-
高通camera之对camx架构的浅析
记录高通camera框架学习的笔记。
参考博客: 深入理解Android相机体系结构之六一、camx整体架构图
高通的camera历史也是比较长久的,从最开的的Qcamera架构,到之前的MM-camera架构,最后到现在主流的camx架构,都是一步一步完善的,因为目前用得最多得都是camx,所以这里就讲camx架构的东西。
camx架构在高通中主要分类两个目录 一个是camx目录 vendor/qcom/proprietary/camx 一个是chi目录 vendor/qcom/proprietary/chi-cdk
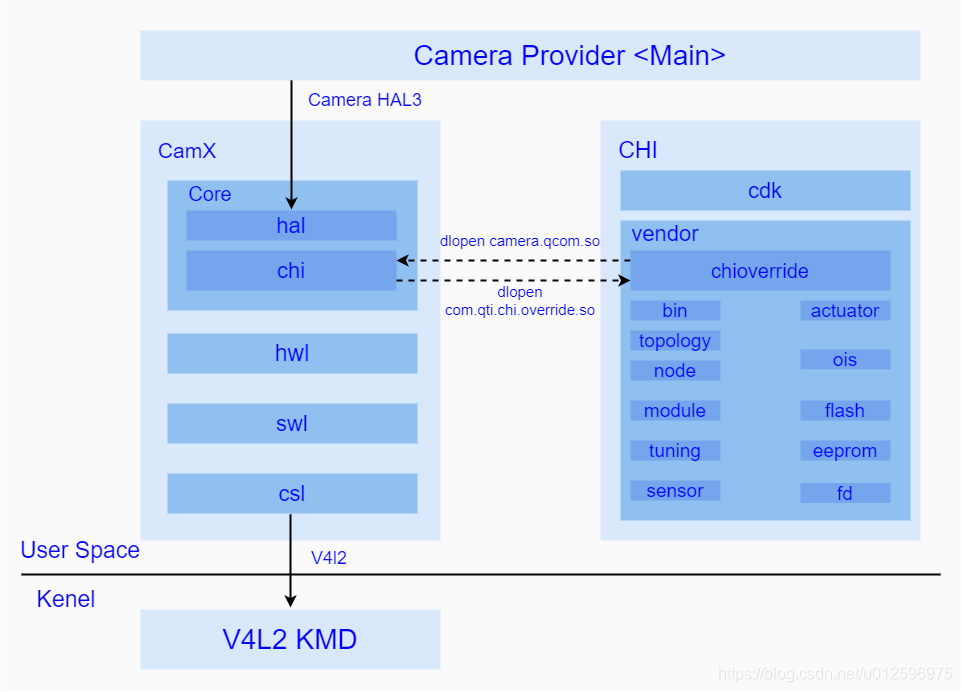
从上图也可以看出来camx是作为一个上下链接的桥梁,而chi是作为一个补充。
所以我们一般在chi目录会修改得比较多,因为这是完成定制化得一些目录。修改完过后,我们也可以直接 mmma 编译对应得目录会生成相应得库,我们直接替换就好二、对应得目录分析
2.1 camx目录分析
camx目录下主要存在几个主要得目录吧
core : 用于存放camx的核心实现模块,其中还包含了主要用于实现hal3接口的hal/目录,以及负责与CHI进行交互的chi/目录
csl : 用于存放主要负责camx与camera driver的通讯模块,为camx提供了统一的Camera driver控制接口
hwl : 用于存放自身具有独立运算能力的硬件node,该部分node受csl管理
swl : 用于存放自身并不具有独立运算能力,必须依靠CPU才能实现的node2.2 chi-cdk 目录分析
chioverride : 用于存放CHI实现的核心模块,负责与camx进行交互并且实现了CHI的总体框架以及具体的业务处理。
bin : 用于存放平台相关的配置项
topology : 用于存放用户自定的Usecase xml配置文件
node : 用于存放用户自定义功能的node
module : 用于存放不同sensor的配置文件,该部分在初始化sensor的时候需要用到
tuning : 用于存放不同场景下的效果参数的配置文件
sensor : 用于存放不同sensor的私有信息以及寄存器配置参数
actuator : 用于存放不同对焦模块的配置信息
ois : 用于存放防抖模块的配置信息
flash : 存放着闪光灯模块的配置信息
eeprom : 存放着eeprom外部存储模块的配置信息
fd : 存放了人脸识别模块的配置信息这里内容我们就暂时不分析,能力目前还不够,所以我们先放在这里,后续补上。
三、camx的各种组件
3.1 Usecase
就是用户空间的设置吧,因为我们在拍照或者拍视频的时候都会有不同的分辨率设置,所以我们可以将我们的设置称之为一个Usecase,比如我的拍照流选择 4096x4096, 视频流为1080x720,那么我们就可以吧这个视频流和这个拍照流共称为 Usecase。
UseCase在camx中很有很多衍生类,这是camx针对不同的stream来建立不同的usecase对象,用来管理选择feature,并且创建 pipeline以及session。vendor/qcom/proprietary/chi-cdk/vendor/chioverride/default/chxusecase.可以通过这个目录去查看对应的UseCase类图。
3.2 feature
代表一个特定的功能吧,比如我们的延时拍照ZSL,高动态范围HDR等等.
