-
基于Python的(拍照签到+网课在线检测)深度学习的人脸识别系统
摘 要
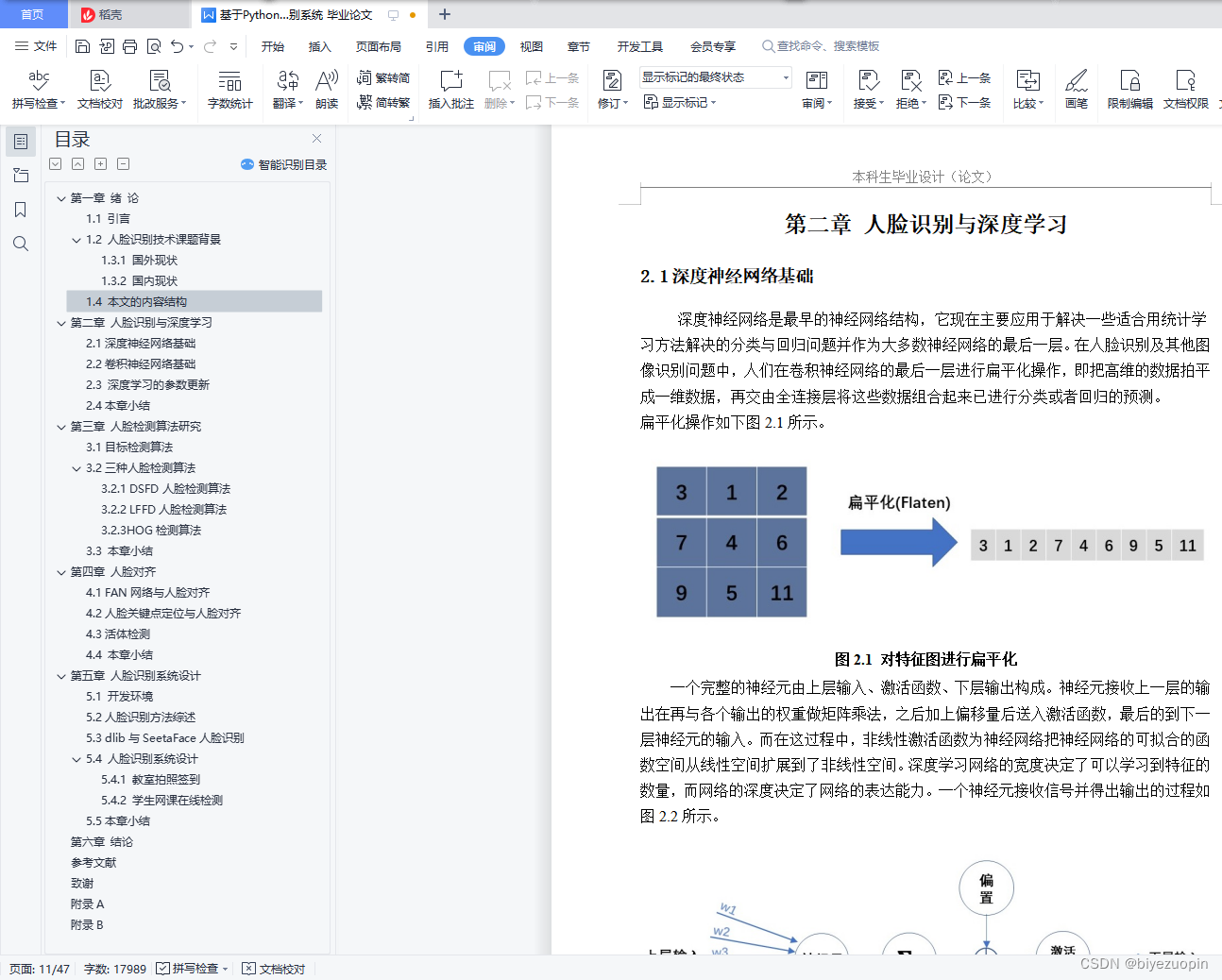
近年来,网络技术日新月异,我们已经进入了大数据的时代并成为其中第一员,由此带来数据量的飞跃式的增长,而如何利用这些数据产生实际的生产价值则成为了大数据时代的一个重要问题。而人脸识别技术是一份对大数据价值应用的标准答卷。传统的身份验证系统基于动态的密码和手机认证,这样的方式看似安全,实际上却非常容易产生信息暴露、信息被盗取、信息丢失等问题。假设有一天,用户丢失了手机或者身份证,如果是传统身份验证技术,那么就可能被不法之人所利用,而如果是生物特征识别技术,则不会存在这一问题。因此,人脸识别技术在未来不久也将会成为主要的信息安全技术。人脸识别是这种识别技术的和弦技术之一,同时也是最成熟的技术之一。利用一段视频或者图片,判断是否为本人,就是人脸识别技术所在做的。而人脸识别技术已经被广泛应用于入口检测之中,未来的应用只会越来越广泛。
人脸识别技术随着卷积神经网络的提出进入了飞速发展阶段,越来越多的研究人员通过改变卷积神经网络结构获得来越来越好的性能与效率。与此同时,人脸识别的数据集的数据量也越来越大、数据集的种类也越来越丰富,出现了3D人脸数据集和各种姿态、光照人脸数据集。人脸识别技术在目前已经发展的越来越成熟了,但是在应用过程中,人脸识别技术陷入了隐私泄露和隐私安全的困境,这种现象在国外尤其严重。
本文对基于深度学习的人脸识别做出了研究,同时也应用研究成果设计了拍照签到与网课在线检测系统。本文的人脸识别分为人脸检测、人脸对齐、人脸检验这三个过程。在人脸检测过程中,本文使用了LFFD算法进行快速人脸检测与活体检测以应对网课在线检测这一场景,同时也使用了DSFD算法进行高精度人脸识别以应对拍照签到这一场景。人脸对齐过程中,本文采用的是快速、简便的5关键点对齐。在最后的人脸检验过程中,本文使用了最新的SeetaFace6算法,支持口罩检测。本文也在最后的人脸检验过程中采用GPU加速了人脸距离计算过程,这不同于目前绝大部分人脸识别技术的人脸距离计算方式,非常的快速。关键词:人脸检测;人脸对齐;人脸识别;卷积神经网络
Abstract
In recent years, network technology has changed rapidly. We have entered the era of big data and become the first member of it, which has brought a leap in data volume growth. How to use these data to generate actual production value has become the era of big data. An important issue. The face recognition technology is a standard answer to the application of big data value. The traditional identity verification system is based on dynamic passwords and mobile phone authentication. This method seems to be safe, but in fact it is very easy to cause problems such as information exposure, information theft, and information loss. Suppose that one day, the user loses the mobile phone or ID card. If it is a traditional authentication technology, it may be used by illegal people. If it is a biometric technology, there will be no such problem. Therefore, face recognition technology will become the main information security technology in the near future. Face recognition is one of the chord technologies of this recognition technology, and it is also one of the most mature technologies. Using a video or a picture to determine whether it is the person is what the face recognition technology is for. While face recognition technology has been widely used in entrance detection, future applications will only become more widespread。
Face recognition technology has entered a stage of rapid development with the introduction of convolutional neural networks. More and more researchers have obtained better and better performance and efficiency by changing the structure of convolutional neural networks. At the same time, the data volume of face recognition data sets is getting larger and larger, and the types of data sets are becoming more and more abundant. 3D face data sets and various poses and lighting face data sets have appeared. Face recognition technology has become more and more mature at present, but in the application process, face recognition technology has fallen into the dilemma of privacy leakage and privacy security, which is especially serious abroad.
