-
论文阅读 (74):A Review: Knowledge Reasoning over Knowledge Graph
1 概述
1.1 题目
2020:知识图谱与知识推理 (A review: Knowledge reasoning over knowledge graph)
1.2 摘要
大规模数据集上的知识挖掘依赖于推理技术。知识图谱作为知识表征的新类型,在自然语言处理中受到了极大关注。知识图谱可以有效地组织和表征知识,可以在高级应用程序中有效利用。知识图谱上的推理可以从已有数据上获得新的知识及结论。
本文回顾了知识推理的基本概念及定义,以及知识图谱上的一些推理方法。这些方法被分为三类:- 规则推理 (Rule-based reasoning);
- 分布表征推理 (Distributed representation-based reasoning);
- 神经网络推理 (Neural network-based reasoning)。
进一步回顾了知识图谱推理的相关应用,例如知识图谱完全、问答,以及推荐系统。最终对一些挑战进行了说明。
1.3 Bib
@article{Chen:2020:112948, author = {Xiao Jun Chen and Sheng Bin Jia and Yang Xiang}, title = {A review: {K}nowledge reasoning over knowledge graph}, journal = {Expert Systems with Applications}, volume = {141}, pages = {112948}, year = {2020} }2 引入
推理是模拟思维的基本形式之一,是从一个或几个已有判断 (前提) 中推导出新判断 (结论) 的过程。这也是为什么AlphaGo能够战胜中国棋手的原因—无与伦比的推理能力以及人工智能能够从小规模数据中发掘一些新的解释。因此,推理能力是至关重要的。DeepMind指出人工智能算法需要具备这种能力,且推理过程必须依赖于先验知识以及经验。
在知识功能的时代背景下,大量的知识图谱 (Knowledge graphs, KGs) 被开发,例如YAGO、WordNet,以及Freebase。KGs包含大量的先验知识,且能高效地组织数据。它们已经被广泛用于问答系统、搜索引擎,以及推荐系统。KGs能够从海量数据中挖掘、组织,以及有效管理知识,提高信息服务的质量,为用户提供更智能的服务。所有这些方面都依赖于知识推理,其是推理领域的核心技术之一。
KGs上的知识推理旨在识别错误并从已有数据集论断。实体之间的关系可以通过知识推理获取并以此馈赠KGs,以支持更高级别的应用。考虑到KGs的广泛应用前景,在大规模KGs上进行知识推理的研究成为近几年自然语言处理的研究热点之一。
本文贡献如下:
- 调研充分—147出版物;
- 直面问题;
- 方向评估—讨论未来研究。
3 知识推理
3.1 定义
推理技术源远流长,早在古希腊时间,著名哲学家亚里士多德便提出了三段论,其实现代演绎推理的基础。从定义计算机的Lambda演算到各种智能计算平台,从专家系统到大规模知识图谱,都离不开推理。对于知识推理的基本概念,学术界给出了不同的定义:
- Zhang和Zhang:推理是对各种事物进行分析、综合,以及决策的过程,从事实收集开始,发现事物之间的相互关系,以发展新的洞察力。简言之,推理是按照规则从现有事实中得出结论的过程;
- Kompridis:推理是一系列能力的统称,包括理解事物、应用逻辑,以及基于现有知识校准或验证架构的能力;
- Tari:知识推理是基于现有事实和逻辑规则推断新知识的机制。
综上,知识推理是以已知论未知的过程。
早期的推理研究由逻辑和知识工程领域的学者推进。逻辑学者主张用形式化的方法来描述客观世界,认为一切推理都是建立在已有的逻辑知识的基础上的,如一阶逻辑和谓词逻辑。他们总是关注如何从已知的命题和谓词中得出正确的结论。为了减轻推理过程的僵化,非单调推理和模糊推理等方法被开发,以便在更复杂的情况下使用。
与逻辑领域的学者使用命题或一阶谓词来表示客观世界中的概念不同,知识工程领域的学者使用语义网络来表示更丰富的概念和知识,以描述实体和属性之间的关系。然而,早期的KGs完全依赖于专家知识,其所属的实体、属性,以及关系完全由CyC等领域的专家来构建。
随着互联网数据规模的爆炸式增长,传统的基于人工构建的知识库 (Knowledge bases, KBs) 的方法已经不适应大数据时代对大量知识进行挖掘的需要。因此,数据驱动的机器推理方法逐渐成为知识推理研究的主流。
3.2 先进的KGs
2012年,Google推出了知识图谱项目,并利用它来提高查询结果的相关性和用户的搜索体验。由于Web资源量的增加和链接开放数据 (LOD) 项目的发布,已经构建了许多知识图谱。本节将简要介绍世界领先的知识图谱,如表2.
