-
第三章 简单静态网页爬取
静态网站是指全部由HTML代码格式页面组成的网站,所有的内容包含在网页文件中,通常没有后台数据库,页面不含程序并且无法交互。网页上也可以出现各种视觉动态效果,如GIF动画、FLASH动画、滚动字幕等,而网站主要是静态化的页面和代码组成,一般文件名均以htm、html、shtml等为后缀,静态网页一经发布到服务器上,无论是否被访问,都是一个独立存在的文件。早期的网站基本都是由静态网站构成的。本章将分别使用urllib3库、Requests库向链家二手房发送HTTP请求,并使用Chrome开发者工具、Xpath表达式、bs4解析、正则表达式解析获取的网页内容,最后将解析的结果分别保存到CSV文件和MySQL数据库中。
3.1 实现HTTP请求
本章主要使用urllib3库和Requests库实现HTTP请求。
3.1.1使用urllib3库
urllib3 是一个强大的、用户友好的 Python HTTP 客户端。许多 Python 生态系统已经使用urllib3,其提供了Python 标准库中缺少的许多关键特性:
- 线程安全。
- 连接池。
- 客户端 TLS/SSL 验证。
- 使用多部分编码的文件上传。
- 重试请求和处理 HTTP 重定向的助手。
- 支持 gzip、deflate 和 brotli 编码。
- 对 HTTP 和 SOCKS 的代理支持。
- 100% 的测试覆盖率。
更多详细内容可以参考urllib3官方网址:https://urllib3.readthedocs.io/en/stable/index.html
使用urllib3库发送请求:
1.安装
urllib3可以使用pip安装,代码如下:pip install urllib32.发送请求
首先,导入urllib3模块,代码如下:import urllib3其次,需要创建一个PoolManager实例来发出请求,该对象处理连接池和线程安全的所有细节,代码如下:
http = urllib3.PoolManager()可以使用request()方法发送请求,代码如下:
response = http.request('GET', 'https://ssr1.scrape.center/')- request()方法的基本语法如下:
- request(method, url, fields=None, headers=None, **urlopen_kw)
- 参数说明:
- method:接收str。表示发送请求的类型,与HTTP请求相同,如:GET、HEAD、POST等,无默认值,必须传入。
- url:接收str。表示发请求的网址,无默认值,必须传入。
- fields:接收dict。表示请求类型所带的参数。默认为None。
- headers:接收dict。表示请求头所带的参数。默认为None。
- **urlopen_kw:接收dict或其他python中的数据类型的数据。无默认值。
request()返回一个HTTPResponse对象,此时response就是获取到的网页内容,如图3-1所示:

该响应对象提供 status、data和 headers等属性,可以通过这些属性获取响应内容中的具体信息,完整如代码3-1所示:# 导入模块 import urllib3 # 创建PoolManager实例对象 http = urllib3.PoolManager() # 目标url url = 'https://ssr1.scrape.center/' # 使用request()方法发送请求 response = http.request('GET', url) # 查看响应对象的状态码 print('响应对象的状态码:', response.status) 响应对象的状态码: 200备注:由于响应内容过长,此处部分结果已省略。
不难发现响应内容就是使用浏览器访问该网页的网页源代码,可以通过Chrome查看网页源代码进行对比。
以上就是使用urllib3库对向静态网页发送请求获得响应的简单过程。除urllib3库以外还可以使用另外一个比较主流的三方库实现发送请求。3.1.2使用requests库