This paper researches on face recognition based on deep learning, and also uses the research results to design a photo check-in and online course detection system. Face recognition in this paper is divided into three processes: face detection, face alignment, and face verification. In the face detection process, this paper uses the LFFD algorithm for fast face detection and live detection to deal with the online class online detection scene, and also uses the DSFD algorithm for high-precision face recognition to deal with the scene of taking photos. In the process of face alignment, this article uses a quick and easy 5 key point alignment. In the final face verification process, this article uses the latest SeetaFace6 algorithm to support mask detection. This article also uses GPU to accelerate the face distance calculation process in the final face verification process, which is different from the current face distance calculation method of most face recognition technologies, which is very fast.Keywords: face detection;face alignment; face recognition; convolutional neural network
目 录
第一章 绪 论 - 1 -
1.1 引言 - 1 -
1.2 人脸识别技术课题背景 - 2 -
1.3人脸识别现状 - 3 -
1.3.1 国外现状 - 3 -
1.3.2 国内现状 - 3 -
1.4 本文的内容结构 - 5 -
第二章 人脸识别与深度学习 - 6 -
2.1深度神经网络基础 - 6 -
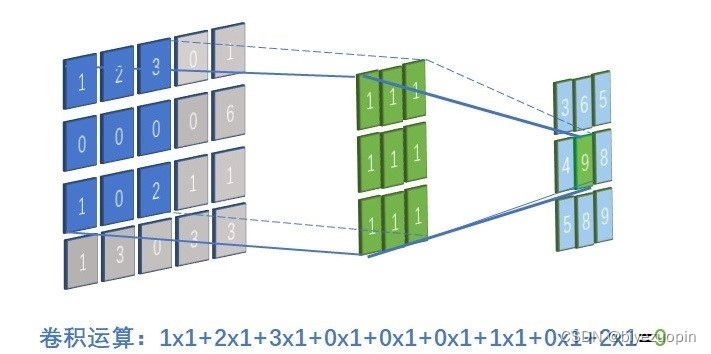
2.2卷积神经网络基础 - 7 -
2.3 深度学习的参数更新 - 13 -
2.4本章小结 - 13 -
第三章 人脸检测算法研究 - 14 -
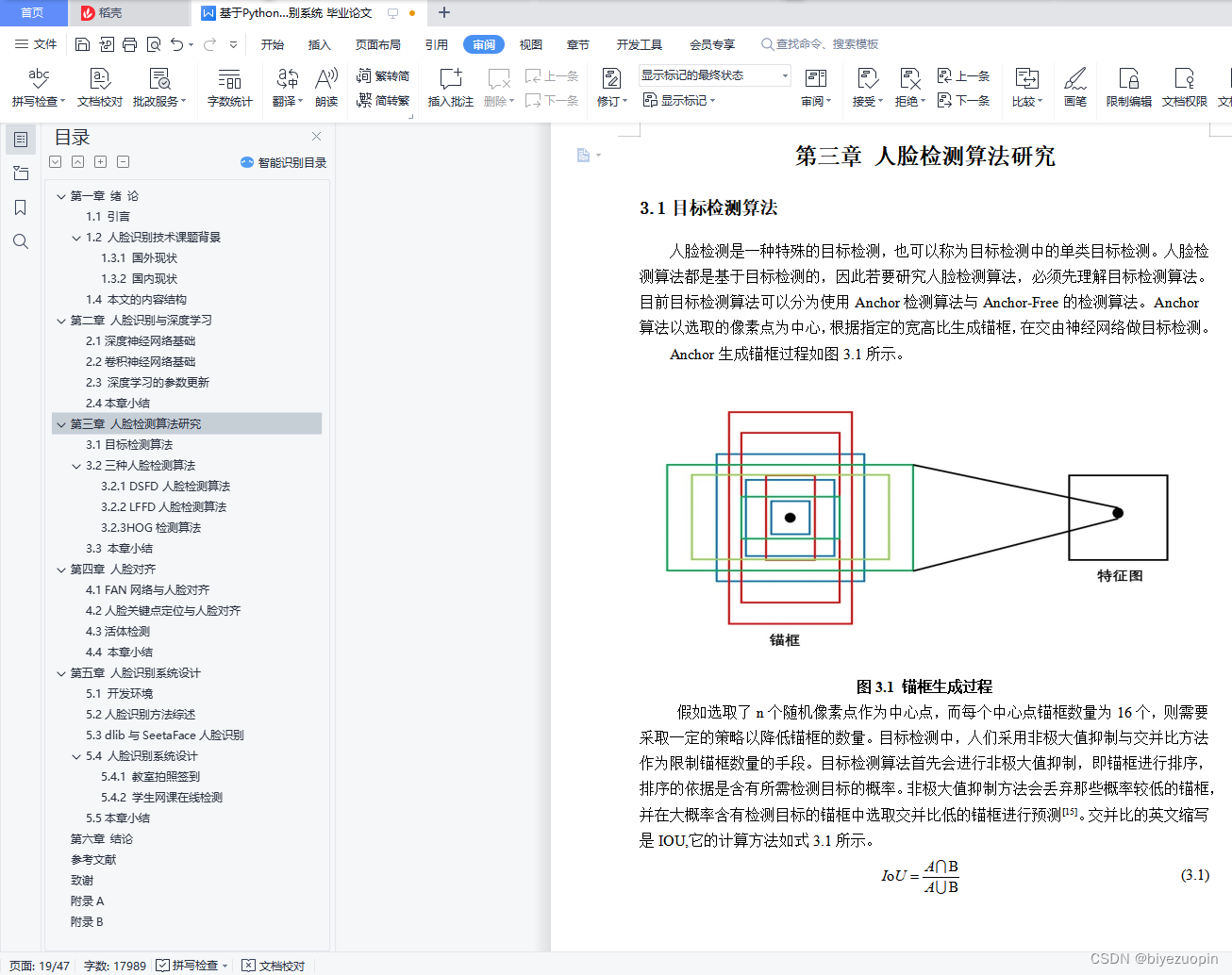
3.1目标检测算法 - 14 -
3.2三种人脸检测算法 - 17 -
3.2.1 DSFD人脸检测算法 - 17 -
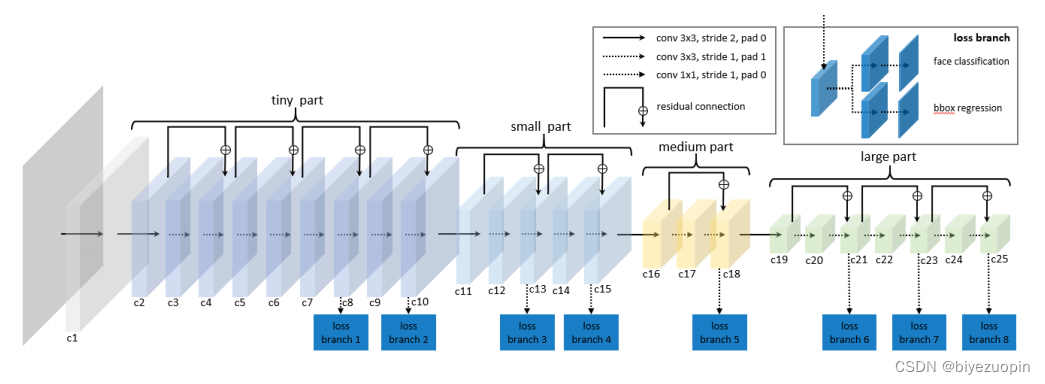
3.2.2 LFFD人脸检测算法 - 18 -
3.2.3HOG检测算法 - 20 -
3.3 本章小结 - 22 -
第四章 人脸对齐 - 23 -
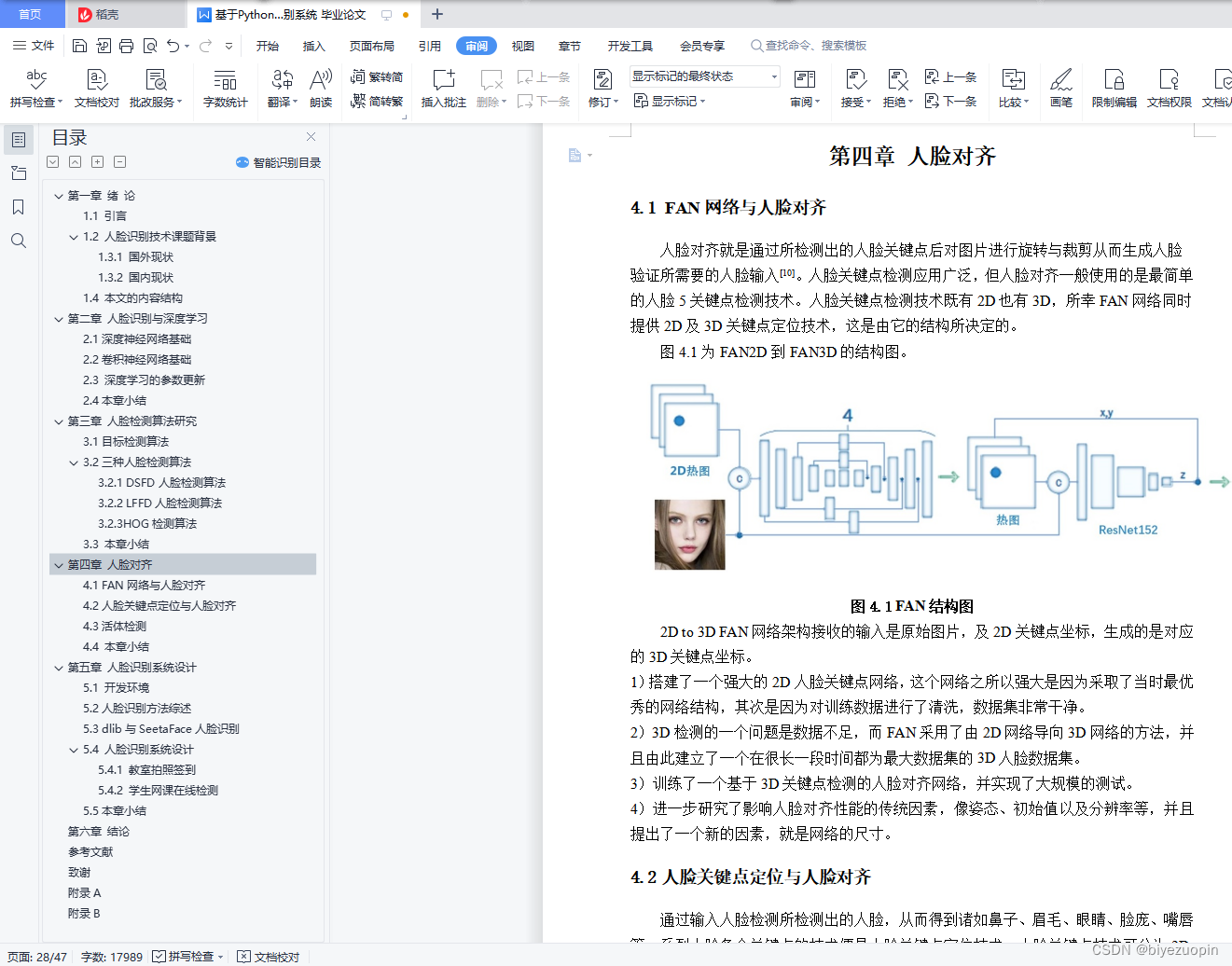
4.1 FAN网络与人脸对齐 - 23 -
4.2人脸关键点定位与人脸对齐 - 23 -
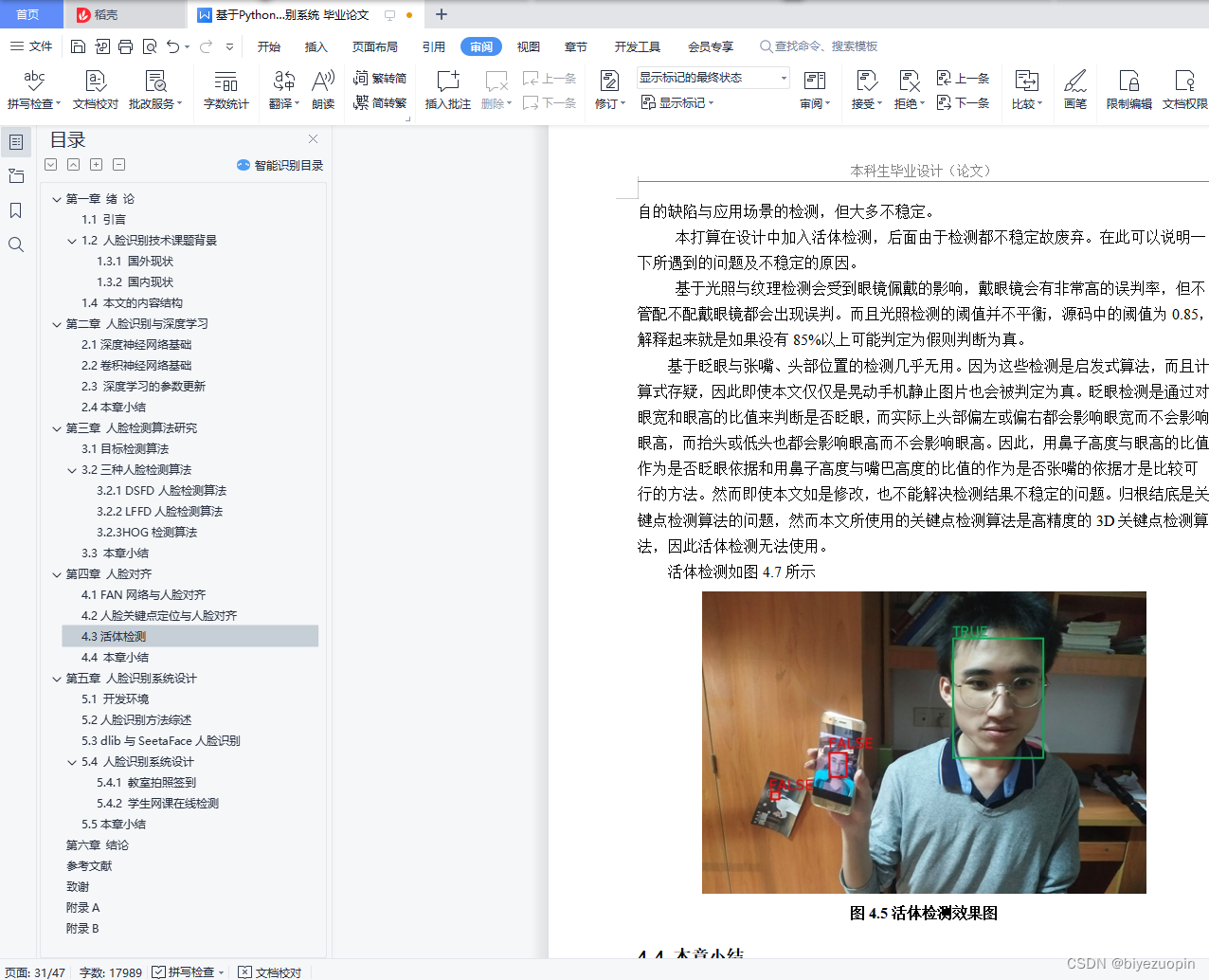
4.3活体检测 - 25 -
4.4 本章小结 - 26 -
第五章 人脸识别系统设计 - 27 -
5.1 开发环境 - 27 -
5.2人脸识别方法综述 - 27 -
5.3 dlib与SeetaFace人脸识别 - 28 -
5.4 人脸识别系统设计 - 32 -
5.4.1 教室拍照签到 - 32 -
5.4.2 学生网课在线检测 - 33 -
5.5本章小结 - 34 -
第六章 结论 - 35 -
参考文献 - 36 -
致谢 - 37 -
附录A - 38 -
附录B - 42 -
第五章 人脸识别系统设计
5.1 开发环境
进行项目开发前必须指明开发环境,开发环境不一致或者模块版本相差过大都可能导致程序无法运行或运行错误。确认开发环境是人脸识别中先决条件,任何人脸识别系统都有其模块版本、Python版本、操作系统型号的要求。若不能满足其要求则系统将可能无法正常运行。
人脸识别可适用的操作系统很多,比如Linux、MacOS、Windows x86、Windos amd64。本设计所采用的操作系统为Windows家庭版,操作版本为18362.778。
模块只能在Python3.6环境中运行,如果已经安装至3.7则需要创建Python3.6的开发环境。本设计依赖的模块见附录B.1。
在人脸识别系统设计中还要考虑所使用的设备,所使用设备不一致可能会无法达到原项目所测试出的性能,本设计的硬件设备信息见附录B.2
5.2人脸识别方法综述
人脸识别方法可以大致分为3类:根据几何特征识别、根据模板是被、根据模型的识别。