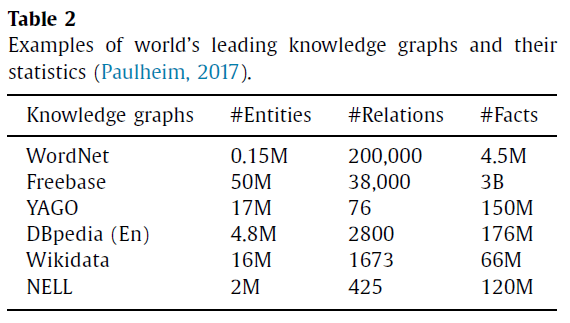
- WordNet:由普林斯顿大学认知科学实验室于1985年创建的英语语言词汇数据库。名词、动词、形容词,以及副词被分组为一组认知同义词 (synsets),每个都表达一个不同的概念。同义词通过概念–语义和词汇关系相互联系,例如狗和哺乳动物之间的IS-A 关系,或汽车和发动机之间的PART-WHOLE关系。WordNet已在信息系统中用于多种用途,包括词义消歧、信息检索、文本分类、文本摘要、机器翻译,甚至填字游戏生成。WordNet 3.0 版是可用的最新版本,包含超过 150,000个单词和200,000个语义关系;
- Freebase:由Metaweb构建的大型协作知识库,主要由其社区成员组成的数据组成。具体包含从Wikipedia、NNDB、Fashion Model Directory和MusicBrainz等收集的数据,以及由其用户提供的数据。Freebase的主题 (Subject) 被称为“Topic”,关于它们的数据存储取决于它们的“type”,type本身被分组为“domain”。Google的KGs部分由Freebase提供支持。目前Freebase中有大约30亿个三元组;
- YAGO:由Max Planck Institute开发的开源知识库。YAGO中的信息是从Wikipedia (例如类别、重定向、信息框)、WordNet (例如synsets、hyonymy) 和GeoNames中提取的。YAGO将WordNet的清晰分类法与Wikipedia类别系统的丰富性相结合,将实体分配到超过350,000个类别。进一步,其将时间维度和空间维度附加到它的许多事实和实体中,从10个不同语言的维基百科中提取和组合实体和事实。目前,YAGO拥有超过1700万个实体 (如个人、组织、城市等) 的知识,并包含超过1.5亿个关于这些实体的事实。YAGO已用于Watson人工智能系统;
- DBpedia:旨在从维基百科项目中创建的信息中提取结构化内容的一个跨语言项目。DBpedia和外部数据集 (包括 Freebase、OpenCyc等) 之间有超过4500万个链接,使用资源描述框架 (RDF) 来表示提取的信息。实体被分类在一个一致的本体 (Ontology) 中,包括人、地点、音乐专辑、电影、视频游戏、组织、物种和疾病。DBpedia被用作IBM Watson Jeopardy获奖系统中的知识源之一,并且可以集成到Amazon Web Services应用程序中;
- Wikidata:一个多语言、开放、链接、结构化的知识库,可供人和机器阅读和编辑。支持280多种语言版本的Wikipedia,具有通用的结构化数据源。Wikidata继承了Wikipedia的众包协作机制,也支持基于三元组的编辑。它依赖于项目和陈述的概念。一个项目代表一个实体,语句由一个主要的属性-值对组成,该对编码诸如“分类单元名称是 Pantera Leo”之类的事实和添加它有关信息的可选限定符,例如“分类单元作者是Carl Linnaeus”;
- NELL:由卡内基梅隆大学的一个研究团队开发的一种语义机器学习系统,可以全天候运行,学习阅读网络。NELL 的输入包括:1) 一个初始本体,定义了NELL预计会阅读的数百个类别和关系,以及2) 每个类别和关系的10到15个种子示例。给定这些输入,NELL会自动从Web 中提取三重事实。到目前为止,NELL 通过阅读网络已经积累了超过1.2亿个候选信念,并且它以不同的置信度来考虑这些,以及NELL用来提取的数百个学习的短语、形态特征和网页结构。