Requests是一个原生的HTTP库, 可以发送原生的 HTTP/1.1 请求。不需要手动为 URL 添加查询字串,也不需要对POST数据进行表单编码。完全自动化的Keep-alive 和 HTTP 连接池的功能,完全满足如今Web的需求,具体特性如下:
- Keep-Alive & 连接池
- 国际化域名和 URL
- 带持久 Cookie 的会话
- 浏览器式的 SSL 认证
- 自动内容解码
- 基本/摘要式的身份认证
- 优雅的 key/value Cookie
- 自动解压
- Unicode 响应体
- HTTP(S) 代理支持
- 文件分块上传
- 流下载
- 连接超时
- 分块请求
- 支持 .netrc
更多详细内容可以参考Requests官方网址:https://docs.python-requests.org/en/latest/
使用Requests库发送请求:
1.安装
Requests库可以使用pip安装,代码如下:pip install requests2.发送请求
导入requests模块,代码如下:import requests使用requests库中的get()方法发送请求,代码如下:
response = requests.get('https://ssr1.scrape.center/')除此以外还可以通过requests库request()方法发送请求,代码如下:
url = 'https://ssr1.scrape.center/' response = requests.request(method='GET', url=url)- request()方法的基本语法如下:
- requests.request(method, url, **kwargs)
- 参数说明:
- method:发送请求的方法:GET, OPTIONS, HEAD, POST, PUT, PATCH, 或DELETE。
- url:发送请求的网址。
- params:(可选)字典、元组、列表或字节列表,查询字符串,作为参数增加到url中,一般用于get请求,post请求也可以使用(不常用)。
- data:(可选)字典,元组列表,字节或文件对象,作为post请求的参数。
- json:(可选) JSON格式的数据,作为post请求的json参数。
- headers:(可选)字典类型, HTTP请求头信息。
- cookies: (可选)字典或CookieJar,响应头中的Cookie。
- files:字典类型,传输文件,作为post请求文件流数据。
- auth:(可选)用于启用基本/摘要/自定义 HTTP 身份验证的身份验证元组。
- timeout: (可选) 设定超时时间,秒为单位,作为浮点数或(connect timeout, read timeout)元组。
- allow_redirects:(可选)布尔值。启用/禁用 GET/OPTIONS/POST/PUT/PATCH/DELETE/HEAD 重定向。默认为True。
- proxies:字典类型,设定访问代理服务器,可以增加登录认证。
- verify:布尔值。默认为True,认证SSL证书开关。
- stream:(可选)如果是False,则将立即下载响应内容。
- cert:(可选)如果是字符串,则为 ssl 客户端证书文件 (.pem) 的路径。如果是元组,则 (‘cert’, ‘key’) 对。
- 返回值:Response object。
示例:向https://www.httpbin.org/get发送请求
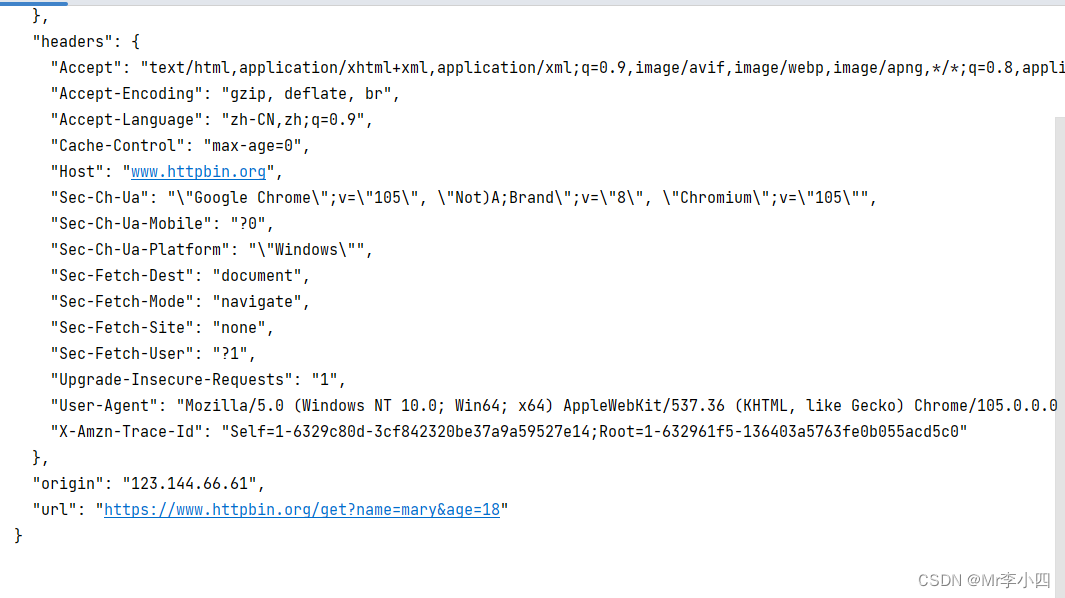
import requests url = 'https://www.httpbin.org/get' response = requests.get(url = url)附加额外信息,例如想实现添加两个参数name和age,其中name是germey、age是25,于是url就可以写成如下内容:https://www.httpbin.org/get?name=germey&age=25。要构造这个请求链接,这样直接写是允许的,但是我们有更好的选择,一般情况下利用params参数就可以直接传递这种信息了,示例如下:
import requests data = { 'name' : 'germey', 'age' : 25 } response = requests.get(url=url, params=data) print(response.text)结果如图所示:
除了使用requests.request()方法外,还有一下六种方法可以使用,如表3-1所示:
方法 基本语法 head requests.head(url, **kwargs) get requests.get(url, params=None, **kwargs) post requests.post(url, data=None, json=None, **kwargs) put requests.put(url, data=None, **kwargs) patch requests.path(url, data=None, **kwargs) delete requests.delete(url, **kwargs) 以上这些方法可以使用requests.request()方法变换其中method参数实现,返回值都为响应对象(Response object)。其中**kwargs参数可以使用requests.request()方法中的其他参数,以关键字传参传入即可。一般情况下,使用get()方法向静态网页发请求。
向”https://ssr1.scrape.center/“发送请求,并查看返回的响应对象、结果类型、状态码、编码类型、响应头和获取到的网页内容,具体示例如代码3-2所示:# 导入包 import requests # 构造url地址 url = 'https://ssr1.scrape.center/page/1' # 构造请求头信息 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36' } # 发送请求 r = requests.get(url=url.format(i), headers=headers).text print(r.status_code) # 状态码 print(r.content) # 二进制内容 print(r.content.decode('utf-8')) # 二进制解码 print(r.cookies) # cookies print(r.headers) # 头部信息 print(r.encoding) # 编码格式…
备注:由于响应内容过长,此处部分结果已省略。
由代码可知,可以使用response.status_code属性查看服务器返回的状态码,使用response.encoding属性可以查看网页编码类型,使用response.text属性可以查看响应内容的文本形式,使用response.content属性可以查看二进制的响应内容。
某些网站为了防止网页信息被恶意爬取,会设置反爬机制,通常情况下在发送请求时都需要构造请求头信息,也就是在get()方法中为参数headers传入请求头字段的某些信息,这些信息中”User-Agent”是一个比较重要的信息,可以在浏览器的Netword中任意选中一个数据包,“Headers”选项中的Requests Header中查找”User-Agent”字段的值,如图3-2所示: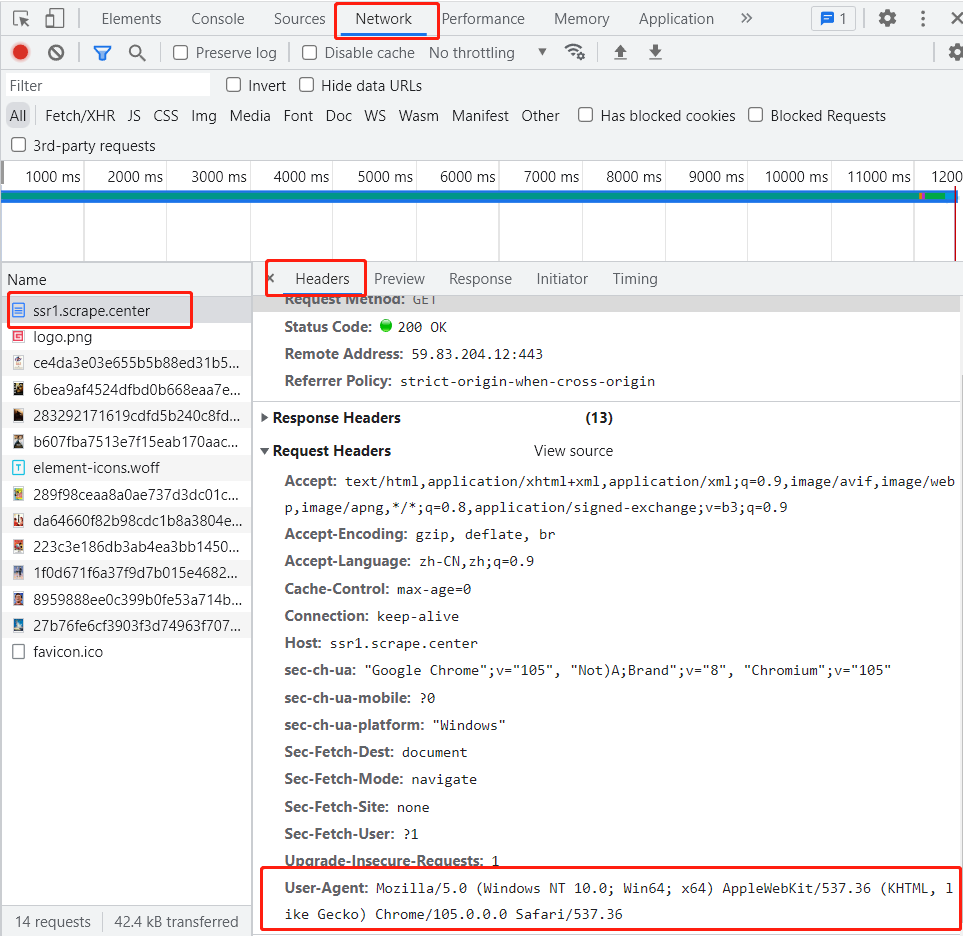
如需设置其他参数请参考requests.request()方法中的其他参数。3.2 解析网页
发送请求获得响应后需要从响应内容中提取出有用的信息这个过程称为解析。通过解析网页可以获取网页源码中包含的有用信息,如文本、图片、链接、视频等。这就需要爬虫具备定位网页中信息的位置并提取网页内容的功能。这一节主要介绍三种解析网页信息的方法,同时还需要借助Chrome开发者工具查看网页结构和页面元素等信息。
3.2.1 使用Xpath表达式解析网页
XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言。XPath基于XML的树状结构,使用路径表达式来选取 XML 文档中的节点或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。XPath 可用来在 XML 文档中对元素和属性进行遍历。XPath 含有超过 100 个内建的函数。这些函数用于字符串值、数值、日期和时间比较、节点和 QName 处理、序列处理、逻辑值等,几乎所有的定位的节点都可以用Xpath来选择。