一张人脸包括眼睛、眉毛、嘴唇、脸庞、下巴、鼻子等部分,前文提到的人脸关键点检测技术便可以将这些特征给识别出来。在没有对人脸识别进行研究前,本文本以为特征点检测是为了进行人脸识别,而在对人脸识别进行研究后才发现目前主流人脸识别算法进行关键点检测是为了进行人脸对齐。不同的人的人脸关键点所构成的特征是不一样的,采用可以对这些特征的形状与相对空间位置关系进行几何描述的算法,就可以根据这些特征识别出人脸的身份。这种方法也可以算是机器学习的方法,而机器学习的方法都比较Naive。而根据这些特征进行度量的算法有欧里几德距离、余弦角。但这只是理论上的,实际上根据这样的算法进行人脸识别的效率与准确率都并不高。因此衍生出了另外一种方法——可变形模板法。
可变形模板是上一种方法的革新,也代表着人脸识别技术的阶段性进步。它的步骤是设计一个可调参的器官模型,并定义一个损失函数,通过对模型的调参使损失函数最小化,而该器官的特征选定为损失函数最小化时的参数。该算法的理论非常好,但是实际模型建立中存在着非常多的问题。一是损失函数的构建只能由经验确定,而不同的人脸数据集及不同研究人员都会对这种经验造成影响,这既限制了模型的推广也限制了模型的泛化。而是损失函数的优化困难,这种困难的体现是高额的时间复杂度与高额的空间复杂度。这种基于参数的编码方法能够对人脸器官进行非常准确的编码,但它需要花费巨量的时间进行预处理标注和没有尽头的调参。同时这种方法的另外一种缺陷是过于宏观,人脸除了器官以外其实还具有非常多的细小特征,比如皱纹、痣等,这种宏观的方法会丢失细微的特征,导致在识别颗粒度上并不够细致。由于可变性模板法的这种缺陷,可变性模板法只适合用于粗分类和预分类,而既不适用于高精度的人脸识别场景,也不适用对识别速度有苛刻要求的实时人脸检测。
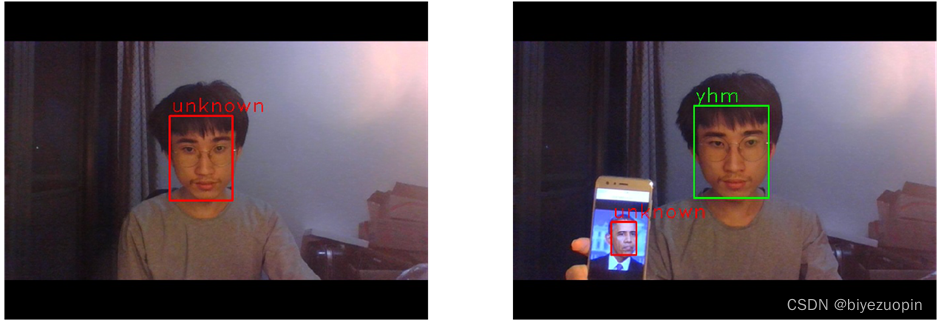
神经网络方法也即是模型方法,同时本设计所使用的方法即是神经网络方法。神经网络方法即是先通过人脸检测检测出人脸,随后通过关键点检测来进行人脸对齐,对齐后的人脸经过尺寸放缩后便可通过使用主流的卷积神经网络来提取特征,之后再通过全连接层对人脸进行编码从而形成高维特征,最后通过对两不同高维度特征进行度量后与阈值进行比较从而完成人脸识别。这个阈值是根据机器学习方法得出来的,常用于得出此阈值的方法是SVM方法。本文转载自http://www.biyezuopin.vip/onews.asp?id=14845import cv2
import sys
sys.path.append(‘./LFFDApply’)
import predict
import mxnet as mx
from config_farm import configuration_10_320_20L_5scales_v2 as cfgclass LFFDDetector(object):
