-
【数据结构与算法】Set 和 Map 接口
🔥 本文由 程序喵正在路上 原创,CSDN首发!
💖 系列专栏:数据结构与算法
🌠 首发时间:2022年9月20日
🦋 欢迎关注🖱点赞👍收藏🌟留言🐾
🌟 一以贯之的努力 不得懈怠的人生Set 和 Map
集合 (set) 是一个用于存储和处理重复元素的高效数据结构。而映射表 (map) 类似于目录,提供了使用键值快速查询和获取值的功能

Set接口
我们可以使用集合的三个具体类 HashSet、LinkedHashSet、TreeSet 来创建集合。Set 接口扩展了 Collection 接口,它没有引入新的方法或常量,只是规定 Set 的实例不能包含重复的元素
实现 Set 的具体类必须确保不能向这个集合添加重复的元素。也就是说,在一个集合中,不存在元素 el 和 e2 , 使得
e1. equals(e2)的返回值为 trueAbstractSet 类继承 AbstractCollection 类并部分实现 Set 接口,提供了 equals 方法和hashCode 方法的具体实现。一个集合的散列码是这个集合中所有元素散列码的和。由于 AbstractSet 类没有实现 size 方法和 iterator 方法,所以 AbstractSet 类是一个抽象类
HashSet
HashSet 类的构造方法:
HashSet()HashSet(c: Collection)HashSet(initialCapacity: int)HashSet(initialCapacity: int, loadFactor: float)
HashSet 类是一个实现了 Set 接口的具体类,可以使用它的无参构造方法来创建空的散列集,也可以由一个现有的合集创建散列集
默认情况下,初始容量为 16 ,而负载系数是 0 .75 。如果我们知道集合的大小,就可以在构造方法中指定初始容量和负载系数,没有指定就使用默认的设置,负载系数的值在 0. 0 ~ 1 .0 之间
HashSet 类可以用来存储互不相同的任何元素。考虑到效率的因素,添加到散列集中的对象必须以一种正确分散散列码的方式来实现 hashCode 方法
import java.util.*; public class TestHashSet { public static void main(String[] args) { Set<String> set = new HashSet<>(); set.add("red"); set.add("green"); set.add("blue"); set.add("green"); //green被添加了2次,但是只会存储1次 set.add("cyan"); System.out.println(set); } }运行结果如下:

LinkedHashSet
LinkedHashSet 用一个链表实现来扩展 HashSet 类,它支持对集合内的元素排序。HashSet 中的元素是没排序的,而 LinkedHashSet 中的元素可以按照它们插入集合的顺序提取
LinkedHashSet 对象可以使用它的 4 个构造方法之一来创建,这些构造方法类似于 HashSet 的构造方法
LinkedHashSet 类的构造方法:
LinkedHashSet()LinkedHashSet(c: Collection)LinkedHashSet(initialCapacity: int)LinkedHashSet(initialCapacity: int, loadFactor: float)
import java.util.*; public class TestLinkedHashSet { public static void main(String[] args) { Set<String> set = new LinkedHashSet<>(); set.add("red"); set.add("green"); set.add("blue"); set.add("green"); //green被添加了2次,但是只会存储1次 set.add("cyan"); set.add("purple"); System.out.println(set); } }运行结果如下:

SortedSet 和 TreeSet
SortedSet 是 Set 的一个子接口,它可以确保集合中的元素是有序的。另外,它还提供方法 first() 和 last() 以返回集合中的第一个元素和最后一个元素,以及方法 headSet(toElement) 和 tailSet(fromElement) 以分别返回集合中元素小于 toElement 和大于或等于 fromElement 的那一部分
