-
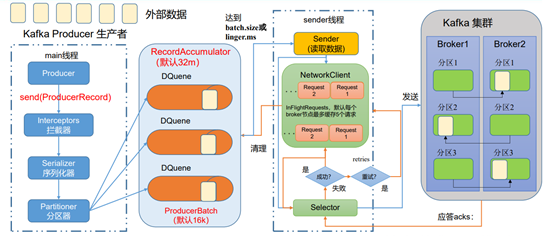
【Kafka】——Producer
Kfaka Producer
1. 原理
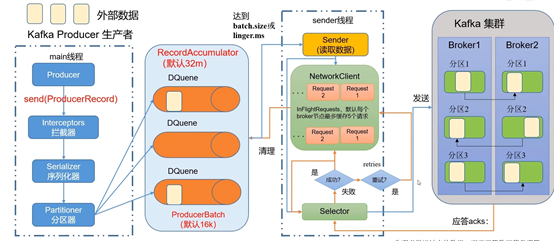
<1> 创建mian线程
<2> 调用send() 方法
<3> 经过拦截器interceptors ,生产中用的较少
<4> 经过序列化器 serializer ,数据量较少
<5> 经过分区器 partitioner ,判断发送到哪一个区分,
<6>数据发送到缓冲区(双端队列record accumulator),一个分区创建一个队列,都是在内存中完成,内存总大小为32M,数据 发送每一个批次大小默认为16k
batch.size: 只有数据积累到了batch.size 之后,sender 才会发送数据,默认为16k
linger.ms:如果数据迟迟未到到batch.size ,sender等待linger.ms设置的时间到了之后会发送数据,单位ms。默认是0ms。表示没有延迟。
<7> sender线程,sender从缓冲区(record accumulator)中读取,发送到kafka集群。默认每个broker节点最多缓存5个请求。
<8> selector 创建消息发送链路
<9> 收到消息进行副本同步,然后会进行应答。应答级别如下
0:生产者发送过来消息后,不需要等待数据落盘应答。
1:生产者发送过来消息后,Leader收到数据后就进行应答。
-1(all):生产者发送过来消息后,Leader和ISR队列里面的所有节点收起数据后应答,-1和all等价
<10> 应答成功后,清理请求,清理缓冲区,应答不成功 sender进行重试,重试的次数为int的最大值。2. 生产者重要参数列表

3. 异步发送
<1>普通异步发送
1. 新建项目
2. 导入依赖
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0modelVersion> <groupId>com.kafkagroupId> <artifactId>KafkaDemoartifactId> <version>1.0-SNAPSHOTversion> <properties> <maven.compiler.source>8maven.compiler.source> <maven.compiler.target>8maven.compiler.target> properties> <dependencies> <dependency> <groupId>org.apache.kafkagroupId> <artifactId>kafka-clientsartifactId> <version>3.0.0version> dependency> dependencies> project>3. 创建不带回调函数客户端类
package com.kafkademo.case1.producer; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerConfig; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.common.serialization.StringSerializer; import java.util.Properties; /** * @author : hechaogao * @createTime : 2022/9/19 17:09 */ public class CustomProducer { private static final String HOST = "hadoop102:9092,hadoop103:9092,hadoop104:9092"; private static final String TOPIC = "test_topic"; public static void main(String[] args) { //1. 配置 Properties properties = new Properties(); //1.1 连接集群 properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, HOST); //1.2 指定对应的的key和value的序列化类型 properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); //2. 创建kafka生产者对象 KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties); //3. 发送数据 for (int i = 0; i < 10; i++) { kafkaProducer.send(new ProducerRecord<>(TOPIC, "test message no : " + i)); } //4. 关闭资源 kafkaProducer.close(); } }4. 执行结果

<2> 带回调函数的异步发送
1. 创建带回调函数客户端类
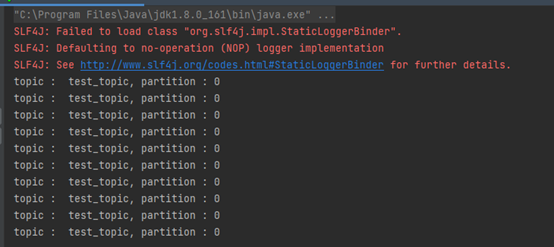
package com.kafkademo.case1.producer; import org.apache.kafka.clients.producer.*; import org.apache.kafka.common.serialization.StringSerializer; import java.util.Properties; /** * @author : hechaogao * @createTime : 2022/9/19 21:22 * * 带回调函数的异步发送消息案例 */ public class CustomProducerCallBack { private static final String HOST = "hadoop102:9092,hadoop103:9092,hadoop104:9092"; private static final String TOPIC = "test_topic"; public static void main(String[] args) { //1. 配置 Properties properties = new Properties(); //1.1 连接集群 properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, HOST); //1.2 指定对应的的key和value的序列化类型 properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); //2. 创建kafka生产者对象 KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties); //3. 发送数据 for (int i = 0; i < 10; i++) { kafkaProducer.send(new ProducerRecord<>(TOPIC, "test message no : " + i), new Callback() { @Override public void onCompletion(RecordMetadata recordMetadata, Exception e) { if(e == null){ System.out.println("topic : "+recordMetadata.topic()+", partition : "+recordMetadata.partition()); } } }); } //4. 关闭资源 kafkaProducer.close(); } }2. 执行结果