3.3 知识推理导向的KGs
随着KGs的发展,其上的推理受到了更广泛的关注。参照推理的定义,KGs上的推理定义如下:
定义1. KGs上的知识推理:给定一个知识图谱 K G = < E , R , T > KG=
其目标是使用机器学习方法推断实体对之间的潜在关系,并根据现有数据自动识别错误知识,以补充KGs。例如,如果KG 包含 (Microsoft,IsBasedIn,Seattle)、(Seattle,StateLocatedIn,Washington) 和 (Washington,CountryLocatedIn,USA) 这样的事实,那么我们将获得缺失的链接 (Microsoft,HeadquarterLocatedIn,USA)。知识推理的对象不仅是实体之间的属性和关系,还包括实体的属性值和本体的概念层次。例如,如果一个实体的身份证号码属性已知,则可以通过推理得到该实体的性别、年龄等属性。
KG基本上是一个语义网络和结构化的语义知识库,可以正式解释现实世界中的概念及其关系。 知识图谱不需要在结构化表达式中采用诸如框架和脚本等繁琐的结构,而是形式更灵活的简单三元组。因此,对知识图谱的推理不仅限于传统的基于逻辑和规则的推理方法,还可以是多种多样的。同时,知识图谱由实例组成,这使得推理方法更加具体。
近年来,研究人员实现了许多开放信息提取 (OIE) 系统,如TextRunner和WOE,其大大扩展了知识图谱构建的数据源。因此,丰富的知识库内容为知识推理技术的发展提供了新的机遇和挑战。随着知识表示学习、神经网络等技术的普及,一系列新的推理方法不断问世。
4 基于逻辑规则的知识推理
早期知识推理方法,如本体推理 (Ontology reasoning) 受到了极大关注且衍生了一系列推理方法。此外,这些方法,还包括谓词逻辑推理 (Predicate logic reasoning) 和随机游走推理 (Random walk reasoning),可以应用于知识图谱的推理。
4.1 基于一阶谓词逻辑规则的知识推理
推理主要依赖于统计关系学习研究早期的一阶谓词逻辑规则。一阶谓词逻辑使用命题作为推理的基本单位,而命题包含个体和预测。可以独立存在的个体对应于知识库中的实体对象,它们可以是具体的事物,也可以是抽象的概念。谓词用于描述个体的性质和事件。例如,人际关系可以通过一阶谓词逻辑进行推理,将关系视为谓词,将字符视为变量,并使用逻辑运算符来表达人际关系,然后设置关系推理的逻辑和约束来进行简单的推理。使用一阶谓词逻辑进行推理的过程由以下公式给出:
( YaoMing, wasBornIn, Shanghai ) ∧ ( Shanghai, ocatedIn, China ) ⇒ ( YaoMing, nationality, China ) 一阶归纳学习器 (FOIL) 是谓词逻辑的典型工作,旨在搜索KG中的所有关系,并获取每个关系的Horn子句集作为特征用于预测对应是否存在的模式。最后,使用机器学习方法获得关系判别模型。大量关于FOIL的相关作品,例如nFOIL和tFOIL分别将朴素贝叶斯学习方案和树增强朴素贝叶斯与FOIL相结合。nFOIL通过朴素贝叶斯的概率分数指导结构搜索。tFOIL放宽了朴素贝叶斯假设,以允许子句之间存在额外的概率依赖性。kFOIL结合了FOIL的规则学习算法和内核方法,从关系表示中导出一组特征。因此,FOIL搜索可用作内核方法中的特征的相关子句。Nakashole提出了一种用于不确定RDF知识库的查询时一阶推理方法,该方法结合了软演绎规则和硬规则。软规则用于推导新事实,而硬规则用于在KG和推断事实之间强制执行一致性约束。Galárraga提出了AMIE系统,用于在知识图谱上挖掘Horn规则。通过将这些规则应用于知识库,可以导出新的事实来补充知识图和检测错误。
