-
数据分析与挖掘———SPSS Moderler
数据分析与挖掘———SPSS Moderler
一、Modeler给概述
1、SPSS Modeler基本认识
IBM SPSS Modeler是一组
数据挖掘工具,通过这些工具可以采用商业技术快速建立预测性模型,并将其应用于商业活动,从而改进决策过程。
SPSS Modeler提供了各种借助机器学习、人工智能和统计学的建模方法。通过建模选项板中的方法,可以根据数据生成新的信息以及开发预测模型。2、SPSS Modeler的特点
- 强大的数据读取功能
- 丰富的数据处理方法
- 图形化的数据探索方式
- 核心挖掘算法
- 简洁直观的模型评估
- 性能卓越的三层体系架构
二、数据读取与数据清洗
1、变量类型
数据挖掘角度
- 数值类型变量:连续性的数字(电话)
- 定类型变量:分类型 (性别)
- 定序型变量:等级次序的变量(职称)
数据储存角度
- 整数型
- 实数型
- 字符串型
- 时间型:时间段
- 日期型
- 时间戳型:时间点
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EhJ5hSy4-1664253911313)(:/b3469e892ded4d96b152720b81b71272)]](https://1000bd.com/contentImg/2024/09/12/d22a0d4b959331af.png)
2、数据读取
txt文件
在
源中把变量文件拖拽出来,右键–编辑–引入文件–修改编码
查看结果 ,在输出中拉出表格
连接(F2) ,运行 (Ctrl+E)

![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PjNJVOpB-1664253911314)(:/78b04ad4f61b4207966a9f7fd9966c01)]](https://1000bd.com/contentImg/2024/09/12/a60aa99811898e76.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jDaNw57e-1664253911314)(:/b792d6bd3ee54f3bbe469a3ab3881a85)]](https://1000bd.com/contentImg/2024/09/12/71bc7c8a8cd988fe.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lTwXx1dY-1664253911315)(:/a3d48b80df814ab59ba65cd5c2e94240)]](https://1000bd.com/contentImg/2024/09/12/e1b341d28d72b6e5.png)
excel文件
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rTqQvFFQ-1664253911316)(:/cb44f0590f3546e0904e2a4cc149c517)]](https://1000bd.com/contentImg/2024/09/12/961c014c664b5290.png)
spss文件
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BciceZaV-1664253911316)(:/e495aec4fd2947098f774bbe4690c147)]](https://1000bd.com/contentImg/2024/09/12/dd71020d9f45eba6.png)
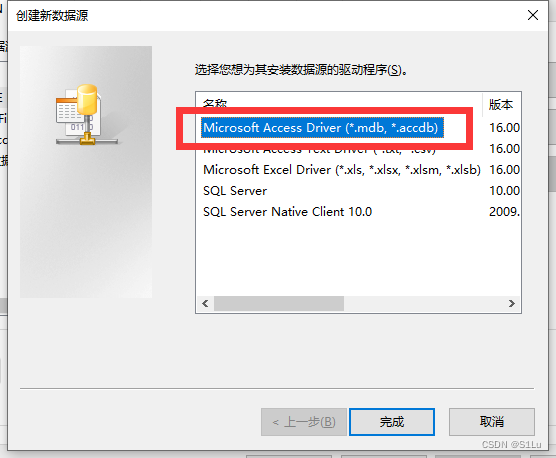
数据库文件
先建立数据源
管理面板–管理工具–ODBC数据源]
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Nds2wsjb-1664253911316)(:/7060ead992ae4be39876bab5a21487c1)]](https://1000bd.com/contentImg/2024/09/12/0d75dc5e04531b99.png)

![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kASWBPTb-1664253911317)(:/10da020a1ada49cfa7bd0143acce3b9f)]](https://1000bd.com/contentImg/2024/09/12/3429097b7806a919.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zYm6YtHX-1664253911317)(:/a8b13e26931a4199b3cb7e7c73621787)]](https://1000bd.com/contentImg/2024/09/12/9d4580806683b54c.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-U8SGHoeL-1664253911318)(:/a2cc6bbbd89844c5a97e90309298a544)]](https://1000bd.com/contentImg/2024/09/12/89cb04d13902835d.png)
在spss modeler操作
选择
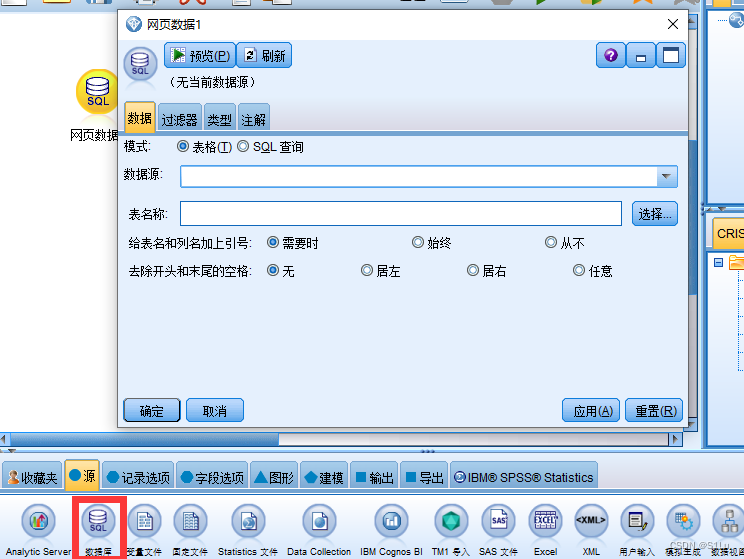


