-
编写递归SQL的思路
契机
前段时间,我遇到了一个需求,就是需要按照中图法去分类图书,然后需要根据分类查找下属所有类别的图书。需求不难,Java原生递归也能实现,只不过是在程序中执行递归操作然后频繁访问数据库获取最终结果,我觉得这样不好,频繁从连接池拿连接去访问数据库消耗了许多不必要的资源,于是就想着直接从sql层面解决这个问题,于是就有了这篇笔记。
场景描述
中图法其实就是按类别去区分图书,大类下面又细分小类,直到无法细分,比如三国演义属于历史大类,然后属于历史大类中的中国历史…,具体模型是一个多叉树,大概这样
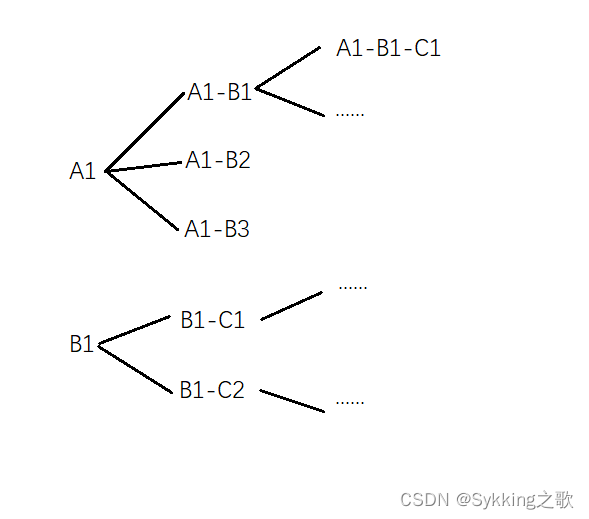
那么在MySQL中我是这样存储的(表名classify)
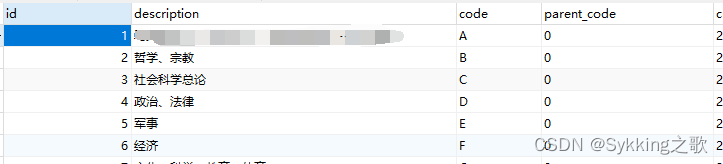
核心其实一共就四个列,分析下
- id没有什么特别的,自动增长的唯一主键
- description就是对该类的描述
- code是唯一类别的识别码
- parent_code就是标识该类是否属于某个类别下的子类,如果不是的话就为0,是就为父类code
那么到此为止就很明了了,假如我现在有一个book表,存放的是书籍的信息,其中有个外键classify_id绑定该表中的某一个主键id,表示该书属于某个类别,那么我现在有两个需求
- 我需要查出某个类别下的所有子类的id(包括自己)
如下图所示,给定A1-B1这个类别,需要查询出包括A1-B1下的所有子类的id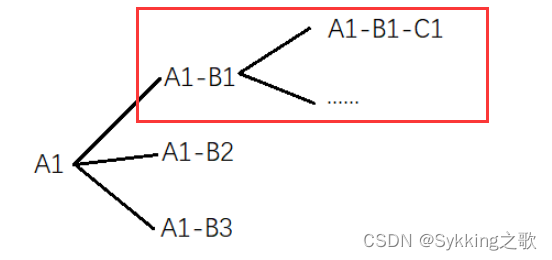
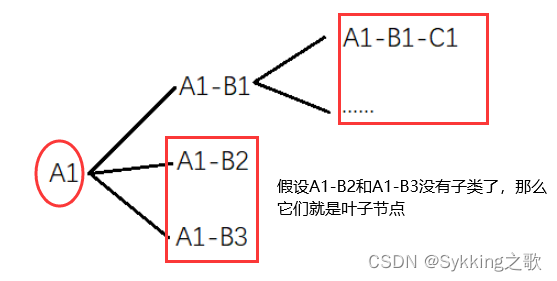
- 我需要查出某个类别下的叶子节点的id
如图所示,给定A1,查询叶子节点
SQL实现
我需要查出某个类别下的所有子类的id(包括自己)
SELECT @codes '父类code', (SELECT @codes :=group_concat(code) FROM classify WHERE find_in_set(parent_code,@codes)) '直接子类code' FROM classify t1,(SELECT @codes :='A') t2 WHERE @codes IS NOT NULL 解析:我们分析一下这段SQL,首先是可以看到SELECT了两个字段,FROM一张表和定义一个变量codes,WHERE后跟一个条件 -- 1.From classify表和定义@codes变量 并生成初始结果集 (其他select和where什么都没做呢) -- 2.where 条件排除掉@codes为空的数据(此时没有排除任何数据,因为@codes的值为'A',不为 --空,通过From生成的笛卡尔积每条都有该字段) -- 3.开始处理select后的列,此时有两个列,一个是@codes,一个是(SELECT @codes :=group_c --oncat(code) FROM classify WHERE find_in_set(parent_code,@codes))。