-
并发原理 — CPU原子性指令(一)
本篇文章将以Intel CPU作为讨论基础
一、并发的由来
- 一台计算机有2个cpu,其中CPU1执行程序A,CPU2执行程序B,由于程序A和程序B是两个不同的应用程序,所以它们两个之间并不存在并发问题。
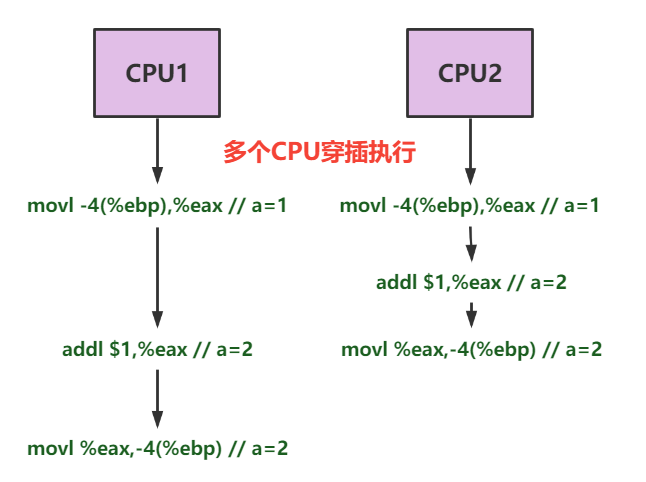
2.现在两个CPU要执行程序A的同一段代码,比如对变量a执行加1操作,代码a=a+1经过汇编器编译之后就是如下指令片段:addl $1,-4(%esp);

Intel CPU的指令集属于复杂指令集类型(CISC),其内部也是由微指令组成,就拿上面的加1操作指令,在CPU内部执行的时候可能会分成如下三步:
(1)从内存中取到1放入寄存器中
movl -4(%ebp),%eax- 1
(2)对寄存器中的数执行加1操作
addl $1,%eax- 1
(3)将加操作的结果写回内存中
movl %eax,-4(%ebp)- 1
3.那么问题就来了:由于执行的是同一段代码,我们期望最后的结果是两个CPU各加一次,也就是a=3。但实际情况存在穿插执行:CPU1和CPU2同时执行了步骤1,此时a=1;然后CPU2执行了加法操作并把数据写入了内存,此时a=2,但CPU1已经取到的值是1,执行加法指令操作,接着把结果写入内存,结果依然是a=2。与我们预期的a=3不符,造成数据紊乱。造成数据紊乱的根本原因就是穿插执行,多个CPU操作同一个可读可写的数据就会有并发问题。那在CPU层面是如何解决并发问题呢?
二、CPU解决并发问题的方案
1.对总线上锁
为了解决并发问题,我们能想到的就是把以上三个步骤的代码当作一个整体,要么全部不执行,要么全部执行不能被穿插,我们称之为原子性代码:将一串操作定义为不能拆散的基本操作。
CPU在访存的时候需要通过控制总线、数据总线和地址总线相结合从内存读写数据,由此可以得知第一种解决办法就是对总线上锁。但这种方法有个很大的弊端,一旦锁了总线,就算其他CPU执行的不是同一个程序的代码,那么这些CPU也得等待,这将造成严重的性能损耗,锁的粒度太大,为此我们考虑如何将锁细粒度化?