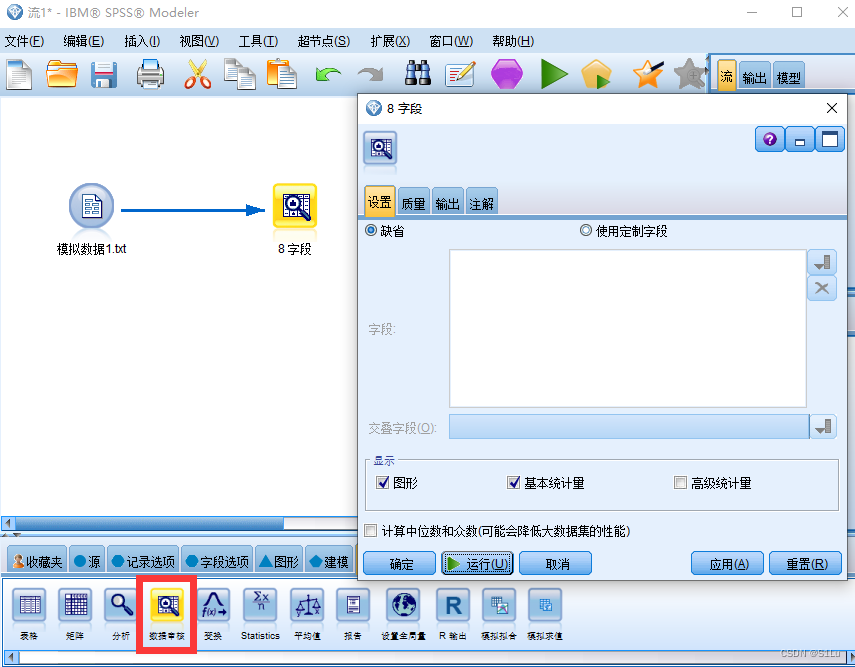
3、数据清洗
缺失值分析及处理
step1:观察缺失值

step2:缺失值定义和缺失值处理(删除or插补)
通过对比发现是因为对于无效数据没有定义,所以导致系统没有排除出无效数据
缺失值的定义
1、先对数据通过 类型 进行实例化
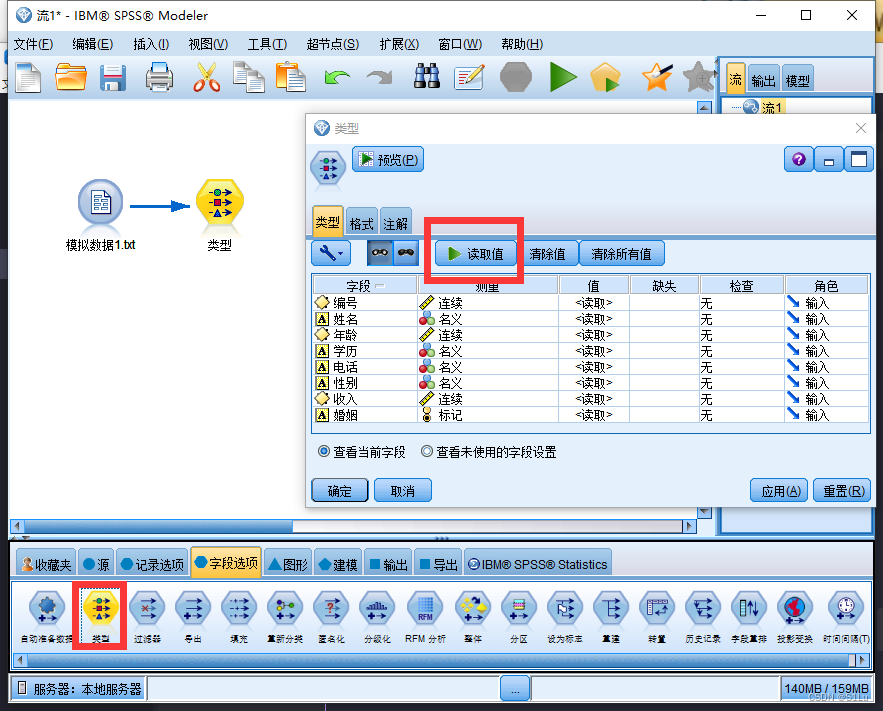

2、对缺失值进行定义



3、利用 数据审核 进行输出观察



缺失值的处理
经过缺失值/异常值的处理使
完整字段和完整记录达到100%,那么处理完的数据才是完美的
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GyFRKZqt-1664253911321)(:/78186a7939194f5c97645a7151a687ff)]方法一、 缺失值删除
将数据中的
缺失值直接删除
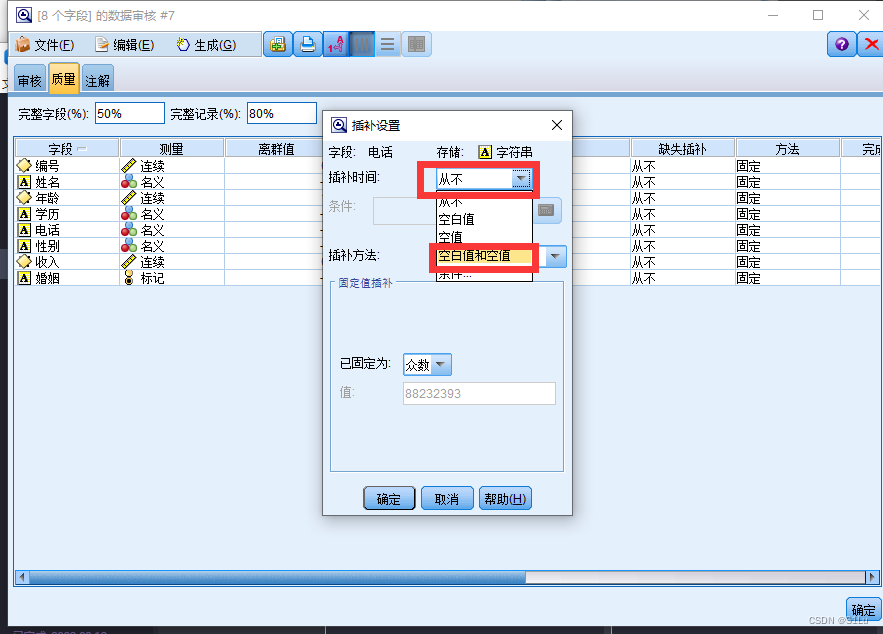
从数据审核节点–>选择生成–缺失值过滤节点方法二、缺失值插补

