-
Zookeeper
1 概述
Zookeeper是一个开源的分布式的,为分布式框架提供协调服务的Apache项目。
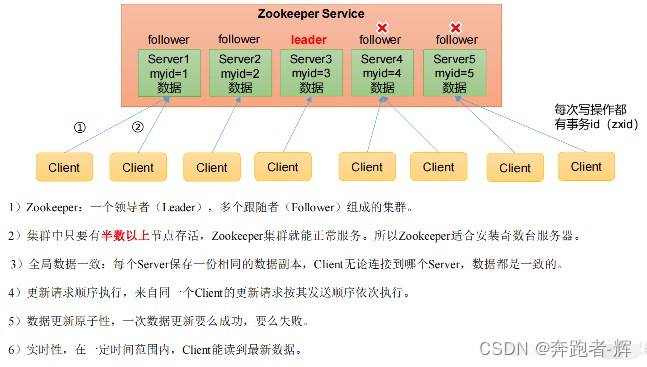
2 Zookeeper工作机制

3 Zookeeper特点
4 选举机制 (重点)
① 半数机制:集群中只要有半数以上机器存活,集群就能正常服务。所以Zookeeper适合安装奇数台服务器。
② Zookeeper虽然在配置文件中并没有指定Master和Slave。但是,Zookeeper工作时,是有一个节点为Leader,其他则为Follower,Leader是通过内部的选举机制临时产生的。
③ 以一个简单的例子来说明整个选举的过程。
假设有五台服务器组成的Zookeeper集群,它们的id从1-5,同时它们都是最新启动的,也就是没有历史数据,在存放数据量这一点上,都是一样的。假设这些服务器依序启动,来看看会发生什么。(1) Zookeeper选举机制——第一次启动

(2) Zookeeper选举机制——非第一次启动

5 选举机制中涉及到的核心概念
(1) Server id(或sid):服务器ID
比如有三台服务器,编号分别是1,2,3。编号越大在选择算法中的权重越大,比如初始化启动时就是根据服务器ID进行比较。
(2) Zxid:事务ID
服务器中存放的数据的事务ID,值越大说明数据越新,在选举算法中数据越新权重越大。
(3) Epoch:逻辑时钟
也叫投票的次数,同一轮投票过程中的逻辑时钟值是相同的,每投完一次票这个数据就会增加。
(4) Server状态:选举状态
LOOKING: 竞选状态。
FOLLOWING:随从状态,同步leader状态,参与投票。
OBSERVING:观察状态,同步leader状态,不参与投票。
LEADING: 领导者状态。
6 监听原理
客户端注册监听它关心的目录节点,当目录节点发生变化(数据改变、节点删除、子目
录节点增加删除)时,ZooKeeper 会通知客户端。监听机制保证 ZooKeeper 保存的任何的数
据的任何改变都能快速的响应到监听了该节点的应用程序。
-
相关阅读:
回溯 -- 21天学习挑战赛第一天
关于web前端大作业的HTML网页设计——我的班级网页HTML+CSS+JavaScript
定时器按钮-->笔记
Java读取Excel并生成Word&PDF
【Pygame实战】打扑克牌嘛?赢了输了?这款打牌游戏,竟让我废寝忘食。
编程学:关于同类词的等长拼写问题
java---网络初始
OOP课第二阶段总结
更新操作及自动填充
大型语言模型与知识图谱融合方法概述
- 原文地址:https://blog.csdn.net/index_test/article/details/126956611