NavigableSet 扩展了 SortedSet ,并提供导航方法 lower(e)、floor(e)、ceiling(e) 和 higher(e) 以分别返回小于、小于或等于、大于或等于以及大于一个给定元素的元素。如果没有这样的元素,方法就返回 null 。方法 pollFirst() 和 pollLast() 会分别删除和返回树形集中的第一个元素和最后一个元素
TreeSet 类的构造方法:
TreeSet()TreeSet(c: Collection)TreeSet(comparator: Comparator)TreeSet(s: SortedSet)
TreeSet 实现了 SortedSet 接口。为了创建 TreeSet 对象,可以使用上面的几个构造方法。只要对象是可以互相比较的,就可以将它们添加到一个树形集 (TreeSet) 中。
元素可以有两种方法进行比较,即使用 Comparable 接口或 Comparator 接口
import java.util.*; public class TestTreeSet { public static void main(String[] args) { Set<String> set = new HashSet<>(); set.add("Beijing"); set.add("London"); set.add("Paris"); set.add("New York"); set.add("San Francisco"); TreeSet<String> treeSet = new TreeSet<>(set); System.out.println("Sorted tree set: " + treeSet); //使用SortedSet接口的方法 System.out.println("first(): " + treeSet.first()); System.out.println("last(): " + treeSet.last()); System.out.println("headSet(\"Paris\"): " + treeSet.headSet("Paris")); System.out.println("tailSet(\"Paris\"): " + treeSet.tailSet("Paris")); //使用Navigable接口的方法 System.out.println("lower(\"P\"): " + treeSet.lower("P")); System.out.println("higher(\"P\"): " + treeSet.higher("P")); System.out.println("floor(\"P\"): " + treeSet.floor("P")); System.out.println("ceiling(\"P\"): " + treeSet.ceiling("P")); System.out.println("pollFirst(): " + treeSet.pollFirst()); System.out.println("pollLast(): " + treeSet.pollLast()); System.out.println("New tree set: " + treeSet); } }运行结果如下:

Set 与 List 的性能比较
在无重复元素进行排序方面,集合比线性表更加高效,但线性表中元素可以通过索引访问。而集合不支持索引,要遍历集合中的所有元素,可使用 foreach 循环
如果想测试一个元素是否在集合或者线性表中,集合比线性表更高效
Map接口
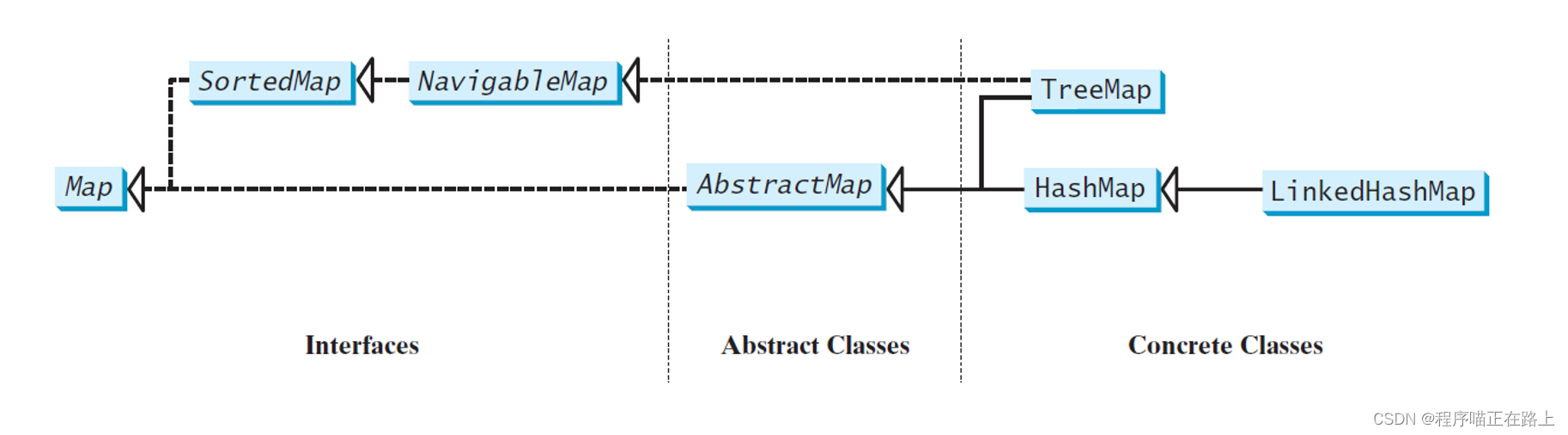
映射表 ( map ) 是一种依照键值对存储元素的容器。它提供了通过键快速获取、删除和更新键/值对的功能。映射表将值和键一起保存。键很像下标。在 List 中,下标是整数。而在 Map 中, 键可以是任意类型的对象。映射表中不能有重复的键,每个键都对应一个值,一个键和它的对应值构成一个条目并保存在映射表中
我们可使用三个具体的类来创建一个映射表,它们分别是 HashMap 、LinkedHashMap 、TreeMap
Map 接口提供了查询、更新和获取合集的值和合集的键的方法,具体如下表所示
