-
46、video-nerf
简介
主页:https://video-nerf.github.io/

该方法以单个随机捕获的视频作为输入,学习时空神经辐照场。(上)输入视频的样本帧。(中)从深度图构造的纹理网格渲染的新视图图像。(下)从提出的时空神经辐照场渲染的结果。贡献点
- 从单个单目视频中聚合帧级2.5D表示为全局一致的时空表示
- 使用视频深度监控来解决固有的运动-外观模糊性,并通过跨时间传播颜色和体积密度来约束错位内容。
- 在智能手机拍摄的各种休闲视频上展示了引人注目的自由视点视频渲染体验,保留了运动和纹理细节,同时传达了生动的3D感。
现有的动态NeRF要么学习有变形的静态正则辐射场,要么学习直接受时间影响的动态辐射场,论文是后者,使用动态场景深度来规范训练
实现流程
NeRF公式
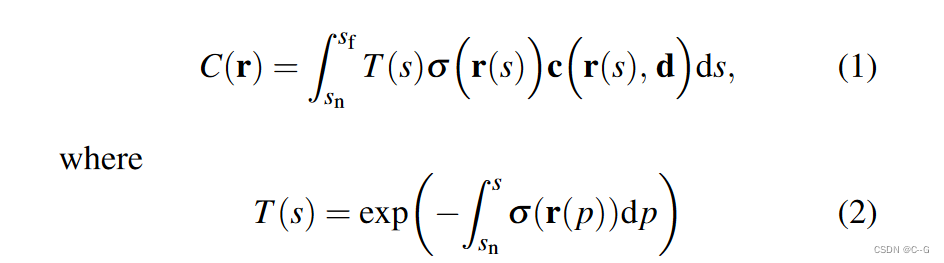
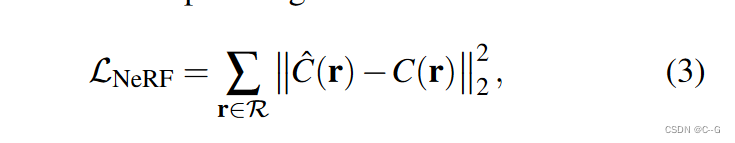
将4D时空辐照场表示为映射时空位置(x,t)到发射颜色和体积密度F:(x,t)→(c,σ)的函数。输入视频表示为RGB-D图像流, I t I_t It: u→(c, d)在离散时间步 t ∈ τ = 1 , 2 , … , N f t∈\tau ={1,2,…, N_f} t∈τ=1,2,…,Nf,其中 u = (u, v) 为二维像素坐标,与之相关的相机标定 P t P_t Pt,对射线进行参数化,使参数 s 表示场景深度
Color reconstruction loss
对每次 t 时的体积渲染图像与相应的输入图像 I t I_t It 之间的差值进行惩罚
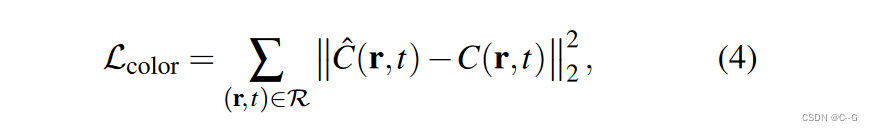
R是一组射线,每条射线都与时间t相关Depth reconstruction loss

(a)经过训练而没有深度损失的模型可以很好地(首先)从原始视点重建图像。然而,在稍微改变视点的情况下,合成图像(第二)由于几何形状不正确(第三)会产生强烈的视觉假象。
(b)用提出的深度损失进行训练,使新的视点没有明显可见的伪影。偏离原始视频的摄像机轨迹时,不正确的几何图形将导致伪影
通过使用输入视频的每帧场景深度(通过视频深度估计方法估计)来约束动态场景表示的时变几何,解决了这种运动外观模糊
通过学习到的场景体积密度估计场景深度,并测量其与输入深度 d t d_t dt 的差值
