-
【C语言】结构体详解
这里主要讲一些结构体得进阶知识,如果想了解得更多可以结合这篇博客一起学习——初始结构体
一.结构体的基本知识
结构是一些值得集合,这些值称为成员变量。结构得每个成员可以是不同类型得变量。
二.结构得特殊声明
在声明结构得时候,可以不完全得声明。
例如:
//匿名结构体类型 struct { int a; char b; float c; }x; struct { int a; char b; float c; }a[20],*p;- 此时定义得结构体变量x,结构体数组a,结构体指针变量p都可以完好得创建出来,但也只能使用这些变量,如果需要其它的变量只能继续在结构体的后边增加,否则只能使用单一的变量。
- 匿名结构体一般只能用一次,创造后使用的结构体变量只用在结构体末尾处已经声明好的变量,以后就不会再用。
写道这里我们会发现,上面创建的两个结构体的成员变量是相同的,连成员变量的顺序都是相同的。那么问题来了,这两个结构体的类型是否相同?
想要探究这个问题,我们只需执行下面的操作即可:
//使用结构体指针变量p接收结构体变量x的地址,若能接收说明它们的类型是相同的 p = &x;执行后,VS编译器给出如下警告:

"="两端的类型是不兼容的,证明虽然它们的结构体是相同的,但它们是不同的类型警告:
编译器会把上面的两个声明当成完全不同的两个类型
所以是非法的。三.结构体的自引用
在结构体中包含一个类型为该结构体本身的成员是否可以呢?
struct Node { int data; struct Node next; }; //这样写是否可以?这么写明显是不对的,一个结构体类型中包含着一个该结构体类型的成员变量,这么一直下去该类型创建的成员变量的大小将无法确定,这明显是不符合C语言语法的。

1.正确的自引用
struct Node { int data; struct Node* next; };- 在结构体类型中创建该结构体类型的指针成员变量,用改指针指向同类型的结构体成员。
2.问题
在前段时间我学习数据结构时,写了一个非常经典的错误写法,这里写出来共大家参考。
typedef struct Node { int data; Nd* next; }Nd;- 使用typedef创建了结构体类型Nd,使用次类型名代替原来的结构体类型struct Node
这是一个非常金典的错误写发,因为Nd的使用是在它的声明之前的,使用时编译器不会识别Nd,哪怕编译器没有报错并且可以使用
3.解决办法
//方法1 typedef struct Node Nd; typedef struct Node { int data; Nd* next; }Node;- 提前使用typedef将结构体类型名赋给Nd
//方法2 typedef struct Node { int data; struct Node* next; }Node;- 按部就班,在创建结构体指针成员变量时,使用最上面的结构体类型名创建。
结构体的自引用是在特殊情况使用的如:数据结构中的链表、二叉树等
如果对这方面的应用感兴趣可以点击链接了解一下线性表之单链表四.结构体内存对齐
当我们明白了结构体的基本使用后,下一个问题就是:计算结构体的大小。
这是一个特别热门的考点:结构体对齐1.偏移量
- 很多学科都包含了偏移量的知识,它的作用范围很广。(这里只研究结构体,其他做了解)
- 概念:存储单元的实际地址与其所在段的段地址之间的距离称为段内偏移,也称为“有效地址或偏移量”。
- 通俗的讲,一个结构体类型的变量创建后,该变量的起始位置,到它所含的结构体成员变量的起始位置之间的距离(字节),就是该结构体成员变量的偏移量。
通过下面一个例子你就能明白:
struct text { int a; char b; }text;我们创建了结构体类型变量text,方便求成员变量a和b的偏移量。
- a是第一个成员变量,所以它的偏移量就是0
- b是第二个成员变量,在它之前的变量a为int类型占4个字节,所以b的偏移量就是4.
我们就能得到该结构体的大小为5

- 当然结构体的内存对齐绝不是这么简单
2.offsetof宏
offsetof(type,member)- 此函数可以返回数据结构或联合类型中成员的偏移量(以字节为单位)
- type:结构体类型(这里之研究结构体,type还可以表示其他类型)
- member:属于对应类型的成员
拿人我们一起看一下下面结构体类型的偏移量:
struct S1 { char a; int b; char c; }; int main() { struct S1 s1; printf("%d\n", offsetof(struct S1, a)); printf("%d\n", offsetof(struct S1, b)); printf("%d\n", offsetof(struct S1, c)); return 0; }
a时第一个元素,偏移量为0,而b和c的偏移量为什么时这样呢?
着源于结构体的对齐规则3.结构体对齐规则
- 第一个成员在与结构体偏移量为0的地址处。
- 其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处。
注意:对齐数 = 编译器默认的一个对齐数 与 该成员大小的较小值
VS默认的对齐数为8,Linux下没有默认对齐数(对齐数为结构体成员自身的大小) - 结构体总大小为:最大对齐数(所有变量类型最大者与默认对齐参数取最小)的整数倍。
- 如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。
- 这里对齐数不能理解为偏移量,偏移量时从起始位置到目标位置的字节数,对齐数又成员变量类型和编译器默认值决定。
看了这些规则后,让我们接着上面的问题继续分析
a:是第一个成员,char类型只占一个字节
b:不是第一个成员,int类型占4个字节。按上边的规则,b的偏移量是某个数字(对齐数)的整数倍的地址处,4小于8(编译器默认对齐数),所以对齐数是4,要偏移到4的整数倍处,此时的偏移量为4的地址是空的,该位置又符合4的整数倍这一要求。
c:b从偏移量为4的地址处开始,一直到7,而c的类型为char占1个字节,所有数字都是1的整数倍,所以偏移量是8.
从0开始,此时一共使用9字节空间。
而结构体的大小又是最大对齐数的整数倍,a——1 , b——4 ,c——1,
最大对齐数为4,而9不是4的整数倍,需要继续偏移,最终,该结构体的大小为12.