不同的feature回去匹配不同的pipeline和stream.
他和usecase的流程关系为:我们选择usecase后他会下发request请求,hal层会根据request去选择对应的feature。3.3 Node
Node作为单个具有独立处理功能的抽象模块,可以是硬件单元也可以是软件单元,关于Node的具体实现是CamX中的Node类来完成的,其中CamX-CHI中主要分为两个大类,一个是高通自己实现的Node包括硬件Node.
如下图,这里面展示很多的节点
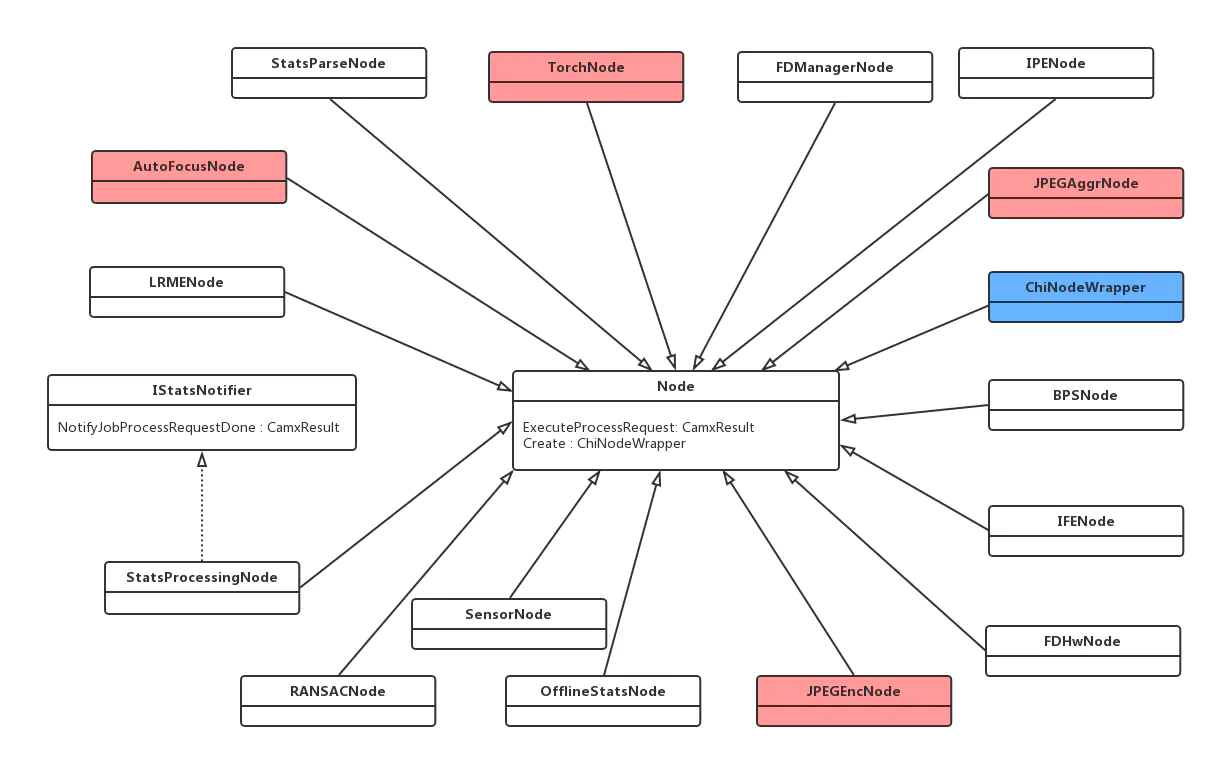
但是我自己目前用的比较多的还是IFE、IPE、BPS、SENSOR、JPEG这几个,其他的目前没有做了解。
IFE:图像前端
IPE:图像处理引擎
BPS:Bayer 处理区段
camx数据流向:
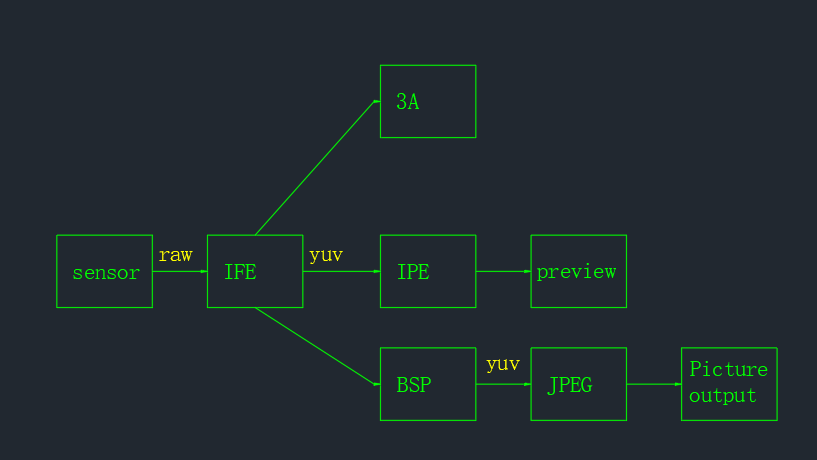
上图我们可以清晰的看到,Camera数据从sensor出来,首先会经过IFE,然后分预览/视频和拍照2种情况。如果是预览或者录像,是先经过IPE处理,最后输出到显示。如果是拍照,则是先经过BSP处理,然后再经过JPEG编码器,最后保存为图片输出
3.4 pipeline
一连串node的集合。pipeline提供单一特定功能的所有资源集合,维护着所有硬件资源以及数据的流转。
不同的usecase会选择不同的pipeline.3.5 session
若干个有关联的pipeline的集合,用于管理pipeline的抽象控制单元,其中至少包含一个pipeline,并控制着所有的硬件资源,管控着每个pipeline内部的request流转以及数据的输入输出。
3.6 Link
定义不同的Port的连接端口(输入端口和输出端口)。
一个Link中包含了一个SrcPort和一个DstPort,分别代表了输入端口和输出端口,然后BufferProperties用于表示两个端口之间的buffer配置3.7 Prot
作为Node的输入输出端口,使用SrcPort以及DstPort结构定义XML文件。