def init(self, symbol_file_path=None, model_file_path=None):
ctx = mx.gpu(0)
self.symbol_file_path = r’./weights/symbol_10_320_20L_5scales_v2_deploy.json’
self.model_file_path = r’./weights/train_10_320_20L_5scales_v2_iter_1000000.params’
self.symbol_file_path = symbol_file_path if symbol_file_path else self.symbol_file_path
self.model_file_path = model_file_path if model_file_path else self.model_file_path
self.face_predictor = predict.Predict(mxnet=mx,
symbol_file_path=self.symbol_file_path,
model_file_path=self.model_file_path,
ctx=ctx,
receptive_field_list=cfg.param_receptive_field_list,
receptive_field_stride=cfg.param_receptive_field_stride,
bbox_small_list=cfg.param_bbox_small_list,
bbox_large_list=cfg.param_bbox_large_list,
receptive_field_center_start=cfg.param_receptive_field_center_start,
num_output_scales=cfg.param_num_output_scales)def get_boxes(self, image): if isinstance(image, str): image = cv2.imread(image, cv2.IMREAD_COLOR) boxes, infer_time = self.face_predictor.predict(image, resize_scale=1, score_threshold=0.8, top_k=10000, \ NMS_threshold=0.4, NMS_flag=True, skip_scale_branch_list=[]) return boxes def