沿着通过透光率和体积密度调制的光线积累深度值,类似于分层场景表示中的深度组成
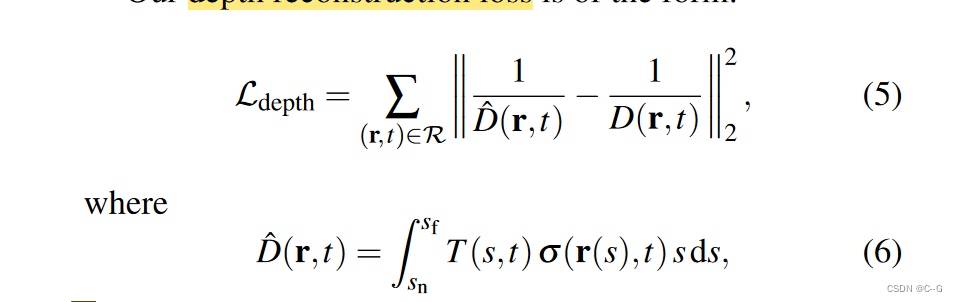
沿射线和D(r)的积分样本深度值Empty-space loss
预测的深度是沿射线的深度值的加权和,在渲染新视图时,有时会看到像雾霾一样的视觉工件,通过在相机和第一个可见场景表面之间留出空间来解决这个问题,对每条射线的非零体积密度测量进行惩罚,直到每条射线不接近于场景深度的 ε = 0.05 ⋅ ( s f − s n ) ε = 0.05·(s_f−s_n) ε=0.05⋅(sf−sn) 的小边界
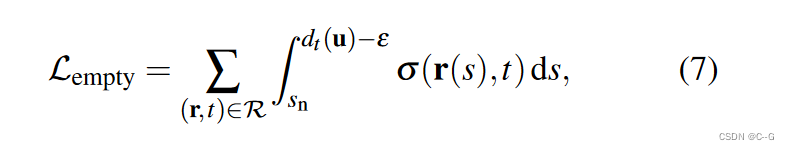
u 表示 r 与像平面在 t 处相交的像素坐标, d t ( u ) d_t(u) dt(u) 表示像素 u 在 t 时刻的场景深度Empty-space loss与Depth reconstruction loss相结合,为在每帧可视场景表面及其周围的表示提供了几何约束,学习到的表示可以产生几何正确的新视图合成
Static scene loss.

静态场景损失处理的是不受颜色和深度重建损失限制的区域,这只处理输入帧(a)中的可见表面。从 t = 40 的角度来看,在 t 1 = 9 和 t 2 = 90 t_1 = 9和t_2 = 90 t1=9和t2=90处渲染两帧。相机在上一行进行平移,在下一行进行缩小。当这些帧从这个新颖的视角呈现出来时,之前隐藏的区域就被消除了。在没有静态场景损失的情况下,它们完全不受约束,容易产生鬼影或雾霾假象,如(b)所示。的静态损失减轻了这些假象。在任何给定时间对输入帧视点隐藏的大部分空间仍然没有受到约束,也就是说,MLP在训练过程中没有将3D位置和时间视为输入查询,论文通过跨时间传播这些部分观察到的内容来约束MLP。这里没有随时间显式地关联曲面,例如使用场景流,而是选择约束曲面区域周围的空间。可以避免由于不可靠的几何估计或在捕获视频中常见的其他图像畸变(如曝光或颜色变化)而导致的场景表面错位
假设世界的每一部分都应该保持静止,除非被观察到,执行这个假设可以防止未被观察到的部分空间完全不受约束,静态场景约束鼓励相同空间位置 x 在两个不同的时间 t 和 t’ 之间的共享颜色和体积密度
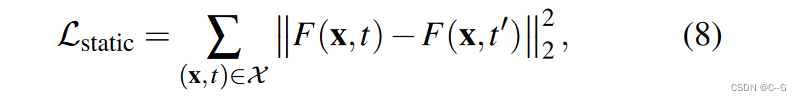
(x,t)和(x,t’)都不接近任何可见的表面,x表示测量损耗的一组采样位置Scene sampling