4. 同步发送
当缓冲区(Record Accumulator)中的数据全部发送到Kafka集群之后,外部数据再写入缓冲区(Record Accumulator)。<1> 创建同步发送客户端类
package com.kafkademo.case1.producer; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerConfig; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.clients.producer.RecordMetadata; import org.apache.kafka.common.serialization.StringSerializer; import java.util.Properties; import java.util.concurrent.ExecutionException; /** * @author : hechaogao * @createTime : 2022/9/19 17:09 * * 同步发送消息案例 */ public class CustomProducerSync { private static final String HOST = "hadoop102:9092,hadoop103:9092,hadoop104:9092"; private static final String TOPIC = "test_topic"; public static void main(String[] args) throws ExecutionException, InterruptedException { //1. 配置 Properties properties = new Properties(); //1.1 连接集群 properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, HOST); //1.2 指定对应的的key和value的序列化类型 properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); //2. 创建kafka生产者对象 KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties); //3. 发送数据 for (int i = 0; i < 10; i++) { kafkaProducer.send(new ProducerRecord<>(TOPIC, "test message no : " + i)).get(); } //4. 关闭资源 kafkaProducer.close(); } }<2> 执行结果

5. 生产者分区
<1> 优点
- 便于合理使用存储资源,每个Partition在一个Broker上存储,可以把海量的数据按照分区切割成一块一块存储在多台Broker中,合理控制分区的任务,可以实现负载均衡的效果。
- 提高并行度,生产者可以以分区为单位发送数据,消费者可以以分区为单位消费数据。
<2> 分区策略
默认的分区器 DefaultPartitioner
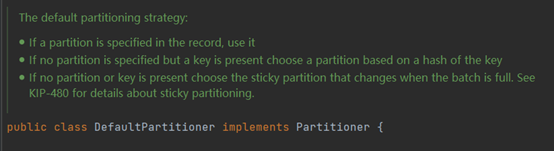
- 指明partition的情况下,直接将指明的值作为partitiion值
- 如果未指定分区但存在key,则将key的hash值与topic的partition数进行取模得到partition的值,
- 如果没有分区或不存在key,则Kafka采用Sticky Partition(黏性分区器),会随机选择一个分区,并尽可能一直使用该分区,待该分区的batch已满或者已完成,Kafka再随机一个分区进行使用(和上一次的分区不同)。
例如:第一次随机选择0号分区,等0号分区当前批次满了(默认16k)或者linger.ms设置的时间到,Kafka再随机一个分区进行使用(如果还是0会继续随机)。
<3> 自定义分区
1. 定义类实现Partitioner接口
2. 重写partition()方法
package com.kafkademo.case2; import org.apache.kafka.clients.producer.Partitioner; import org.apache.kafka.common.Cluster; import java.util.Map; /** * @author : hechaogao * @createTime : 2022/9/20 10:21 */ public class MyPartition implements Partitioner { @Override public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) { int partition; // 获取数据 String msgValues = value.toString(); if(msgValues.contains("test")){ partition = 0; }else{ partition = 1; } return partition; } @Override public void close() { } @Override public void configure(Map<String, ?> configs) { } }3. 关联自定义分区器客户端