draw_in_image(self, path, display=True, save_path=None): image = cv2.imread(path, cv2.IMREAD_COLOR) boxes = self.get_boxes(image) for box in boxes: cv2.rectangle(image, (box[0], box[1]), (box[2], box[3]), (0, 0, 255), 2) if save_path: cv2.imwrite(save_path, image) if display: cv2.imshow('test', image) k = cv2.waitKey(0) # 按下空格退出 if k == ord(' '): cv2.destroyAllWindows() def get_pure_faces(self, path): if isinstance(path, str): image = cv2.imread(path, cv2.IMREAD_COLOR) else: image = path boxes = self.get_boxes(image) faces = [] for i, box in enumerate(boxes): box = tuple(map(int, box)) face = image[box[1]:box[3], box[0]:box[2], :] faces.append(face) return faces def realtime_detect(self): video_capture = cv2.VideoCapture(0) try: while video_capture.isOpened(): ret, image = video_capture.read() if not ret: print('摄像头有问题') break boxes = self.get_boxes(image) for box in boxes: cv2.rectangle(image, (box[0], box[1]), (box[2], box[3]), (0, 0, 255), 2) cv2.imshow('Online', image) k = cv2.waitKey(1) if k == ord(' '): break if k == ord('s'): cv2.imwrite('realtine.jpg', image) finally: video_capture.release() cv2.destroyAllWindows()def run_time_test():
import time
detector = LFFDDetector()