第二个列是通过一 --个sql语句查询出的结果,下面就开始递归了, 第一行: 首先正常输出第一列@codes变量中的值,然 --后通过执行第二列的sql语句生成当前@codes变量值的直接子类通过group_concat函数连接结 --果,然后赋值给@codes(此时@codes变量已被重新赋值) --TIPS:这里由于@codes的值被改变了,导致结果集的数据都被改变了,然后where子句重新执行, --过滤掉@codes为空的数据然后执行下一步继续处理select后的列 -- 第二行: -- 正常输出@codes变量中的值,然后通过执行第二列的sql语句生成当前@codes变量值的直接子类, --通过group_concat函数连接结果,然后赋值给@codes(此时@codes变量已被重新赋值) --TIPS:这里由于@codes的值被改变了,导致结果集的数据都被改变了,然后where子句重新执行, --过滤掉@codes为空的数据然后执行下一步继续处理select后的列 --以此类推...直到@codes为空为止 输出结果进行最终显示SQL实现
我需要查出某个类别下的叶子节点的id
这个需求要比上面的稍微麻烦一点,可以先分析一下,我们如果要查询叶子节点,那么由于叶子节点是没有后代的,那么我们就可以先查询出某个类别下的所有的子类id,然后输出这些id对应数据的时候,附带查询该数据是否有子类,然后将该结果作为临时表进行筛选,没有子类的数据就是该类别下的叶子节点了
那么,我们如何判断该数据是否有子类呢?
答:很简单,我们可以通过查询parent_code=?的语句进行查询,然后以count(*)输出结果,只要count(*)不为0就代表查询出了对应的数据,那么就可以认为该?对应的数据是有子类的,所以我们可以最后通过count(*)这一列等于0筛选出我们想要的数据进行查询显示
SQL如下:SELECT temp.* FROM ( SELECT c2.*,(SELECT count(c1.id) FROM classify AS c1 WHERE c1.parent_code=c2.CODE) AS 'count' FROM classify c2 WHERE c2.id IN -- 该语句目的是拿到某个类别下的所有子类id ( SELECT classify.id FROM ( SELECT @ids _ids,(SELECT @ids :=group_concat(CODE) FROM classify WHERE find_in_set(parent_code,@ids)) sub FROM classify t1,(SELECT @ids :='A') t2 WHERE @ids IS NOT NULL ) temp,classify WHERE FIND_IN_SET(classify.CODE,temp._ids) ) -- 该语句目的是拿到某个类别下的所有子类id ) AS temp WHERE temp.count=0 -
相关阅读:
LeetCode 1465. 切割后面积最大的蛋糕:纵横分别处理
深入理解PKI
Web Components详解-Shadow DOM插槽
视频分析:走路看手机行为
向pycdc项目提的一个pr
项目经理7大步骤轻松跟进项目,让你带项目不再那么累
实验4 交换机端口隔离(access模式)_Cisco Packet Tracer 8.2.1
如何写好一个接口
Linux高并发连接数解决
LeetCode 1422. 分割字符串的最大得分
- 原文地址:https://blog.csdn.net/weixin_44001317/article/details/127097793