package com.kafkademo.case2; import org.apache.kafka.clients.producer.*; import org.apache.kafka.common.serialization.StringSerializer; import java.util.Properties; /** * @author : hechaogao * @createTime : 2022/9/19 21:22 * * 带回调函数的异步发送消息案例 */ public class CustomProducerMyPartition { private static final String HOST = "hadoop102:9092,hadoop103:9092,hadoop104:9092"; private static final String TOPIC = "test_topic" public static void main(String[] args) { //1. 配置 Properties properties = new Properties(); //1.1 连接集群 properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, HOST); //1.2 指定对应的的key和value的序列化类型 properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); //1.3 关联自定义分区器 properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,"com.kafkademo.case2.MyPartition"); //2. 创建kafka生产者对象 KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties); //3. 发送数据 for (int i = 0; i < 10; i++) { kafkaProducer.send(new ProducerRecord<>(TOPIC, " message no : " + i), new Callback() { @Override public void onCompletion(RecordMetadata recordMetadata, Exception e) { if(e == null){ System.out.println("topic : "+recordMetadata.topic()+", partition : "+recordMetadata.partition()); } } }); } //4. 关闭资源 kafkaProducer.close(); } }6. 生产者提高吞吐量
<1> 方案

<2> 实现
package com.kafkademo.case3; import org.apache.kafka.clients.producer.*; import org.apache.kafka.common.serialization.StringSerializer; import java.util.Properties; /** * @author : hechaogao * @createTime : 2022/9/20 10:52 * * 修改参数提高生产者吞吐量案例 */ public class CustomProducerParamenters { private static final String HOST = "hadoop102:9092,hadoop103:9092,hadoop104:9092"; private static final String TOPIC = "test_topic"; public static void main(String[] args) { //1. 配置 Properties properties = new Properties(); //1.1 连接集群 properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, HOST); //1.2 指定对应的的key和value的序列化类型 properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); // 缓冲区大小 修改为 32M , 采用默认值 properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432); // 批次大小 默认为16k , 采用默认值 properties.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384); // linger.ms 默认为0ms 改为 1ms properties.put(ProducerConfig.LINGER_MS_CONFIG, 1); //压缩 压缩方式 采用snappy properties.put(ProducerConfig.COMPRESSION_TYPE_CONFIG, "snappy"); //2. 创建kafka生产者对象 KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties); //3. 发送数据 for (int i = 0; i < 10; i++) { kafkaProducer.send(new ProducerRecord<>(TOPIC, "test message no : " + i), new Callback() { @Override public void onCompletion(RecordMetadata recordMetadata, Exception e) { if(e == null){ System.out.println("topic : "+recordMetadata.topic()+", partition : "+recordMetadata.partition()); } } }); } //4. 关闭资源 kafkaProducer.close(); } }7. 数据可靠性
<1>ACK应答级别
1. acks = 0
生产者发送过来消息后,不需要等待数据落盘应答。
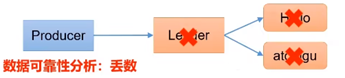
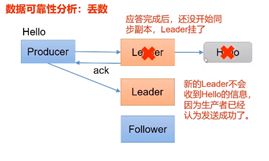
2. acks =1
生产者发送过来消息后,Leader收到数据后就进行应答。
3. acks = -1(all)
生产者发送过来消息后,Leader和ISR队列里面的所有节点收起数据后应答,-1和all等价
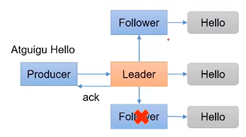
<2> acks = -1(all)存在的问题
1. Follower 故障
Leader 收到数据,所有Follower都开始同步数据,但是有个一Follower因为某种故障,迟迟不能和Leader进行同步数据,则消息不能进行应答,那么这个问题咋那么解决?
ISR :Leader 维护了一个动态的in-sync-replica set (ISR) ,意为和Leader 保持同步的Follower 和Leader集合(leader:0 ,isr:0,1,2)
如果Follower长时间没有向Leader发送通信请求或同步数据,则该Follower将被踢出ISR。该事件阈值由replica.lag.time.max.ms 参数设定,默认为30s。例如 2超时。I
SR为0,1
这样就不用等长期联系不上或者已经出故障的节点。
