-
MindSpore自定义数据增强报错【args should be Numpy narray.Got<;class tuple>;】
MindSpore可以自定义数据增强算子,切入到数据流水线中对数据进行处理
相关的API可以参考:mindspore.dataset.map
自定义函数写的不对的时候会出现这个错误:

Exception thrown from PyFunc. TypeError: args should be Numpy narray. Got
. 打开脚本分析一下:
自定义的Crop操作
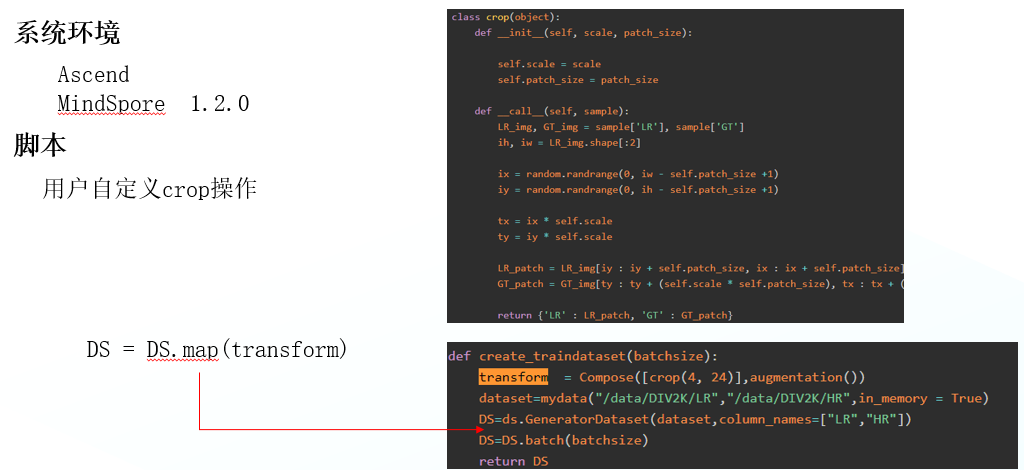
原因分析:
GeneratorDataset中存在两个数据列”LR”, “HR”,但是Crop类的__call__函数中除self外只有r入参sample,导致传入的数据类型转为tuple,与期望的numpy.ndarray不符合。
输入数据列(2个数据列):

数据处理类的定义(仅接受单个数据列):

解决办法:
- 修改__call__的入参为个数,除self外入参个数需要与input_columns中的参数个数保持一致,忽略input_columns时默认为全部的数据列。
可以参考下面修改成__call__方法的入参数量,同时确保__call__方法返回的是numpy组成的tuple对象

其他错误相关帖:
-
相关阅读:
org.apache.flink.table.api.TableException: Sink does not exists
HOOPS/QT集成指南
基于jquery 实现导航条高亮显示的两种方法
echarts手动触发气泡的显示和隐藏
路由vue-router(二)
第一章 Redis基础
云原生架构体系
动态规划题: 统计每个月兔子的总数
JS系列1-布尔陷阱以及如何避免
小程序 target 与 currentTarget(详细)
- 原文地址:https://blog.csdn.net/Kenji_Shinji/article/details/126957131