-
数据库(2):表的CRUD\内置函数\多表符合查询

"敢拼敢当,勇敢去闯"
前面一篇主要讲了数据库、数据库表的操作和使用,以及表是如何受到约束的,约束对表而言为什么需要。 可以看出 alter + table\database 都是作用于 表属性而非表值,那么如何对表进行处理呢?
-------前言
(一)表的CURD
(1)Create
①单行数据+全列插入

指定插入:
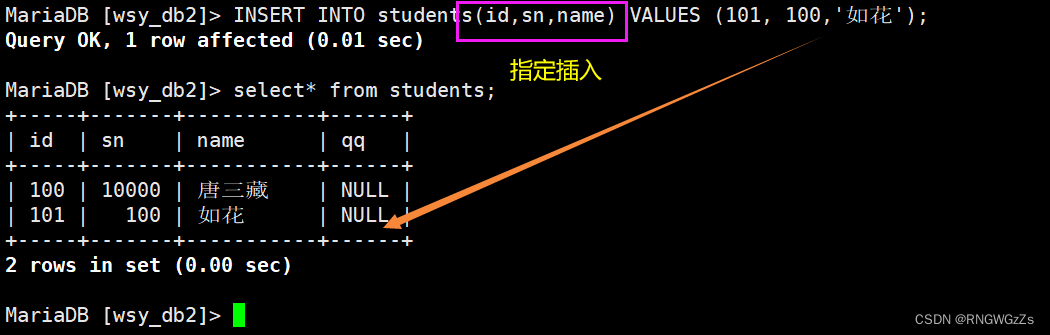
②多行指定插入
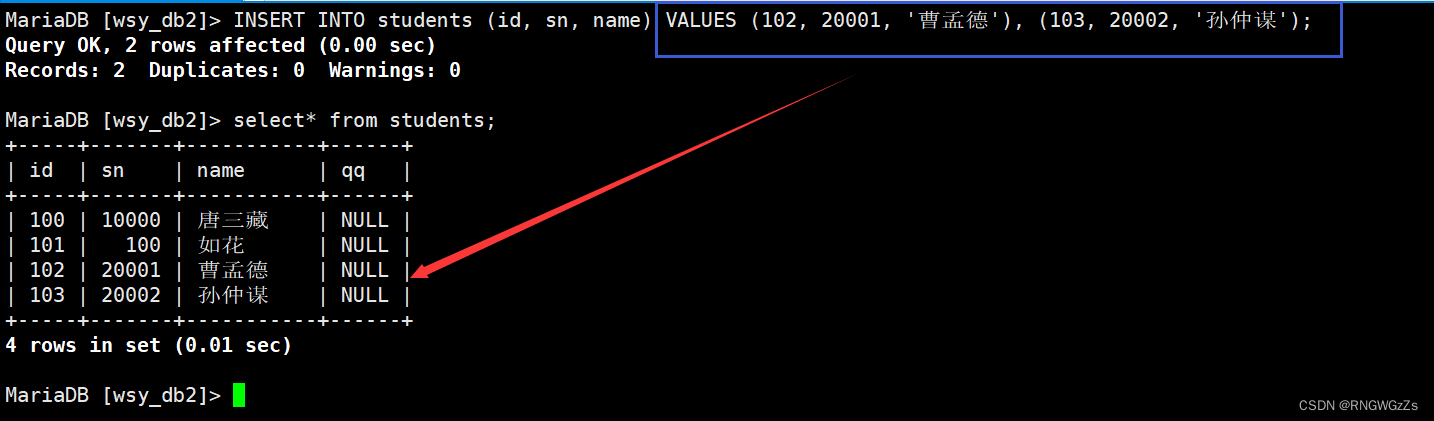
③插入出现冲突后 更新操作
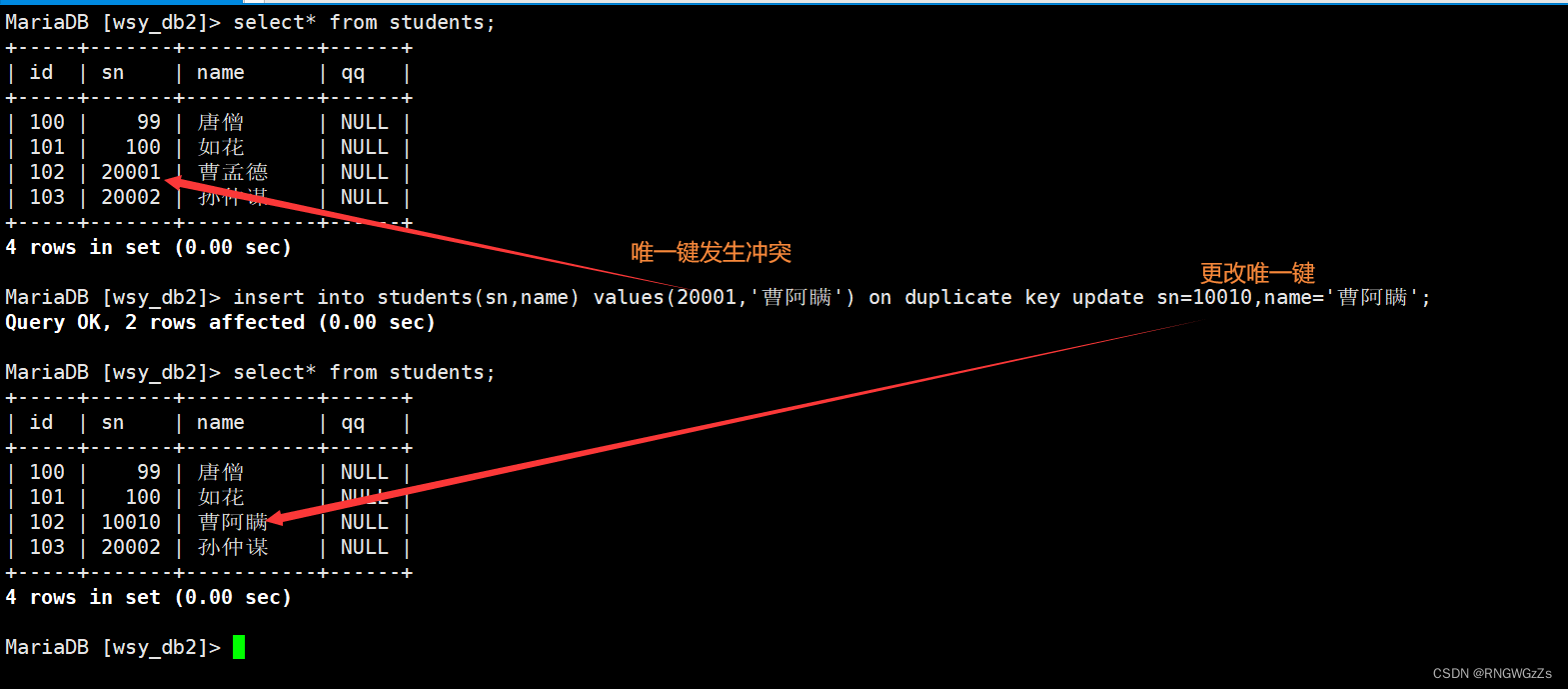
insert ... on duplicate key updatecolumn = value [, column = value] ...不免当我们不知道自己插入的值,是否会与表内的 主键、唯一键发生冲突时,sql不会给我们进行执行。
唯一键冲突;
主键冲突;
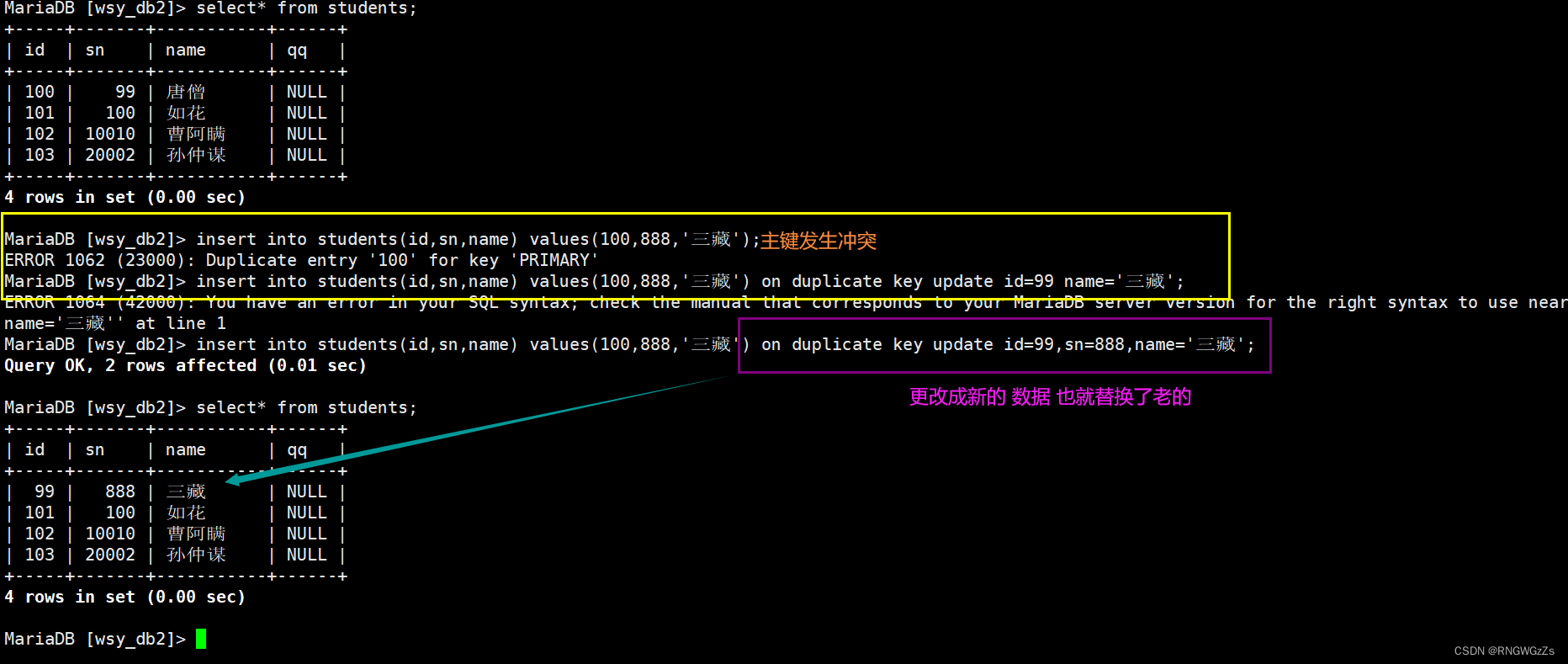
④替换
replace into + table_name-- 主键 或者 唯一键 没有冲突,则直接插入;-- 主键 或者 唯一键 如果冲突,则删除后再插入产生冲突;

产生冲突

(2)Retrieve
SELECT[DISTINCT] {* | {column [, column] ...}[FROM table_name][WHERE ...][ORDER BY column [ASC | DESC], ...]LIMIT ...①全队列查询
1.但全队列查询一般不建议使用,因为实际的数据量是很大的、仅仅从表中 查询数据打印在显示器上花费的时间就很多。
2.可能会影响到索引的使用。(目前不讲)

