-
【Pytorch深度学习实战】(12)神经风格迁移(Neural Style Transfer)
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】

🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
神经风格迁移(Neural Style Transfer)
Neural Style Transfer认为画家的作品包含两部分内容——内容(Content)和风格(Style),而拍摄的照片只有内容。我们人类是很容易可以识别一幅画的内容同时也能识别其风格,也就是说我们可以把一幅画的内容和风格分割开来。
深度卷积网络通过层次化的表示,每一层建立在前一层的基础上,因此逐层学习到越来越高层,越来越抽象的特征。
如下图所示,在下面的内容重建(Content Reconstruction)部分,我们发现底层的网络可以重建出原始图像的细节,而到高层(比如第五层)网络学到的是更加高层和抽象的特征,因此无法重建细节。这是符合我们的期望的——高层的网络丢弃掉了和识别物体无关的一些细节,它们更加关注图片的内容和而不是像素级的细节。这使得它的识别会更加准确。因此我们也可以把高层的特征叫做内容特征(Content Features)。
那风格(Style)怎么提取出来呢?我们可以认为高层网络的每一个Filter都提取了一种特征,从内容的角度来说它们是不同的。而风格是于具体内容无关的一种作者个性化的特征,因此它是存在于不同的Filter之中的。换句话说就是,作者的风格是一致的,不管Filter的内容是什么,都会有风格特征包含其中。因此提取风格就要找不同Filter的共同点。具体来说,它是通过计算同一层的Filter的相关性来提取风格特征的。如下图的上半部分所示,通过计算同一层Filter的相关性,我们可以提取多种不同尺度(scale)的风格特征。

通过上面的方式,给定一幅画(比如梵高的作品),我们可以提取其风格特征,再给定一张风景照片(没有风格),我们可以把风格特征融合到这种风景照片中,这就是所谓的Neural Style Transfer。如下图所示,左图是原始的风景照片,右图是混入了毕加索风格后的照片,右图的左下是用于提取风格的毕加索的作品。

下面我们来介绍Neural Style Transfer的具体实现方法。给定一副画和一张照片,我们可以用卷积神经网络提取画里的风格特征和照片的内容特征。这就是我们期望得到的风格和内容,那怎么把它们两张混合起来呢?风格和内容并不是同一种东西,不能颜色那样直接混合。本文使用的是用梯度下降的方法逐步修改图像的方法。
首先我们需要定义两个Loss——内容的Loss和风格的Loss。或者说给定两个内容(特征),我们可以计算它们的相似度;给定两个风格(特征),我们也可以计算它们的相似度。有了这两个Loss之后,理论上我们可以”遍历”所有可能的图像(实际不可能,比如28x28的灰度图,理论上有2256>10752256>1075个不同图像),然后分别用神经网络提取其内容和风格特征,然后计算它们和我们想要的内容和风格特征的Loss,选择最小的那个。当然这两个Loss不可能同时为零,那么我们需要选择它们的加权和较小的。如果我们期望内容更相似,那么我们可以求和时给内容Loss更大的权重;而如果我们期望风格更相似,那么可以给风格Loss更大的权重。
但是上面的方法只是理论上的,实际是不可能这样做的。下面我们介绍实际可行的做法。
我们把照片再次输入神经网络,当然可以同时计算这个照片的风格和内容,显然这个时候内容就是我们想要的,但是风格完全不同。显然这个时候是有Loss的(内容Loss是零但是风格Loss很大)。我们可以把图片看成变量(参数),而神经网络的参数是固定的。我们可以把Loss看成是图片的函数,因此我们可以使用梯度下降的方法求Loss对每一个像素的梯度,然后微调每一个像素使得Loss变小。
最后剩下的问题就是怎么定义内容特征和风格特征并且定义内容Loss和风格Loss了。
首先我们介绍一些论文中用到的符号。我们假设第l个卷积层有NlNl个Filter(Feature map),它的大小MlMl是Feature Map的width x height。第l层一共有Nl×MlNl×Ml个输出,我们把它记为矩阵Fl∈RNl×MlFl∈RNl×Ml。因此FlijFijl表示第i个Feature Map的第j个元素(我们把二维的Feature Map矩阵展开成一共一维的向量)。
有了FlijFijl,我们可以定义内容Loss如下:

其中p⃗ p→是提供内容的图片,而jx⃗ jx→是当前正在生成的图片。FlFl是x⃗ x→对应的第l层特征矩阵,而PlPl是原始图片p⃗ p→对应的特征矩阵。为了得到风格特征,我们需要求第l层所有特征矩阵的Gram矩阵(相关矩阵)GlGl:

Gram矩阵GlGl的大小Nl×NlNl×Nl,计算相关(Correlation)是统计和信号处理中的常见技巧。有了GlGl之后,我们也可以定义两个照片风格的Loss:
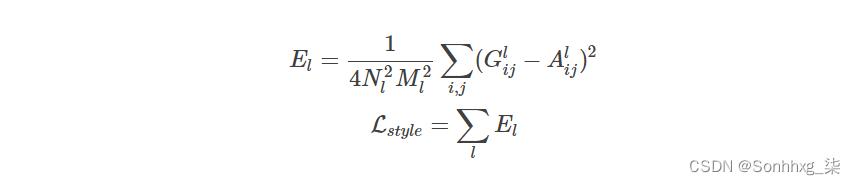
其中GlGl和AlAl是x⃗ x→和p⃗ p→的Gram矩阵。最后我们定义总的Loss:

神经风格转移是一种使用 CNN 将一张图像的内容与另一张图像的风格相结合的算法。给定一个内容图像和一个风格图像,目标是生成一个目标图像,使与内容图像的内容差异和与风格图像的风格差异最小化。
输入图像:


输出图像:

内容丢失
为了最小化内容差异,我们将内容图像和目标图像分别前向传播到预训练的VGGNet,并从多个卷积层中提取特征图。然后,更新目标图像以最小化内容图像的特征图与其特征图之间的均方误差。
风格损失
在计算内容损失时,我们将风格图像和目标图像前向传播到 VGGNet 并提取卷积特征图。为了生成与风格图像的风格相匹配的纹理,我们通过最小化风格图像的 Gram 矩阵和目标图像的 Gram 矩阵之间的均方误差来更新目标图像(特征相关性最小化)。请参阅此处了解如何计算样式损失。
需要下载的库:
库名 用途 argparse python用于解析命令行参数和选项的标准模块,用于代替已经过时的optparse模块。 torch PyTorch是一个优化的张量库,主要用于使用gpu和cpu的深度学习应用程序。 torchvision 独立于pytorch的关于图像操作的一些方便工具库。 Pillow Pillow 是 Python3 最常用的图像处理库。 神经风格迁移Pytorch的实现
- from __future__ import division
- from torchvision import models
- from torchvision import transforms
- from PIL import Image
- import argparse
- import torch
- import torchvision
- import torch.nn as nn
- import numpy as np
- # 设备配置
- device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
- def load_image(image_path, transform=None, max_size=None, shape=None):
- """加载图像并将其转换为tensor张量。"""
- image = Image.open(image_path)
- if max_size:
- scale = max_size / max(image.size)
- size = np.array(image.size) * scale
- image = image.resize(size.astype(int), Image.ANTIALIAS)
- if shape:
- image = image.resize(shape, Image.LANCZOS)
- if transform:
- image = transform(image).unsqueeze(0)
- return image.to(device)
- class VGGNet(nn.Module):
- def __init__(self):
- """选择 conv1_1 ~ conv5_1 激活图。"""
- super(VGGNet, self).__init__()
- self.select = ['0', '5', '10', '19', '28']
- self.vgg = models.vgg19(pretrained=True).features
- def forward(self, x):
- """提取多个卷积特征图。"""
- features = []
- for name, layer in self.vgg._modules.items():
- x = layer(x)
- if name in self.select:
- features.append(x)
- return features
- def main(config):
- # 图像预处理
- # VGGNet 在 ImageNet 上训练,其中图像通过 mean=[0.472, 0.436, 0.424] 和 std=[0.227, 0.226, 0.225] 进行归一化。
- # 我们在这里使用相同的归一化统计。
- transform = transforms.Compose([
- transforms.ToTensor(),
- transforms.Normalize(mean=(0.472, 0.436, 0.424),
- std=(0.227, 0.226, 0.225))])
- # 加载内容和样式图片
- # 使样式图像与内容图像大小相同
- content = load_image(config.content, transform, max_size=config.max_size)
- style = load_image(config.style, transform, shape=[content.size(2), content.size(3)])
- # 使用内容图像初始化目标图像
- target = content.clone().requires_grad_(True)
- optimizer = torch.optim.Adam([target], lr=config.lr, betas=[0.5, 0.999])
- vgg = VGGNet().to(device).eval()
- for step in range(config.total_step):
- # 提取多个(5)个卷积特征向量
- target_features = vgg(target)
- content_features = vgg(content)
- style_features = vgg(style)
- style_loss = 0
- content_loss = 0
- for f1, f2, f3 in zip(target_features, content_features, style_features):
- # 使用目标图像和内容图像计算内容损失
- content_loss += torch.mean((f1 - f2)**2)
- # 重塑卷积特征图
- _, c, h, w = f1.size()
- f1 = f1.view(c, h * w)
- f3 = f3.view(c, h * w)
- # 计算 gram 矩阵
- f1 = torch.mm(f1, f1.t())
- f3 = torch.mm(f3, f3.t())
- # 使用目标和风格图像计算风格损失
- style_loss += torch.mean((f1 - f3)**2) / (c * h * w)
- # 计算总损失、反向传播和优化
- loss = content_loss + config.style_weight * style_loss
- optimizer.zero_grad()
- loss.backward()
- optimizer.step()
- if (step+1) % config.log_step == 0:
- print ('Step [{}/{}], Content Loss: {:.4f}, Style Loss: {:.4f}'
- .format(step+1, config.total_step, content_loss.item(), style_loss.item()))
- if (step+1) % config.sample_step == 0:
- # 保存生成的图片
- denorm = transforms.Normalize((-2.12, -2.04, -1.80), (4.37, 4.46, 4.44))
- img = target.clone().squeeze()
- img = denorm(img).clamp_(0, 1)
- torchvision.utils.save_image(img, 'output-{}.png'.format(step+1))
- if __name__ == "__main__":
- parser = argparse.ArgumentParser()
- parser.add_argument('--content', type=str, default='png/content.png')
- parser.add_argument('--style', type=str, default='png/style.png')
- parser.add_argument('--max_size', type=int, default=400)
- parser.add_argument('--total_step', type=int, default=4000)
- parser.add_argument('--log_step', type=int, default=80)
- parser.add_argument('--sample_step', type=int, default=800)
- parser.add_argument('--style_weight', type=float, default=100)
- parser.add_argument('--lr', type=float, default=0.001)
- config = parser.parse_args()
- print(config)
- main(config)
-
相关阅读:
MySQL(四)——正则表达式查询、插入数据、删除数据
【人工智能】知识表示
.NET周刊【11月第4期 2023-11-26】
华为 ia综合topo
94后字节P7晒出工资单:狠补了这个,真不错...
一文详解爬楼梯
最大似然估计,散度,交叉熵
数据结构与算法-Hash算法
Redisson实现分布式锁
关于I/O——内存与CPU与磁盘之间的关系
- 原文地址:https://blog.csdn.net/sikh_0529/article/details/126940216