传统的FOIL算法在小规模知识库上实现了很高的推理精度。此外,实验结果表明,“实体-关系”关联模型具有很强的推理能力。然而,由于大规模知识图中实体和关系的复杂性和多样性,很难穷举所有的推理模式。此外,穷举算法的高复杂性和低效率使得原始的FOIL算法不适合对大规模图进行推理。为了解决这个问题,Galárraga通过一系列修剪和查询重写技术将AMIE扩展到AMIE+,以挖掘更大的KB。此外,AMIE+通过考虑类型信息和使用联合推理来提高预测的精度。Demeester提出了一种可扩展的方法,将一阶含义纳入关系表示以改进大规模KG推理。虽然AMIE+一次挖掘一个规则,但Wang提出了一种名为RDF2Rules的新规则学习方法,其挖掘频繁谓词循环 (FPC) 以并行化此过程。由于适当的剪枝策略,处理大规模KB比AMIE+更有效。
为了有效地形式化语义网和推理,一些研究人员提出了一种易于处理的语言,称为描述逻辑 (DL)。描述逻辑是在命题逻辑和一阶谓词逻辑的基础上发展起来的本体推理的重要基础。描述逻辑的目标是平衡表示能力和推理复杂性,它可以为知识图谱提供定义明确的语义和强大的推理工具,满足本体构建、集成和演化的需要。因此,它是一种理想的本体语言。使用DL表示的KB由术语公理 (TBox) 和断言公理 (ABox) 组成。TBox由一组包含断言组成,这些断言陈述了概念和角色的一般属性。例如,断言是声明一个概念表示另一个概念的专业化的断言。 ABox由对单个对象的断言组成。知识库的一致性是知识图推理中的基本问题。知识图谱中复杂的实体或关系推理可以通过TBox和ABox转化为一致性检测问题,从而提炼和实现知识推理。Halschek-Wiener提出了一种描述逻辑推理算法,用于在添加和删除ABoxes断言的情况下补充知识图。它提供了对波动/流数据进行推理的关键步骤。 Calvanese提出了基于认知一阶查询语言的语言EQL,该语言能够推断查询描述逻辑知识图的不完整性。提出了大量的模糊描述逻辑来扩展具有模糊能力的经典描述逻辑。Li提出了一种新颖的离散表格算法,用于使用通用TBoxes对FSHI知识库的可满足性,它支持在模糊DL中使用通用TBoxes实现推理的新方法。此外,Stoilos用模糊集理论扩展了深度学习,以表示知识并执行推理任务。为了配备用于处理元知识的描述逻辑,Krötzsch用有限的属性值对集 (称为属性描述逻辑) 丰富了DL概念和角色,用于知识图推理。现有的深度学习推理器不提供用户解释服务。为了解决这个问题,Bienvenu开发了一个框架,为推理系统配备了在不一致性语义下的解释能力。
4.2 基于规则的知识推理
4.3 基于总体的知识推理
4.4 基于随机游走的知识推理
以上以下省略。
-
相关阅读:
【前端】HTTP相关知识总结
一级建造师有哪些答题技巧
动态规划题: 统计每个月兔子的总数
Java面试题大全(2021版)
Flink 实践 | B站流式传输架构的前世今生
YOLOv5基础知识入门(5)— 损失函数(IoU、GIoU、DIoU、CIoU和EIoU)
08.爱芳地产项目小程序全栈项目经验(已上线)
PAT 1048 Find Coins
【网关路由测试】——报文路由模式与信号路由模式
Spring Boot Actuator介绍
- 原文地址:https://blog.csdn.net/weixin_44575152/article/details/127068557