将数据中的
缺失值进行其他数据的添补
运行数据审核节点–>对缺失插补进行操作–>编辑后确定–>生成缺失值超节点







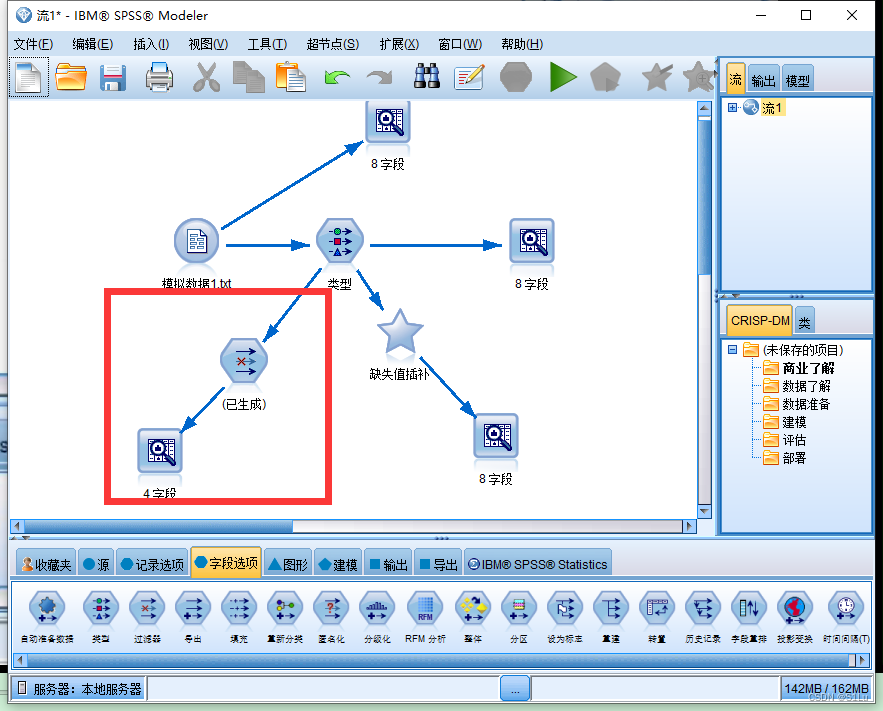

最终得到:

异常值分析及处理
异常值的定义
异常值是在数据集中与其他观察值有很大差距的数据点,它的存在,会对随后的计算结果产生不适当的影响,因此检测异常值并加以适当的处理是十分必要的。
异常值的类型
- 单字段异常值
某条或者多条字段的单个变量出现异常 - 多字段异常值
某条或者多条字段的多个变量出现异常
异常值处理
异常值处理的原理
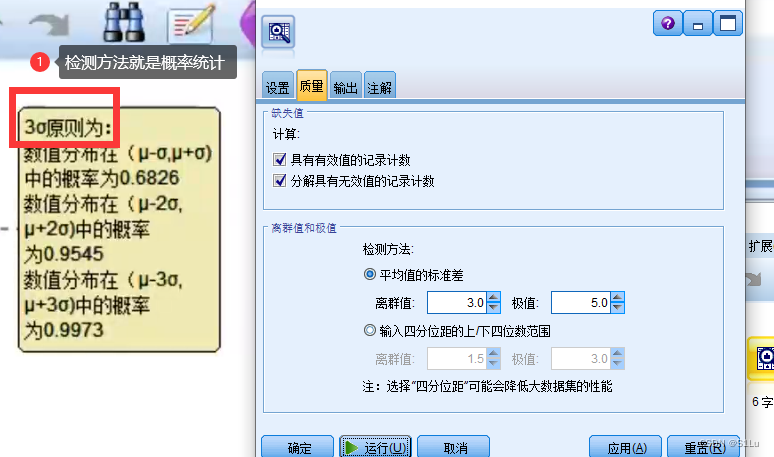
处理步骤:
数据审核节点–>质量操作–>生成



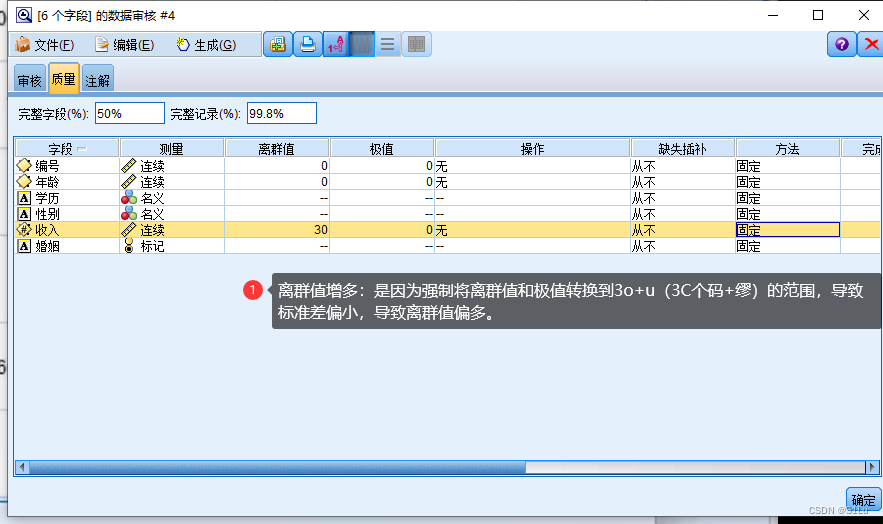
重复值处理


(这个最后的输出应该是表格而不是审核节点 )


