-
django-haystack使用小结
细节请参考大佬文章,但是文章时间比较久远,部分设置尤其是中文分词器设置的位置有些许变化:
https://blog.csdn.net/qiqiyingse/article/details/110299639whoosh 全文检索的核心程序
jieba 中文分词工具(全文检索需要分词提供成功率,whoosh默认不带中文分词,所以用一个免费的分词工具jieba)
haystack 对于whoosh的封装,也可以调用es全文检索的流程
1.配置haystack环境
INSTALLED_APPS = [ ... 'haystack', ]HAYSTACK_CONNECTIONS = { 'default': { #使用whoosh搜索引擎,由于要自定义分词器,所以用自定义的Engine 'ENGINE': 'yewu.whoosh_cn_backend.WhooshEngine', 'PATH': os.path.join(BASE_DIR, 'whoosh_index'), }, }HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor''运行2.修改分词器
我的django-haystack 是3.2.1版本的,你们可以参考一下。
至Lib\site-packages\haystack\backends中复制whoosh_backend.py到我们自己的目录
把文件中所有的StemmingAnalyzer替换成ChineseAnalyzer(from jieba.analyse import ChineseAnalyzer)3.指定索引模板文件
在项目的“templates/search/indexes/应用名称/”下创建“模型类名称_text.txt”文件(例如 templates/search/indexes/blog/blog_text.txt),全小写即可。
此文件指定将模型中的哪些字段建立索引,写入如下内容:(不要改掉object,可以继续添加其他的字段)
# templates/search/indexes/blog/blog_text.txt <div ><b>标题:</b></div> {{ object.title }} <div ><b>内容:</b></div> {{ object.body }}然后运行rebuild指令,生成索引文件
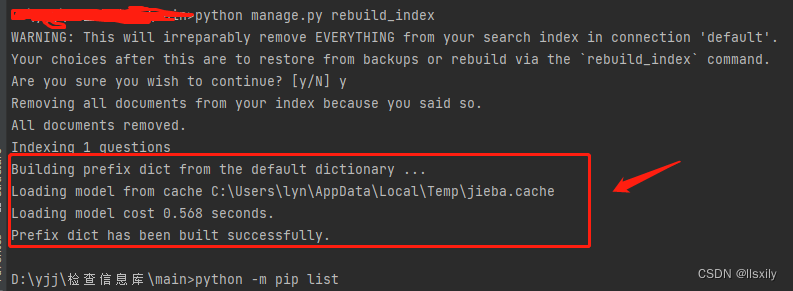
看到红框里面的输出才是对的,我之前配置错了分词器一直只显示到红框前,导致搜索一直没有结果。4.新建search_indexes.py文件
在文件里面新建一个index类,把我们的model和上面的模型索引文件配置进去。
class QuestionSearchIndex(indexes.SearchIndex, indexes.Indexable): # 设置需要检索的主要字段内容 use_template表示字段内容在模板中 text = indexes.CharField(document=True, use_template=True) # 获取检索对应对的模型 def get_model(self): return Question # 设置检索需要使用的查询集 def index_queryset(self, using=None): """Used when the entire index for model is updated.""" return self.get_model().objects.all()5.自定义view
接下来是网络上比较难找的,我们不需要他返回templates的数据的时候直接重写他的render_to_response函数就可以控制返回的结果了。
from haystack.generic_views import SearchView class LlsxilySearchView(SearchView): def render_to_response(self, context, **response_kwargs): print(context) print(**response_kwargs) return JsonResponse({'msg': '不能用drf的response', 'code': status.HTTP_401_UNAUTHORIZED}, status=200, json_dumps_params={'ensure_ascii': False}) # 不能用drf的Response # return Response({'success': True, 'code': status.HTTP_200_OK}, status=status.HTTP_200_OK)6.GET请求的时候带上q参数就能查询了

PS:7.前端对接
不知道是不是这个库用的人实在少,目前大部分系统都是前后端分离的情况下,我找不到这个库的前后端分离要怎么做。
只好自己研究研究再记录一下:咱们上面第3点有写一个索引模板文件(模板修改后需要运行rebuild_index才会生效,数据的修改不用)
接下来如果匹配到你的搜索内容,他就会根据你的模板返回信息(在Index类里面配置好,看第4点)你可以打个断点看一下
render_to_response函数里面的context,里面的context['object_list']就是匹配中关键词后返回的数据,会根据你写的索引模板把相关的数据填写进去。也就说,你可以自定义的得到一段html代码。得到这个html代码后我应该如何将它放到我的前端代码里呢?
<div dangerouslySetInnerHTML={{__html: textHightLight(item.content, key_word)}}></div>我用到了一个叫
dangerouslySetInnerHTML,顾名思义危险的把html插入的函数(由于我只是内部系统,不太涉及安全问题,请各位使用的时候还请注意。)
那这里的textHightLight又是啥呢,由于我研究了半天都没找到在haystack怎么进行高亮标识。
所以我就用最土的办法在react里面去处理高亮,代码供大家参考。const textHightLight = (value, keyWord) => { console.log(value) if (value && value.indexOf(keyWord) !== -1 && keyWord !== '') { // eval 为拼接字符串,进行全局搜索替换 let ret = value.replace(eval('/' + keyWord + '/g'), `${keyWord}`) console.log(ret) return ret } return value }最近比较忙,这篇文章写的杂乱,还请各位看官多多批评指正。
-
相关阅读:
Vue2与Vue3区别01
Go死锁——当Channel遇上Mutex时
美国想通过法案建立加密世界的新SWIFT
<sa8650>sa8650开发板-之-刷机教程(flashing)
Winform +OpenCvSharp更换证件照底色
融合定位在石油化工人员定位中应用
Keycloak中授权的实现
私有云不是真正的云计算!
lv11 嵌入式开发 计算机硬件基础 1
我在高职教STM32——GPIO入门之按键输入(2)
- 原文地址:https://blog.csdn.net/u013113491/article/details/127045228