-
地质学中 P-A 图(PA图)讲解并使用python实现 || plt绘图实现,一个坐标图共享两个左右y轴
一、P-A图
P-A图由文章《Fuzzification of continuous-value spatial evidence for mineral prospectivity mapping》首次提出。
如下图d 所示:
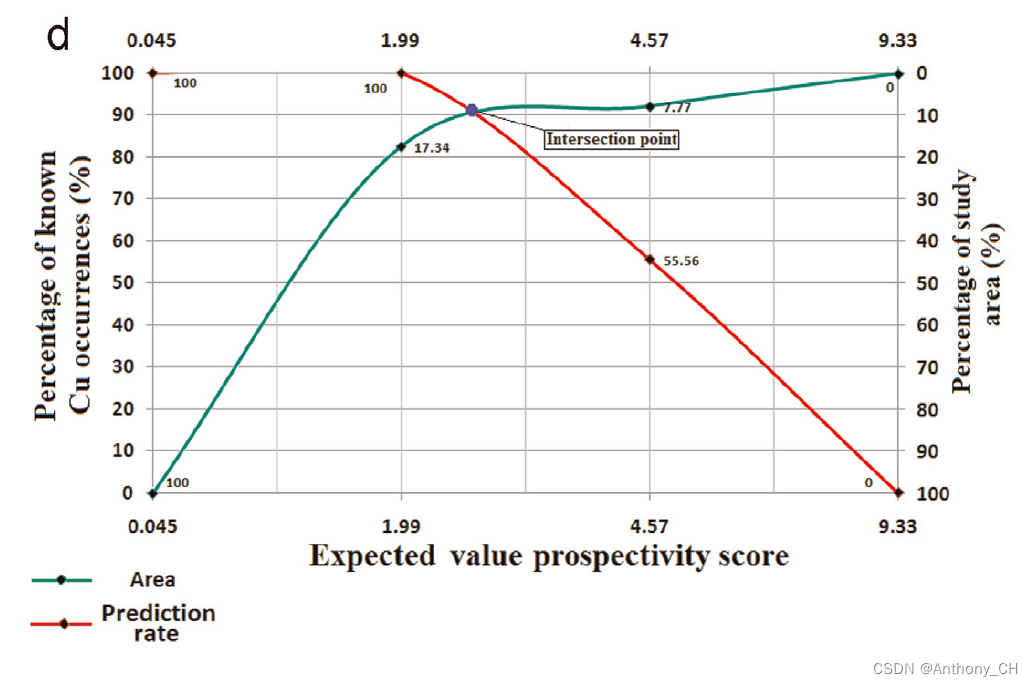
原文中对P-A图的说明
在本文中,我们用相应的远景等级划定的已知矿点的百分比和相应的远景等级所占的面积(相对于总研究区而言)相互结合,组成一个图。因此,通过将已知矿床的位置叠加到分类的远景图上,根据已知矿床与不同远景等级的关联(如Carranza等,2005;Porwal等,2003,2004,2006;Yousefi等,2012,2013,2014),考虑其相对于被研究区域总面积的占用面积,对模型进行评估,得到图d。这些图被称为预测-面积(P-A)图,分别基于图c,针对模糊前景模型和期望值前景模型绘制。
图c:
P-A图的含义在图d中,两条曲线的交点,即对应于远景等级的已知矿点预测率曲线和对应于远景等级的占用面积百分比曲线,是评价和比较模糊远景模型和期望值远景模型的标准。这是因为如果一个交点在P-A图中出现在较高的位置,它所描绘的是一个包含较多矿藏的较小区域。因此,在这样一个较小的区域内,"更容易 "找到未被发现的矿床类型。交点越高,则更优先地进一步勘探,就越具有高价值的目标区域。
我的理解:
对整个研究区域我们有已知的矿区(正样本),也有未知的矿区,使用神经网络模型对这些矿区预测会得到每一个矿区的成矿概率(0~1之间的小数,一般大于0.5判定为有矿)。改变分类阈值,从0到1,每次以0.1为步长增加,大于阈值判定为有矿(不再是固定的0.5)。那么每次改变阈值算出一个 正样本分类正确 / 已知正样本总数 正确分类百分比,同时算出 大于阈值所占的面积/总面积 ;得到这两个数后,就可以画出P-A图
二、python 绘制
predictionClaCorPer = [] # 保存 正样本分类正确 / 已知正样本总数 AreaClaCorPer = [] # 保存 大于阈值所占的面积/总面积 # 坐标样式 custom_y_left = [] for i in range(11): custom_y_left.append(str(i*10)+'%') custom_y_right = custom_y_left[::-1] # 将custom_y_left的顺序逆置 ''' custom_y_right: ['100%', '90%', '80%', '70%', '60%', '50%', '40%', '30%', '20%', '10%', '0%'] custom_y_left: ['0%', '10%', '20%', '30%', '40%', '50%', '60%', '70%', '80%', '90%', '100%'] ''' # 设置画布大小 7×7 fig, ax1 = plt.subplots(figsize=(8, 