架整合
迅雷下载宝-openwrt-kodexplorer
基于蛙跳算法求解简单调度问题附matlab代码
别看了,这就是你的题呀(四)
3主3从redis集群配置(docker中)
SQLite—免费开源数据库系列文章目录
Git学习笔记2
- 原文地址:https://blog.csdn.net/weixin_43595036/article/details/127097316