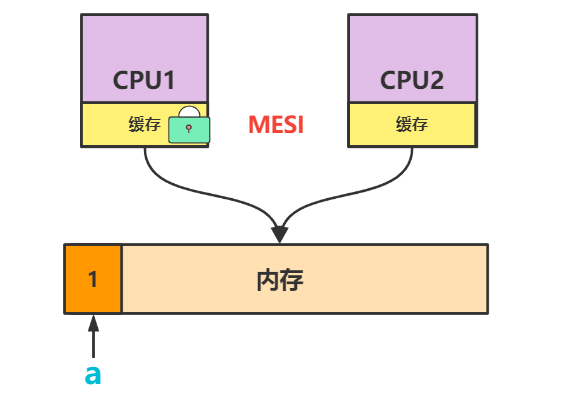
2.对缓存行上锁
CPU内部有缓存,为了加速访问,CPU会把数据a相邻连续的一段内存空间数据(缓存行)加载到缓存中,为此得到了我们第二种解决数据紊乱的办法:对缓存行上锁。一旦数据a发生改变,会根据CPU的MESI协议来更新数据,达到数据一致性。[关于CPU的MESI协议可以参考本篇文章]
3.原子性指令
综上所述,intel cpu提供了原子性指令,只要指令支持lock前缀,那么它就可以把这条指令变成原语指令(原语:原子性的语义),比如 add,加上lock前缀就是 lock;add ,那么加法操作就变成了原子性操作,不会再被穿插执行了。但也有一些指令比较特殊,它们本身就是原语指令,不需要lock前缀,比如:xchg。
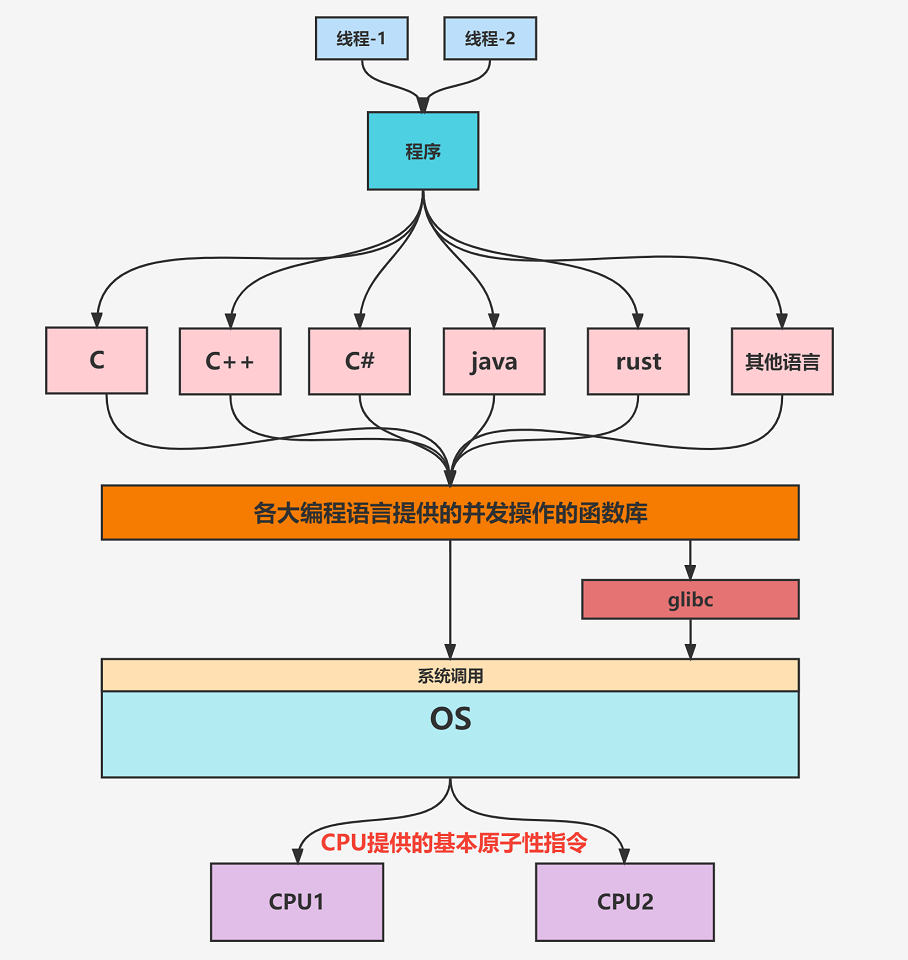
三、上层应用的并发解决方案
只有CPU提供了原子性指令,上层应用才能够根据这些指令来设计出指令段与指令段之间的原子性操作。这是一种自底向上的设计,没有CPU最底层的支持,上层应用根本就无法解决并发问题。应用程序使用自身语言提供的并发操作函数库,比如java的juc包,而这些函数库又会封装OS的系统调用或者使用glibc库,OS的系统调用最终会使用CPU提供的原子性指令。
-
相关阅读:
查询中一些字段的用法
[工业自动化-13]:西门子S7-15xxx编程 - 分布式从站 - 硬件配置
C/C++——内存管理
Shell 正则表达式及综合案例及文本处理工具
Hadoop学习
【JVM】垃圾标记算法与无用类判断算法
【Promise】一文带你了解promise并解决回调地狱
day4作业
Docker入门概述
python实现语音识别
- 原文地址:https://blog.csdn.net/tianxingzhe37/article/details/126965131