-
机器人开发新思路——强化学习
众所周知,机器人(Robot)是一种能够半自主或全自主工作的智能机器。机器人能够通过编程和自动控制来执行诸如作业或移动等任务,而在执行过程中,最常用的就是判断命令或逻辑。换句话来说,机器人之所以能够执行并输出我们所期望的结果,跟判断命令是离不开的。
今天我们就从判断逻辑的开发来模拟未来的机器人开发场景。首先来试想一个场景:老鼠走迷宫。

图中绿色线条为迷宫的正确路线,起点至终点,需要通过26个路口。由此我们可以模拟出两种开发路径:
-
按照最简单的开发方式来设计程序,在知道答案的前提下,进行26次正确判断,使老鼠走出迷宫。这种方式虽然开发过程比较繁琐,但好在小老鼠最省力。如果是更高难度等级的迷宫开发,这种方式就不太适用了。
-
按照条件来设计程序,即每个路口都由小老鼠去自主尝试,直到找出正确的路线。这种方式虽然开发简单,但是费时费力。如果换一个更高难度等级的迷宫,小老鼠可能跑得没电了也没找到正确的路。
试想一下,有没有什么办法既能省去中间的复杂环节,又能减少程序员的开发精力,同时让小老鼠看起来更聪明呢?
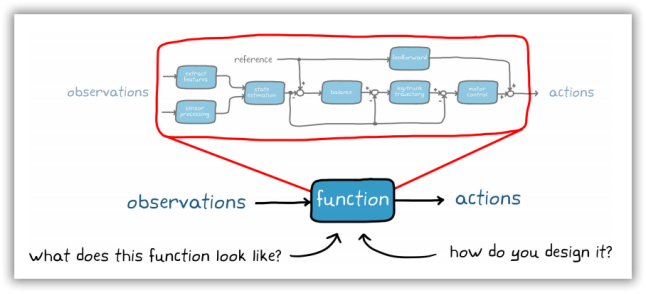
利用强化学习的思路来解决
通过人为设置奖励函数,让小老鼠在仿真环境中自行运算、试错、碰壁,将一定量级的案例经验进行积累,小老鼠将自行生成出符合走出迷宫的最佳算法或经验集合。
当小老鼠在实际环境中每遇到一个路口需要判断时,它都会在经验集合中查找最适合的路径或算法,帮助它做出最合适的判断,从而达到比人类设计程序更适合的程序效果。
在这一开发过程中,案例积累的大部分工作是由机器自行学习完成的,机器学习的时间相对人类而言,耗时更短效率更高,且能够应对不同等级的迷宫场景,适用性更强。
由此我们可以看出:仅仅是在走迷宫这一机器人开发的小小场景中,强化学习就能发挥如此大的作用。若是在一个多自由度,多控制域,多场景等条件下的机器人开发,强化学习思路的机器人程序开发方式,是否有机会成为未来的主流方式?

近期,阿木实验室也利用强化学习的思路测试了我们的KKSwarm无人小车,接下来给大家展示我们的实验成果:
无人车通过强化学习有序跟车运输货物
如今,KKSwarm集群测试平台已经实现了强化学习理论到开发落地的衔接,并提供强化学习demo仿真环境与实际物理环境的映射,同时KKSwarm项目仍在不断的强化中,期待各位未来人工智能领域的领头羊与我们一道探索机器人的未来。
-END-
特别福利:为鼓励广大开发者开源,凡是基于KKSwarm系统研究出新算法,同时达到以下标准者,将给予相应现金奖励(按最高贡献只奖励一次),以达到共建开源项目的目的。
A类贡献者(奖励2万元),需同时满足以下要求:
1. 开源算法发表在SCI期刊;
2. 提供相应算法代码或下载链接;
3. 提供相应演示视频。
B类贡献者(奖励8千到1万元),需同时满足以下要求:
1. 成果发表在EI期刊;
2. 提供相应算法代码或下载链接;
3. 提供相应演示视频。
C类贡献者(奖励2千到5千元),需审核:
成果以论文、博客、教程等形式发表;或提供与众不同的演示视频。
可搭配学习的资料
1、开源项目地址:
https://github.com/amov-lab/kk-robot-swarm
https://github.com/kkswarm/kk-robot-swarm
2、Wiki资料:https://wiki.amovlab.com/public/misaro-doc/
-
-
相关阅读:
【刷题】搜索——DFS:DFS求排列和组合
【blood group + transferase】
自定义http状态码
05c++呵呵老师【FPS游戏准备】
Spring系列25:Spring AOP 切点详解
智慧工地管理系统源码(电脑端+手机端+APP+SAAS云平台)
TypeError: res.data.map is not a function微信小程序报错
JVM下篇(三、JVM监控及诊断工具-GUI篇)
岛屿数量 -- 二维矩阵的dfs算法
高性能版本的零内存分配LikeString函数(ZeroMemAllocLikeOperator)
- 原文地址:https://blog.csdn.net/msq19895070/article/details/127088676