-
@Elasticsearch之深度应用及原理剖析--Filter过滤机制剖析(bitset机制与caching机制)
title: ElasticSearch之深度应用及原理剖析
author: Xoni
tags:- 搜索引擎
- Elasticsearch
categories: - 搜索引擎
- Elasticsearch
abbrlink: 5a1f6e0b
第1节 索引文档写入和近实时搜索原理

第9节 Filter过滤机制剖析(bitset机制与caching机制)
1. 在倒排索引中查找搜索串,获取document list
解析:
date举例:倒排索引列表,过滤date为2020-02-02(filter:2020-02-02)。
去倒排索引中查找,发现2020-02-02对应的document list是doc2、doc3。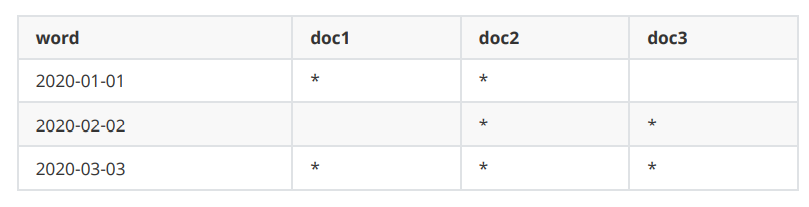
2. Filter为每个在倒排索引中搜索到的结果,构建一个bitset,[0, 0, 0, 1, 0, 1](非常重要)
解析:
- 使用找到的document list,构建一个bitset(二进制数组,用来表示一个document对应一个filter条件是否匹配;匹配为1,不匹配为0)。
- 为什么使用bitset:尽可能用简单的数据结构去实现复杂的功能,可以节省内存空间、提升性能。
- 由上步的document list可以得出该filter条件对应的bitset为:[0, 1, 1];代表着doc1不匹配filter,doc2、doc3匹配filter。
3. 多个过滤条件组合查询时,遍历每个过滤条件对应的bitset,优先从最稀疏的开始搜索,查找满足所有条件的
document
解析:- 多个filter组合查询时,每个filter条件都会对应一个bitset。
- 稀疏、密集的判断是通过匹配的多少(即bitset中元素为1的个数)[0, 0, 0, 1, 0, 0] 比较稀疏、[0,1, 0, 1, 0, 1] 比较密集 。
- 先过滤稀疏的bitset,就可以先过滤掉尽可能多的数据。
- 遍历所有的bitset、找到匹配所有filter条件的doc。
请求:filter,postDate=2017-01-01,userID=1;
postDate:[0, 0, 1, 1, 0, 0]
userID: [0, 1, 0, 1, 0, 1]
遍历完两个bitset之后,找到的匹配所有条件的doc,就是doc4。 - 将得到的document作为结果返回给client。
4. caching bitset,跟踪query,在最近256个query中超过一定次数的过滤条件,缓存其bitset。对于小segment(<1000,或<3%),不缓存bitset
解析:
- 比如postDate=2020-01-01,[0, 0, 1, 1, 0, 0];可以缓存在内存中,这样下次如果再有该条件查询时,就不用重新扫描倒排索引,反复生成bitset,可以大幅提升性能。
- 在最近256个filter中,有某个fiflter超过一定次数,次数不固定,就会自动缓存该filter对应的bitset。
- filter针对小segment获取的结果,可以不缓存,segment记录数<1000,或者segment大小
- filter比query的好处就在于有caching机制,filter bitset缓存起来便于下次不用扫描倒排索引。以后只要是由相同的filter条件的,会直接使用该过滤条件对应的cached bitset
比如postDate=2020-01-01,[0, 0, 1, 1, 0, 0];可以缓存在内存中,这样下次如果再有该条件查询时,就不用重新扫描倒排索引,反复生成bitset,可以大幅提升性能。 - filter比query的好处就在于有caching机制,filter bitset缓存起来便于下次不用扫描倒排索引。以后只要是由相同的filter条件的,会直接使用该过滤条件对应的cached bitset
5. 如果document有新增或修改,那么cached bitset会被自动更新
示例:postDate=2020-01-01,filter:[0, 0, 1, 0]
- 新增document,id=5,postDate=2020-01-01;会自动更新到postDate=2020-01-01这个filter的bitset中,缓存要会进行相应的更新。postDate=2020-01-01的bitset:[0, 0, 1, 0, 1]。
- 修改document,id=1,postDate=2019-01-31,修改为postDate=2020-01-01,此时也会自动更新bitset:[1, 0, 1, 0, 1]。
6. filter大部分情况下,在query之前执行,先尽量过滤尽可能多的数据
- query:要计算doc对搜索条件的relevance score,还会根据这个score排序。
- filter:只是简单过滤出想要的数据,不计算relevance score,也不排序。
-
相关阅读:
Lwip中实现DM9000/DM9003驱动之二
智能工单系统(IT运维工单系统),为企业IT运维跨部门协作量身定制!
prometheus学习4Grafana监控mysql&blackbox了解
元宇宙崛起:区块链与金融科技共绘数字新世界
tmux的简单使用
腾讯云AMD服务器标准型SA4实例CPU性能测评
单层应用升级到多层应用2
用户中心系统开发--表设计以及表说明
计算机毕业设计(附源码)python中学网站
QGIS 捕捉
- 原文地址:https://blog.csdn.net/weixin_45992021/article/details/127041115