1.Xpath节点
在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档节点(或称为根节点)。示例如下:<html> <head> <title>The Dormouse's storytitle> head> <body> <p class="title"><b>The Dormouse's storyb>p> <p class="story">Once upon a time there were three little sisters;and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsiea>, <a href="http://example.com/lacie" class="sister" id="link2">Laciea> and <a href="http://example.com/tillie" class="sister" id="link3">Tilliea>; and they lived at the bottom of a well.p> <p class="story">...p> <p>本节结束p> <div> <p>The Dormouse's storyp> <span>pricespan> <span>25span> div> body> html>上面HTML文档中节点例子:
<html> 根节点 <b>The Dormouse's storyb> 文档节点 class="story" 属性节点2.节点关系
- 父(Parent):除根节点以外,每个元素以及属性都有一个父。上例中head节点是title节点的父;
- 子(Children):元素节点可有零个、一个或多个子。上例中head节点、body节点是html节点的子;
- 同胞(Sibling):拥有相同的父的节点。上例中body节点中的p节点都是同胞,head节点和body节点也是同胞;
- 先辈(Ancestor):某节点的父、父的父。上例中p节点的先辈是body节点和html节点;
- 后代(Descendant):某个节点的子,子的子。上例中html节点的后代是head节点、title节点、body节点、p节点、a节点。
3.选取节点
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。
常用的路径表达式,如表3-2所示:表达式 描述 nodename 选取此节点的所有子节点 / 从根节点选取,或者表示一个层级 // 从匹配选择的当前节点选择文档中的节点,任意层级,不考虑它们的位置 . 选取当前节点 … 选取当前节点的父节点 @ 选取属性 4.谓语
谓语用来查找某个特定的节点或者包含某个指定的值的节点,谓语被嵌在路径后的方括号中,如表3-3所示:路径表达式 结果 /html/body/p[1] 选取属于body子节点的第一个p节点 /html/body/p[last()] 选取属于body子节点的最后一个p节点 /html/body/p[last()-1] 选取属于body子节点的倒数第二个p节点 /html/body/p[position()< 3] 选取属于body子节点的前两个p节点 //p[@class] 选取属于body子节点带有class属性的p节点 //p[@class=“title”] 选取属于body子节点带有class属性值为title的p节点 /html/body/div[span>20]/p 选取属于body子节点所有div节点,其中p节点的值须大于20 5.功能函数
Xpath还提供了可以进行模糊搜索的功能函数,有时仅掌握了对象的部分特征,当需要模糊搜索该类对象时便可以使用功能函数来实现,如表3-4所示:功能函数 示例 说明 starts-with //div[starts-with(@class, “ti”)] 选取class属性以ti开头的div节点 ends-with //div[ends-with(@class, “ti”)] 选取class属性以ti结尾的div节点 contains //div[ends-with(@class, “ti”)] 选取class属性包含ti的div节点 text //li[contains(text(), “price”)] 选取节点文本包含price的li节点 6.提取文本