虽然有颜色、深度和自由空间监督的位置,由体绘制使用的正交显式指示,但可以自由选择应用静态约束的位置
随机绘制另一个与当前时间t不同的时间 t’,并强制MLP在这两个时空位置产生相似的外观和体积密度
当相机运动较大时,这仍然会留下场景的很大一部分不受约束,在场景包围体中统一采样也不是理想的,因为由于透视投影,采样效率非常低(除了特殊情况,如摄像机环绕某个有边界的体积)。
既满足采样效率又满足样本覆盖率的简单解决方案:取所有帧的所有射线上的所有采样点的并集,形成样本池 X,排除了所有比阈值 ε 更接近观察曲面的点,在每次训练迭代中,从这个集合中随机抽取固定数量的采样点,并为每个采样点添加小的随机抖动。在时间 t’ 时,静态场景损失测量也随机选择每个样本位置 x,同时确保结果位置 (x,t’) 不接近任何场景表面
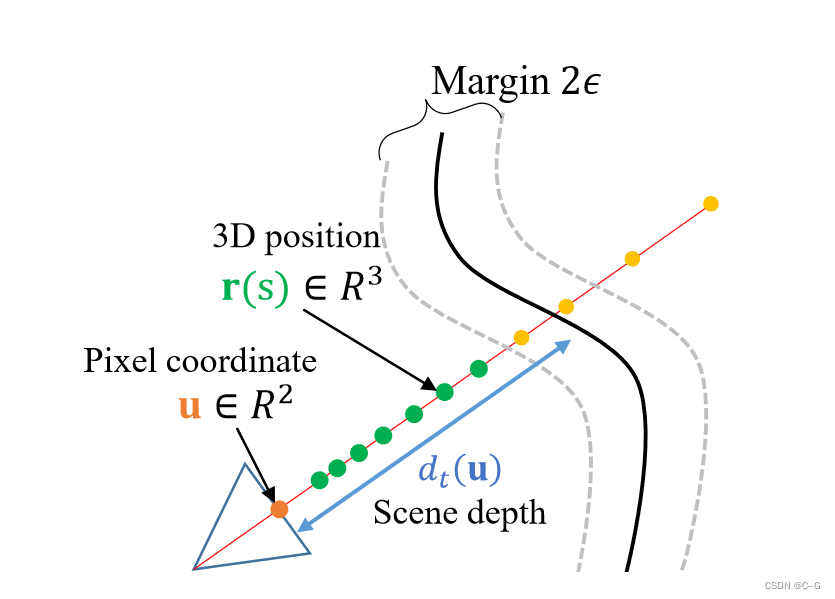
测量三维位置上的空白损失,直到达到估计的场景深度(绿色)。
使用沿光线(绿色和黄色)的所有样本来计算深度和颜色重建损失。
对于静态损耗,从所有输入帧的所有相机光线 ( 在 s ∈ [ z n , z f ] 的范围内 ) (在s∈[z_n, z_f]的范围内) (在s∈[zn,zf]的范围内)所跨空间的并集中对场景进行采样。
排除了除 ε 以外接近任何表面的任何样本。Total loss
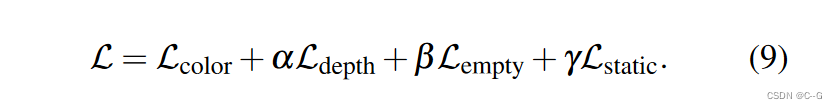
实验证明:选取α = 1, β = 100, and γ = 10效果

-
相关阅读:
多终端云同步文献管理:Zotero+TeraCloud(Windows+Android)
【计网 EMail】计算机网络 EMail协议详解:中科大郑烇老师笔记 (五)
界面组件Telerik WinForm R3 2022,让应用启动变得更酷炫
软件测试面试题:Internet采用哪种网络协议?该协议的主要层次结构?Internet物理地址和IP地址转换采用什么协议?
2022年《财富》世界500强排行榜
数据结构——基于顺序表实现通讯录
MYSQL一站式学习,看完即学完
dijkstra算法+链表储存+优先队列
LabVIEW以编程方式启用IEPE激励
20221129今天的世界发生了什么
- 原文地址:https://blog.csdn.net/weixin_50973728/article/details/126959123