-
YOLO系列目标检测算法-Scaled-YOLOv4
- YOLO系列目标检测算法总结对比- 文章链接
- YOLOv1- 文章链接
- YOLOv2- 文章链接
- YOLOv3- 文章链接
- YOLOv4- 文章链接
- Scaled-YOLOv4- 文章链接
- YOLOv5- 文章链接
- YOLOv6- 文章链接
- YOLOv7- 文章链接
- PP-YOLO- 文章链接
- PP-YOLOv2- 文章链接
- YOLOR- 文章链接
- YOLOS- 文章链接
- YOLOX- 文章链接
- PP-YOLOE- 文章链接
本文总结:
- 提出一种网络缩放方法,使得基于CSP的YOLOv4可以上下伸缩,以适用于大型/小型网络;
- 将CSP应用到各式CNN中,可以减少参数和计算量,提高准确性,减少推理时间,因此CSP化了Backbone、neck和SPP;
- 分别分析了对于低端设备和高端设备对模型缩放的研究;
- 对于小型模型,限制计算复杂度小于O(whkb^2),选择使用OSANet,并CSP化,得到CSPOSANet;最小化/平衡特征图的大小,在CSPOSANet的计算块之间执行梯度截断,并将它们分割为通道数相等的两条路径;当Cin=Cout时的内存访问成本MAC最小,所以卷积前后保持相同的通道数;
- 对于大型模型,能更好地预测物体大小的能力基本上取决于特征向量的感受野,与感受野最直接相关的是stage,分析多个因素对感受野的影响后得出,{ s i z e i n p u t size^{input} sizeinput,#stage}的组合效果最好。因此,在执行缩放时,首先对 s i z e i n p u t size^{input} sizeinput、#stage执行复合缩放,然后根据实时要求,分别对深度和宽度执行缩放;将一个完全CSP化的YOLOv4-P5,通过缩放,并将其扩展到YOLOv4-P6和YOLOv4-P7;
专栏链接:
https://blog.csdn.net/qq_39707285/article/details/124005405
此专栏主要总结深度学习中的知识点,从各大数据集比赛开始,介绍历年冠军算法;同时总结深度学习中重要的知识点,包括损失函数、优化器、各种经典算法、各种算法的优化策略Bag of Freebies (BoF)等。
6. YOLO系列目标检测算法-Scaled-YOLOv4
6.1 简介
本文研究表明, 基于CSP方法的YOLOv4目标检测神经网络可以上下伸缩,适用于小型和大型网络,同时保持最佳速度和精度。本文提出了一种 网络缩放方法,不仅仅是修改网络的深度、宽度、分辨率,还修改网络结构。
神经网络算法的计算设备可能是云计算设备、通用GPU、物联网集群或单个嵌入式设备。为了设计有效的目标检测器,模型缩放技术是非常重要的,因为它可以使目标检测器对各种类型的设备实现高精度和实时推理。
最常见的模型缩放技术是改变Backbone的深度(CNN中卷积层的数量)和宽度(卷积层中卷积滤波器的数量),然后训练适合不同设备的CNN。EfficientNet-B0中使用NAS技术执行复合缩放,包括宽度、深度和分辨率的处理,他们使用这个初始网络,并限定计算量,开始搜索最佳CNN的网络结构,并将其设置为EfficientNet-B1,然后使用线性放大技术获得EfficientNetB2-EfficitentNet-B7的体系结构。
RegNet中总结并添加了来自广阔参数搜索空间AnyNet的约束,他们发现CNN的最佳深度约为60,还发现当瓶颈比设置为1,cross-stage宽度增加率设置为2.5时,会获得最佳性能。
其他多种轻量级神经网络算法详见系列文章《轻量级神经网络算法》。通过对各种目标检测算法的分析后发现,作为YOLOv4的Backbone的 CSPDarknet53几乎与通过网络架构搜索技术获得的所有优化过的架构特征相匹配。CSPDarknet53的深度、瓶颈比、stage间宽度增长率分别为65、1和2。因此,本文基于YOLOv4开发了 模型缩放技术,并提出了 scaled-YOLOv 4。如图1所示,提出的的scaled-YOLOv4具有出色的性能。