②指定列查询

查询列与表达式;
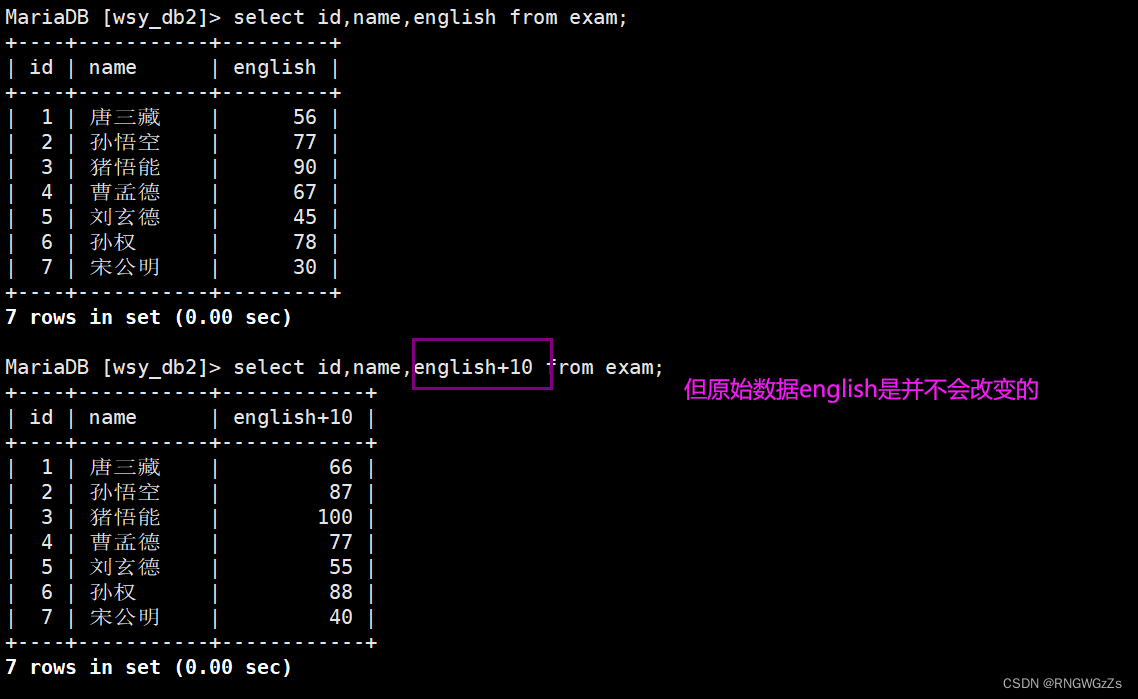
③查询别名as

④去重结果
distinct 去重条件
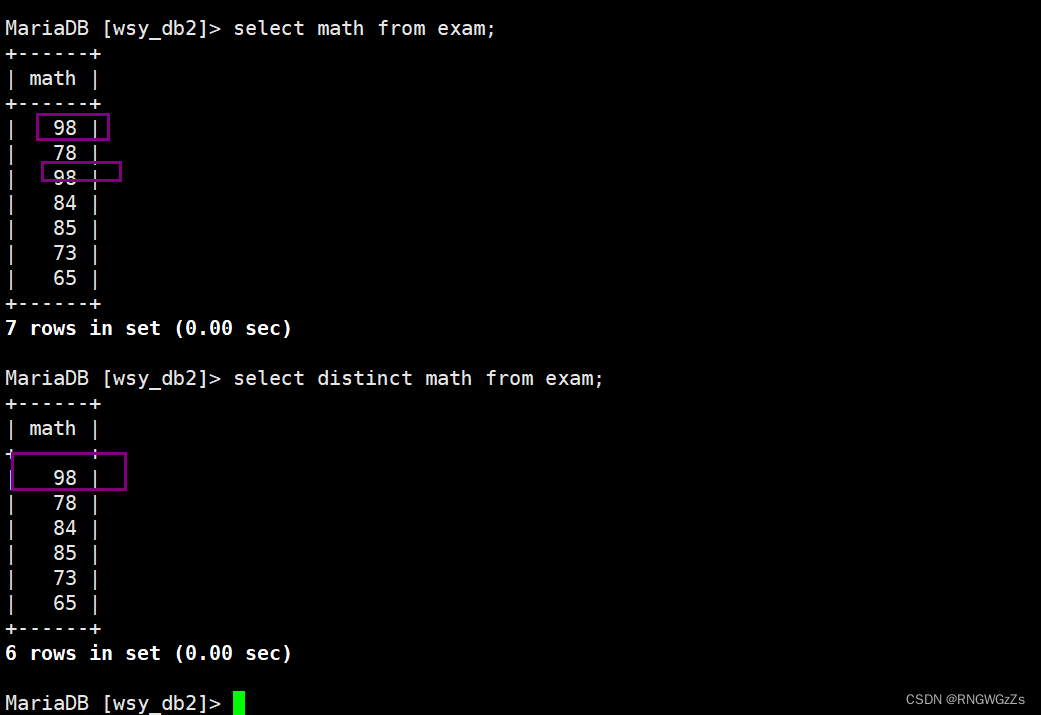
⑤Where条件筛选
比较运算符
运算符说明>, >=, <, <=大于,大于等于,小于,小于等于= 等于, NULL 不安全,例如 NULL = NULL 的结果是 NULL<=>等于, NULL 安全,例如 NULL <=> NULL 的结果是 TRUE(1)!=, <>不等于between a0 and a1范围匹配, [a0, a1] ,如果 a0 <= value <= a1 ,返回 TRUE(1)in (option, ...)如果是 option 中的任意一个,返回 TRUE(1)is null 是 NULLis not null 不是 NULL like 模糊匹配 % 表示任意多个(包括 0 个)任意字符; _ 表示任意一个字符运算符说明and 多个条件必须都为 TRUE(1)or 任意一个条件为 TRUE(1),not 条件为 TRUE(1),结果为flase英语不及格的同学及英语成绩 ( < 60 ) ;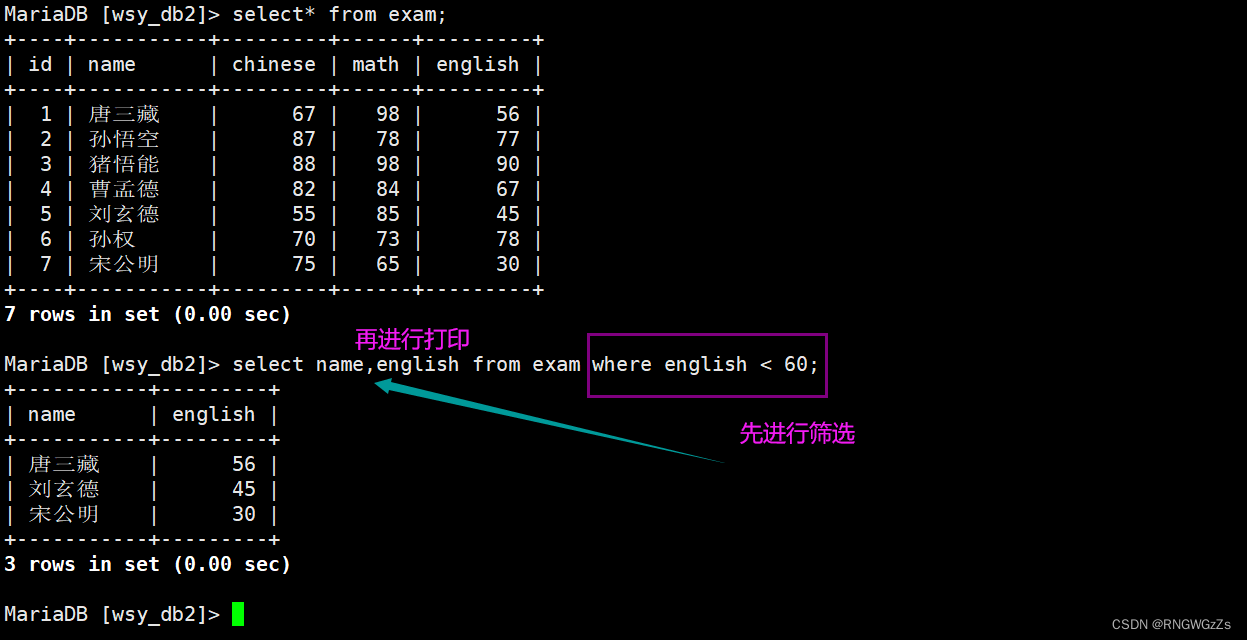
语文成绩在 [80, 90] 分的同学及语文成绩;
数学成绩是 58 或者 59 或者 98 或者 99 分的同学及数学成绩;

姓孙的同学 及 孙某同学;

语文成绩 > 80 并且不姓孙的同学;

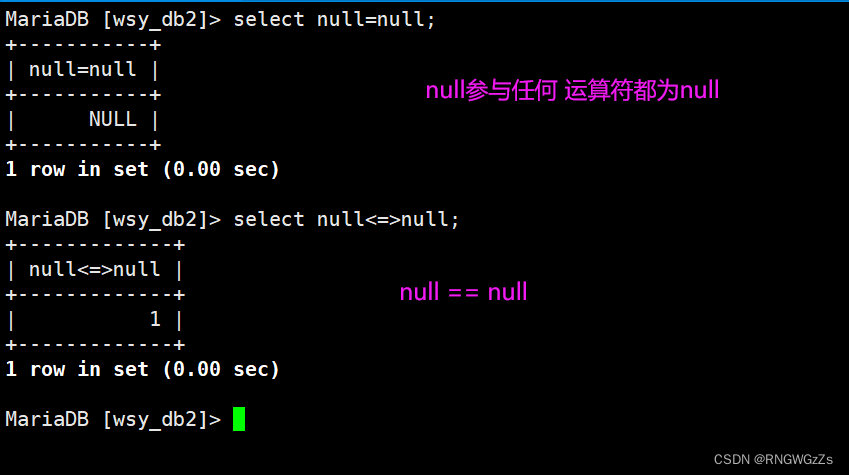
⑥null的查询

= 与 <=>区别
⑥结果排序
-- ASC 为升序(从小到大)-- DESC 为降序(从大到小)-- 默认为 ASCSELECT ... FROM table_name [WHERE ...]ORDER BY column [ASC|DESC], [...];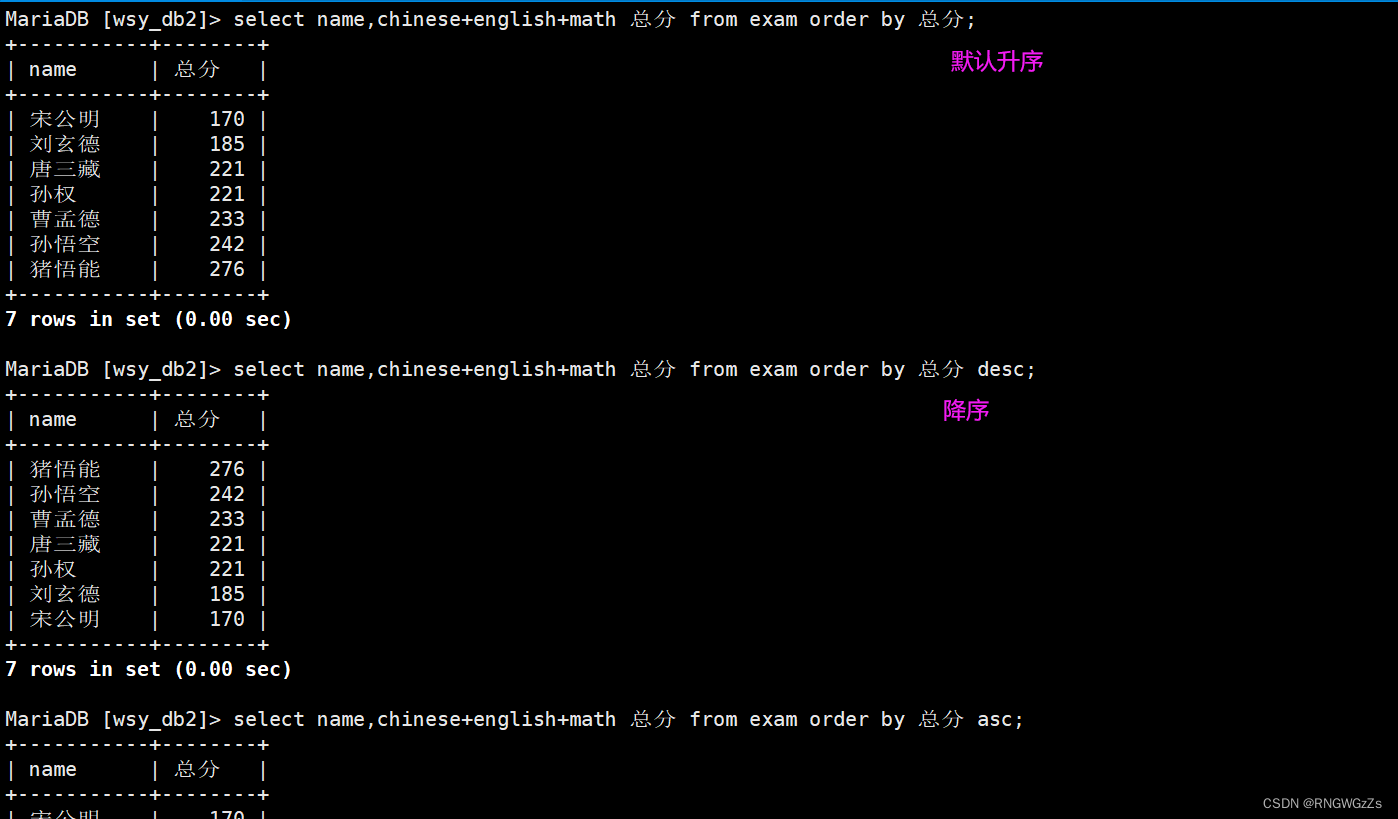
null 与 数值
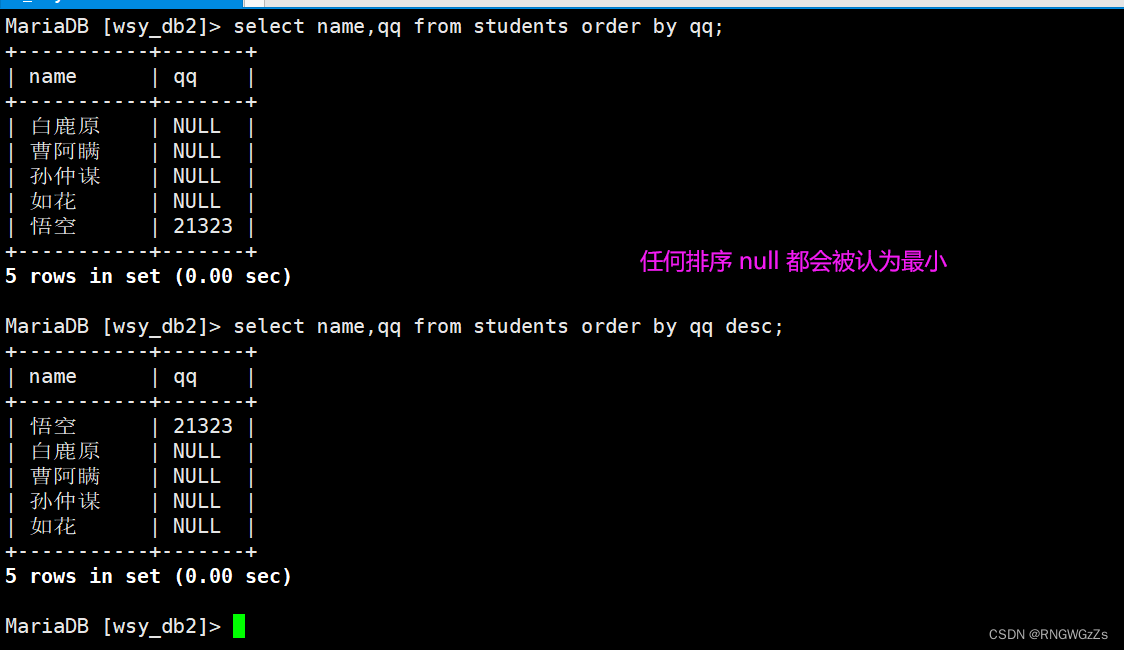
多组排序;