三、数据的基本分析
1、数据质量分析
就是进行
数据清洗,将数据质量达到100%2、描述性统计分析
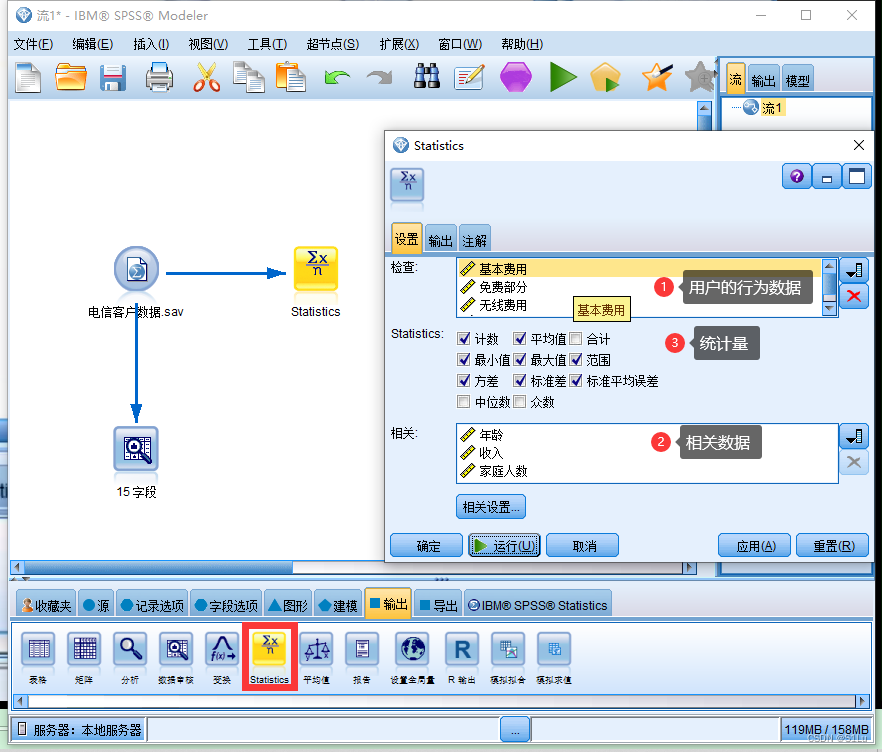

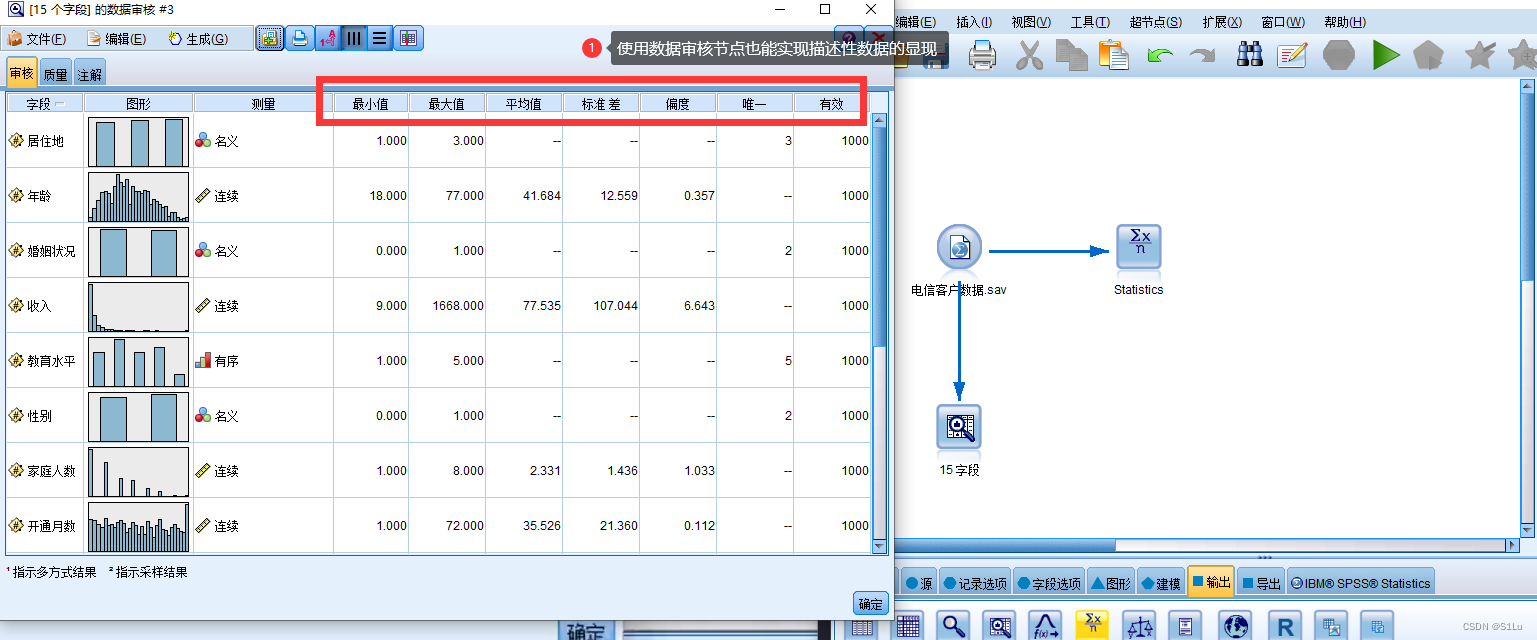
3、探索性分析
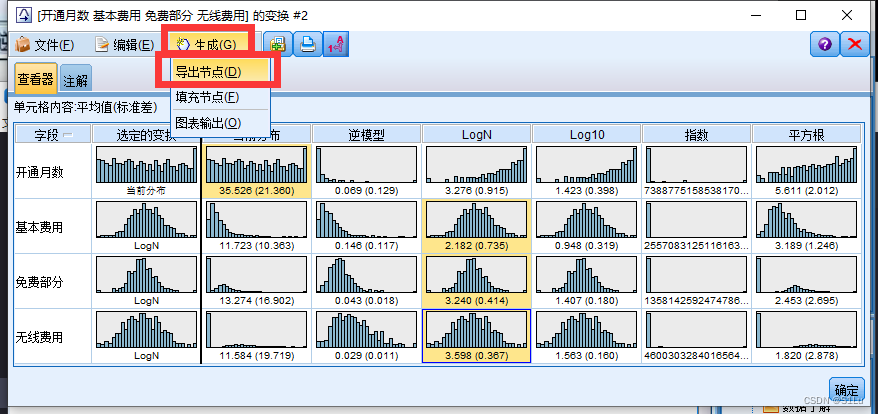
统计建模常常要求变量服从
正态分布如果变量不服从正态分布,应对变量进行适当的转换处理。
SPSS Modeler提供了直观的图形方式用于变量的转换,大大缩短了变量分布探索的时间。步骤:
输出的变换节点读入数据选择字段运行生成函数图像–>选择符合正态分布的函数图像–>生成超节点变换–>表格输出