scaled-YOLOv4的设计过程如下。首先,重新设计了YOLOv4并提出了YOLOv4 CSP,然后基于YOLOv 4 CSP开发了scaled-YOLOv4。在提出的scaled-YOLOv4中,讨论了线性扩大/缩小模型的上下界,并分别分析了小模型和大模型缩放时需要注意的问题。因此,能够系统地开发YOLOv4大型和YOLOv小型模型。本文主要贡献总结如下:
(1)针对小模型设计了一种强大的模型缩放方法,可以系统地平衡浅层CNN的计算开销和存储带宽;
(2)设计一种简单而有效的策略来扩大大型目标探测器;
(3)分析所有模型缩放因子之间的关系,然后基于最有利的组划分执行模型缩放;
(4)实验证实,FPN结构本质上是一种一劳永逸(once-for-all )的结构;
利用上述方法开发了YOLOv4-tiny和YOLOv4-large。6.2 模型缩放原理
在对目标检测器执行模型缩放后,下一步是处理将发生变化的定量因素,包括带有定性因素的参数数量。这些因素包括模型推理时间、平均精度等。定性因素将根据所使用的设备或数据库产生不同的增益效应。将在第1小节中分析和设计定量因素。在第2、3小节中,将分别设计在低端设备和高端GPU上的目标检测器相关的定性因素。
6.2.1 模型缩放的一般原理
在设计有效的模型缩放方法时, 主要原则是,当缩放比例增大/减小时,我们希望增加/减少的量化成本越低/越高,效果越好。
在本节中,将展示和分析各种通用CNN模型,并试图了解它们在1)图像大小、2)层数和3)通道数变化时的量化成本。选择的CNN有ResNet、ResNext和Darknet。
对于具有b个base layer通道的k层CNN,
ResNet layer的计算为:k*[conv(1x1,b/4)] -> conv(3x3,b/4) -> conv(1x1,b)];
ResNeXt layer的计算为:k*[conv(1x1,b/2) -> gconv(3x3/32,b/2) -> conv(1x1,b)];
Darknet layer的计算为:k*[conv(1x1,b/2) -> conv(3x3,b)]。分别用α、β和γ表示可用于调整图像大小、层数和通道数的缩放因子,当这些比例因子变化时,表1总结了FLOPs的相应变化。
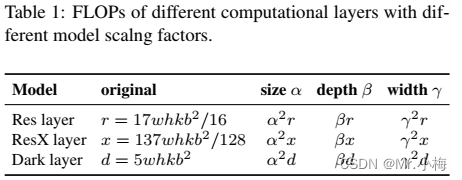
从表1可以看出,计算消耗缩放尺寸和宽度呈平方倍增长,深度呈线性增长。

CSPNet可以应用于各种CNN架构,同时减少了参数和计算量。此外,它还提高了准确性,减少了推理时间。将其应用于ResNet、ResNeXt和Darknet,并观察计算量的变化,如表2所示。CSP block的结构如上图所示。

从表2所示的数字中,可以看到,将上述CNN转换为CSPNet后,新架构可以有效地将ResNet、ResNeXt和Darknet上的计算量(FLOP)分别减少23.5%、46.7%和50.0%。因此,本文使用 CSP-ized化模型作为执行模型缩放的最佳模型。6.2.2 低端设备可缩放的微型模型
对于低端设备,设计模型的推理速度不仅受计算量和模型大小的影响,更重要的是必须考虑外围硬件资源的限制。因此,在执行微小模型缩放时,还必须考虑内存带宽、内存访问成本(MAC)和DRAM流量等因素。为了考虑上述因素,设计必须符合以下原则:
-
使计算复杂度小于 O ( w h k b 2 ) O(whkb^{2}) O(whkb2)
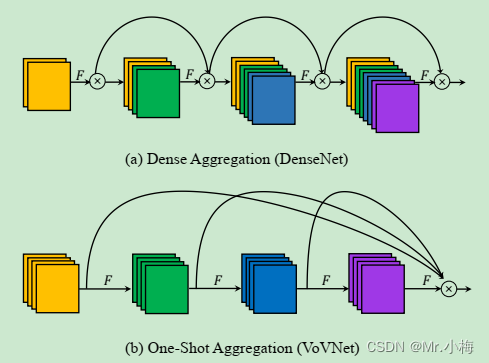
轻量级模型与大型模型的不同之处在于,它们的参数利用效率必须更高,以便通过少量计算达到所需的精度。在执行模型缩放时,希望计算顺序尽可能低。在表3中,分析了具有有效参数利用率的网络,例如DenseNet和OSANet的计算负载,其中g表示增长率。