使用text()方法可以提取某个子节点的直系文本,如果想要提取定位到的子节点及其子孙节点下的全部文本可以使用string方法来实现。
使用Xpath需要安装lxml,代码如下:pip install lxml从lxml库中导入etree模块,代码如下:
from lxml import etree需要使用HTML类对需要解析的响应对象进行初始化,HTML类的基本语法如下:
etree.HTML(text, parser=None, *, base_url=None)参数说明:
- text:接收str。需要转换的HTML字符串,无默认值。
- parser:接收str。解释器,无默认值。
- base_url:接收url。表示文档的原始URL,用于查找外部实体的相对路径。
爬取到的Scrape网页首页的相关信息,并使用etree.HTML()类初始化响应对象,为解析数据做好准备,如代码3-3所示:
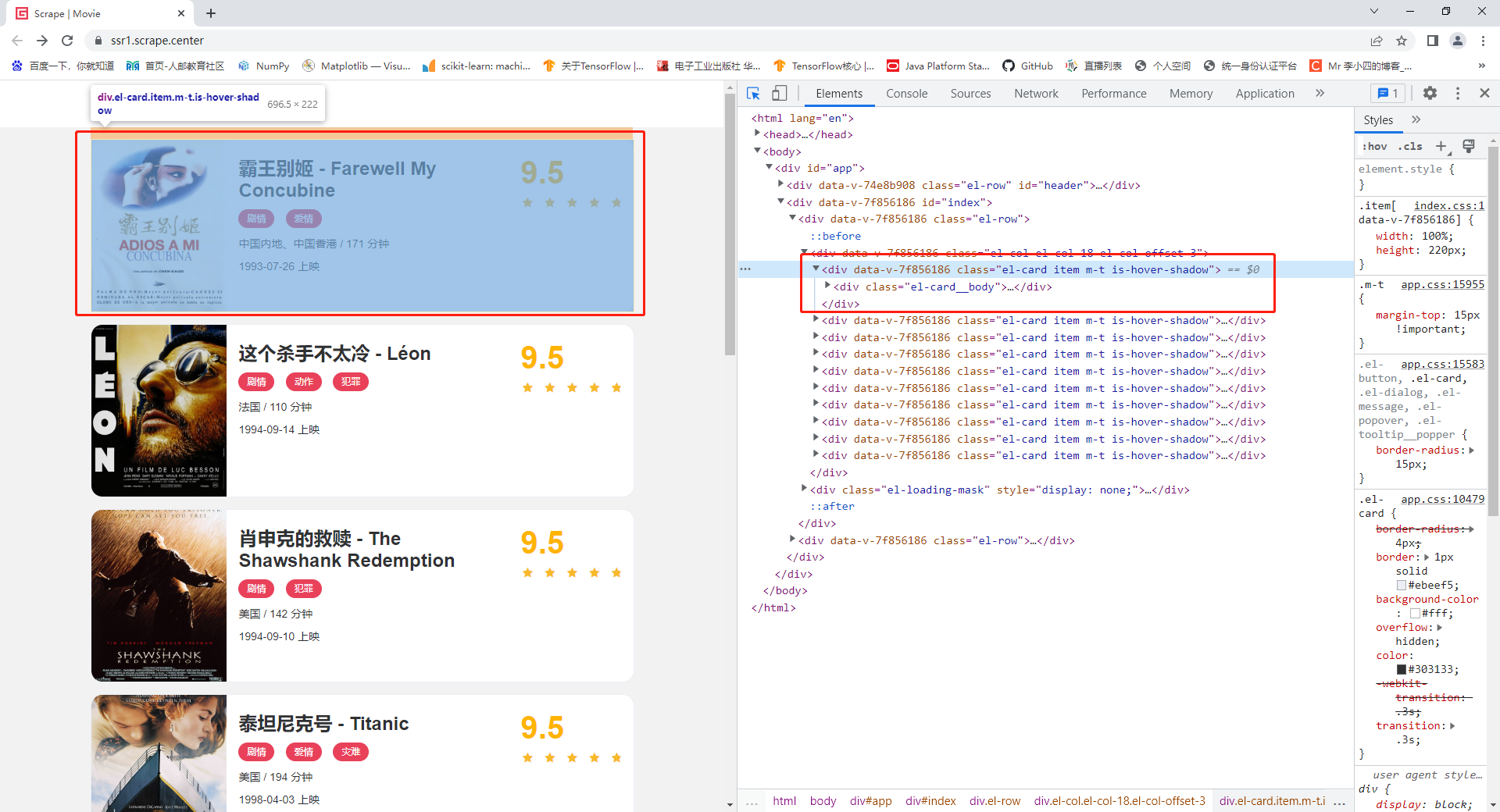
# 导入requests库 import requests # 导入etree from lxml import etree # 构造发送请求的网址 url = 'https://ssr1.scrape.center/' # 构造请求头信息 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36'} # 发送请求获得文本响应 response = requests.get(url=url, headers=headers).text # 初始化响应对象 tree = etree.HTML(response)使用Chrome打开Scrape首页,并且打开开发者工具,从元素面板(Elements)中可以看到结构化的网页代码,将鼠标移动到开发者工具的左上角单击小箭头后,将鼠标移动到想要解析的内容上,便可以在网页代码中定位到对应的代码,如图3-3所示:
面向过程的详细代码:# 导入包 import requests from lxml import etree import csv # 构造url地址 url = 'https://ssr1.scrape.center/page/{}' # 构造请求头信息 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36' } # 实现翻页功能 for i in range(1, 12): # 1 2 3 4 5 6 7 8 9 10 11 # 发送请求 response = requests.get(url=url.format(i), headers=headers).text # 数据解析 tree = etree.HTML(response) # 构造结构化的对象,方便解析使用 # 解析存放电影信息div节点的父节点,也是一个div节点 div_list = tree.xpath('//div[@class="el-col el-col-18 el-col-offset-3"]/div') # 返回一个列表,列表中的元素是每部电影信息的div # 使用循环遍历div_list,得到每部电影的div节点 for div in div_list: item = {} # 创建item字典去保存数据 # 使用xpath表达式提取电影名信息,返回存放电影名的列表 name_list = div.xpath('.//h2[@class="m-b-sm"]/text()') # 判断电影名列表是否为空,不为空则使用索引获取第零个元素存放到item字典中 item['name'] = name_list[0] if name_list else None # 使用xpath表达式提取上映地点列表 address_list = div.xpath('.