4、二分类变量相关性分析
时间:01:37:26
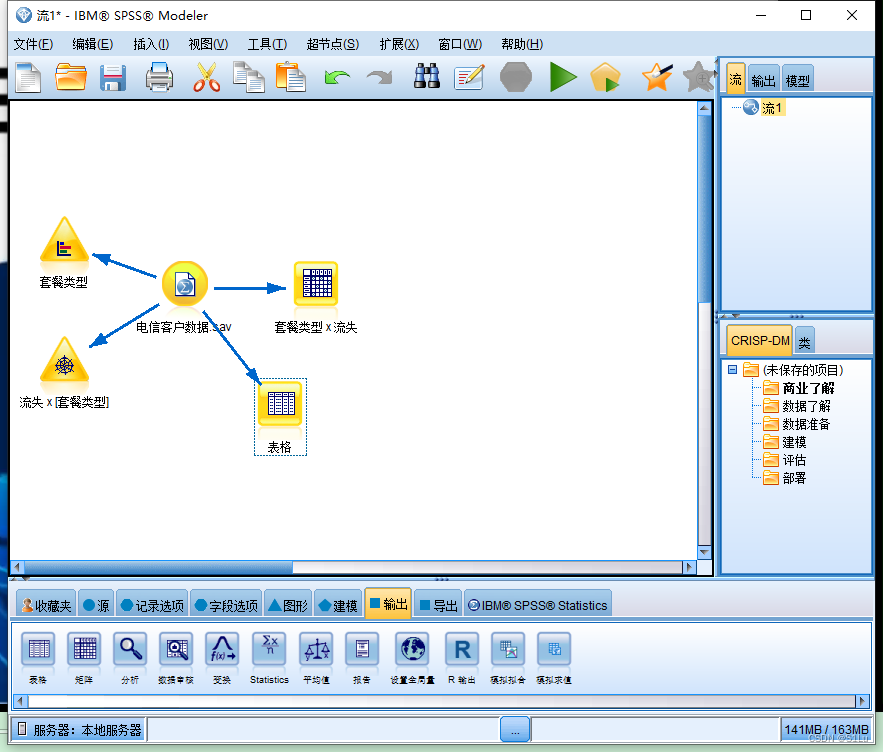
➢二分类型相关性研究可以
从图形分析入手,也可以采用数值方法进行分析。问 :
➢例如,基于电信客户数据,可分析客户流失与套餐类型、婚姻状况、电子支付等是否相关。➢这里,基于电信客户数据,
分析套餐类型的分布特征,以及流失客户在不同套餐类型上的分布。图形分析
分类图:



网络图:

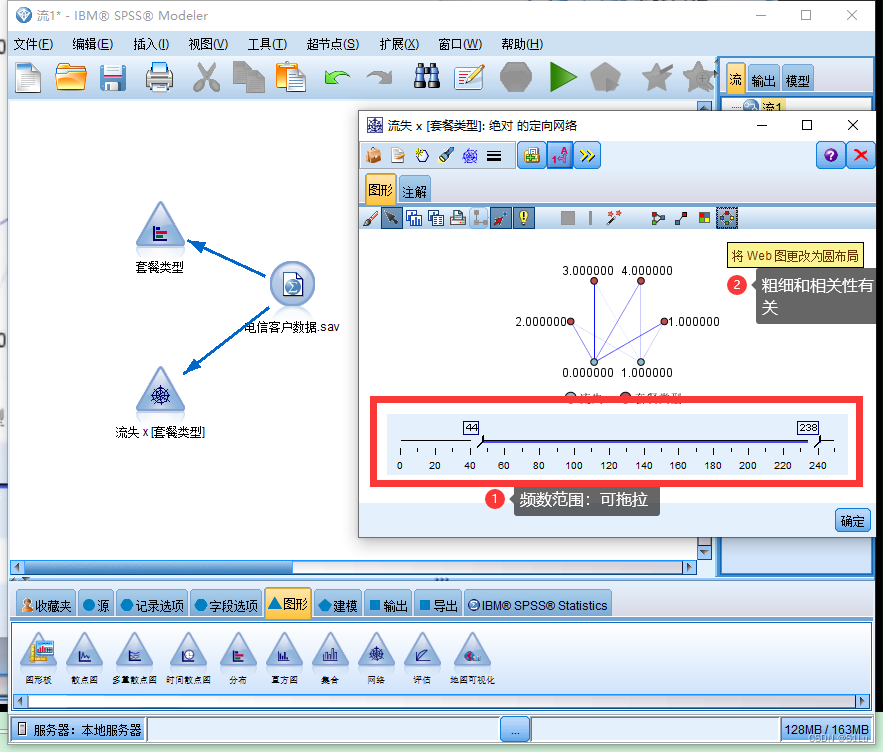
列联分析
图形分析并不能准确反映二分类型之间精确的相关程度,因此进行数值分析
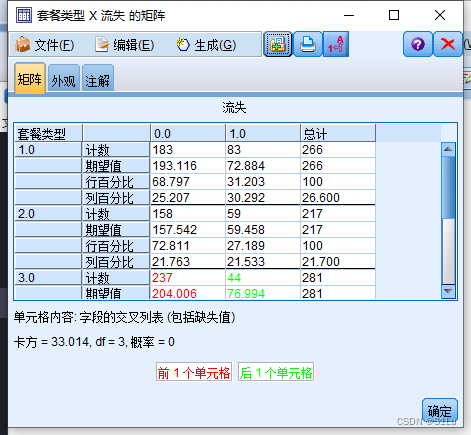
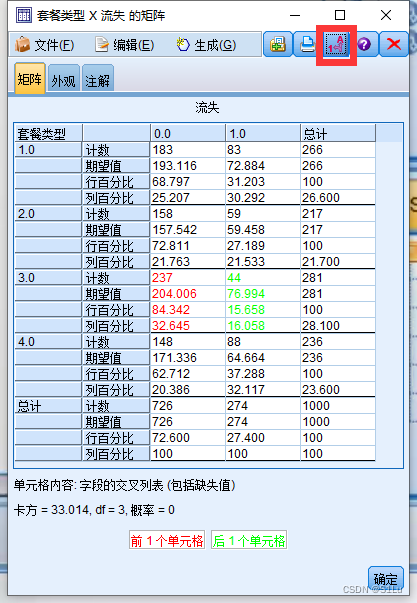
是必要的, 数值分析通常采用的方法是列联分析。列联分析包括两个步骤:第一步,计算二分类型的列联表;第二步,分析列联表中行、列变量之间的.相关性。
问:
这里,对电信客户数据
进行数值分析,目标是.分析客户“流失”与“套餐类型”是否相关。



