-
Zookeeper入门(一)
1 zookeeper简介
ZooKeeper是一个分布式开源的分布式应用协调服务。它公开了一组简单的原语,分布式应用程序可以在其基础上实现用于同步、配置维护以及分组和命名的更高级别服务。它的设计便于编程,并使用了一种熟悉的文件系统目录树结构样式的数据模型。它使用Java语言编写,并且有针对Java和C的客户端。众所周知,协调服务很难做好。它们特别容易出现竞争条件和死锁等错误。
ZooKeeper背后的动机是为了减轻分布式应用从头开始实现协调服务的压力。2 zookeeper特性
简单
ZooKeeper允许分布式进程通过一个共享的分层命名空间来相互协调,这个命名空间的组织方式类似于一个标准的文件系统。命名空间由数据寄存器组成,在ZooKeeper中称为znodes,它们类似于文件和目录。与为存储而设计的典型文件系统不同,ZooKeeper的数据保存在内存中,这意味着ZooKeeper可以实现高吞吐量和低延迟数。ZooKeeper的实现重视高性能、高可用性、严格有序的访问。ZooKeeper的性能意味着它可以用于大型分布式系统。可靠性方面使它不会成为单点故障。严格的排序意味着可以在客户机上实现复杂的同步。可备份
就像它所协调的分布式进程一样,
ZooKeeper本身也被用于在一组称为集群的主机上进行复制
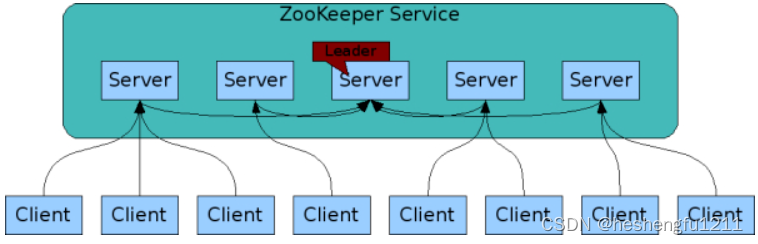
组成ZooKeeper服务的服务器必须相互了解。它们在内存中维护状态快照,并在持久存储中维护事务日志和快照。只要大多数服务器可用,ZooKeeper服务就可用。客户端连接单个ZooKeeper服务器。客户机维护一个TCP连接,通过该连接发送请求、获取响应、获取监视事件和发送心跳。如果与服务器的TCP连接中断,客户端将连接到另一个服务器
有序
ZooKeeper用一个数字标记每个更新,这个数字反映了所有ZooKeeper事务的顺序。后续操作可以使用该顺序来实现更高级的抽象,比如同步原语
快速
它在“读为主”的工作负载中尤其快。ZooKeeper应用程序运行在数千台机器上,在读比写更常见的地方性能最好,其比率约为10:1
3 数据模型和层次命名空间
ZooKeeper提供的命名空间很像标准的文件系统。名称是由斜杠(/)分隔的路径元素序列。ZooKeeper命名空间中的每个节点都由路径标识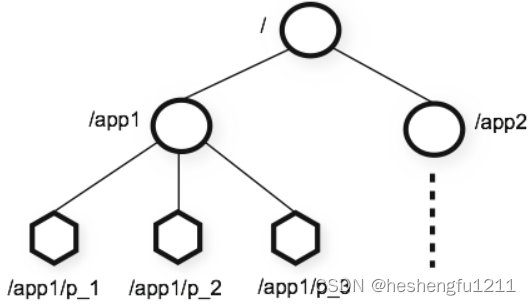
3.1 永久节点与临时节点
与标准文件系统不同,
ZooKeeper名称空间中的每个节点都可以有与其关联的数据以及子节点。这就像拥有一个文件系统,它允许一个文件同时也是一个目录。(ZooKeeper被设计用来存储协调数据:状态信息、配置、位置信息等,所以每个节点存储的数据通常很小,以字节到千字节为单位) 我们使用术语znode来表明我们谈论的ZooKeeper数据节点Znodes维护一个统计结构,其中包括数据更改的版本号、ACL更改和时间戳,以允许缓存验证和协调更新。每次znode的数据发生变化,版本号就会增加。例如,每当客户机检索数据时,它也会接收数据的版本。存储在名称空间中的每个
znode中的数据是原子地读取和写入的。读操作获取与znode相关的所有数据字节,写操作替换所有数据。每个节点都有一个访问控制列表(Access Control List, ACL),用于限制谁可以做什么。ZooKeeper也有临时节点的概念。只要创建znode的会话处于活动状态,这些临时节点就存在。当会话结束时,临时节点也被删除3.2 条件更新与监听
ZooKeeper支持监听器的概念,客户端可以在一个znode节点上设置监听,监听器watcher可以通过节点的变化来触发和删除。当一个watch被触发时,客户端会收到一个通知znode已经改变的数据包。当客户端与ZooKeeper服务器之间的连接中断时,客户端会收到本地通知。3.6.0 版本新特性:客户端还可以在一个znode上设置永久的递归监视,该监视在触发时不会删除,并递归地触发已注册的
znode以及任何子节点上的变化3.3 数据一致性保证
ZooKeeper非常快速和简单。但是,由于它的目标是成为更复杂的服务(如同步)构造的基础,因此它具有如下几个保证数据一致性的特性:- 顺序一致性: 客户端的更新将按照它们被发送的顺序更新
- 原子性:更新要么成功,要么失败,没有中间结果
- 但系统镜像:客户机将看到服务的相同视图,而不管它连接到哪个服务器。也就是说,即使客户端故障转移到具有相同会话的不同服务器,客户端也永远不会看到系统的旧视图
- 可靠性:一旦应用了更新,它将从那时起持续存储,直到客户端覆盖了更新
- 及时性: 系统的客户端视图保证在一定的时间范围内是最新的
3.4 简单的API
ZooKeeper的设计目标之一就是提供一个非常简单的编程界面。因此,它只支持这些操作- create: 在树中的某个位置创建节点
- delete: 删除节点
- exists: 测试在某个位置是否存在节点
- get data : 从节点中读取数据
- set data: 将数据写到节点中
- get children: 从一个节点中检索中所有子节点
- sync: 等待数据被传播
4 zookeeper的安装与启动
下载地址:https://zookeeper.apache.org/
我下的是最新的稳定版本压缩包:apache-zookeeper-3.7.1-bin.tar.gz
4.1 解压
tar zxvf apache-zookeeper-3.7.1-bin.tar.gz