//div[@class="m-v-sm info"][1]/span[1]/text()') item['address'] = address_list[0] if address_list else None # 使用xpath表达式提取时长列表 long_list = div.xpath('.//div[@class="m-v-sm info"][1]/span[3]/text()') item['long'] = long_list[0] if long_list else None # 使用xpath表达式提取上映时间列表 time_list = div.xpath('.//div[@class="m-v-sm info"][2]/span/text()') item['time'] = time_list[0] if time_list else None # 获取详情页的一半地址 half_url_list = div.xpath('.//a[@class="name"]/@href') half_url = half_url_list[0] if half_url_list else None # 拼接详情页的整个地址 detail_url = 'https://ssr1.scrape.center' + half_url # 向详情页发送请求 detail_response = requests.get(url=detail_url, headers=headers).text # 构造详情页的结构化对象 detail_tree = etree.HTML(detail_response) # 使用xpath表达式从detail_tree中获取剧情简介列表 content_list = detail_tree.xpath('//div[@class="drama"]/p/text()') item['content'] = content_list[0].strip() if content_list else None # 打印字典,观察爬取数据内容 print(item)3.3 数据持久化
爬虫通过解析网页获取到需要的数据后还需要将数据存储下来以便后期使用。可以将数据存储到文件中,也可以将数据存入数据库中,本小节主要介绍将使用Xpath表达式解析的数据保存到CSV文件中,将BeautifulSoup解析的数据通过PyMySQL保存到MySQL数据库中。
3.3.1 将数据存储到CSV文件
CSV逗号分隔值(Comma-Separated Values)有时也称为字符分隔值格式,是电子表格和数据库最常见的导入和导出格式。Python自带处理csv文件的库只需要导入就可以直接使用,无需安装。csv模块定义了读(reader)写(writer)函数,reader函数的基本语法如下:
csv.reader(csvfile, dialect='excel', **fmtparams)参数说明:
- csvfile:文件路径、文件名称,如果 csvfile是文件对象,则打开它时应使用 newline=’’。
- dialect:用于不同的 CSV 变种的特定参数组
- fmtparams :可以覆写当前变种格式中的单个格式设置
返回值:返回reader对象
Reader 对象具有以下公开属性和方法,如表所示:函数名称 说明 csvreader.next() 返回 reader 的可迭代对象的下一行 csvreader.dialect 变种描述,只读,供解析器使用。 csvreader.line_num 已经读取的行数 writer函数的基本语法如下:
csv.writer(csvfile, dialect='excel', **fmtparams)参数同上
返回值:返回writer对象
Writer对象具有以下公开属性和方法,如表所示:函数名称 说明 csvwriter.writerow(row) 将row写入到 writer 的文件对象中 csvwriter.writerows(rows) 将 rows中的所有元素写入 writer 的文件对象中 csvwriter.dialect 变种描述,只读,供 writer 使用 除此以外,csv模块还定义了DictReader类和DictWriter类处理映射关系内容的读写,DictWriter类的基本语法如下:
csv.DictWriter(f, fieldnames, restval='', extrasaction='raise', dialect='excel', *args, **kwds)参数说明:
- f:需要写入的文件
- fieldnames:组成键的序列
- restval:如果字典缺少fieldnames中的键,则可选参数restval用于指定要写入的值
- extrasaction:默认值raise,传递给writerow() 方法的字典的某些键在fieldnames中找不到时则会引发ValueError,将其设置为 ignore,则字典中的其他键值将被忽略。
如代码3-8所示:
import csv # 创建文件 with open('names.csv', 'w', newline='') as csvfile: # 创建字段名列表 fieldnames = ['first_name', 'last_name'] # 创建写入对象 writer = csv.DictWriter(csvfile, fieldnames=fieldnames) # 写入字段名 writer.writeheader() # 写入数据 writer.writerow({'first_name': 'Baked', 'last_name': 'Beans'}) writer.writerow({'first_name': 'Lovely', 'last_name': 'Spam'}) writer.writerow({'first_name': 'Wonderful', 'last_name': 'Spam'}) DictReader类的基本语法如下: csv.DictReader(f, fieldnames=None, restkey=None, restval=None, dialect='excel', *args, **kwds)参数同上,示例如下:
# 创建文件 with open('names.csv', newline='') as csvfile: # 创建读取对象 reader = csv.DictReader(csvfile) # 循环遍历读取内容 for row in reader: print(row) # 结果: {'first_name': 'Baked', 'last_name': 'Beans'} {'first_name': 'Lovely', 'last_name': 'Spam'} {'first_name': 'Wonderful', 'last_name': 'Spam'}将Xpath表达式解析得到的数据保存为csv文件,如代码3-9所示:
# 导入包 import requests from lxml import etree import csv # 构造url地址 url = 'https://ssr1.scrape.center/page/{}' # 构造请求头信息 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36' } # 创建一个文件 f = open('movie.csv', mode='w', newline='', encoding='utf-8') # 创建字段名 fieldnames = ['name', 'address', 'long', 'time', 'content'] # 创建write对像 write = csv.DictWriter(f, fieldnames=fieldnames) write.writeheader() # 实现翻页功能 for i in range(1, 12): # 1 2 3 4 5 6 7 8 9 10 11 # 发送请求 response = requests.get(url=url.format(i), headers=headers).text # 数据解析 tree = etree.HTML(response) # 构造结构化的对象,方便解析使用 # 解析存放电影信息div节点的父节点,也是一个div节点 div_list = tree.xpath('//div[@class="el-col el-col-18 el-col-offset-3"]/div') # 返回一个列表,列表中的元素是每部电影信息的div # 使用循环遍历div_list,得到每部电影的div节点 for div in div_list: item = {} # 创建item字典去保存数据 # 使用xpath表达式提取电影名信息,返回存放电影名的列表 name_list = div.xpath('.