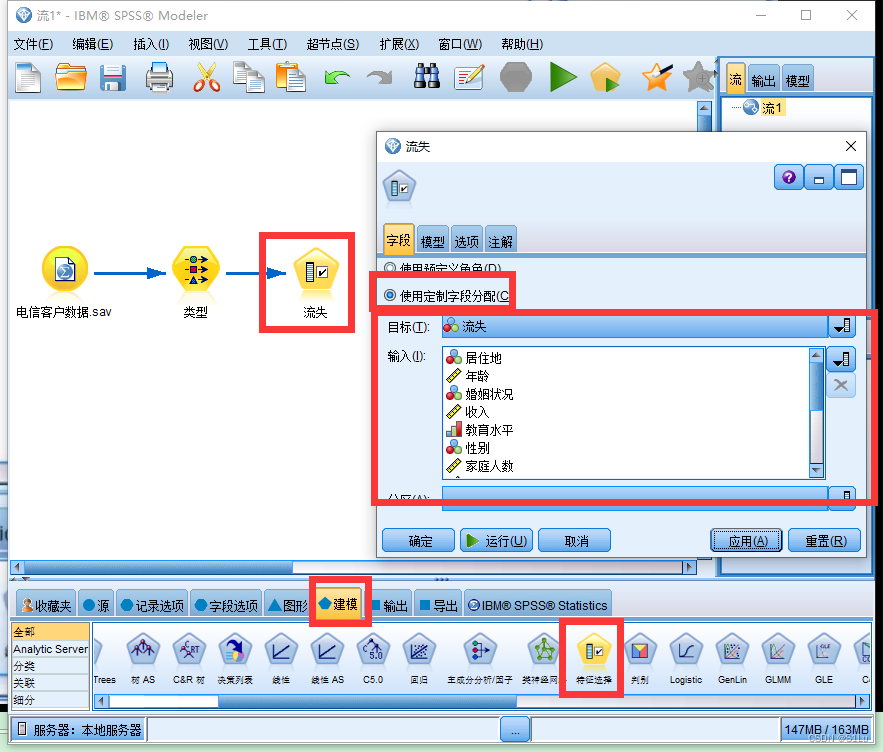
5、变量的重要性分析
时间:01:49:05
变量重要性概念:
◆从变量本身看,重要的输入变量应是携带信息较多的变量,也就是方差较大的变量。
◆从变量与目标变量的相关性角度看,重要变量应对目标变量的分类预测有显著意义。


四、统计图
时间:01:51:42
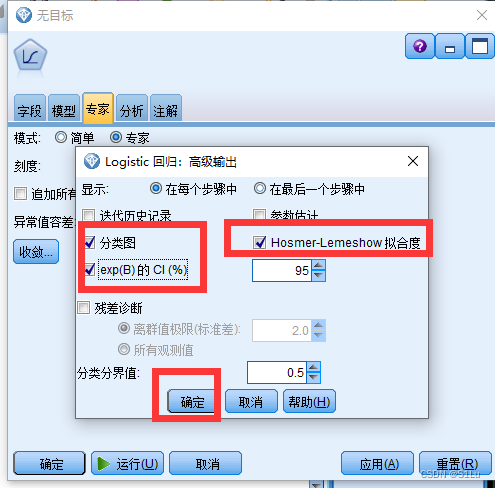
1、逻辑回归分析
时间:01:53:02
逻辑回归概念
- 逻辑回归分类:二项分类逻辑回归,多项分类逻辑回归。
- 底层原理:假设因变量y服从伯努利分布,Sigmoid映射函数的引入。
逻辑回归算法流程
- 收集数据
- 准备数据
- 分析数据
- 训练算法
- 测试算法
- 使用算法
逻辑回归案例
问:
◆现有一份顾客购买意愿数据表,文件名为: [购买判断.sav]
◆现需从顾客信息数据中,寻找顾客购买意愿的影响因素并训练模型用来预测。





2、关联分析
Apriori算法
时间:02:05:57
问:
- 以超市会员顾客购物信息.txt为例(1000名顾客)
- 存储格式:事实表
- 个人信息:会员卡号、消费金额、支付方式、性别、是否户主、年龄、收入;
- 一次购买商品的信息:果蔬、鲜肉、奶制品、蔬菜罐头、肉罐头、冷冻食品、啤酒、葡萄酒、软饮料、鱼、糖果。
- 目标1:分析商品之间的关联性,为超市提供决策。
- 目标2:在顾客已买商品的情况下预测可能性商品的连带购买
注意将食品项的角色分配为
任意



3、时间列序分析
时间序列概述
➢时间序列是指按时间顺序排列的一组数据序列,是-一个变量在一-定时间段内不同时间点 上观测值的集合。
➢根据观察时间的不同,时间序列中的时间间隔可以是年份、季度、月份、周、日或其他时间段。时间序列分析