执行重命名命令:mv apache-zookeeper-3.7.1-bin zookeeper-3.7.14.2 配置
-
执行以下命令进入配置项目录:
cd ./zookeeper-3.7.1/cfg -
执行拷贝zoo_sample.cfg文件并重命名为zoo.cfg命令:
cp zoo_sample.cfg zoo.cfg -
执行编辑
zoo.cfg命令vim zoo.cfg可以看到其中的配置项;

4.3 配置项解释
- tickTime: zookeeper服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个tickTime时间就会发送一个心跳, 单位毫秒(ms。 该参数用来定义心跳的时间间隔,zookeeper的客户端和服务端之间也有类似和Web开发里类似的session的概念, 而zookeeper里最小的session过期时间就是tickTime的两倍
- initLimit: Follow启动过程中会从Leader同步所有最新数据,然后确定自己能够对外服务的起始状态。Leader允许Follow在nitLimit时间内完成这个工作。通常情况下,我们不要太在意这个参数。如果zookeeper集群的数据量确实很大了,Follow在启动时从Leader同步数据的时间也要相应变长,在这种情况下才有必要调大参数值。initTime默认值为10
- syncLimit: Leader在运行过程中负责与ZK集群中的所有机器通信,例如通过一些心跳检测机制来检测机器的存活状态,如果Leader在发出心跳包之后在syncLimit时间之后还没有收到Follow的回应,那就任务这台Follow机器挂掉了。注意不要把这个参数设置过大,否则可能掩盖一些问题。
- dataDir: 存储快照文件snapshot的目录。默认情况下事务日志也会存储在这里,建议同时配置参数dataLogDir, 事务日志的写性能直接影响ZK性能
- clientPort: 客户端连接服务器的端口
- maxClientCnxns: ZK服务器最多允许的分客户端连接数
简化以下配置文件:
tickTime=2000 initLimit=10 syncLimit=5 dataDir=/usr/local/zookeeper-3.7.1/data dataLogDir=/usr/local/zookeeper-3.7.1/logs如何改cd到
/usr/local/zookeeper-3.7.1目录通过下面的命令创建data和logs目录mkdir data logs4.4 启动与停止ZK服务
进入到
/usr/local/zookeeper-3.7.1/bin目录下
可通过下面的方式将zookeeper/bin目录加入到环境变量# 编辑环境变量 vim /etc/profile # 在开发的文件中按住i键进入编辑状态后在CLASSPATH变量后面暴露zookeeper的环境变量 export ZOOKEEPER_HOME=/usr/local/zookeeper-3.7.1 PATH=$ZOOKEEPER_HOME/bin:$JAVA_HOME/bin:$PATH # 然后按住esc键输入:wq后保存退出 # 输入如下的命令使配置的环境变量生效 source /etc/profile
这样就可以在任服务器的任意目录下运行zkServer.sh和zkCli.sh命令了,无需进入zookeeper的bin目录下执行启动服务和建立客户端连接命令
打开命令行工具运行
zkServer.sh start命令,运行成功后控制太显示如下信息表示zookeeper服务启动成功Starting zookeeper ... STARTEDZooKeeper启动成功后可通过下面的命令停止zookeeper服务zkServer.sh stop关闭成功后会在命令控制台看到如下信息:
Stopping zookeeper ... STOPPED4.5 客户端连接zookeeper服务
在启动
ZooKeeper服务的前提下,打开一个新的客户端会话,在命令行中输入如下命令zkCli.sh运行成功后会看到客户端连接成功日志,最后可以在命令行中看到入戏控制台信息
[zk: localhost:2181(CONNECTED) 0]关于API的使用下一篇文章我们再介绍
5 集群环境搭建
由于是在单机环境下模拟集群环境, 因而需要使用不同端口来模拟不同主机
5.1 复制配置文件
cd /usr/local/zookeeper-3.7.1/cfg cp zoo.cfg zoo1.cfg cp zoo.cfg zoo2.cfg cp zoo.cfg zoo3.cfg5.2 创建数据和日志文件目录
# 切换到zookeeper主目录 cd ../ # 执行创建过个目录命令 mkdir data_1 data_2 data_3 logs_1 logs_2 logs_35.3 创建myid文件
echo "1" > ./data_1/myid echo "2" > ./data_2/myid echo "3" > ./data_3/myid5.4 修改配置文件
- zoo1.cfg
