-
HDFS总结
概述
HDFS 分布式文件系统。适合一次写入,多次读出(文件创建写入关闭后不修改)
优点:高容错(分布式)+大规模数据(文件数量、数据PB级别)+成本低(多副本在廉价机器上)
缺点:存储数据延迟+只适合大文件存储+单线程写文件+只追加文件不随机修改
HDFS组成
NameNode(Master) 管理 HDFS名称空间+配置副本+数据块映射+处理客户端读写请求
DataNode(Slave, NameNode下达命令,DataNode执行命令)存储实际数据+执行数据读写
Client(客户端)
Secondary NameNode: 辅助NameNode分担工作量如定期合并Fsimage和Edit并推送给NameNode;+紧急情况辅助恢复NameNodeHDFS文件块大小(面试)
HDFS文件是分块存储,块的大小可以配置参数(dfs.blocksize)。hadoop1.X块大小64M,hadoop2.X、hadoop3.X 是128M。
如果寻址时间是10ms,理论上寻址时间是传输时间的1%最为理想。所以理想的传输时间是1s,而磁盘的传输速率普遍是100M/s,所以块大小100M(磁盘传输更快的话可以设置更大)。
HDFS 块设置太小,会增加寻址时间(程序的寻址时间比重增大)
HDFS块设置大:从磁盘传输数据时间会明显大于寻址定位时间,导致程序在处理这个数据块非常慢。
总结:HDFS的块大小取决于磁盘的传输速率HDFS的Shell操作(开发重点)
- 基本语法
hadoop fs 具体命令
hdfs dfs 具体命令
准备工作 启动集群上传
-mkdir 创建文件夹
hadoop fs -mkdir /mytest/

在hadoop102:9870查看
-moveFromLocal:从本地剪切粘贴到HDFS
注意:本地的文件shuguo.txt没了

./代表当前目录
/代表根目录

-copyFromLocal:从本地文件系统中拷贝文件到HDFS路径去

-put:等同于copyFromLocal
hadoop fs -put ./wuguo.txt /sanguo-appendToFile:追加一个文件到已经存在的文件末尾

查看shuoguo.txt,后面已经追加了liubei

下载
-copyToLocal:从HDFS拷贝到本地(可重命名)

重命名为shuhuo2.txt(本地已经有shuguo.txt)

-get:等同于copyToLocal
重命名shuguo3.txt

HDFS直接操作
这里是显示HDFS集群中的信息(hadoop102:9870可以看信息)
-ls: 显示目录信息

cat:显示文件内容

-chgrp、-chmod、-chown
Linux文件系统中的用法一样,修改文件所属权限
hadoop fs -chmod 666


hadoop fs -chown tm:yy /sanguo/shuguo.txt

-mkdir:创建路径
hadoop fs -mkdir /jinguo在根目录(/)创建jingguo文件夹-cp:从HDFS的一个路径拷贝到HDFS的另一个路径
hadoop fs -cp /sanguo/shuguo.txt /jinguosanguo下的shuguo.txt 复制到/jinguo-mv:在HDFS目录中移动文件
hadoop fs -mv /sanguo/wuguo.txt /jinguo
sanguo/wuguo.txt的文件 移动到jinguo文件夹下
hadoop fs -mv /sanguo/weiguo.txt /jinguo
sanguo/weiguo.txt的文件 移动到jinguo文件夹下-tail:显示一个文件的末尾1kb的数据
hadoop fs -tail /jinguo/shuguo.txt-rm:删除文件或文件夹
hadoop fs -rm /sanguo/shuguo.txt-rm -r:递归删除目录及目录里面内容
hadoop fs -rm -r /sanguo-du统计文件夹的大小信息
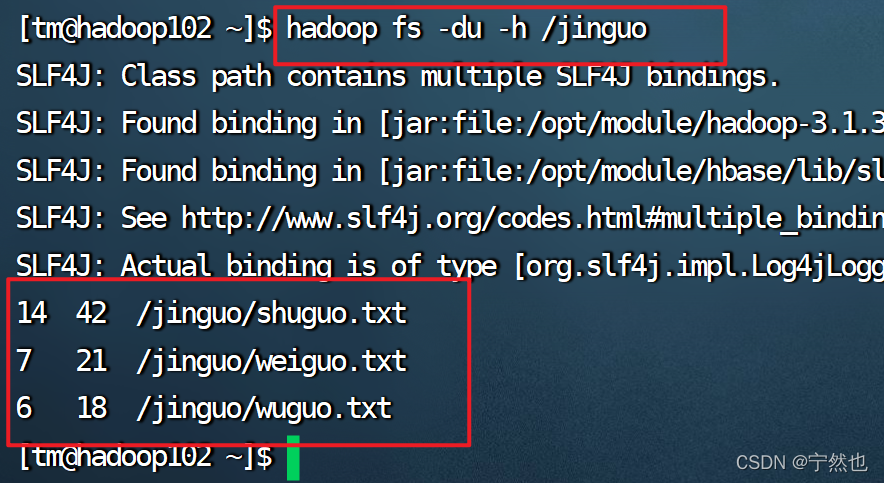
hadoop fs -du -s -h /jinguo

说明:27表示文件大小;81表示27*3个副本;/jinguo表示查看的目录
-setrep:设置HDFS中文件的副本数量


这里设置的副本数只是记录在NameNode的元数据中,是否真的会有这么多副本,还得看DataNode的数量。因为目前只有3台设备,最多也就3个副本,只有节点数的增加到10台时,副本数才能达到10。 - 基本语法
-
相关阅读:
【LeetCode】【剑指offer】【圆圈中最后剩下的数字】
循环神经网络不常应用于,循环神经网络应用举例
关于 /lib/modules/**内核版本号**/ build 和 /source
生命 周期
Arcgis提取每个像元的多波段反射率值
stm32----SPI协议
[4G/5G/6G专题基础-159]: CQI值的滤波方法
业务逻辑漏洞
传统算法与神经网络算法,进化算法优化神经网络
笔试题/面试题——数组去重--9种方法
- 原文地址:https://blog.csdn.net/weixin_42382758/article/details/124209239