使用OutputPort以及InputPort结构体来进行在代码中定义。详情可以参考下面一片博客:
Camx 基本组件及其结构关系详解四、组件结构关系
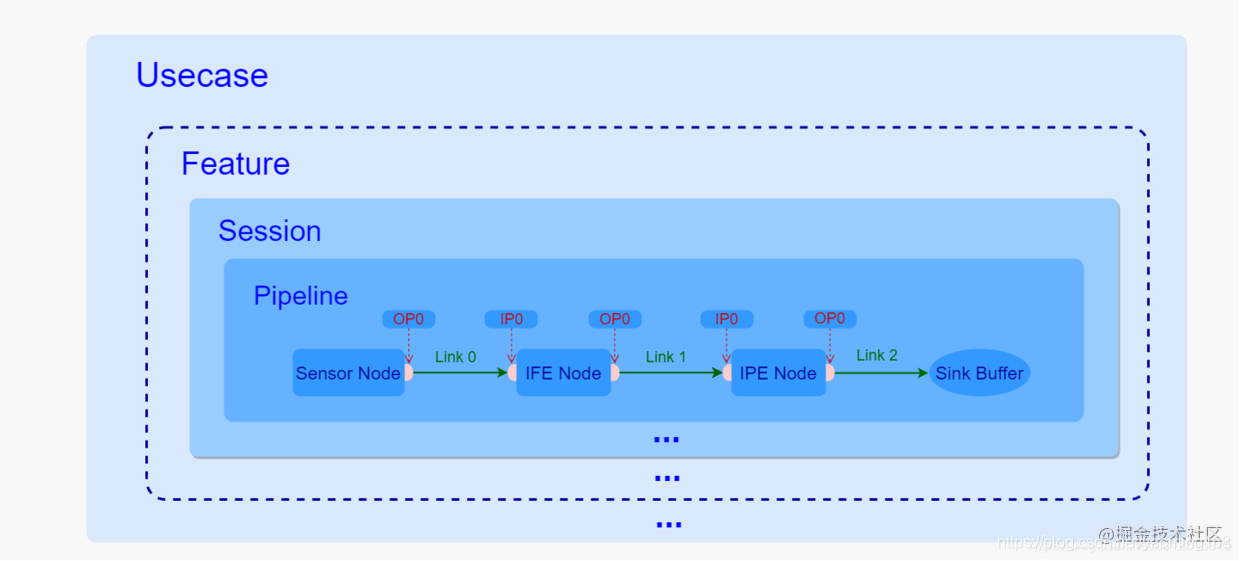
由图可知:Usecase 包含Feature,而Feature包含了Session,Session又维护了内部的Pipeline的流转,而每一条pipeline中又通过Link将所有Node都连接了起来。- 一个Usecase代表了某个特定的图像采集场景,比如人像场景,后置拍照场景等等,在初始化的时候通过根据上层传入的一些具体信息来进行创建,这个过程中,一方面实例化了特定的Usecase,这个实例是用来管理整个场景的所有资源,同时也负责了其中的业务处理逻辑,另一方面,获取了定义在XML中的特定Usecase,获取了用于实现某些特定功能的pipeline。
- 在Usecase中,Feature是一个可选项,如果当前用户选择了HDR模式或者需要在Zoom下进行拍照等特殊功能的话,在Usecase创建过程中,便会根据需要创建一个或者多个Feature,一般一个Feature对应着一个特定的功能,如果场景中并不需要任何特定的功能,则也完全可以不使用也不创建任何Feature。
- 每一个Usecase或者Feature都可以包含一个或者多个Session,每一个Session都是直接管理并负责了内部的Pipeline的数据流转,其中每一次的Request都是Usecase或者Featuret通过Session下发到内部的Pipeline进行处理,数据处理完成之后也是通过Session的方法将结果给到CHI中,之后是直接给到上层还是将数据封装下再次下发到另一个Session中进行后处理,这都交由CHI来决定。
- Session和Pipeline是一对多的关系,通常一个Session只包含了一条Pipeline,用于某个特定图像处理功能的实现,但是也不绝对,比如FeatureMFNR中包含的Session就包括了三条pipeline,又比如后置人像预览,也是用一个Session包含了两条分别用于主副双摄预览的Pipeline,主要是要看当前功能需要的pipeline数量以及它们之间是否存在一定关联。