时间序列分析
➢时间序列分析是一种根据时间序列揭示系统动态结构和规律的统计方法。
➢依据时间序列的特征,产生了与之相适用的方法。
➢时间序列分析的主要目的是根据已有的历史数据对未来进行预测。案例
问:
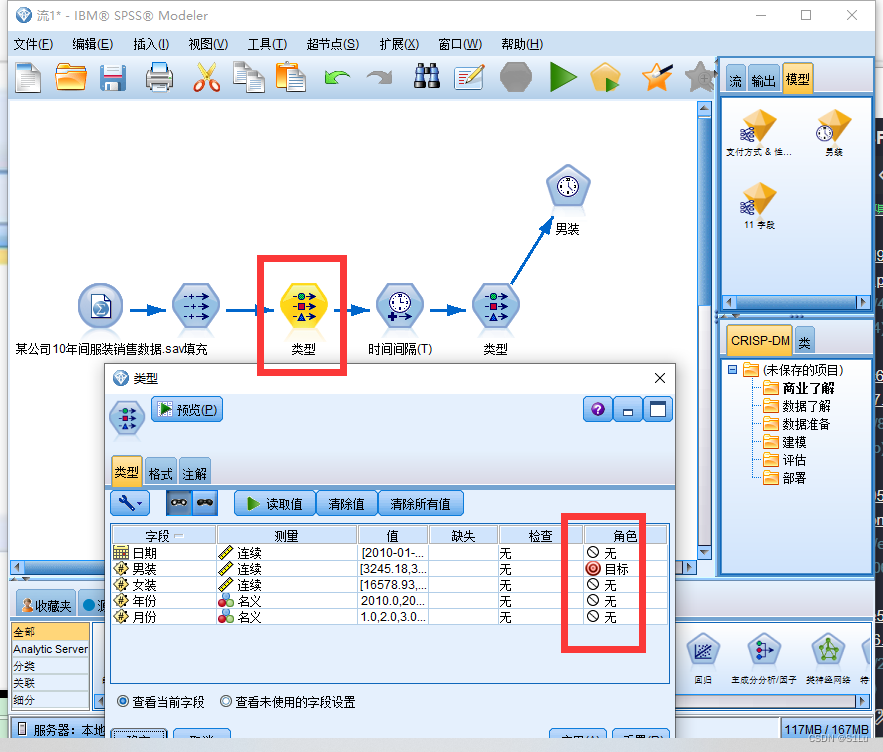
●该数据是某公司2010-2019十年间服装销售情况(单位:万元)
●需求:根据过去10年的销售数据来预测其男装类的月度销售情况
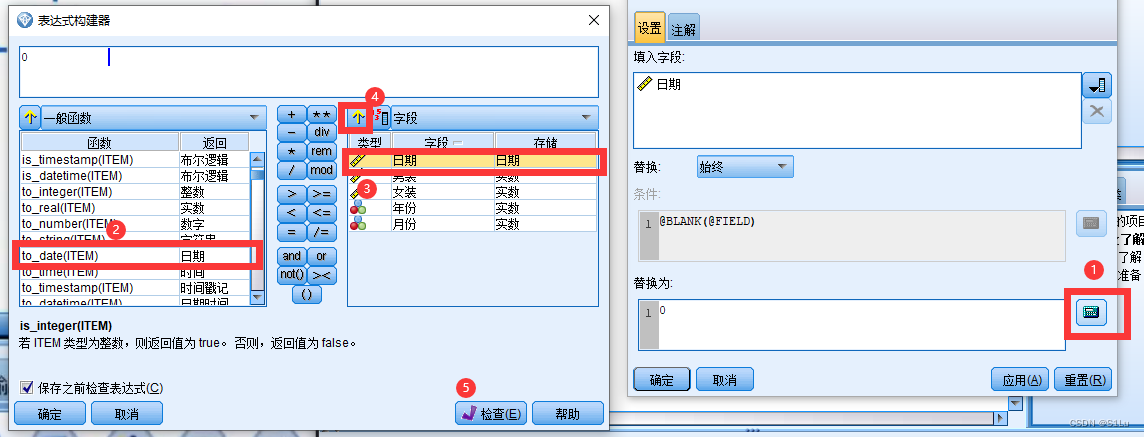
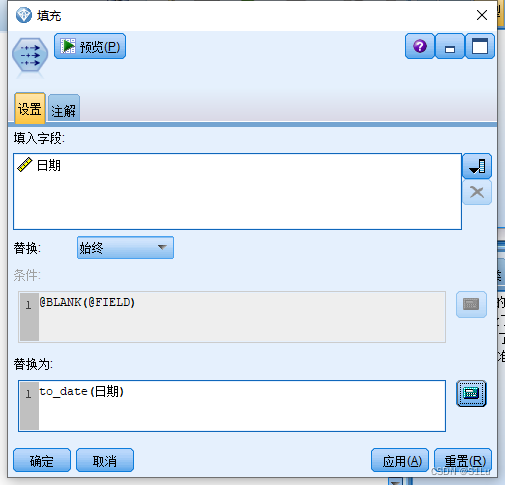
●操作: 定义日期-指定目标-设置时间间隔创建模型-检查模型填充 定义时间






