-
扫描型PDF转成可搜索可复制的文字型PDF,使用PDF24 OCR 程序报“下载需要的文件时出现一个错误”
1、PDF工具 -- PDF24
需要找一个将扫描型的PDF转换成可搜索可复制的PDF文件的工具,搜到的大部分工具我都试用了,要么转换出来样式不行,要么收费。然后找到了一个下图所示的PDF24 的工具,PDF24提供很多精心裁剪的针对特定问题的工具。所有的PDF工具 - 100%免费 - PDF24 Tools

其中的PDF 文本识别工具可将扫描型的PDF转换成可搜索可复制的PDF文件。PDF24提供在线和离线两种方式。
使用PDF 文本识别工具 ,在线转换文件 通过OCR识别文本 - 简便,在线,免费 - PDF24 Tools

下载离线版本的PDF24 Creator PDF24 Creator - 下载 - 100%免费 - PDF24 Tools

网页版的可以正常使用,推荐使用网页版的。
2、PDF24 OCR程序报错
使用离线版本的PDF24 OCR时出现问题,本文主要记录如何解决下图的问题。

本文使用的是11.4.0的私人版本


在手册中找到关于pdf24-Ocr.exe下的所有语言文件的本地安装方法
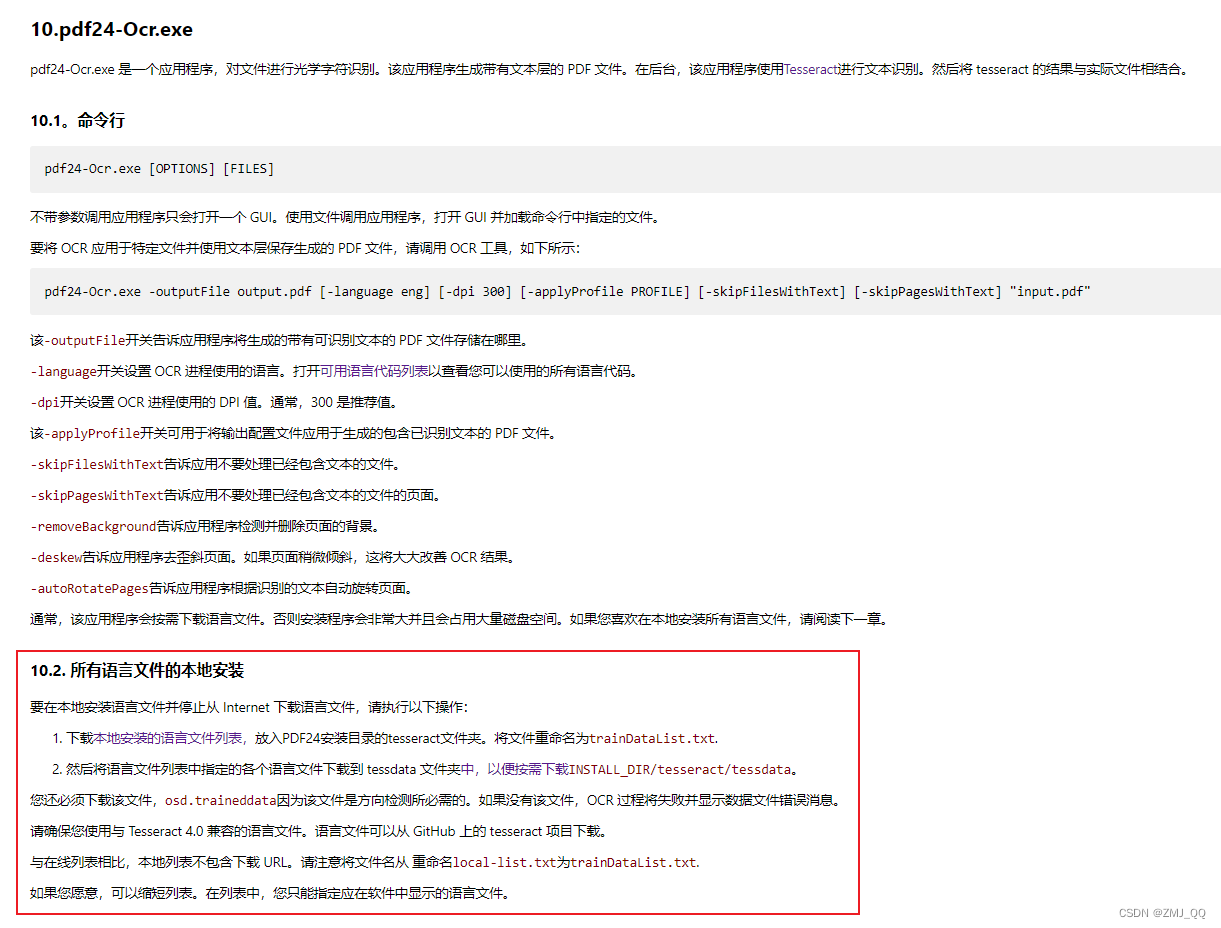
解决步骤
所需文件下载地址 :https://download.csdn.net/download/ZMJ_QQ/87361516

1、将
trainDataList.txt放入PDF24安装目录的tesseract文件夹。(官网下载地址https://creator.pdf24.org/tesseract/4.0/traindata/local-list.txt
2、将tessdata-master文件夹下的所有文件复制到 tessdata 文件夹下。

另外手册中说的 osd.traineddata文件就在解压的语言包中,不需要找


请确保您使用与 Tesseract 4.0 兼容的语言文件。语言文件可以从 GitHub 上的 tesseract 项目下载。
贴一个github上的项目地址(方法测过了,文件下载失败。如果后期还是无法下载可以使用上文给出的文件)GitHub - tesseract-ocr/tessdata: Trained models with support for legacy and LSTM OCR engine
3、完成上面两步后再重新打开PDF24 OCR,添加文件后点击开始后即可正常使用,如下图所示

文章可能写的啰嗦,如果后期我的语言文件不生效,可以到官方手册中查找语言文件下载的方法。
-
相关阅读:
JavaScript高级知识-this的指向
Linux常用命令
MAC如何在根目录创建文件
【李宏毅】深度学习-CNN(影像辨识为例)
微信小程序跳转到其他小程序
企业实践开源的动机
【100天精通Python】Day70:Python可视化_绘制不同类型的雷达图,示例+代码
关于滑块验证码的问题
Mac系统补丁管理
英语语法 - 宾语从句
- 原文地址:https://blog.csdn.net/ZMJ_QQ/article/details/126952422