⑦筛选分页
当面对海量数据,但是我们只想取其中有限的n 个数据查询,避免数据库卡死。
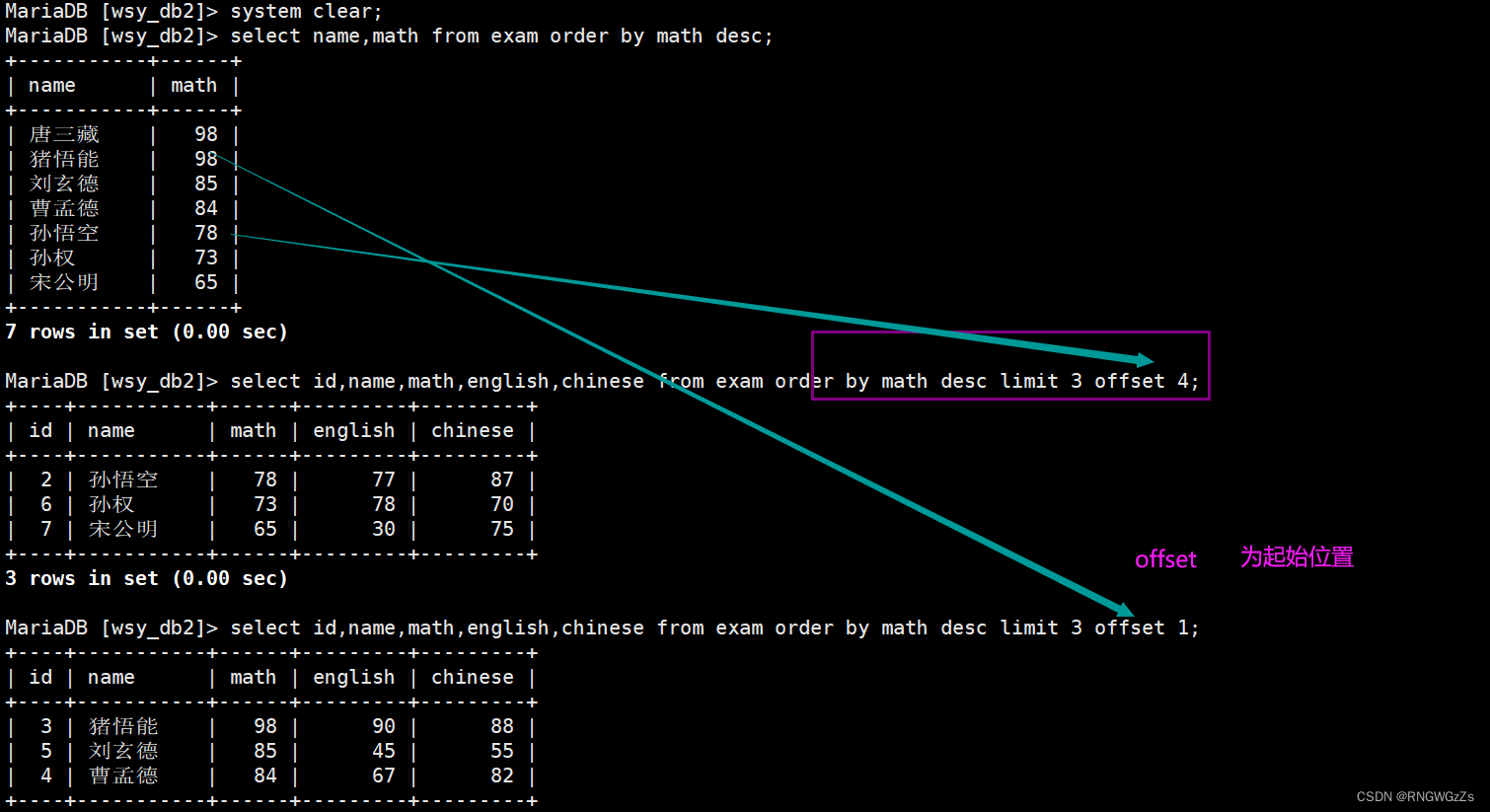
-- 从 0 开始,筛选 n 条结果SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n;-- 从 s 开始,筛选 n 条结果SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT s, n;-- 从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n OFFSET s;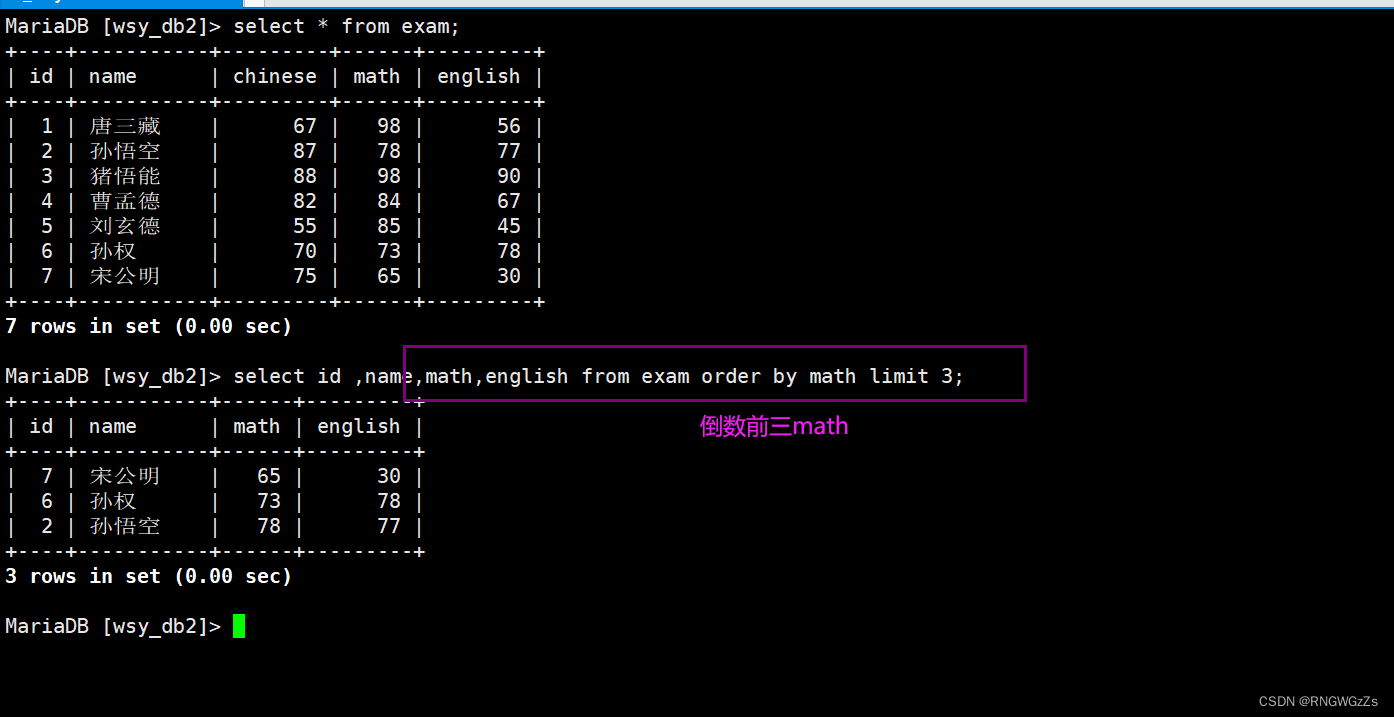
offset;
(3)Update
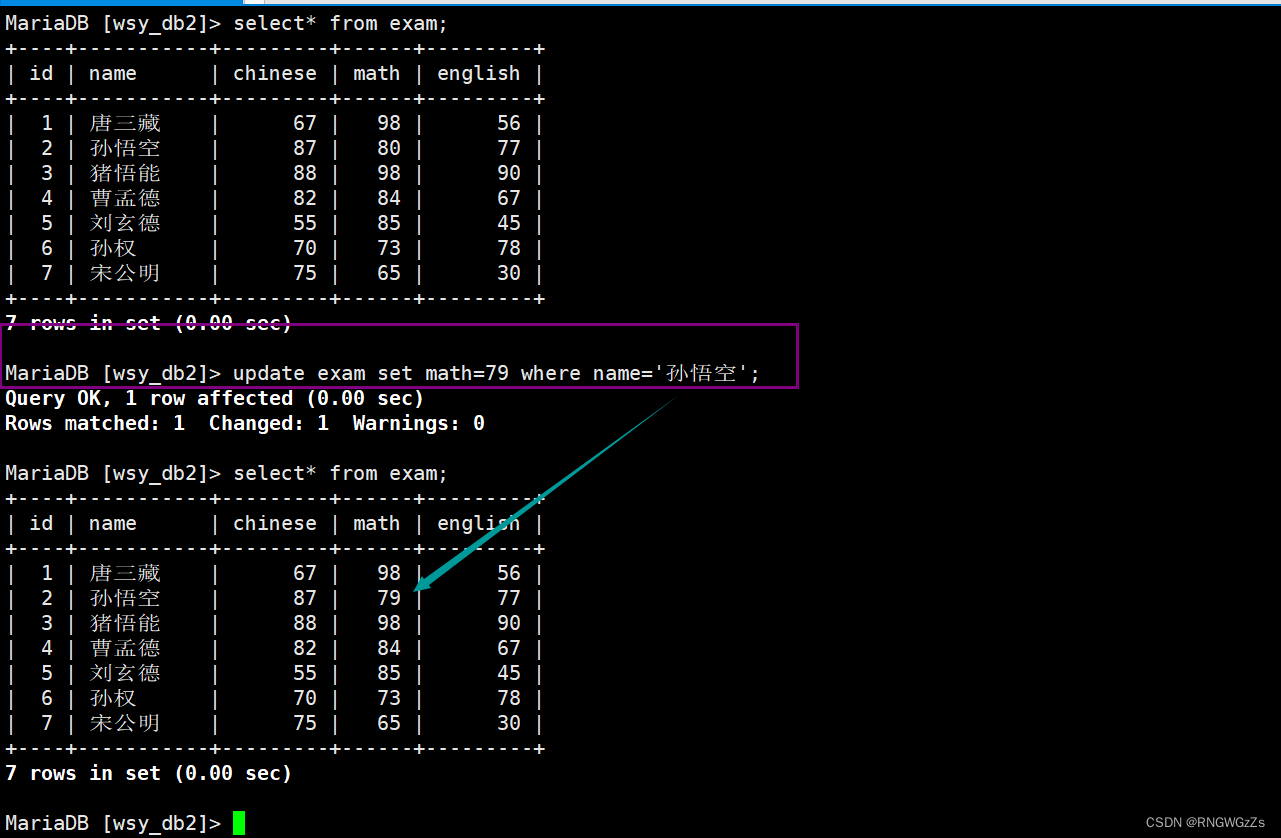
UPDATE table_name SET column = expr [, column = expr ...][WHERE ...] [ORDER BY ...] [LIMIT ...]将孙悟空同学的数学成绩变更为 80 分;
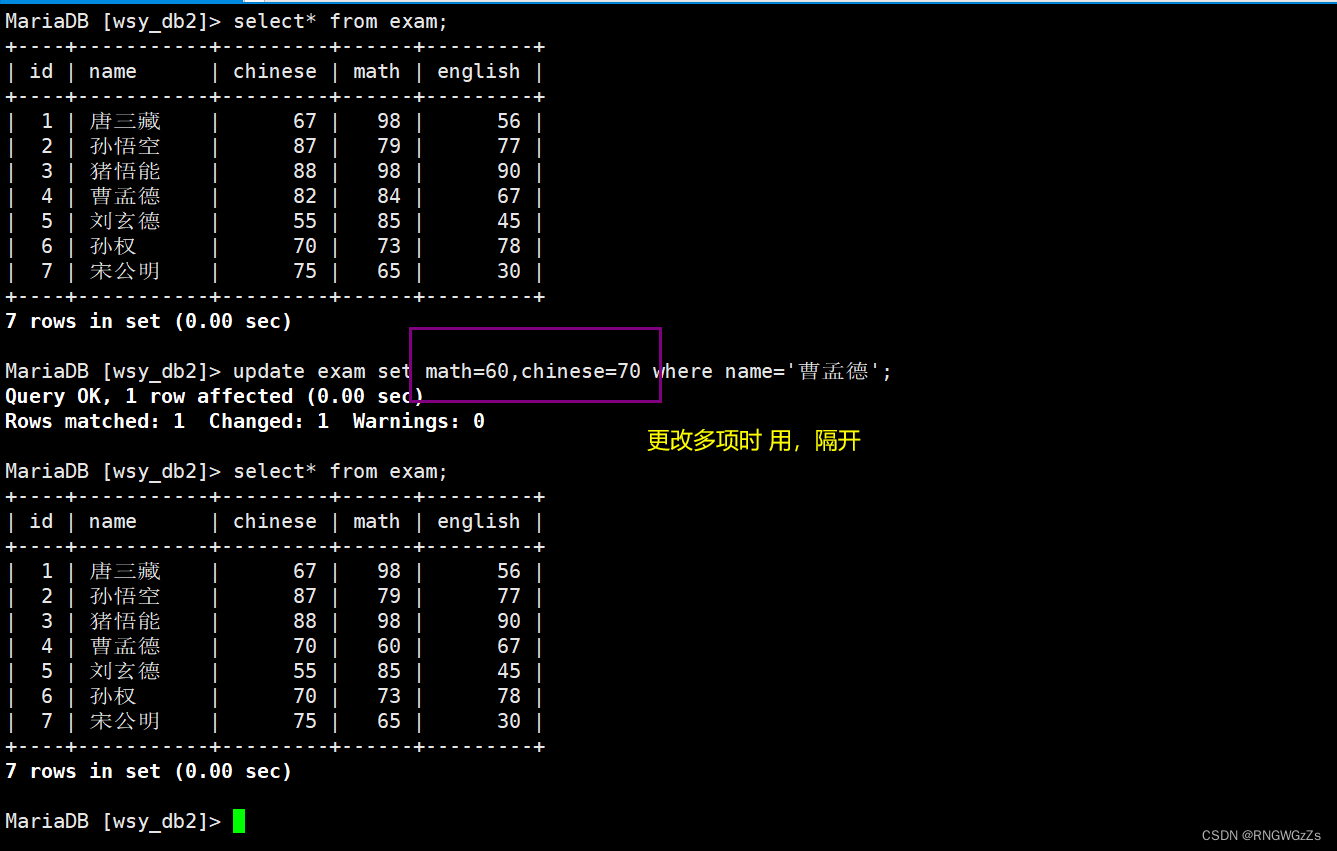
将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分;
将总成绩倒数前三的 3 位同学的数学成绩加上 30 分;