对于一般的CNN,表3中列出的g、b和k之间的关系为k<
-
最小化/平衡特征图的大小
为了在计算速度方面取得最佳平衡,提出了一个新概念,即在CSPOSANet的计算块之间执行梯度截断。如果将原始CSPNet设计应用于DenseNet或ResNet架构,因为这两种架构的第j层输出是第1到(j-1)层输出的整合,必须将整个计算块视为一个整体。由于OSANet的计算块属于PlainNet架构,因此从计算块的任何层制作CSPNet都可以实现梯度截断的效果。本文使用此功能重新规划基础层的b通道和计算块生成的kg通道,并将它们分割为通道数相等的两条路径,如表4所示。

当通道数为 b + k g b+kg b+kg时,如果要将这些通道分成两条路径,最好的分割是将其分成两个相等的部分,例如 ( b + k g ) / 2 (b+kg)/2 (b+kg)/2。当实际考虑硬件的带宽τ时,如果不考虑软件优化,最佳值为 c e i l ( ( b + k g ) / 2 τ ) ∗ τ ceil((b+kg)/2τ)*τ ceil((b+kg)/2τ)∗τ。本文设计的CSPOSANet可以动态调整信道分配。 -
卷积后保持相同的通道数
为了评估低端设备的计算成本,还必须考虑功耗,而影响功耗的最大因素是内存访问成本(MAC)。通常,卷积运算的MAC计算方法如下:

其中,h、w、Cin、Cout和K分别表示特征映射的高度和宽度、输入和输出的通道数以及卷积滤波器的数量。通过计算几何不等式,可以得出 当 C i n = C o u t C_{in}=C_{out} Cin=Cout时的MAC最小。 -
最小化卷积输入/输出(CIO)

CIO是一个可以测量DRAM IO状态的指示器。表5列出了OSA、CSP和本文设计的CSPOSANet的CIO。 当kg>b/2时,提出的的CSPOSANet可以获得最佳CIO。
6.2.3 高端GPU扩展的大型模型
由于我们希望在放大CNN模型后提高精度的同时并保持实时推理速度,因此在执行复合缩放时,必须在目标检测器的许多缩放因子中找到最佳组合。通常,可以调整目标探测器input、backbone和neck的比例因子。表6总结了可调整的缩放因子。

图像分类和目标检测的最大区别在于,前者只需要识别图像中最大占比的类别,而后者需要预测图像中每个目标的位置和大小。在一阶段目标检测器中,每个位置对应的特征向量用于预测该位置上的目标类别和大小。更好地预测物体大小的能力基本上取决于特征向量的感受野。在CNN架构中,与感受野最直接相关的是stage,而特征金字塔网络(FPN)架构告诉我们,更多的stage更适合预测大型物体。在表7中,说明了感受野和几个参数之间的关系。

从表7可以看出,宽度缩放可以独立操作。当输入图像尺寸增大时,如果想要对大型目标有更好的预测效果,就必须增加网络的深度或stage数。在表7中列出的参数中,{ s i z e i n p u t size^{input} sizeinput,#stage}的组合效果最好。 因此,在执行缩放时,首先对size^input、#stage执行复合缩放,然后根据实时要求,分别对深度和宽度执行缩放。6.3 Scaled-YOLOv4
在本节中,讲解为普通GPU、低端GPU和高端GPU设计可缩放的YOLOv4。
6.3.1 SCP-ized YOLOv4
YOLOv4是为通用GPU上的实时目标检测而设计的。在本小节中,重新设计了YOLOv4得到YOLOv 4 CSP,以获得最佳速度/精度权衡。
-
Backbone
在CSPDarknet53的设计中,跨阶段过程的下采样卷积计算不包括在残差块中。因此,可以推断出每个CSPDarknet阶段的计算量为 w h b 2 ( 9 / 4 + 3 / 4 + 5 k / 2 ) whb^{2}(9/4+3/4+5k/2) whb2(9/4+3/4+5k/2)。从上面推导的公式中,可以知道只有当满足k>1时,CSPDarknet stage才比Darknet stage有更好的计算优势。CSPDarknet53中每个stage的残差层数量分别为1-2-8-8-4。为了获得更好的速度/精度权衡,将第一个CSP stage转换为原始的Darknet残差层。 -
Neck
为了有效地减少计算量,在YOLOv4中CSP化了PAN架构。PAN的结构如图2(a)所示。它主要整合来自不同特征金字塔的特征,然后通过两组反向Darknet残差层,没有shortcut连接。CSP化之后,新的结构如图2(b)所示,这个新的更新有效地减少了40%的计算量。

