-
机器学习模型2——决策树
前置知识
信息熵
信息增益
信息增益率
基尼系数主要内容

决策树
本质是⼀颗由多个判断节点组成的树。

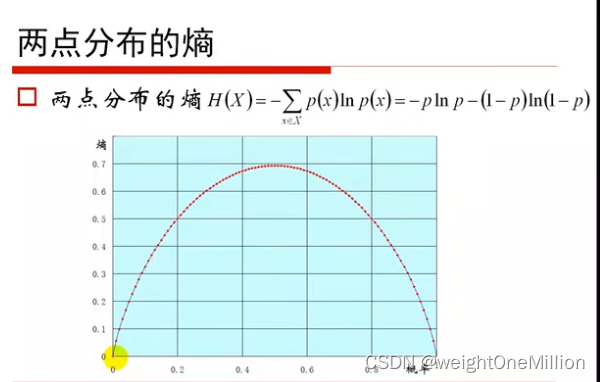
信息熵
信息熵:用来描述信息源各可能事件发生的不确定性。信息熵的值越小,说明样本的纯度越高。

以两点分布 X~§为例:
信息增益(ID3决策树)

信息增益率(C4.5决策树算法)
实际上,信息增益准则对可取值数⽬较多的属性有所偏好,为减少这种偏好可能带来的不利影响,著名的 C4.5 决策树算法 [Quinlan, 1993J 不直接使⽤信息增益,⽽是使⽤"增益率" (gain ratio) 来选择最优划分属性.
增益率:增益率是⽤前⾯的信息增益Gain(D, a)和属性a对应的"固有值"(intrinsic value) [Quinlan , 1993J的⽐值来共同定义的。
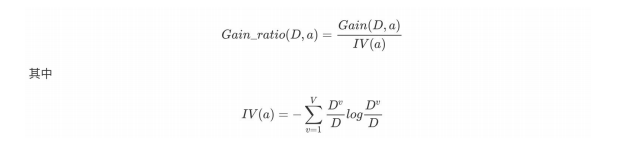
为什么使⽤C4.5要好?
1.⽤信息增益率来选择属性,克服了⽤信息增益来选择属性时偏向选择值多的属性的不⾜。
2.采⽤了⼀种后剪枝⽅法,避免树的⾼度⽆节制的增⻓,避免过度拟合数据
3.对于缺失值的处理。
在某些情况下,可供使⽤的数据可能缺少某些属性的值。 假如〈x,c(x)〉是样本集S中的⼀个训练实例,但是其属性A 的值A(x)未知。 处理缺少属性值的⼀种策略是赋给它结点n所对应的训练实例中该属性的最常⻅值; 另外⼀种更复杂的策略是为A的每个可能值赋予⼀个概率。 例如,给定⼀个布尔属性A,如果结点n包含6个已知A=1和4个A=0的实例,那么A(x)=1的概率是0.6,⽽A(x)=0的概率 是0.4。于是,实例x的60%被分配到A=1的分⽀,40%被分配到另⼀个分⽀。
C4.5就是使⽤这种⽅法处理缺少的属性值
4.可以处理连续数值型属性
缺点: 在构造树的过程中,需要对数据集进⾏多次的顺序扫描和排序,因⽽导致算法的低效。 此外,C4.5只适合于能够驻留于内存的数据集,当训练集⼤得⽆法在内存容纳时程序⽆法运⾏。基尼值与基尼指数(CART 决策树)
CART 决策树 [Breiman et al., 1984] 使⽤"基尼指数" (Gini index)来选择划分属性.
CART 是Classification and Regression Tree的简称,这是⼀种著名的决策树学习算法,分类和回归任务都可⽤
基尼值Gini(D):从数据集D中随机抽取两个样本,其类别标记不⼀致的概率。故,Gini(D)值越⼩,数据集D的纯度越⾼。
数据集 D 的纯度可⽤基尼值来度量:

基尼指数Gini_index(D):⼀般,选择使划分后基尼系数最⼩的属性作为最优化分属性。
属性a的基尼指数定义为:
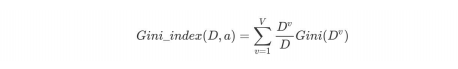
取Gini指数最⼩的属性作为决策树的根节点属性,选择使划分后基尼指数最小的属性作为最优划分属性。
CART算法相⽐C4.5算法的分类⽅法,采⽤了简化的⼆叉树模型,同时特征选择采⽤了近似的基尼系数来简化计算。 C4.5不⼀定是⼆叉树,但CART⼀定是⼆叉树。剪枝
为什么剪枝?降低过拟合
- 噪声、样本冲突,即错误的样本数据
- 特征即属性不能完全作为分类标准
- 巧合的规律性,数据量不够⼤。
决策树剪枝的基本策略有"预剪枝" (pre-pruning)和"后剪枝"(post- pruning) 。
预剪枝是指在决策树⽣成过程中,对每个结点在划分前先进⾏估计,若当前结点的划分不能带来决策树泛化性能提升,则停⽌划分并将当前结点标记为叶结点;
后剪枝则是先从训练集⽣成⼀棵完整的决策树,然后⾃底向上地对⾮叶结点进⾏考察,若将该结点对应的⼦树替换 为叶结点能带来决策树泛化性能提升,则将该⼦树替换为叶结点。
预剪枝
在构建树的过程中,同时剪枝
- 限制节点最⼩样本数
- 指定数据⾼度
- 指定熵值的最⼩值
后剪枝
把⼀棵树,构建完成之后,再进⾏从下往上的剪枝
对比
对⽐两种剪枝⽅法, 后剪枝决策树通常⽐预剪枝决策树保留了更多的分⽀。 ⼀般情形下,后剪枝决策树的⽋拟合⻛险很⼩,泛化性能往往优于预剪枝决策树。 但后剪枝过程是在⽣成完全决策树之后进⾏的。 并且要⾃底向上地对树中的所有⾮叶结点进⾏逐⼀考察,因此其 训练时间开销⽐未剪枝决策树和预剪枝决策树都要⼤得多.
回归决策树(看看就好,我也不想去记它)
⼀个回归树对应着输⼊空间(即特征空间)的⼀个划分以及在划分单元上的输出值。分类树中,我们采⽤信息论中的⽅法,通过计算选择最佳划分点。
⽽在回归树中,采⽤的是启发式的⽅法。假如我们有n个特征,每个特征有si(i ∈ (1, n))个取值,那我们遍历所有特征, 尝试该特征所有取值,对空间进⾏划分,直到取到特征 j 的取值 s,使得损失函数最⼩,这样就得到了⼀个划分点。描 述该过程的公式如下:
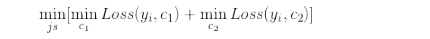
算法描述:

决策树的API
tree.DecisionTreeClassifier(*[, criterion, ...])A decision tree classifier. tree.DecisionTreeRegressor(*[, criterion, ...])A decision tree regressor. tree.ExtraTreeClassifier(*[, criterion, ...])An extremely randomized tree classifier. tree.ExtraTreeRegressor(*[, criterion, ...])An extremely randomized tree regressor. tree.export_graphviz(decision_tree[, ...])Export a decision tree in DOT format. tree.export_text(decision_tree, *[, ...])Build a text report showing the rules of a decision tree. tree.plot_tree(decision_tree, *[, ...])Plot a decision tree.决策树分类器
class sklearn.tree.DecisionTreeClassifier(*, criterion='gini', splitter='best', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, class_weight=None, ccp_alpha=0.0)参数:
-
criterion: {“gini”, “entropy”, “log_loss”}, default=”gini”
衡量分割质量的函数。特征选择标准 “gini"或者"entropy”,前者代表基尼系数,后者代表信息增益。⼀默认"gini",即CART算法。 -
splitter:{“best”, “random”}, default=”best”
用于选择每个节点上的拆分的策略。支持的策略是“最佳”选择最佳分割,“随机”选择最佳随机分割。 -
max_depth: int,default=None
树的最大深度。如果为“无”,则节点将展开,直到所有叶都是纯叶或所有叶包含的采样数小于min_samples_split。
决策树最⼤深度 决策树的最⼤深度,默认可以不输⼊,如果不输⼊的话,决策树在建⽴⼦树的时候不会限制⼦树的深度。 ⼀般来说,数据少或者特征少的时候可以不管这个值。如果模型样本量多,特征也多的情况下,推荐限制 这个最⼤深度,具体的取值取决于数据的分布。常⽤的可以取值10-100之间. -
min_samples_split: int或float,default=2
分割内部节点所需的最小样本数:
如果为int,则将min_samples_split视为最小值。
如果是float,则min_samples_split是一个分数,而ceil(min_samples _split*n_samples)是每个分割的最小采样数。 -
min_samples_leaf:int或float,default=1
叶节点所需的最小样本数。只有在每个左分支和右分支中至少保留min_samples_leaf训练样本时,才会考虑任何深度的分割点。这可能会产生平滑模型的效果,尤其是在回归中。
如果为int,则将min_samples_leaf视为最小值。
如果是float,那么min_samples_leaf是一个分数,ceil(min_samples _leaf*n_samples)是每个节点的最小采样数。 -
min_weight_fraction_leaf: float,default=0.0
叶节点所需的(所有输入样本)权重总和的最小加权分数。未提供sample_weight时,样本具有相等的权重。 -
max_features:int, float or {“auto”, “sqrt”, “log2”}, default=None
寻找最佳分割时要考虑的功能数量:
如果为int,则考虑每次拆分时的max_features特性。
如果是float,那么max_features是一个分数,每次拆分时都会考虑max(1,int(max_feetures*n_feature in))特性。
如果为“auto”,则max_features=sqrt(n_feature)。
如果为“sqrt”,则max_features=sqrt(n_feature)。
如果为“log2”,则max_features=log2(n_feature)。
如果无,则max_features=n_feature。
自版本1.1以来已弃用:“auto”选项在1.1中已弃用,将在1.3中删除。
注意:在找到节点样本的至少一个有效分区之前,对分割的搜索不会停止,即使它需要有效检查超过max_features的功能。 -
random_state: int, RandomState instance or None, default=None
控制估计器的随机性。即使拆分器设置为“最佳”,功能也总是在每次拆分时随机排列。当max_features -
max_leaf_nodes: int,default=None
用max_leaf_nodes以最佳方式生长一棵树。最佳节点定义为杂质的相对减少。如果为“无”,则叶节点的数量不受限制。 -
min_impurity_declease: float,default=0.0
如果此拆分导致杂质减少大于或等于此值,则节点将被拆分。 -
class_weight: dict, list of dict or “balanced”, default=None
与{class_label:weight}形式的类关联的权重。如果没有,则所有类都应该有一个权重。对于多输出问题,可以按照与y列相同的顺序提供dict列表。
请注意,对于多输出(包括multilabel),应该在其自己的dict中为每个列的每个类定义权重。例如,对于四类multillabel分类,权重应该是[{0:1,1:1},{0:1、1:5},}0:1、1:1},而不是[{1:1}、{2:5}、}3:1}和{4:1}]。
“balanced”模式使用y值自动调整权重,权重与输入数据中的类频率成反比,即n_samples/(n_classes*np.bincount(y))
对于多输出,y的每个列的权重将相乘。
请注意,如果指定了sample_weight,则这些权重将与sample_tweight(通过fit方法传递)相乘。 -
ccp_alpha: non-negative float, default=0.0
用于最小成本复杂性修剪的复杂性参数。将选择成本复杂性最大且小于ccp_alpha的子树。默认情况下,不执行修剪。有关详细信息,请参见最小成本复杂性修剪。
属性:
- classes_: ndarray of shape (n_classes,) or list of ndarray
类标签(单输出问题),或类标签数组列表(多输出问题)。 - feature_importances_: ndarray of shape (n_features,)
返回功能重要性。 - max_features_: int
max_features的推断值。 - n_classes_: int or list of int
类的数量(对于单输出问题),或包含每个输出的类数量的列表(对于多输出问题)。 - n_features_: int
已弃用:属性n_features_在1.0中已弃用,将在1.2中删除。 - n_features_in : int
装配过程中看到的特征数量。 - feature_names_in_: ndarray of shape (n_features_in_,)
配合期间看到的特征名称。仅当X具有全部为字符串的要素名称时才定义。 - n_outputs_: int
执行拟合时的输出数。 - tree_: Tree instance
基础Tree对象。有关tree对象的属性,请参阅帮助(sklearn.tree._tree.tree);有关这些属性的基本用法,请参阅了解决策树结构。