//查看struct S1类型的大小 printf("%d\n", sizeof(struct S1));
4.练习
//练习1 struct S2 { char c1; char c2; int i; }; printf("%d\n", sizeof(struct S2));
- 结构体S1(上面举例使用的结构体)和S2的结构体成员变量类型相同,但结构体大小不同,原因在于结构体成员变量的位置不同,我们写结构体时,可以将占用空间小的类型放在前面,更加节省空间。
//练习2 struct S3 { double d; char c; int i; }; printf("%d\n", sizeof(struct S3));
//练习3-结构体嵌套问题 struct S4 { char c1; struct S3 s3; double d; }; printf("%d\n", sizeof(struct S4));
- 以练习3中struct S3为例,结构体中成员变量的地址时由底到高的
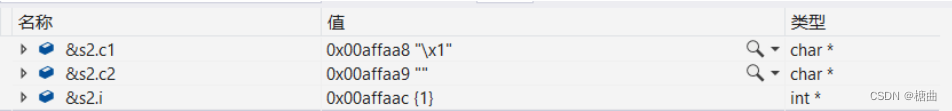
五.为什么存在内存对齐
这里官方没有给出原因,大部分参考书给出的原因如下
- 平台原因(移植原因)
不是所有的平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些特点的地址处存储特点类型的数据,否则会抛出异常。比如因为硬件的原因当我们要定义一个整型的变量时,要求它必须存储在偏移量为4的倍数的位置,这样它的对齐数就只能是4.(基于一些特殊的平台)
- 性能原因
数据结构(尤其是栈)应该尽可能地在自然边界上对齐。
为了访问未对其的内存,处理器需要作两次访问;而对齐的内存仅需要一次访问。由于CPU和数据存储方式的原因,当一个整数,放在偏移量为1的位置上时,CPU需要访问两次,才能完全取出数据。大家要是对这个原理感兴趣,可以看一下我总结的这篇博客 探索未对齐内存CPU的访问逻辑
总体来说:
结构体的内存就是拿空间换取时间的做法
六.修改默认对齐数
使用#pragma预处理指令改变默认对齐数。
- 设置默认对齐数:#pragma pack() —— 括号内设默认对齐数的值,值为整数,不能为空
- 回复默认对齐数:#pragma pack() —— 括号内什么都不写
#include#pragma pack(8)//设置默认对齐数为8 struct S1 { char c1; int i; char c2; }; #pragma pack()//取消设置的默认对齐数,还原为默认 #pragma pack(1)//设置默认对齐数为1 struct S2 { char c1; int i; char c2; }; #pragma pack()//取消设置的默认对齐数,还原为默认 int main() { //输出的结果是什么? printf("%d\n", sizeof(struct S1)); printf("%d\n", sizeof(struct S2)); return 0; } 
七.结构体传参
struct S { int data[1000]; int num; }; struct S s = {{1,2,3,4}, 1000}; //结构体传参 void print1(struct S s) { printf("%d\n", s.num); } //结构体地址传参 void print2(struct S* ps) { printf("%d\n", ps->num); } int main() { print1(s); //传结构体 print2(&s); //传地址 return 0; }上述代码哪一种传参方式更好?
- 地址传参更好
原因
函数传参是,参会需要压栈,会有时间和空间上的系统开销。
如果传递一个结构体变量值时,如果该结构体变量过大,参数压栈的系统开销比较大,所以会导致性能的下降。
简单的说,传结构体变量过去,形参会复制一份实参的数据,当数据过大时,计算机性能就会下降。
而传地址,只是传递过去一个地址,在32位平台下,地址的大小时固定的,占4个字节。八.总结
- 在学习和做题过程中结构体是非常重要的,每当遇到一个对象有多种特性的问题时,都可以用结构体来解决。
- 该博客结构体的内存对齐那一块是面试时的高频考点,务必要掌握。
- 结构体应用在学校生涯中应当是数据结构,在学习数据结构之前大家要一起加油打好基础。

-
相关阅读:
使用鸿蒙HarmonyOs NEXT 开发 快速开发 简单的购物车页面
[C++ 从入门到精通] 11.拷贝构造函数
作业11:优化算法比较
windows定制ISO-可安装
JAVA学习笔记(IF判断结构)
2022年,下半年互联网最靠谱的搞钱方法?
Shiro认证
Pyecharts一文速学-绘制桑基图详解+Python代码
我的十年程序员生涯--无锡之旅,开启岗前培训
能不能手写Vue响应式?前端面试进阶
- 原文地址:https://blog.csdn.net/m0_52094687/article/details/126960882