//h2[@class="m-b-sm"]/text()') # 判断电影名列表是否为空,不为空则使用索引获取第零个元素存放到item字典中 item['name'] = name_list[0] if name_list else None # 使用xpath表达式提取上映地点列表 address_list = div.xpath('.//div[@class="m-v-sm info"][1]/span[1]/text()') item['address'] = address_list[0] if address_list else None # 使用xpath表达式提取时长列表 long_list = div.xpath('.//div[@class="m-v-sm info"][1]/span[3]/text()') item['long'] = long_list[0] if long_list else None # 使用xpath表达式提取上映时间列表 time_list = div.xpath('.//div[@class="m-v-sm info"][2]/span/text()') item['time'] = time_list[0] if time_list else None # 获取详情页的一半地址 half_url_list = div.xpath('.//a[@class="name"]/@href') half_url = half_url_list[0] if half_url_list else None # 拼接详情页的整个地址 detail_url = 'https://ssr1.scrape.center' + half_url # 向详情页发送请求 detail_response = requests.get(url=detail_url, headers=headers).text # 构造详情页的结构化对象 detail_tree = etree.HTML(detail_response) # 使用xpath表达式从detail_tree中获取剧情简介列表 content_list = detail_tree.xpath('//div[@class="drama"]/p/text()') item['content'] = content_list[0].strip() if content_list else None # 打印字典,观察爬取数据内容 print(item) # 逐条将爬取的数据写入csv文件中。 write.writerow(item)运行后会自动创建.csv文件,解析的数据被保存在文件中,如图3-12所示:

除此以外还可以使用csv.writer方法创建写入对象,使用对象的writerow()方法也可以将数据保存到csv文件中,细节稍作变化,将item字典中的键值对取出来放入一个列表中,一个列表为一部电影的信息,逐条写入到csv文件中即可。比较简单,此处省略代码。
以上两种方法均可使用将数据保存成csv文件,可根据实际情况选择使用。 -
相关阅读:
不同服务器节点之间 如何实现高效可靠的文件同步?
一、Redis入门之——介绍、安装,图形化界面(GUI)工具Redis Desktop Manager (RDM)安装
【2015】【论文笔记】等离子光混合器THz辐射的光谱——
【JAVA】03 对象
镜频抑制滤波器对射频接收前端输出噪声的影响
在命令行下使用Apache Ant
c# Predicate vs Action vs Func
【Pandas数据处理100例】(九十九):Pandas使用at_time()筛选出特定时间点的数据行
超强视频超分AI算法,从此只看高清视频
多态的详解
- 原文地址:https://blog.csdn.net/shield911/article/details/126962606