-
TorchDrug教程--逆合成
TorchDrug教程–逆合成
教程来源TorchDrug开源
目录
反合成是药物发现的一项基本任务。给定一个目标分子,反合成的目标是确定一组可以产生目标的反应物。
在这个例子中,我们将展示如何使用G2Gs框架预测逆合成。G2Gs首先识别反应中心,即产物中产生的键。根据反应中心,产物被分解成几个合成子,每个合成子被转化为一个反应物。
准备数据
我们使用标准USPTO50k数据集。该数据集包含50k分子及其合成途径。首先,让我们下载并加载数据集。这可能需要一段时间。有两种模式来加载数据集。reaction模式将数据集加载为(
reactants,product)对,用于中心识别。synthon模式将数据集作为(reactant,synthon)对加载,用于synthon完成。from torchdrug import data, datasets, utils reaction_dataset = datasets.USPTO50k("~/molecule-datasets/", atom_feature="center_identification", kekulize=True) synthon_dataset = datasets.USPTO50k("~/molecule-datasets/", as_synthon=True, atom_feature="synthon_completion", kekulize=True)然后我们将数据集中的一些样本可视化。对于反应数据集,我们可以使用connected components()将反应物图和生成物图拆分为单个分子。注意USPTO50k忽略了所有非目标产品,所以右边只有一个产品。
from torchdrug.utils import plot for i in range(2): sample = reaction_dataset[i] reactant, product = sample["graph"] reactants = reactant.connected_components()[0] products = product.connected_components()[0] plot.reaction(reactants, products)
下面是synthon数据集中对应的示例。for i in range(3): sample = synthon_dataset[i] reactant, synthon = sample["graph"] plot.reaction([reactant], [synthon])
为了确保两个数据集使用相同的split,我们可以在调用split()之前设置随机种子。import torch torch.manual_seed(1) reaction_train, reaction_valid, reaction_test = reaction_dataset.split() torch.manual_seed(1) synthon_train, synthon_valid, synthon_test = synthon_dataset.split()中心识别
现在我们定义我们的模型。我们使用一个关系图卷积网络(RGCN)作为我们的表示模型,并包装它来完成中心识别任务。注意,这里也可以使用其他图表示学习模型。
from torchdrug import core, models, tasks reaction_model = models.RGCN(input_dim=reaction_dataset.node_feature_dim, hidden_dims=[256, 256, 256, 256, 256, 256], num_relation=reaction_dataset.num_bond_type, concat_hidden=True) reaction_task = tasks.CenterIdentification(reaction_model, feature=("graph", "atom", "bond"))reaction_optimizer = torch.optim.Adam(reaction_task.parameters(), lr=1e-3) reaction_solver = core.Engine(reaction_task, reaction_train, reaction_valid, reaction_test, reaction_optimizer, gpus=[0], batch_size=128) reaction_solver.train(num_epoch=50) reaction_solver.evaluate("valid") reaction_solver.save("g2gs_reaction_model.pth")验证集上的计算结果可能如下所示
accuracy: 0.836367我们可以从我们的模型中展示一些预测。为了多样性,我们收集了4种不同反应类型的样品。
batch = [] reaction_set = set() for sample in reaction_valid: if sample["reaction"] not in reaction_set: reaction_set.add(sample["reaction"]) batch.append(sample) if len(batch) == 4: break batch = data.graph_collate(batch) batch = utils.cuda(batch) result = reaction_task.predict_synthon(batch)下面的代码可视化了基本事实以及我们对样本的预测。我们用蓝色代表基本事实,红色代表错误的预测,紫色代表正确的预测。