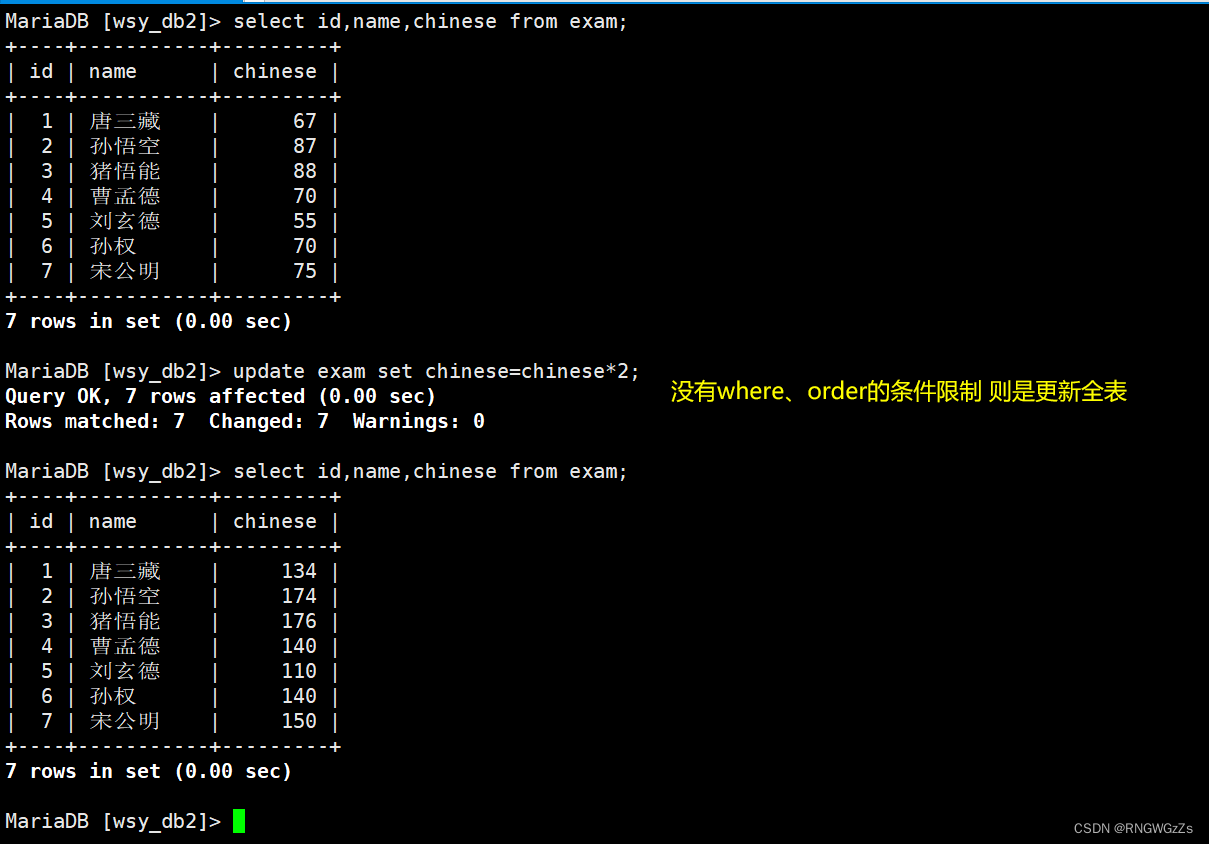
将所有同学的语文成绩更新为原来的 2 倍;
(4)Delete
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]
删除孙悟空同学的考试成绩;
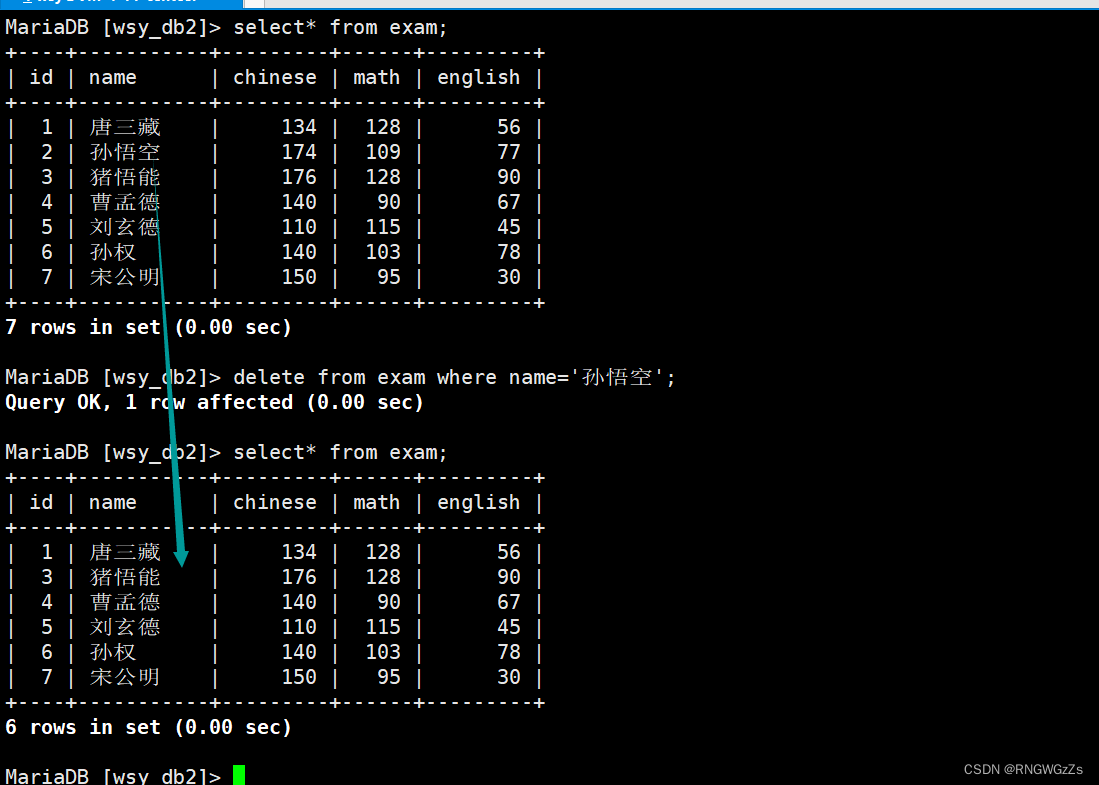
但值得注意和update一样,如果没有where条件 则是对整张表进行处理。
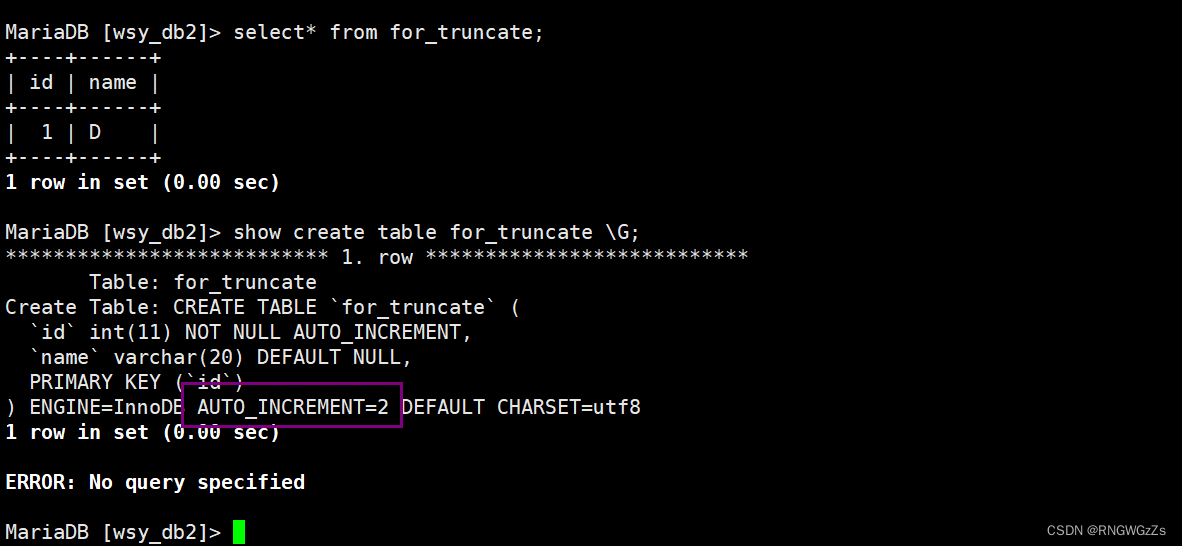
①截断表
TRUNCATE [TABLE] table_name注:1. 只能对整表操作,不能像 DELETE 一样针对部分数据操作;2. 实际上 MySQL 不对数据操作,所以比 DELETE 更快,但是 TRUNCATE 在删除数据的时候,并不经过真正的事物,所以无法回滚3. 会重置 AUTO_INCREMENT 项
清空auto_increment;
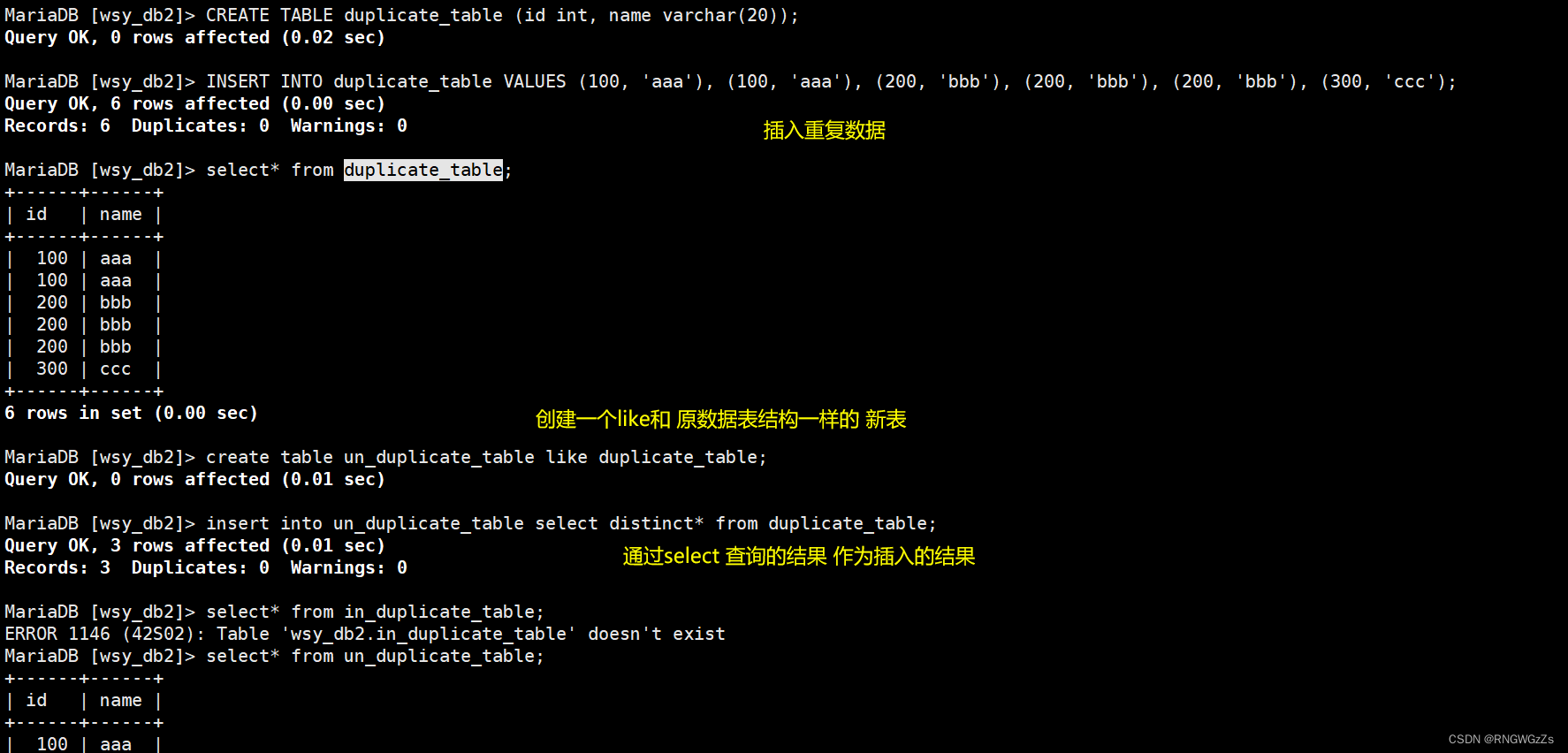
②插入 查询后的结果
对表中重复插入的数据去重;
(二)聚合函数
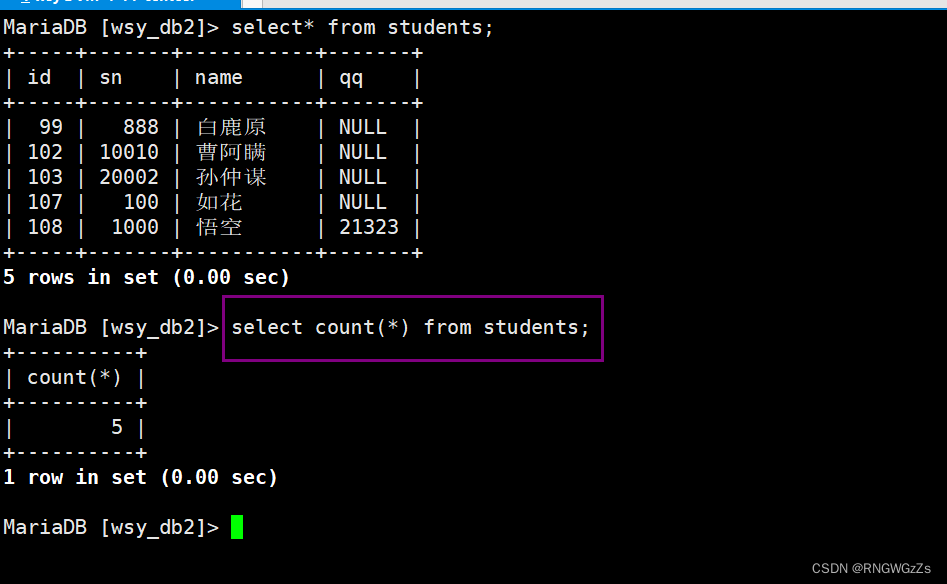
函数说明 COUNT([DISTINCT] expr)返回查询到的数据的 数量SUM([DISTINCT] expr)返回查询到的数据的 总和,不是数字没有意义AVG([DISTINCT] expr返回查询到的数据的 平均值,不是数字没有意义MAX([DISTINCT] expr)返回查询到的数据的 最大值,不是数字没有意义MIN([DISTINCT] expr)返回查询到的数据的 最大值,不是数字没有意义①count
统计班级共有多少同学;
统计班级收集的 qq 号有多少;