如果分区副本设置为l个,或者ISR里应答的最小副本数量( min.insync.replicas 默认为1)设置为1,和ack=1的效果是一样的,仍然有丢数的风险(leader: 0, isr:0)。2. Leader故障
当Leader 接收到数据,并进行Follower 数据同步之后,在消息应答之前 Leader发生故障,此时此时未进行消息应答,集群会重新选举产证Leader,上一条消息会重复发送给Ledaer ,然后重复发送到Follower ,这样就行接收到两份数据,导致消息重复。
<3> 完全可靠的条件
ACK级别设置为 -1 + 分区副本大于等于2 + ISR里应答的最小副本数大于等于2
<4>总结
- acks=0,生产者发送过来数据就不管了,可靠性差,效率高;
- acks=1,生产者发送过来数据Leader应答,可靠性中等,效率中等;
- acks=-1,生产者发送过来数据Leader和ISR队列里面所有Follwer应答,可靠性高,效率低。
- 在生产环境中,acks=0很少使用;acks=1,一般用于传输普通日志,允许丢个别数据; acks=-1,一般用于传输和钱相关的数据,对可靠性要求比较高的场景。
8. 数据重复
<1> 数据传递语义
- 至少一次(At Least Once)
至少一次 = ACK级别设置为 -1 + 分区副本大于等于2 + ISR里应答的最小副本数大于等于2
可以保证数据不丢失,但是不能保证数据不重复 - 最多一次(At Nost Once)
最多一次 = ACK级别设置为 0
可以保证数据不重复,但是不能保证数据不丢失 - 精确一次(Exactly Once)
精确一次 = 幂等性+至少一次(ACK级别设置为 -1 + 分区副本大于等于2 + ISR里应答的最小副本数大于等于2)
对应一些非常重要的信息,比如和钱相关的数据,要求数据既不能重复也不能丢失
Kafka 0.11版本以后,引入了一项重大特性:幂等性和事务
<2> 幂等性
- 概念
幂等性就是指Producer不论向Broker发送多少次重复数据,Broker端都只会持久化一条,保证了不重复。
只能保证的是在单分区,单会话内不重复。(启动一次 一次会话) - 重复数据判断标准
具有 - 幂等性使用
开启参数:enable.idempotence 。默认是true ,false 关闭
<3> 生产者事务
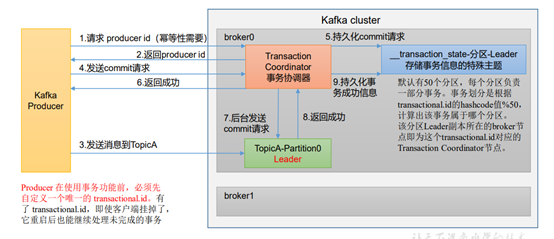
- 开启事务,前提必须开启幂等性
- 案例
package com.kafkademo.case4; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerConfig; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.common.serialization.StringSerializer; import java.util.Properties; /** * @author : hechaogao * @createTime : 2022/9/19 17:09 ** Kafka 生产者事务案例 */
public class CustomProducerTransactions { private static final String HOST = "hadoop102:9092,hadoop103:9092,hadoop104:9092"; private static final String TOPIC = "test_topic"; public static void main(String[] args) { //1. 配置 Properties properties = new Properties(); //1.1 连接集群 properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, HOST); //1.2 指定对应的的key和value的序列化类型 properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); // 指定 唯一的 Transaction id properties.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "transaction_id_01"); //2. 创建kafka生产者对象 KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties); //3.1 初始化事务 kafkaProducer.initTransactions(); //3.2 开启事务 kafkaProducer.beginTransaction(); //4. 发送数据 try { for (int i = 0; i < 10; i++) { kafkaProducer.send(new ProducerRecord<>(TOPIC, "test message no : " + i)); } //int i = 1 / 0; //3.3 提交事务 kafkaProducer.commitTransaction(); } catch (Exception e) { //3.4 放弃事务 kafkaProducer.abortTransaction(); } finally { //5. 关闭资源 kafkaProducer.close(); } } }9. 数据单分区有序
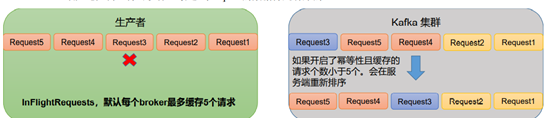
<1> kafka1.x版本之前
max.in.flight.requests.per.connection需要设置为1(不需要考虑是否开启幂等性)。
<2> kafka1.x版本之后
(1)未开启幂等性 max.in.flight.requests.per.connection需要设置为1。
(2)开启幂等性 max.in.flight.requests.per.connection需要设置小于等于5。
原因说明:因为在kafka1.x以后,启用幂等后,kafka服务端会缓存producer发来的最近5个request的元数据, 故无论如何,都可以保证最近5个request的数据都是有序的
-
相关阅读:
常用工具类之使用hutool生成验证码
PyQt5应用开发-PyQt5对比其他python生态的界面开发工具
JPA自动建表字段名称采用驼峰形式
Git配置代理:fatal: unable to access*** github Failure when receiving data from
跟我读CVPR 2022论文:基于场景文字知识挖掘的细粒度图像识别算法
DP专题4 不同路径|
Python时间序列分析库介绍:statsmodels、tslearn、tssearch、tsfresh
5302: 【C3】【分治】【二分查找】刚好比我小
curl语法整理
Java基础11——抽象类和接口
- 原文地址:https://blog.csdn.net/qq_42000631/article/details/127088743