tickTime=2000 initLimit=10 syncLimit=5 dataDir=/usr/local/zookeeper-3.7.1/data_1 clientPort=2181 dataLogDir=/usr/local/zookeeper-3.7.1/logs_1 # server.x中的x和myid中的值保持一致,第一个端口用于Leader和Learner之间的同步通信,第二个端口用于选举过程中的投票通信 server.1=localhost:2887:3887 server.2=localhost:2888:3888 server.3=localhost:2889:3889- zoo2.cfg
tickTime=2000 initLimit=10 syncLimit=5 dataDir=/usr/local/zookeeper-3.7.1/data_2 clientPort=2182 dataLogDir=/usr/local/zookeeper-3.7.1/logs_2 # server.x中的x和myid中的值保持一致,第一个端口用于Leader和Learner之间的同步通信,第二个端口用于选举过程中的投票通信 server.1=localhost:2887:3887 server.2=localhost:2888:3888 server.3=localhost:2889:3889- zoo3.cfg
tickTime=2000 initLimit=10 syncLimit=5 dataDir=/usr/local/zookeeper-3.7.1/data_3 clientPort=2183 dataLogDir=/usr/local/zookeeper-3.7.1/logs_3 # server.x中的x和myid中的值保持一致,第一个端口用于Leader和Learner之间的同步通信,第二个端口用于选举过程中的投票通信 server.1=localhost:2887:3887 server.2=localhost:2888:3888 server.3=localhost:2889:38895.5 启动集群
在
zookeeper主目录下的命令控制台中依次执行下面三条命令zkServer.sh start ./conf/zoo1.cfg zkServer.sh start ./conf/zoo2.cfg zkServer.sh start ./conf/zoo3.cfg以上每输入一条命令回车后控制台都会有表示ZK服务节点启动成功的信息
Starting zookeeper ... STARTED5.6 验证服务节点状态
在
zookeeper主目录下的命令控制台中依次执行如下命令zkServer.sh status ./conf/zoo1.cfg zkServer.sh status ./conf/zoo2.cfg zkServer.sh status ./conf/zoo3.cfg可以看到如下信息:
Server1: Mode: follower Server2: Mode: leader Server2: Mode: follower打开三个客户端分别连上三个服务端
zkCli.sh -server localhost:2181 zkCli.sh -server localhost:2182 zkCli.sh -server localhost:2183连上之后可以看到在三个客户端执行
ls /命令 可以分别查到三个Server的当前目录结构都是一致的,都是[zookeeper]在连接Server1的客户端命令控制台中输入创建节点命令
create /firstNode serverCreated然后执行获取新创建节点数据命令:
get /firstNode可以看到
serverCreated信息在连接
Server2和Server3的客户端命令控制台执行get /firstNode命令也可以看到相同的信息说明在集群模式下任意一个服务端节点创建了节点数据,都会同步到另外的ZK服务节点中去
5.7 集群中增加Observer节点
zoo4.cfg节点配置中增加如下配置
# zoo4.cfg中单独添加 peerType=observer #servers列表中增加(集群中的所有zoox.cfg都需要添加) server.4=localhost:2890:38905.8 集群角色
- 领导者(Leader): 领导者不接受客户端请求,负责进行投票的发起和决议,
- 跟随者(Follower): 用于接收客户端请求并返回结果,同时参与Leader发起的投票
- 观察者(Observer):Observer可以接受客户端请求,并把请求转发给Leader, 但是Observer不参与投票过程,只是同步Leader的转态, Observer为系统扩展提供了一种方式
- 学习者(Learner): 和Leader进行状态同步的server统称为Learner, 以上的Follower和Observer都是Learner
本文首发个人微信公众号【阿福谈Web编程】, 欢迎读者朋友们加个关注一起交流学习技术。
-
相关阅读:
‘java‘ 不是内部或外部命令,也不是可运行的程序 或批处理文件
HTTP 协议详解-上(Fiddler 抓包演示)
C/C++ 面试八股文
【指针差找长度为n的数字字符串的第m项】
远程控制软件Splashtop的使用
科技赋能,创新发展!英码科技受邀参加2023中国创新创业成果交易会
day01
MySQL学习笔记23
贪心算法之找零钱
pytorch加载的cifar10数据集,到底有没有经过归一化
- 原文地址:https://blog.csdn.net/heshengfu1211/article/details/127040112