方法 描述 clear() : void从该映射表中删除所有条目 containsKey(key: Object) : boolean如果该映射表包含了指定键的条目,则返回 true containsValue(value: Object) : boolean如果该映射表将一个或者多个键映射到指定值,则返回 true entrySet() : Set返回一个包含了该映射表中条目的集合 get(key: Object) : V返回该映射表中指定键对应的值 isEmpty() : boolean如果该映射表没有包含任何条目,则返回 true keySet() : Set返回一个包含该映射表中所有键的集合 put(key: K, value: V) : V将一个条目放入该映射表中 putAll(m: Map) : void将 m 中的所有条目添加到该映射表中 remove(key: Object) : V删除指定键对应的条目 size() : int返回该映射表中的条目数 values() : Collection返回该映射表中所有值组成的合集 Entry接口
我们可以使用方法 keySet() 来获得一个包含映射表中键的集合,也可以使用方法 values() 获得一个包含映射表中值的合集。方法 entrySet() 会返回一个所有条目的集合,这些条目是 Map.Entry
Entry 接口的方法:
方法 描述 getKey() : K返回该条目的键 getValue() : V返回该条目的值 setValue(value: V) : void将该条目中的值赋以新的值 HashMap 和 TreeMap

对于定位一个值、插入一个条目以及删除一个条目而言, HashMap 类是高效的
LinkedHashMap 类用链表实现来扩展 HashMap 类,它支持映射表中条目的排序。HashMap 类中的条目是没有顺序的,但是在 LinkedHashMap 中,元素既可以按照它们插入映射表的顺序排序,也可以按它们被最后一次访问时的顺序,从最早到最晚排序
TreeMap 类在遍历排好顺序的键时是很高效的。键可以使用 Comparable 接口或 Comparator 接口来排序。如果使用它的无参构造方法创建一个 TreeMap 对象,假定键的类实现了 Comparable 接口,则可使用 Comparable 接口中的 compareTo 方法对映射表内的键进行比较。要使用比较器,必须使用构造方法
TreeMap(Comparator comparator)来创建有序映射表,这样该映射表中的条目就能使用比较器中的 compare 方法进行排序单词计数
编写一个程序,以统计一个文本中单词的出现次数,然后按照单词的字母顺序显示这些单词以及它们对应的出现次数
代码实现
import java.util.*; public class CountOccurrenceOfWords { public static void main(String[] args) { // Set text in a string String text = "Good morning. Have a good class. Afternoon. Have a good time. " + "Have a good visit. Have fun!"; // Create a TreeMap to hold words as key and count as value Map<String, Integer> map = new TreeMap<>(); String[] words = text.split("[ \n\t\r.,;:!?(){}]"); for (String word : words) { String key = word.toLowerCase(); if (key.length() > 0) { if (!map.containsKey(key)) { map.put(key, 1); } else { int value = map.get(key); value++; map.put(key, value); } } } // Get all entries into a set Set<Map.Entry<String, Integer>> entrySet = map.entrySet(); // Get key and value from each entry for (Map.Entry<String, Integer> entry : entrySet) System.out.println(entry.getKey() + "\t" + entry.getValue()); } }运行结果

Java 中的通用排序方法
高级语言都提供排序方方法,C语言 有 qsort() 函数,C++ 有 sort() 函数,Java 语言有 Arrays 类中的静态方法 sort。用这些排序时,还可以使用自己的排序规则
Java API 对 Arrays 类的说明是:此类包含用来操作数组(比如排序和搜索)的各种方法
说明:
(1) Arrays 类中的 sort() 使用的是 “经过调优的快速排序法”