统计本次考试的数学成绩分数个数;

② AVG
统计平均总分;
统计数学平均分;

③max
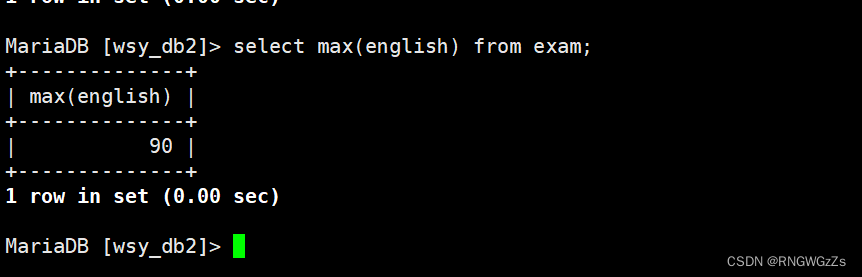
返回英语最高分;
④min
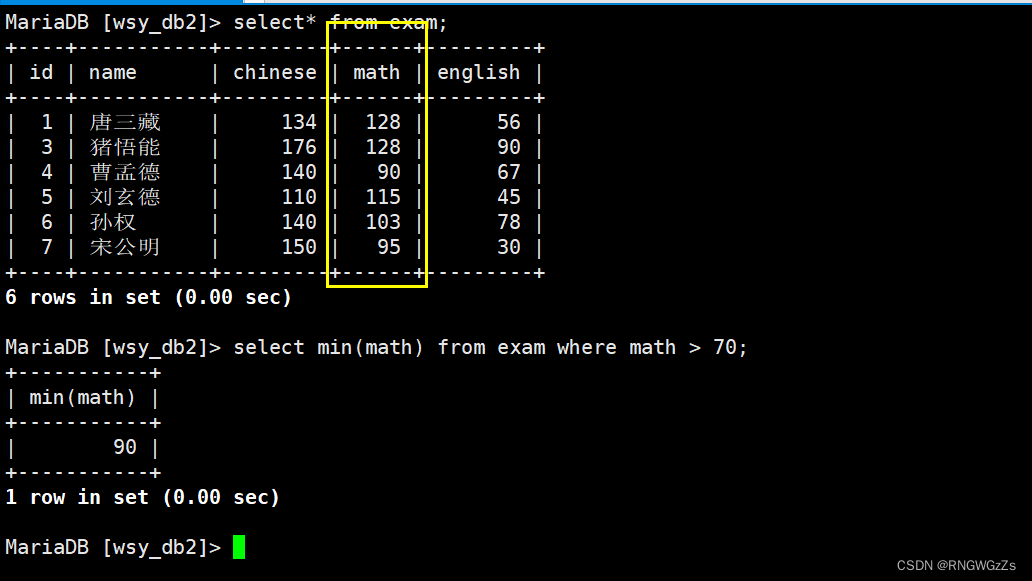
返回 > 70 分以上的数学最低分;
(三)基本查询
可以看出,前面的查询都是单逻辑、单表的 简单查询,数据量不大。
但面对复杂情况应该怎么处理呢?
①by groupe
在select中使用group by 子句可以对指定列进行分组查询
select column1, column2, .. from table group by column;
 传上来一个.sql文件。
传上来一个.sql文件。命令行:
source ./scott_data.sql
当前目录下直接执行.sql语句

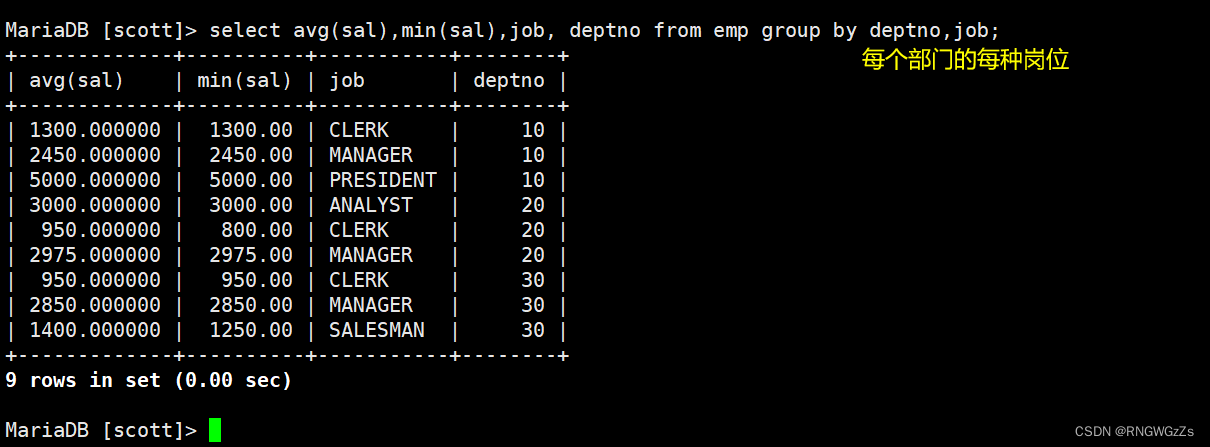
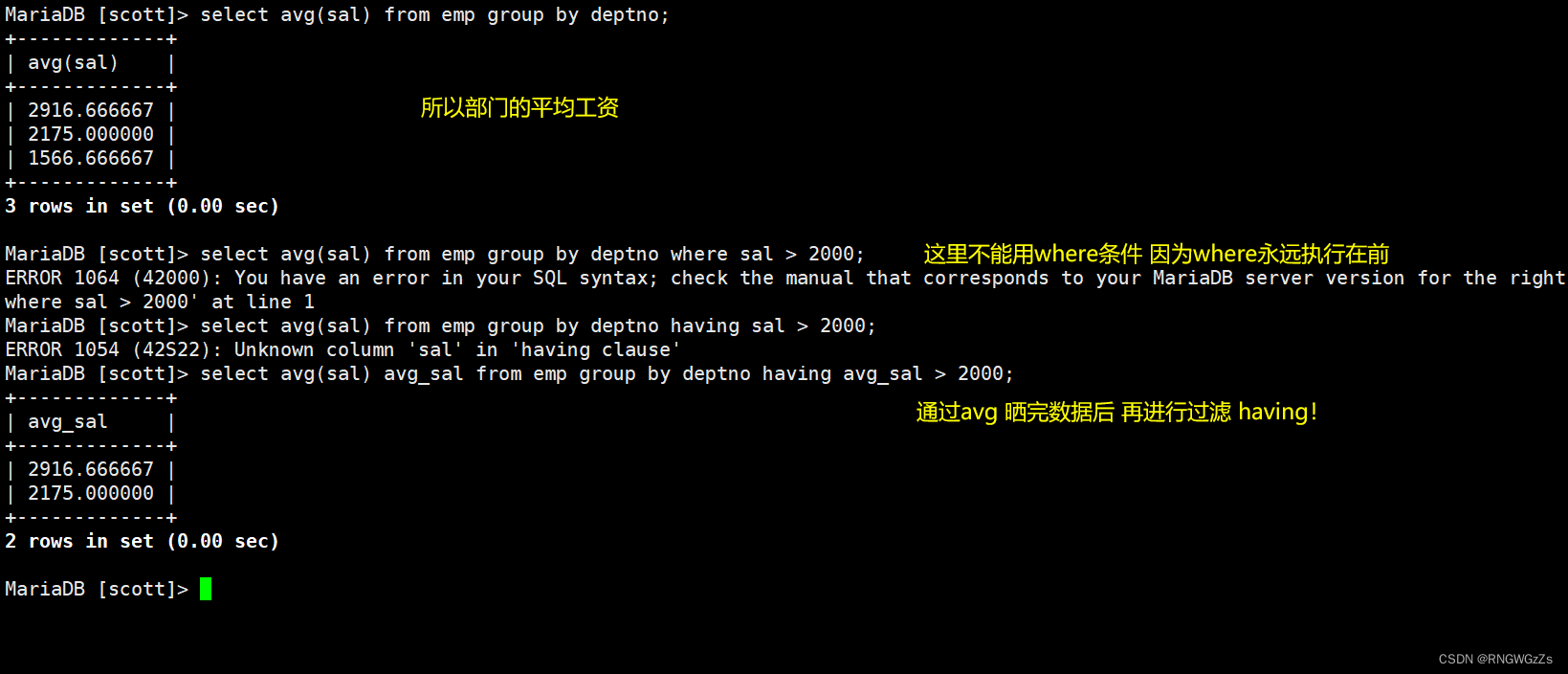
显示每个部门的每种岗位的平均工资和最低工资;
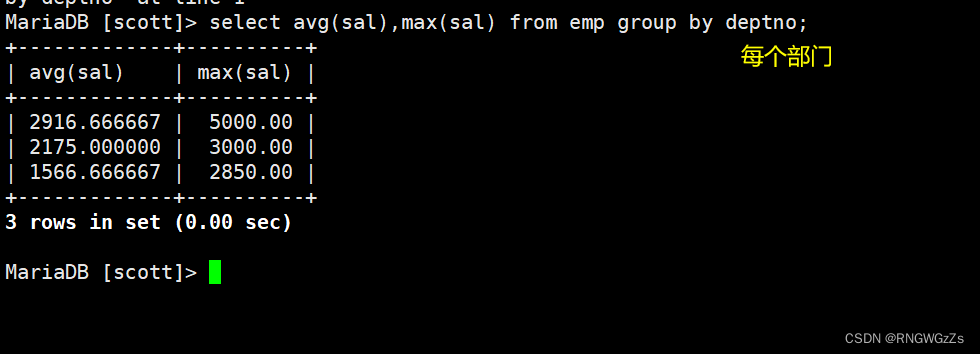
显示每个部门的平均工资和最高工资;
②having
显示平均工资低于2000的部门和它的平均工资;
(四)内置函数
(1)日期类
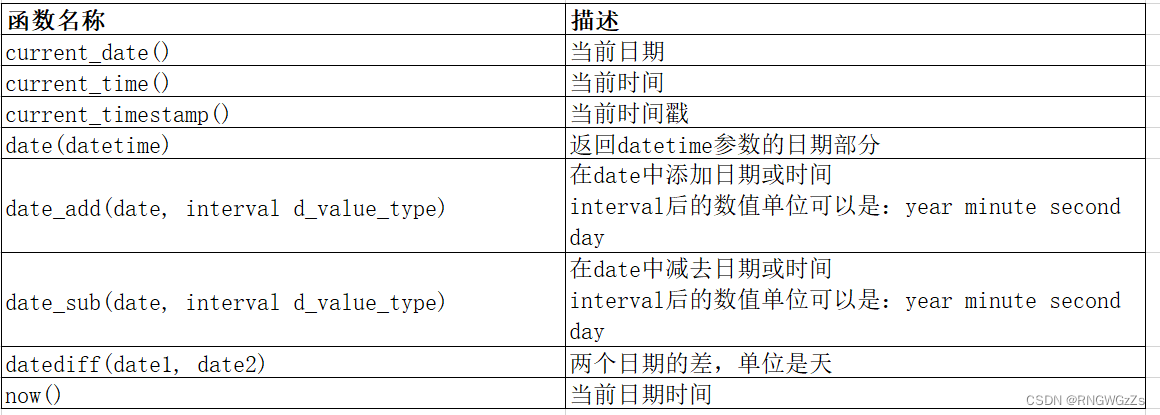
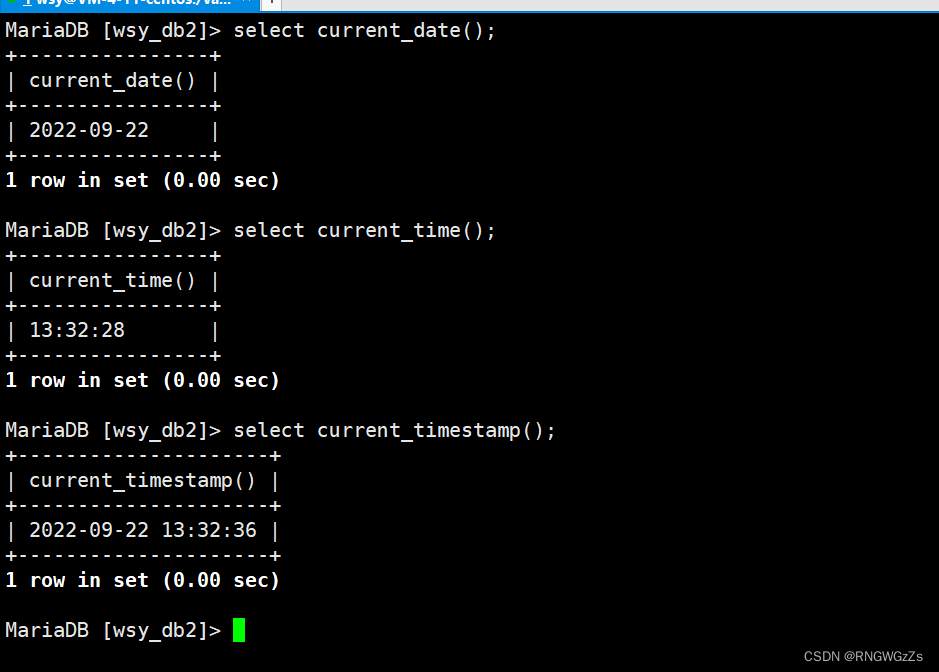
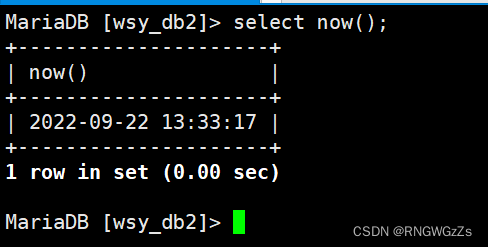
①日期之差
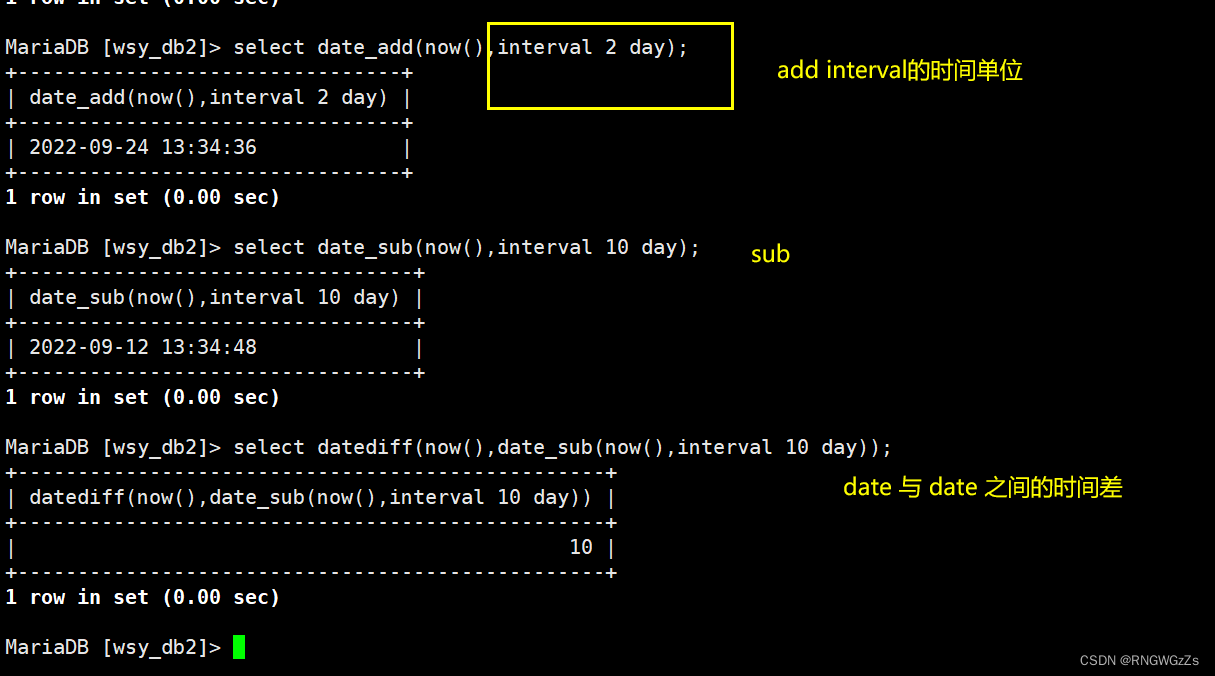
(2)字符串函数
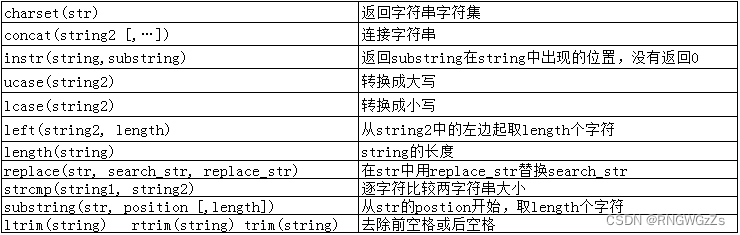
①charset字符集