- 根据上面关于Pipeline的定义,它内部包含了一定数量的Node,并且实现的功能越复杂,所包含的Node也就越多,同时Node之间的连接也就越错综复杂,比如后置人像预览虚化效果的实现就是将拿到的主副双摄的图像通过RTBOfflinePreview这一条Pipeline将两帧图像合成一帧具有虚化效果的图像,从而完成了虚化功能。
- Pipeline中的Node的连接方式是通过XML文件中的Link来进行描述的,每一个Link定义了一个输入端和输出端分别对应着不同Node上面的输入输出端口,通过这种方式就将其中的一个Node的输出端与另外一个Node的输入端,一个一个串联起来,等到图像数据从Pipeline的起始端开始输入的时候,便可以按照这种定义好的轨迹在一个一个Node之间进行流转,而在流转的过程中每经过一个Node都会在内部对数据进行处理,这样等到数据从起始端一直流转到最后一个Node的输出端的时候,数据就经过了很多次处理,这些处理效果最后叠加在一起便是该Pipeline所要实现的功能,比如降噪、虚化等等。
五、总结
其实就是参考前辈的笔记,配合自己的代码进行一些逻辑上整理,之所以要写下来是因为自己写一边会更加有记忆力。
-
相关阅读:
网络安全(黑客)自学
各国Web3现状与未来
【云原生】这么火,你不来了解下?
ActiveMQ-架构设计
DDD 架构分层,MQ消息要放到那一层处理?
springboot 发布tomcat(zip包)
Key Points Estimation and Point Instance
助听器不仅能帮你听到,还有另外一个功能……
mysql的索引分类B+和hash详解
忘记密码,如何解除Excel的限制保护?
- 原文地址:https://blog.csdn.net/weixin_51178981/article/details/126714490