(2) 比如 int[]、double[]、char[] 等基本数据类型的数组,Arrays 类之只是提供了默认的升序排列,没有提供相应的降序排列方法
(3) 要对基础类型的数组进行降序排序,需要将这些数组转化为对应的封装类数组,如 Integer[]、Double[]、Character[] 等,对这些类数组进行排序。其实还不如先进行升序排序,自己在转为降序
用默认的升序对数组排序
函数原型:
static void sort(int[] a)对指定的 int 型数组按数字升序进行排序static void sort(int[] a, int fromIndex, int toIndex)对指定 int 型数组的指定范围按数字升序进行排序import java.util.Arrays; public class ArraysSort { public static void main(String args[]) { int[] a = {1, 4, -1, 5, 0}; Arrays.sort(a); for (int i = 0; i < a.length; i++) System.out.print(a[i] + " "); } }
对复合数据类型排序
函数原型:
(1)
public static根据指定比较器产生的顺序对指定对象数组进行排序void sort(T[] a,Comparator c) (2)
public static根据指定比较器产生的顺序对指定对象数组的指定范围进行排序void sort(T[] a,int fromIndex,int toIndex,Comparator c) 说明:这个两个排序算法是 “经过调优的合并排序” 算法
import java.util.Arrays; import java.util.Comparator; public class ArraysSort { Point[] arr; ArraysSort() { arr = new Point[4]; //定义对象数组arr,并分配存储的空间 for (int i = 0; i < 4; i++) arr[i] = new Point(); } public static void main(String[] args) { ArraysSort sort = new ArraysSort(); //初始化,对象数组中的数据 sort.arr[0].x = 2; sort.arr[0].y = 1; sort.arr[1].x = 2; sort.arr[1].y = 2; sort.arr[2].x = 1; sort.arr[2].y = 2; sort.arr[3].x = 0; sort.arr[3].y = 1; Arrays.sort(sort.arr, new MyComprator()); //使用指定的排序器排序 for (int i = 0; i < 4; i++) //输出排序结果 System.out.println("(" + sort.arr[i].x + "," + sort.arr[i].y + ")"); } } class Point { int x; int y; } //比较器,x坐标从小到大排序;x相同时,按照y从小到大排序 class MyComprator implements Comparator { public int compare(Object arg0, Object arg1) { Point t1 = (Point) arg0; Point t2 = (Point) arg1; if (t1.x != t2.x) return t1.x > t2.x ? 1 : -1; else return t1.y > t2.y ? 1 : -1; } }
-
相关阅读:
[BJDCTF2020]Mark loves cat
Linux内核基础 - list_splice_tail_init函数详解
【前端开发】前端开发深度解析:HTML、CSS、JavaScript与Vue.js
吃透Chisel语言.38.Chisel实战之以FIFO为例(三)——几种FIFO的变体的Chisel实现
C基础知识-结构体(详解)
Java中transient关键字的详细总结
2022年数维杯国际大学生数学建模挑战赛C题如何利用大脑结构特征和认知行为特征诊断阿尔茨海默病解题过程
defer面试题,你能答对几题?
Cppcheck 详细介绍
LeViT:Facebook提出推理优化的混合ViT主干网络 | ICCV 2021
- 原文地址:https://blog.csdn.net/weixin_62511863/article/details/126911028