②concat链接字符串

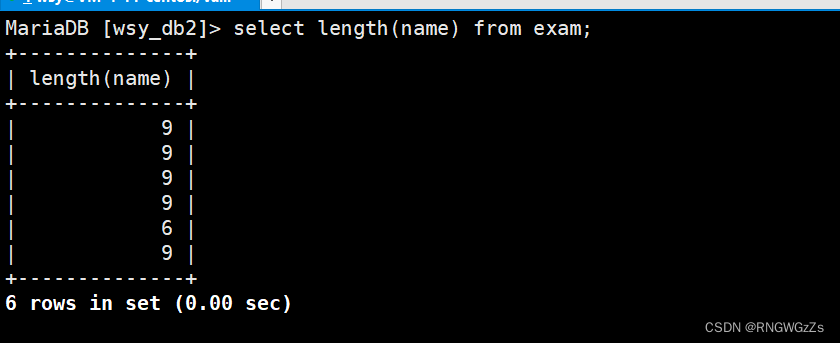
③length\字符串长度
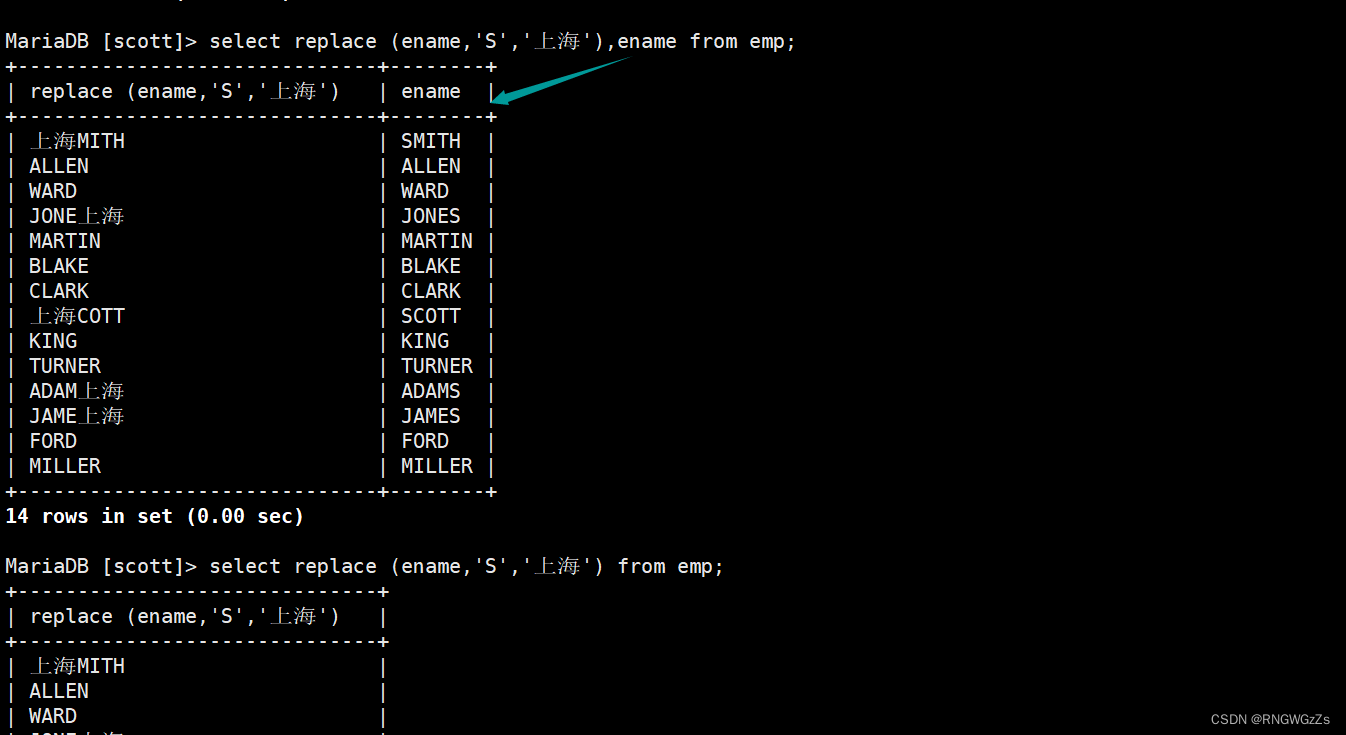
④replace
⑤大小写
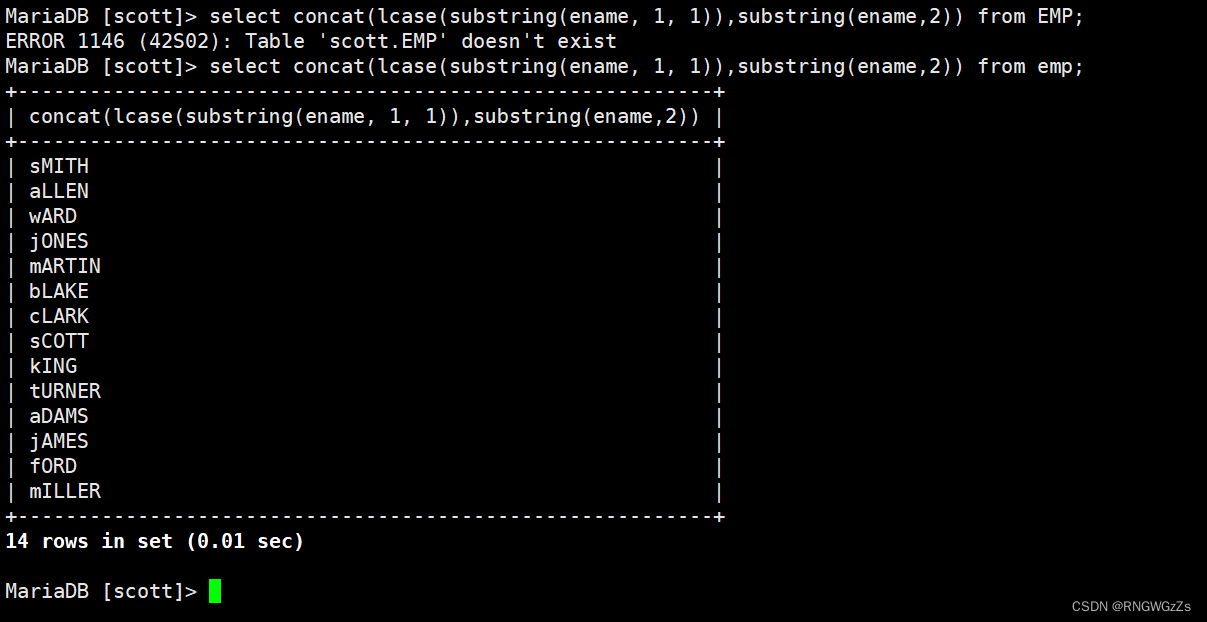
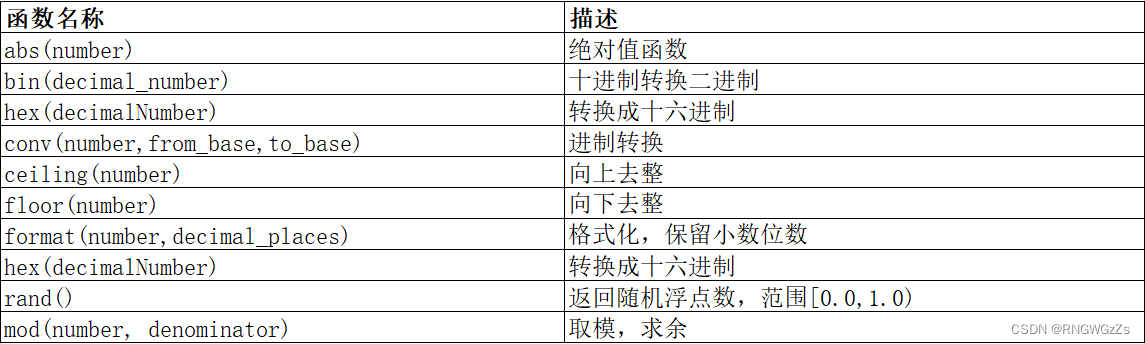
(3)数字类
select abs(-100.2);
select ceiling(23.04);
select floor(23.7);
select format(12.3456, 2);
select rand();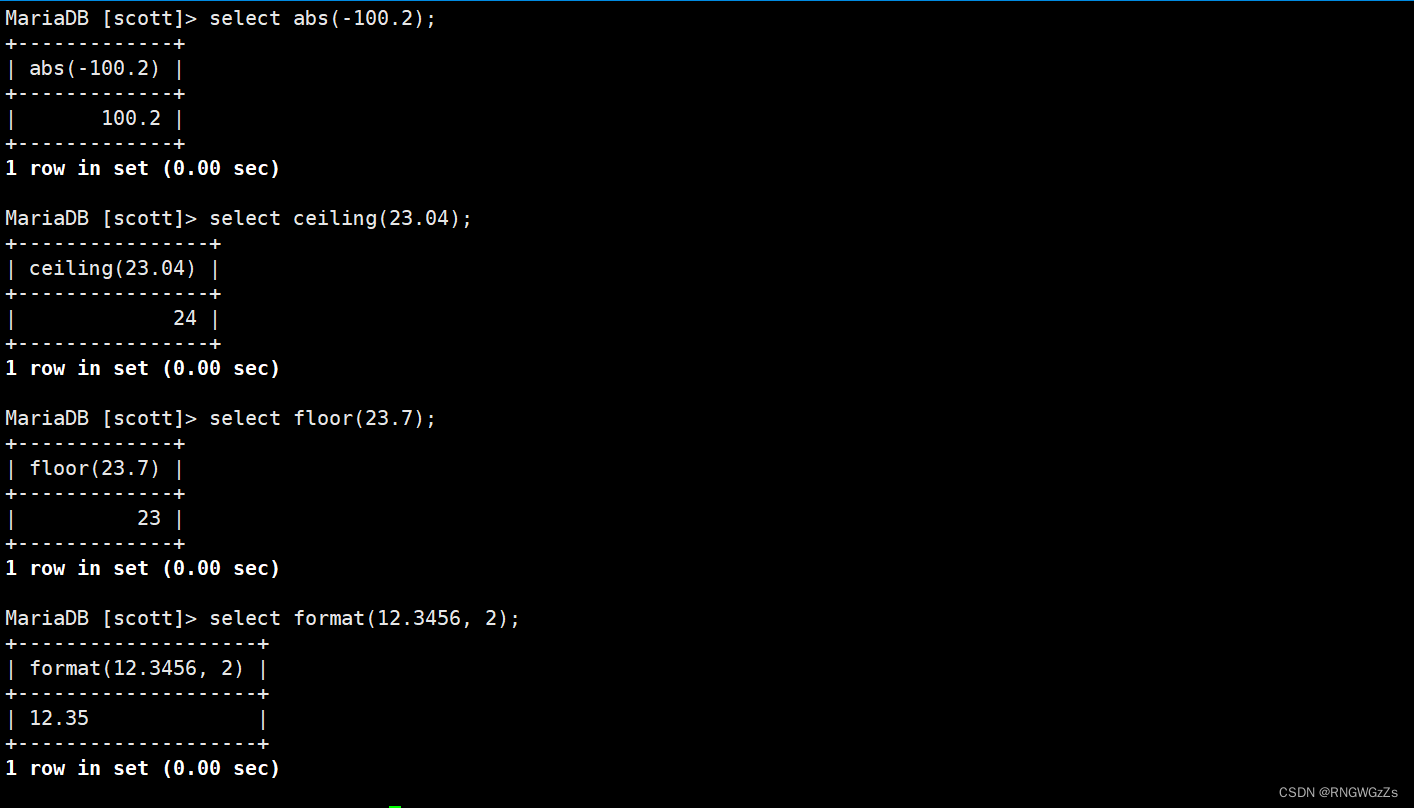
(4)其它函数
user() 查询当前用户
md5(str)对一个字符串进行md5摘要,摘要后得到一个32位字符串
database()显示当前正在使用的数据库
password()函数,MySQL数据库使用该函数对用户加密
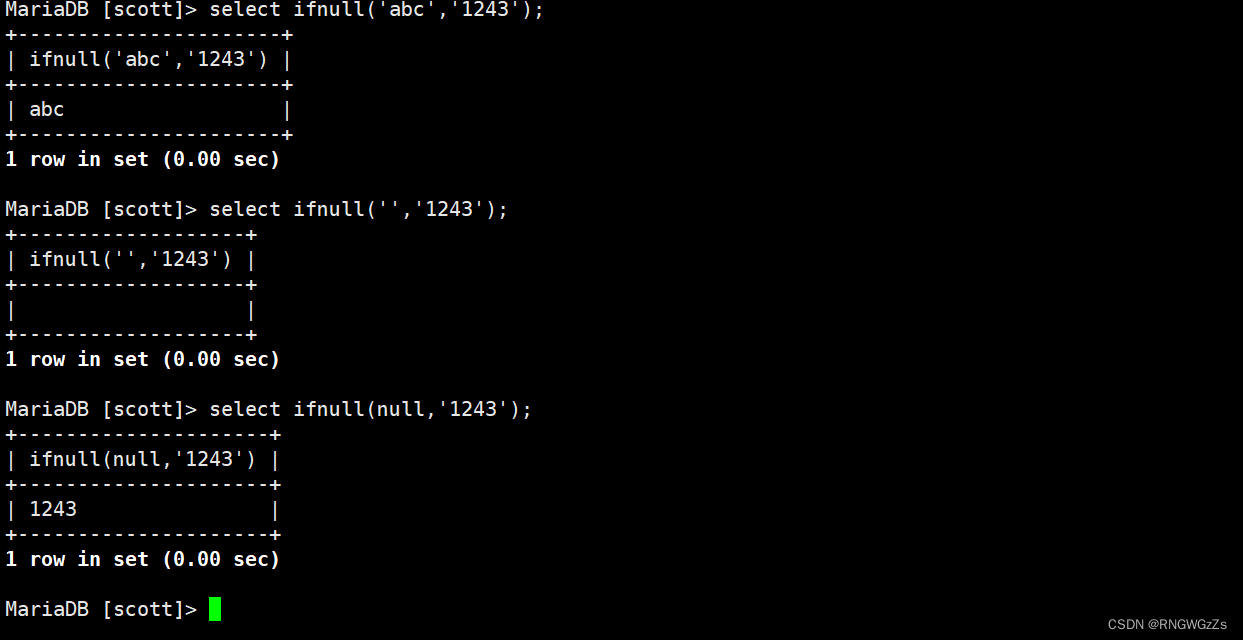
ifnull(val1, val2) 如果val1为null,返回val2,否则返回val1的值