8), dpi=100) # 设置网格线 ax1.grid(axis='both', linestyle='-.') # 设置左边的 y轴 ax1.plot(np.linspace(0, 1.0, 101), predictionClaCorPer, color="red", alpha=0.5, label="Prediction rate",linewidth= 2) ax1.set_yticks(np.linspace(0, 100, 11), custom_y_left) # 设置左边 y轴刻度 plt.ylim(0, 100) # 设置y轴显示刻度 0~100 ax1.set_xticks(np.linspace(0, 1.0, 11)) # 设置共享 x轴刻度 ax1.set_xlabel('Prospectivity score', fontdict={'size': 16}) ax1.set_ylabel('Percentage of known mine occurrences', fontdict={'size': 16}) # 设置右边的 y轴,与ax1共享同一个 x轴 ax2 = ax1.twinx() ax2.set_yticks(np.linspace(100, 0, 11),custom_y_right) # 设置右边 y轴刻度 plt.ylim(0, 100) # 设置y轴显示刻度 0~100 ax2.invert_yaxis() # 将右边 y轴刻度逆置 ax2.set_ylabel('Percentage of study area', fontdict={'size': 16}) ax2.plot(np.linspace(0, 1.0, 101), AreaClaCorPer, color="green", label="Area",linewidth=2) fig.legend(loc=4, bbox_to_anchor=(1, 1), bbox_transform=ax1.transAxes) plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
结果图:
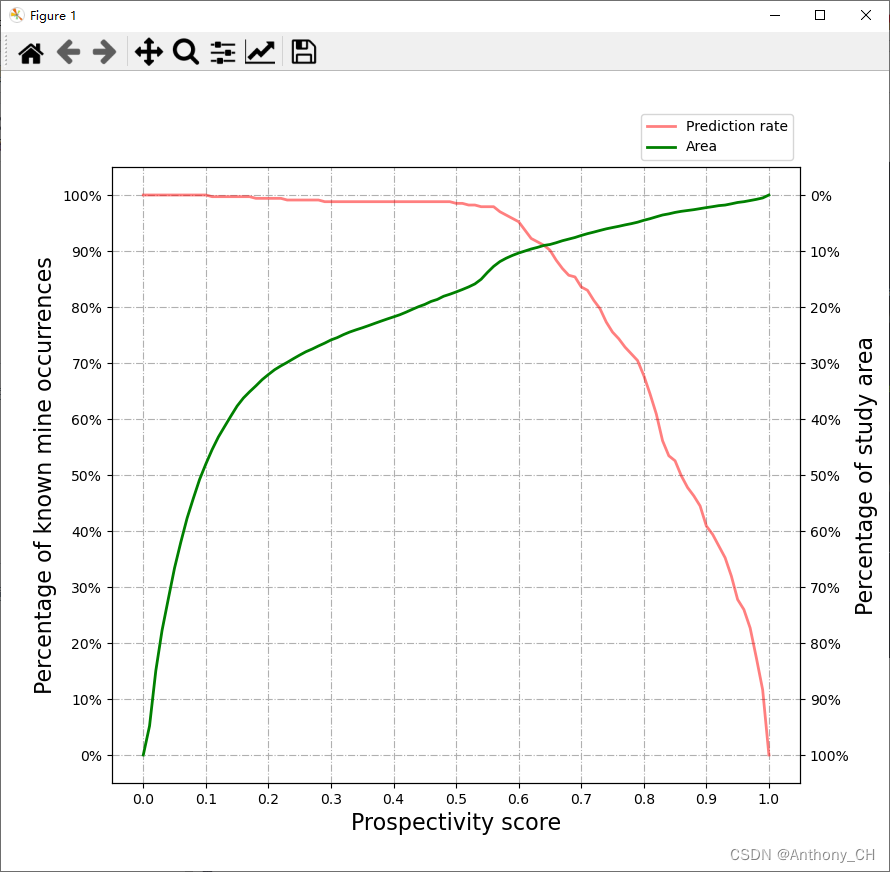
-
相关阅读:
tomcat注册为服务
Log4j日志级别及使用规范
根据经纬度坐标获得省市区县行政区划城市名称,自建数据库 java python php c# .net 均适用
含文档+PPT+源码等]精品基于PHP实现的计算机信息管理学院网站[包运行成功]计算机PHP毕业设计项目源码
基于遗传算法的自主式水下潜器路径规划问题(Matlab代码实现)
网络安全(黑客)自学
代码随想录算法训练营第八天|二叉树(截止到左叶子之和)
一个在使用react时突然遇到的问题
十天学完基础数据结构-第六天(树(Tree))
pip list 和 conda list的区别
- 原文地址:https://blog.csdn.net/qq_56039091/article/details/126794380