def atoms_and_bonds(molecule, reaction_center): is_reaction_atom = (molecule.atom_map > 0) & \ (molecule.atom_map.unsqueeze(-1) == \ reaction_center.unsqueeze(0)).any(dim=-1) node_in, node_out = molecule.edge_list.t()[:2] edge_map = molecule.atom_map[molecule.edge_list[:, :2]] is_reaction_bond = (edge_map > 0).all(dim=-1) & \ (edge_map == reaction_center.unsqueeze(0)).all(dim=-1) atoms = is_reaction_atom.nonzero().flatten().tolist() bonds = is_reaction_bond[node_in < node_out].nonzero().flatten().tolist() return atoms, bonds products = batch["graph"][1] reaction_centers = result["reaction_center"] for i, product in enumerate(products): true_atoms, true_bonds = atoms_and_bonds(product, product.reaction_center) true_atoms, true_bonds = set(true_atoms), set(true_bonds) pred_atoms, pred_bonds = atoms_and_bonds(product, reaction_centers[i]) pred_atoms, pred_bonds = set(pred_atoms), set(pred_bonds) overlap_atoms = true_atoms.intersection(pred_atoms) overlap_bonds = true_bonds.intersection(pred_bonds) atoms = true_atoms.union(pred_atoms) bonds = true_bonds.union(pred_bonds) red = (1, 0.5, 0.5) blue = (0.5, 0.5, 1) purple = (1, 0.5, 1) atom_colors = {} bond_colors = {} for atom in atoms: if atom in overlap_atoms: atom_colors[atom] = purple elif atom in pred_atoms: atom_colors[atom] = red else: atom_colors[atom] = blue for bond in bonds: if bond in overlap_bonds: bond_colors[bond] = purple elif bond in pred_bonds: bond_colors[bond] = red else: bond_colors[bond] = blue plot.highlight(product, atoms, bonds, atom_colors, bond_colors)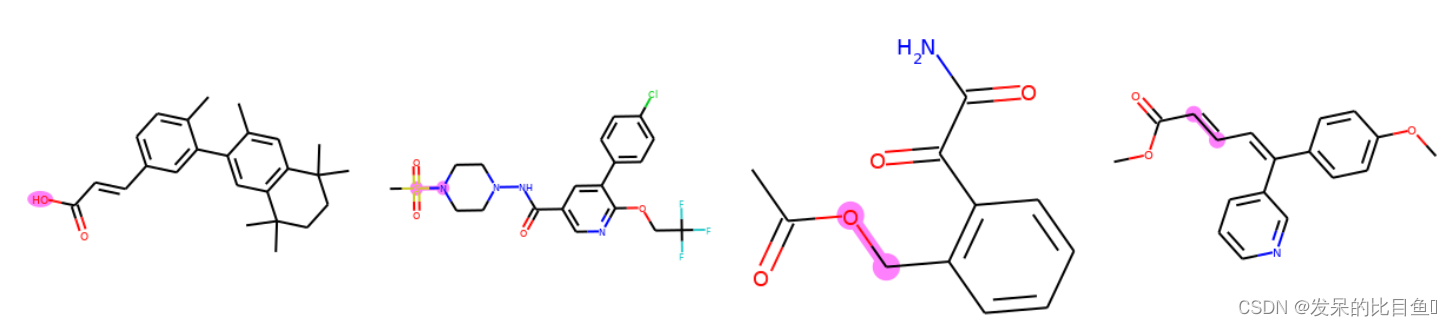
合成纤维完成
类似地,我们在synthon数据集上训练synthon完成模型。
synthon_model = models.RGCN(input_dim=synthon_dataset.node_feature_dim, hidden_dims=[256, 256, 256, 256, 256, 256], num_relation=synthon_dataset.num_bond_type, concat_hidden=True) synthon_task = tasks.SynthonCompletion(synthon_model, feature=("graph",))synthon_optimizer = torch.optim.Adam(synthon_task.parameters(), lr=1e-3) synthon_solver = core.Engine(synthon_task, synthon_train, synthon_valid, synthon_test, synthon_optimizer, gpus=[0], batch_size=128) synthon_solver.train(num_epoch=10) synthon_solver.evaluate("valid") synthon_solver.save("g2gs_synthon_model.pth")我们可以得到一些结果
bond accuracy: 0.983013 node in accuracy: 0.967535 node out accuracy: 0.892999 stop accuracy: 0.929348 total accuracy: 0.844374然后,我们执行束搜索,以产生候选反应物。
batch = [] reaction_set = set() for sample in synthon_valid: if sample["reaction"] not in reaction_set: reaction_set.add(sample["reaction"]) batch.append(sample) if len(batch) == 4: break batch = data.graph_collate(batch) batch = utils.cuda(batch) reactants, synthons = batch["graph"] reactants = reactants.ion_to_molecule() predictions = synthon_task.predict_reactant(batch, num_beam=10, max_prediction=5) synthon_id = -1 i = 0 titles = [] graphs = [] for prediction in predictions: if synthon_id != prediction.synthon_id: synthon_id = prediction.synthon_id.item() i = 0 graphs.append(reactants[synthon_id]) titles.append("Truth %d" % synthon_id) i += 1 graphs.append(prediction) if reactants[synthon_id] == prediction: titles.append("Prediction %d-%d, Correct!" % (synthon_id, i)) else: titles.append("Prediction %d-%d" % (synthon_id, i)) # reset attributes so that pack can work properly mols = [graph.to_molecule() for graph in graphs] graphs = data.PackedMolecule.from_molecule(mols) graphs.visualize(titles, save_file="uspto50k_synthon_valid.png", num_col=6)
逆合成
给定训练过的模型,我们可以将它们组合成一个端点管道进行逆向合成。这是通过将两个子任务包裹在一个逆合成任务中来完成的。
注意,如果您从未声明
reaction_task和synthon_task的求解器,那么在将它们组合到管道中之前,您需要手动调用它们的preprocess()方法。# reaction_task.preprocess(reaction_train, None, None) # synthon_task.preprocess(synthon_train, None, None) task = tasks.Retrosynthesis(reaction_task, synthon_task, center_topk=2, num_synthon_beam=5, max_prediction=10)管道将对来自两个子任务的预测之间的所有可能组合执行波束搜索。为了演示,我们使用一个较小的光束尺寸,并且只对验证集的子集进行评估。注意,如果我们给光束搜索更多的预算,结果会更好。
from torch.utils import data as torch_data lengths = [len(reaction_valid) // 10, len(reaction_valid) - len(reaction_valid) // 10] reaction_valid_small = torch_data.random_split(reaction_valid, lengths)[0] optimizer = torch.optim.Adam(task.parameters(), lr=1e-3) solver = core.Engine(task, reaction_train, reaction_valid_small, reaction_test, optimizer, gpus=[0], batch_size=32)要加载两个子任务的参数,我们只需
load_optimizer。注意负载优化器应该设置为False以避免冲突。solver.load("g2gs_reaction_model.pth", load_optimizer=False) solver.load("g2gs_synthon_model.pth", load_optimizer=False) solver.evaluate("valid")反合成的准确性可能接近于以下
top-1 accuracy: 0.47541 top-3 accuracy: 0.741803 top-5 accuracy: 0.827869 top-10 accuracy: 0.879098以下是验证集中样本的前1个预测
batch = [] reaction_set = set() for sample in reaction_valid: if sample["reaction"] not in reaction_set: reaction_set.add(sample["reaction"]) batch.append(sample) if len(batch) == 4: break batch = data.graph_collate(batch) batch = utils.cuda(batch) predictions, num_prediction = task.predict(batch) products = batch["graph"][1] top1_index = num_prediction.cumsum(0) - num_prediction for i in range(len(products)): reactant = predictions[top1_index[i]].connected_components()[0] product = products[i].connected_components()[0] plot.reaction(reactant, product)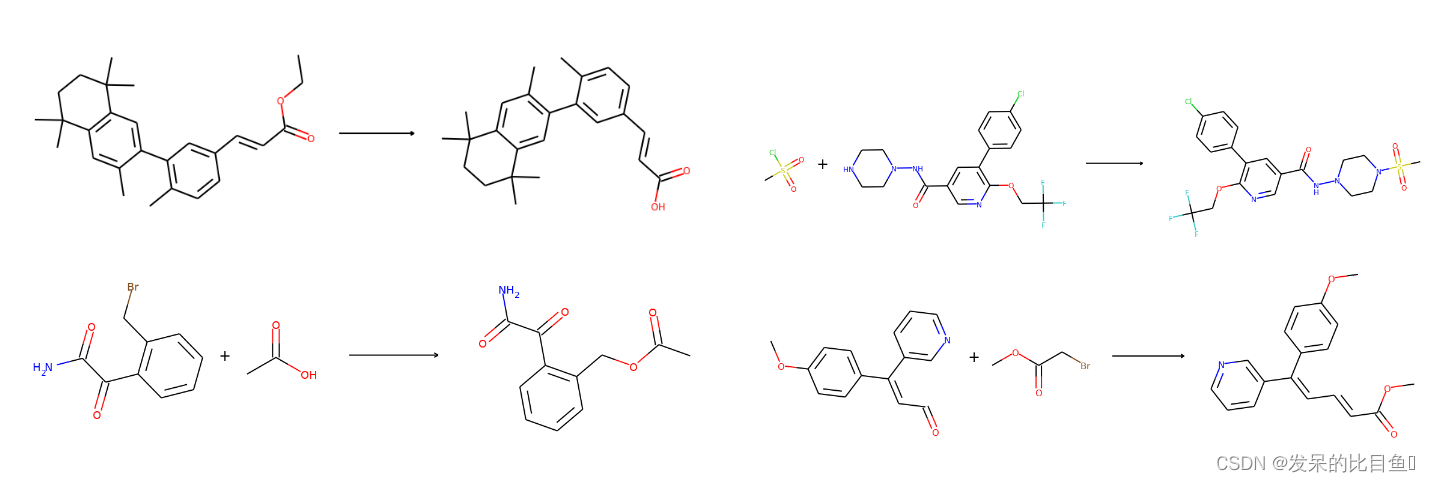
-
相关阅读:
《微积分的力量》读书摘记
【Java开发岗:Spring篇】
U盘提示格式化怎么搞定?本文有5种方法(内含教程)
计算机网络 二、网络协议
STL源码
python毕业设计作品基于django框架 多用户商城平台系统毕设成品(8)毕业设计论文模板
【论文阅读】Cornus: Atomic Commit for a Cloud DBMS with Storage Disaggregation
vue3接入腾讯地图后遇到的错位问题探究
springboot网上电子书店下载购买系统-图书商城网站961h3-java-ssm二级分类
【JavaScript-进阶】详解数据类型,内存分配,API元素对象获取
- 原文地址:https://blog.csdn.net/weixin_42486623/article/details/127039141