ifnull;
(五)多表查询
实际开发中往往数据来自不同的表,所以需要多表查询。本节我们用一个简单的公司管理系统,有三张表EMP,DEPT,SALGRADE来演示如何进行多表查询。
①笛卡尔积
很多多表查询的方法,就是进行笛卡尔积合并、筛表实现。
select * from emp,deptno ; 实质是将两张表进行合并、并一 n*n 的排列组合 组成对应的集合


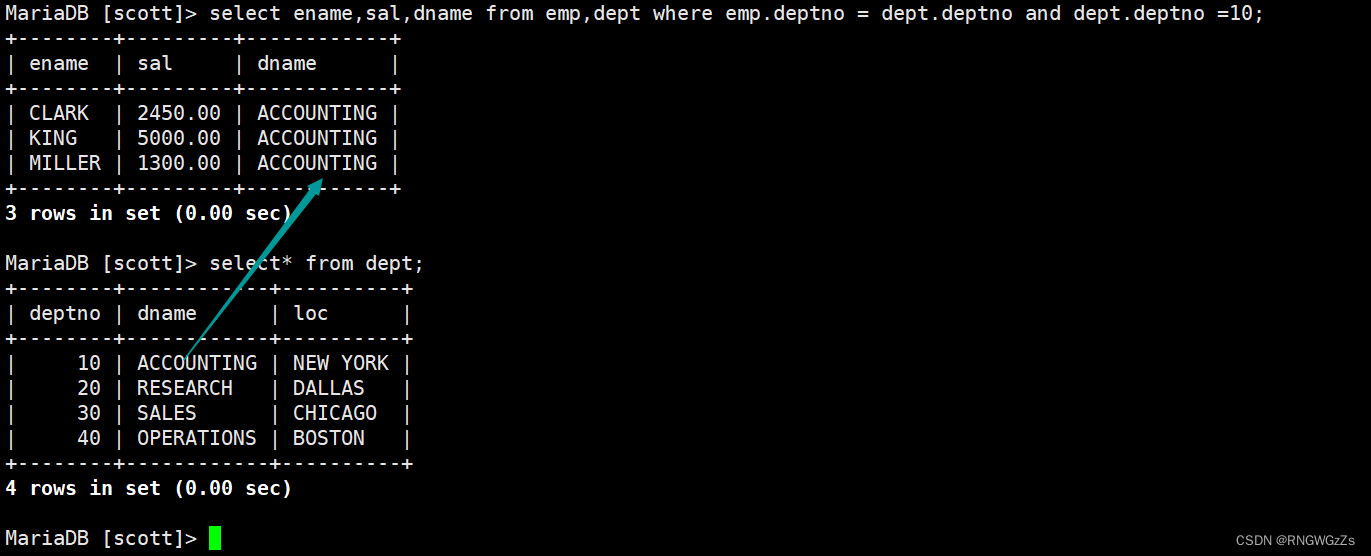
显示部门号为10的部门名,员工名和工资;
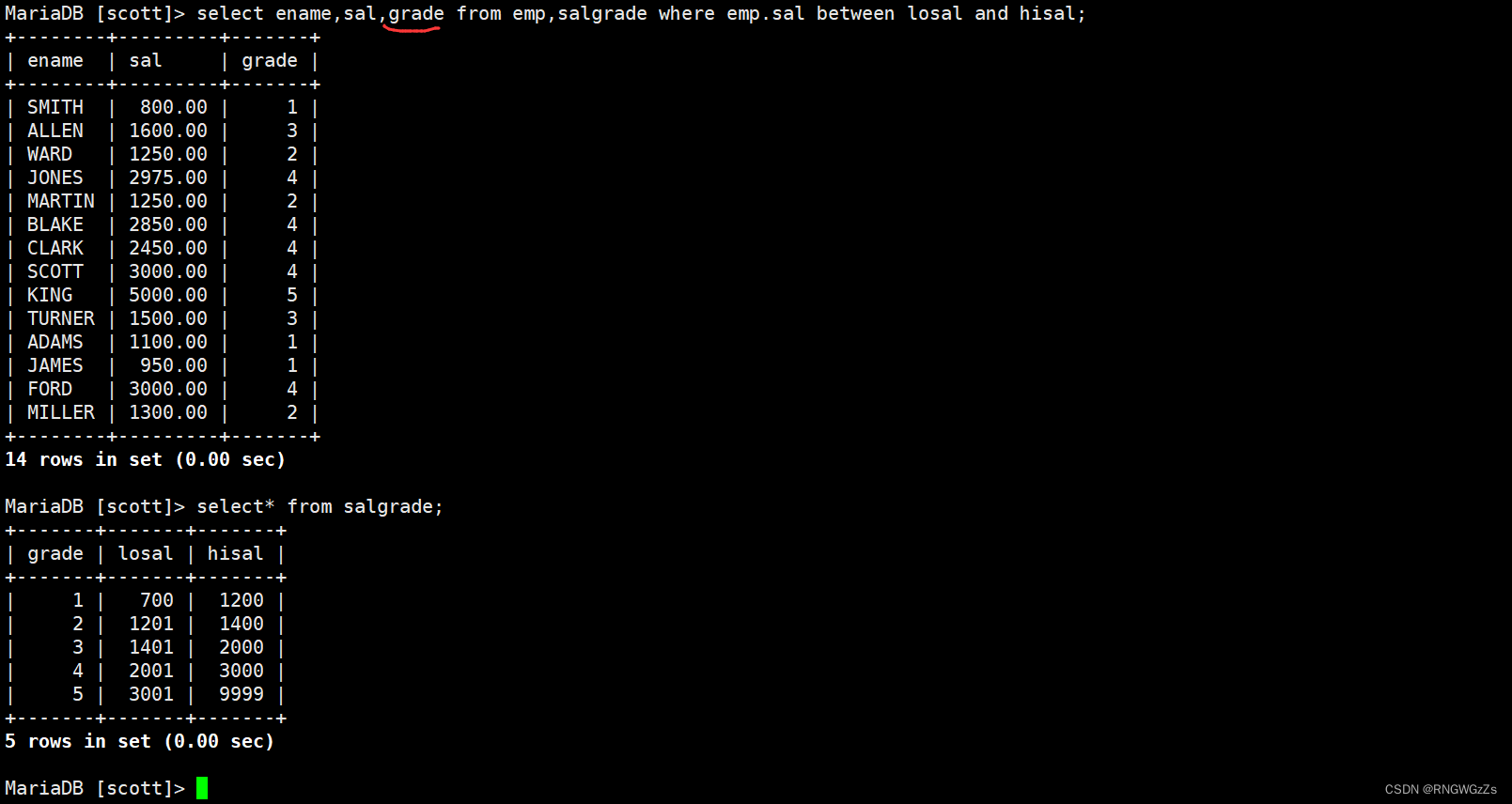
显示各个员工的姓名,工资,及工资级别;
②子查询
嵌套select作为另外一个select的条件。
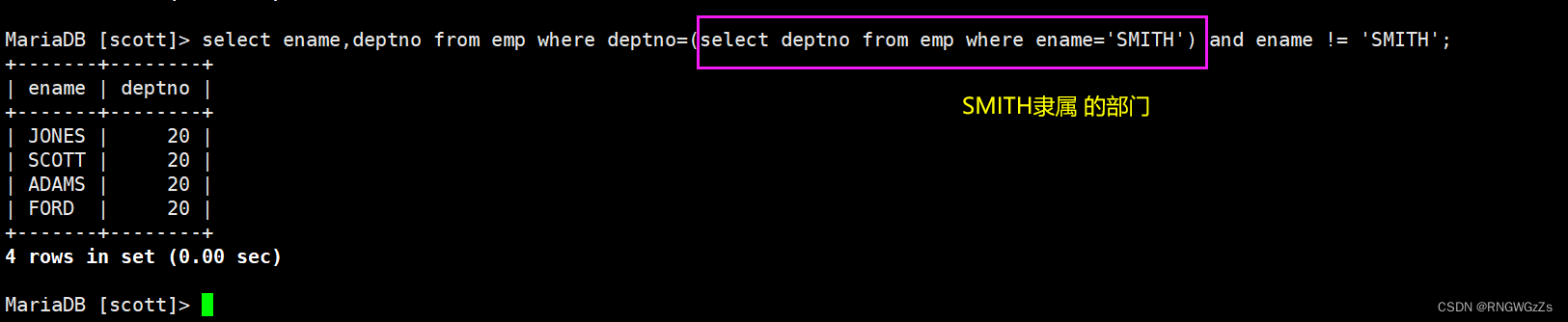
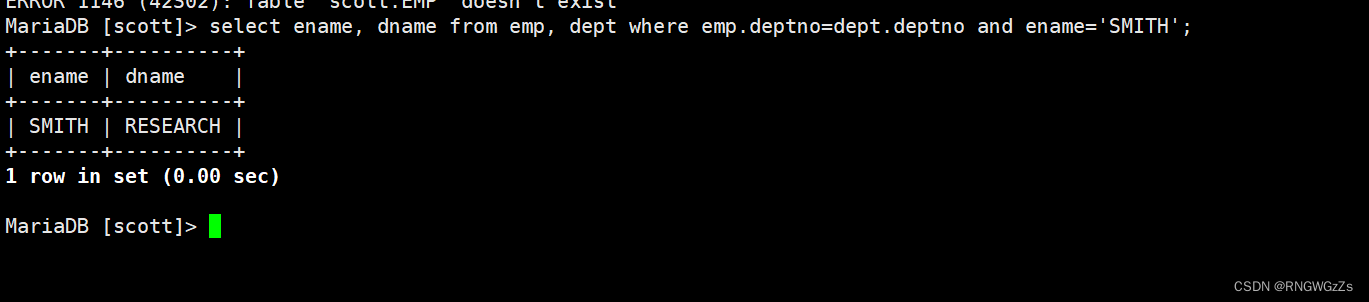
显示SMITH同一部门的员工;
③多行子查询
in \ all \ any 关键字 查找的不是一列
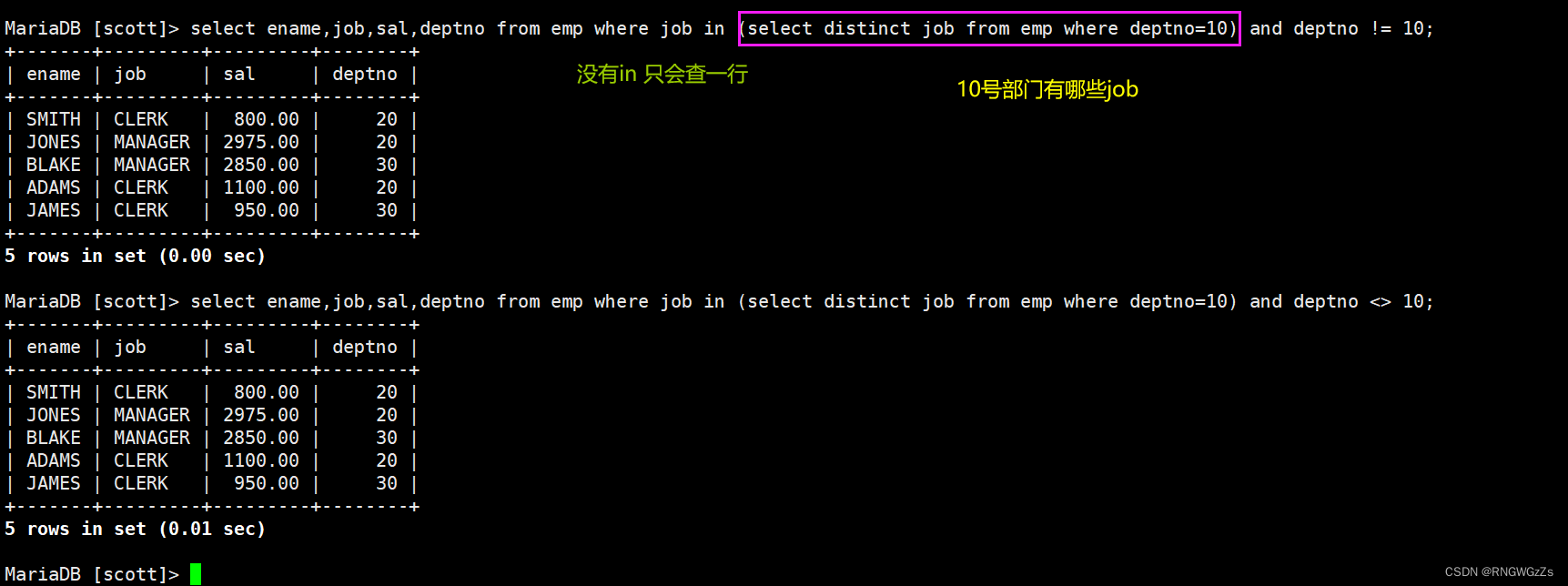
查询和10号部门的工作岗位相同的雇员的名字,岗位,工资,部门号,但是不包含10自己的;
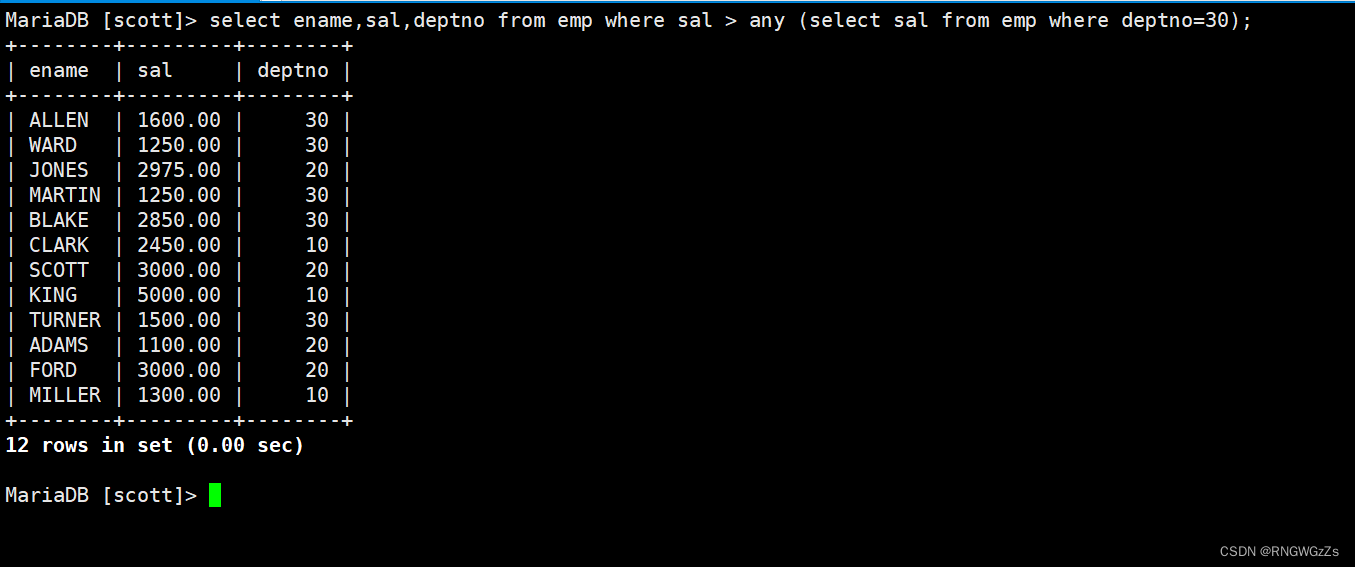
显示工资比部门30的所有员工的工资高的员工的姓名、工资和部门号;
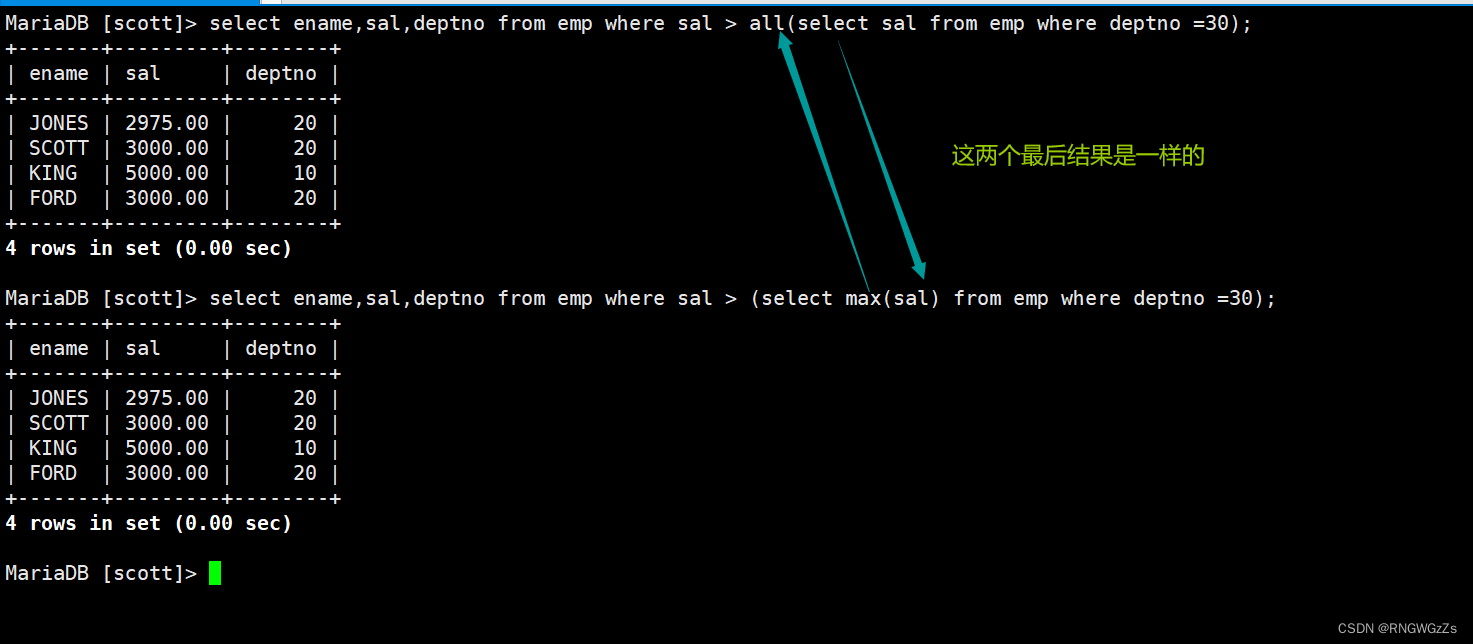
显示工资比部门30的任意员工的工资高的员工的姓名、工资和部门号(包含自己部门的员工)
④多列子查询