决策树回归器
class sklearn.tree.DecisionTreeRegressor(*, criterion='squared_error', splitter='best', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, ccp_alpha=0.0)[source]¶随机森林(集成学习再学)
 在样本和特征上做随机
在样本和特征上做随机
①Bootstrap,这个奇怪的名字来源于文学作品 The Adventures of Baron Munchausen(吹牛大王历险记),这个作品中的一个角色用提着自己鞋带的方法把自己从湖底下提了上来。因此采用意译的方式,叫做自助法。自助法顾名思义,是从样本自身中再生成很多可用的同等规模的新样本,不借助其他样本数据。这个方法在样本比较小的时候很有用,比如我们的样本很小,但是我们希望留出一部分用来做验证,那如果传统方法做train-validation的分割的话,样本就更小了,bias会更大,这是不希望的。而自助法不会降低训练样本的规模,又能留出验证集(因为训练集有重复的,但是这种重复又是随机的),因此有一定的优势。
至于自助法能留出多少验证,或者说,m个样本的每个新样本里比原来的样本少了多少?可以这样计算:每抽一次,任何一个样本没抽中的概率为 (1-1/N),一共抽了N次,所以任何一个样本没进入新样本的概率为(1-1/N)N。那么从统计意义上来说,就意味着大概有(1-1/N)N比例的样本作为验证集。当N→infinite时,这个值大概是1/e,36.8%。以这些为验证集的方式叫做包外估计(out of bag estimate)。
②Bagging,它的名称来源于(Bootstrap aggregating),意思是自助抽样集成,这种方法将训练集分成m个新的训练集,然后在每个新训练集上构建一个模型,各自不相干,最后预测时我们将这m个模型的结果进行整合,得到最终结果。整合方式就是:分类问题用majority voting,回归用均值。

-
相关阅读:
ppt 作图 如何生成eps格式
elasticsearch查询之keyword字段的查询相关度评分控制
Java多线程进阶——常见的锁策略
Mac根据端口查询进程id的命令
如何防止网络攻击?
java计算机毕业设计晨光文具店进销存系统设计与开发源码+系统+lw文档+mysql数据库+部署
Python 与 MySQL 交互
【面试题解】你了解JavaScript常用的的十个高阶函数么?
精解四大集合框架:List 核心知识总结
基于桶的排序之计数排序
- 原文地址:https://blog.csdn.net/littleyy666/article/details/126961197