模型一、指数平滑法



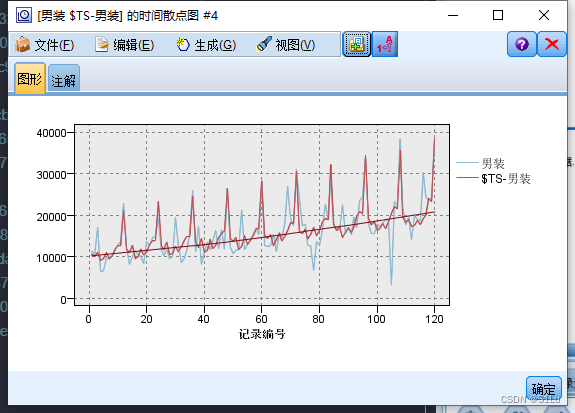
模型二、专家建模器


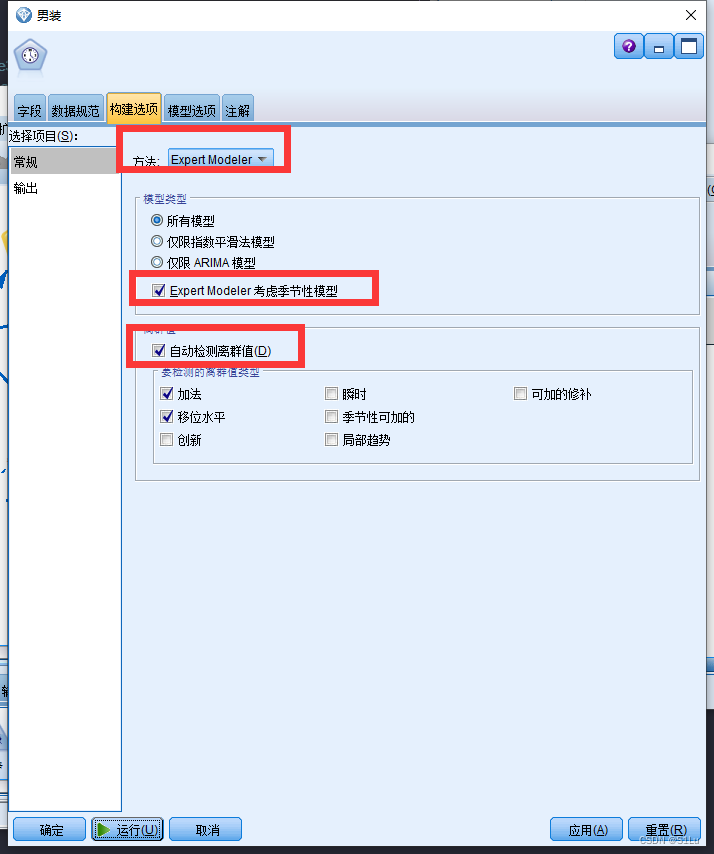

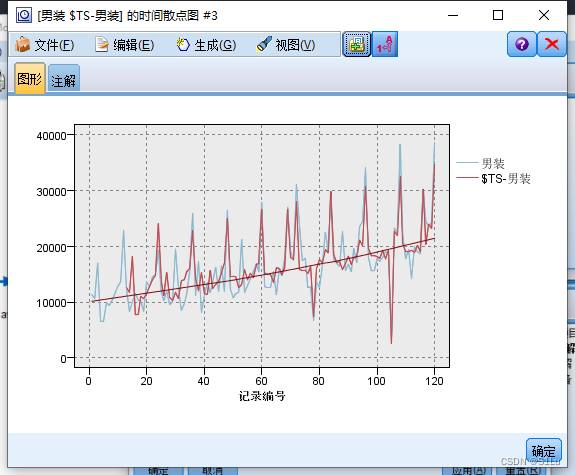
使用专家建模器分析未来三个的数据
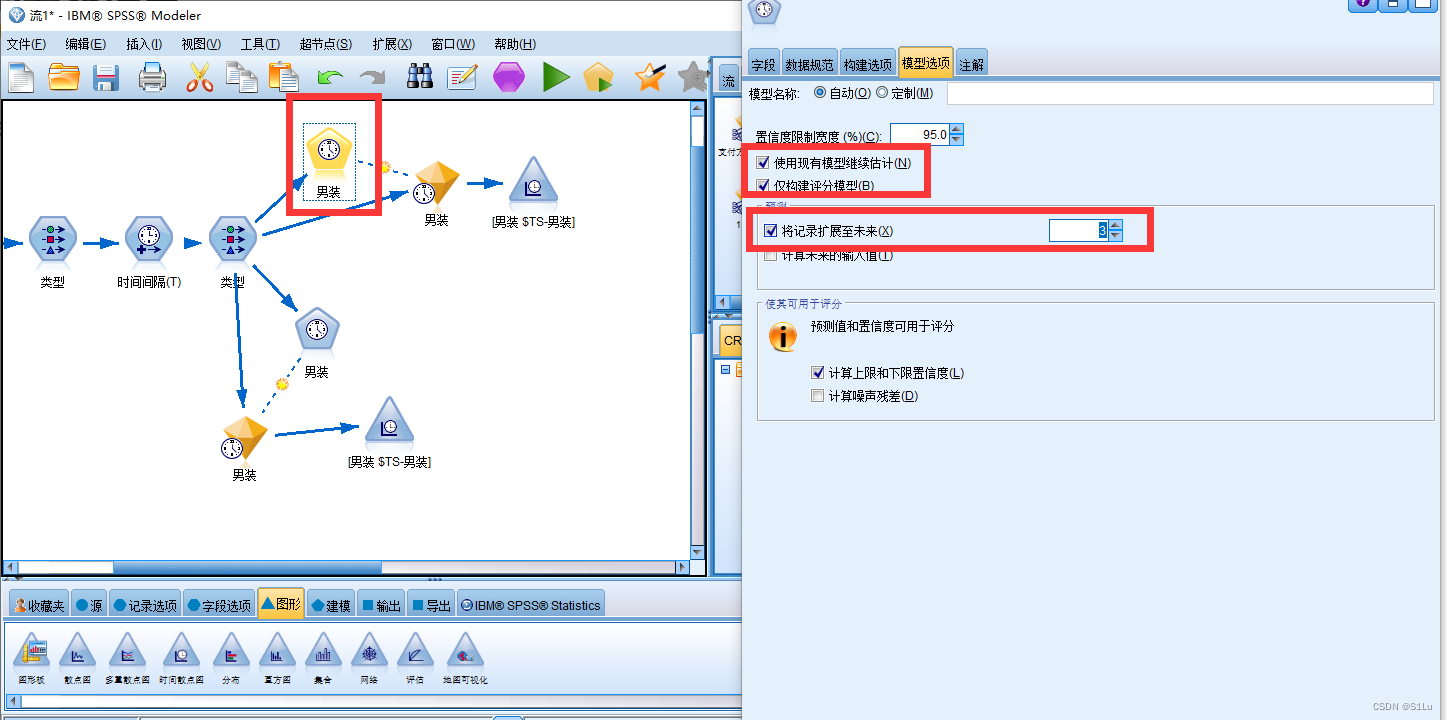

-
相关阅读:
自然语言处理(八):预训练BERT
Levenberg-Marquardt (LM) 算法进行非线性拟合
用Python执行JavaScript代码,这些方法你不可不知!
玩转外贸LinkedIn必备的三大特质,以及突破六度人脉技巧
Delphi 报错 Type androidx.collection.ArraySet is defined multiple times
设计模式之创建型模式
项目时间管理-架构真题(二十四)
设计模式—简单工厂模式
一个字符串数组里的id和json数组里的元素对比
19.服务器端会话技术Session
- 原文地址:https://blog.csdn.net/qq_51644623/article/details/127069322