查询和SMITH的部门和岗位完全相同的所有雇员,不含SMITH本人;

⑤合并查询
在实际应用中,为了合并多个select的执行结果,可以使用集合操作符 union,union all
将工资大于2500或职位是MANAGER的人找出来;
union
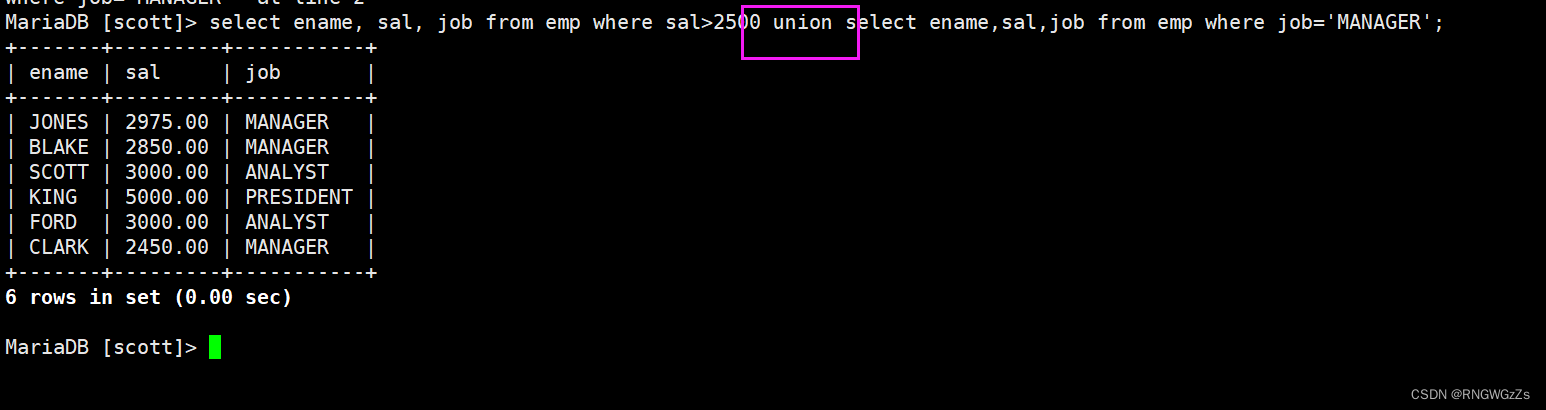
union all

(六)内外连接
(1)内连接
内连接实际上就是利用where子句对两种表形成的笛卡儿积进行筛选,我们前面学习的查询都是内连接,也是在开发过程中使用的最多的连接查询。
select 字段 from 表1 inner join 表2 on 连接条件 and 其他条件;
(2)外连接
外连接分为左外连接和右外连接
左侧的表完全显示我们就说是左外连接
右侧的表完全显示我们就说是右外连接左外连接

右外连接

总结
①数据库表的CURD: create update selet delete
②聚合函数count、sum、max、avg、min
③内置函数:日期时间类、字符串类、运算符类
④多表查询:笛卡尔积
⑤内外链接

-
相关阅读:
(Java)数据类型与变量
git使用说明
C++类型转换运算符
GoogleTest使用
opencv学习笔记九--背景建模+光流估计
nodejs+vue旅游推荐系统-计算机毕业设计
大数据之Maven+数据库连接池
【计算机网络】IP协议(下)
c#Nettonsoft.net库常用的方法json序列化反序列化
Python - Flask 实现自动登录
- 原文地址:https://blog.csdn.net/RNGWGzZs/article/details/126984969