-
SPP
SPP模块最初插入neck第一个计算列表组的中间位置。因此,本文还将SPP模块插入到CSPPAN第一个计算列表组的中间位置。
6.3.2 YOLOv4-tiny
YOLOv4 tiny是为低端GPU设备设计的,设计遵循<低端设备可缩放的微型模型>节中提到的原则。

本文使用带有PCB架构的CSPOSANet来构成YOLOv4的Backbone。设置 g = b / 2 g=b/2 g=b/2作为增长率,并在最后使其增长到 b / 2 + k g = 2 b b/2+kg=2b b/2+kg=2b。通过计算,得出 k = 3 k=3 k=3,其结构如图3所示。对于每个阶段和neck部分的通道数,遵循YOLOv3-tiny的设计规则。
6.3.3 YOLOv4-large
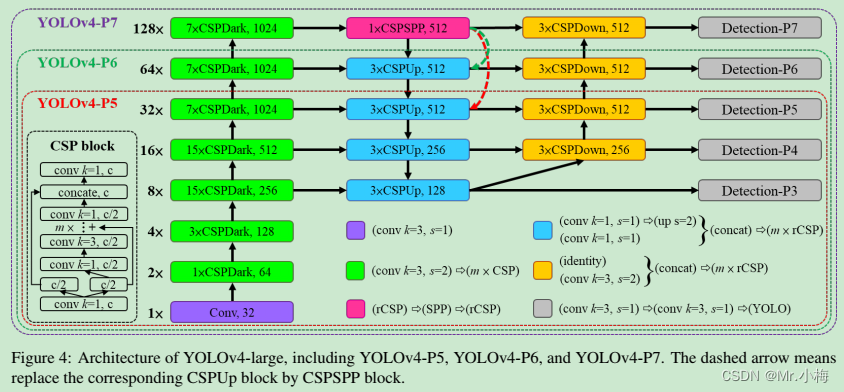
YOLOv4 large是为云GPU设计的,主要目的是实现高精度的目标检测。设计了一个完全CSP化的YOLOv4-P5,并将其扩展到YOLOv4-P6和YOLOv4-P7。图4展示了YOLOv4-P5、YOLOv 4P6和YOLOv-4-P7的结构。在 s i z e i n p u t size^{input} sizeinput、#stage上执行复合缩放,将每个阶段的深度刻度设置为 2 d s i 2^{dsi} 2dsi, d s 为 [ 1 , 3 , 15 , 15 , 7 , 7 , 7 ] ds为[1,3,15,15,7,7,7] ds为[1,3,15,15,7,7,7]。最后,进一步使用推理时间作为约束来执行额外的宽度缩放。实验表明,当宽度缩放因子等于1时,YOLOv4-P6可以在30 FPS视频上达到实时性能。对于YOLOv4-P7,当宽度比例因子等于1.25时,它可以在16 FPS视频下实现实时性能。
-
相关阅读:
Linux学习——标准IO的读写
2. 堪比JMeter的.Net压测工具 - Crank 进阶篇 - 认识yml
1. zookeeper分布式协调者
Unity3D学习笔记12——渲染纹理
自学Python只看这个够不够........?
速学Linux丨一文带你打开Linux学习之门
前端vue论坛项目(八)------组件的数据存储和父子组件之间的传值
AlphaFold2源码解析(1)--安装使用
RPA的命令库与子程序是什么?
智能工厂落地的三种模式,你了解多少?
- 原文地址:https://blog.csdn.net/qq_39707285/article/details/126968156