-
损失函数笔记(2)--对比损失
- 一些常用与分类问题的损失函数:
- 交叉熵损失:
- 是分类问题中默认使用的损失函数
- 交叉熵函数:计算了类概率与标准答案的距离
- softamax:一般用作最后一层的激活函数,计算归一化的类概率。
- 交叉熵损失:
- 前置知识:
- 非参数样本分类:
- 每个权重向量事实上代表了每一类样本其特征值的模板
- 现有的分类问题实际是通过一系列深度网络提取特征,再依据大量的样本学习到有关每一类样本特征的模板,在测试阶段再将这个学到的特征模板去做比对。
- 所谓非参数样本分类,则是将每个计算出的样本特征作为模板,
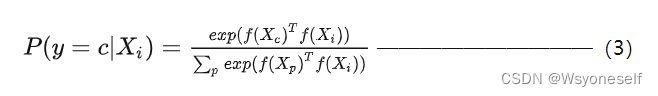
- 根据向量乘法:越相似的两个向量其内积越大。
- 非参数样本分类:
- 对比损失:
- 对比损失在非监督学习中应用广泛。
- 在对比学习框架下,通常以每个样本作为一个单独的语义类别,并且有如下假设:
- 同一样本做不同变换后不改变其语义类别
- 举例说明:假设对样本x,分别做不同变换A,B,对比损失希望A(x),B(x)之间的距离要小于A(x)和任意其他样本的距离
- 对比损失可视作添加了变换不确定性的非参数分类损失。
- 基本准则:
- 近似样本之间的距离越小越好
- 不似样本之间的距离如果小于m,则通过互斥使其距离接近m(m使得训练目标有了边界)
- 依据此准则,对比损失完全忽视了那些属于不同类,但两两距离天生大于m的样本对,大大减少了计算量。

- 一些常用与分类问题的损失函数:
-
相关阅读:
Mips架构安装mysql问题
Java必做实验4线程应用
JavaScript 浏览器对象模型BOM 概念
嵌入式分享合集57
期货开户寻找交易确定性
C++中的模板
MySQL 5.7安装教程(win11)
leetcode 1620. 网络信号最好的坐标
入职阿里必会199道SpringCloud面试题,你能掌握多少?
最全面的SpringMVC教程(二)——SpringMVC核心技术篇
- 原文地址:https://blog.csdn.net/weixin_45647721/article/details/126975131