cap = cv2.VideoCapture(0)
cost_times = 0
delay_times = 200
test_times = 1000
multiply = test_times
while cap.isOpened():
ret, img = cap.read()
if not ret:
break
delay_times -= 1
start = time.time()
boxes = detector.get_boxes(img)
cost = time.time() - start
if delay_times <= 0:
cost_times += cost
test_times -= 1
print(test_times)
if test_times <= 0:
avg_time = cost_times / multiply
print(f’Cost time is {avg_time} second.')
cv2.destroyAllWindows()
breakif name == ‘main’:
# run_time_test()
# sys.exit(0)
detector = LFFDDetector()
detector.realtime_detect()
sys.exit(0)
# LFFD的感受野有限,人像不能过大
path = r’F:/obama1.jpg’
detector = LFFDDetector()
detector.draw_in_image(path, save_path=path.replace(‘.jpg’, ‘LFFD.jpg’))
import math
import matplotlib.pyplot as pltdense_face_path = 'F:/1140.jpg' detector.draw_in_image(dense_face_path) faces = detector.get_pure_faces(dense_face_path) nums = len(faces) print(f'Got {nums} faces in image.') sub_width = math.ceil(math.sqrt(nums)) for i, face in enumerate(faces): face = cv2.cvtColor(face, cv2.COLOR_BGR2RGB) plt.subplot(sub_width, sub_width, i + 1) plt.axis('off') plt.imshow(face) plt.show() _ = input('按下Enter键关闭') plt.close()








-
相关阅读:
JVM常用参数
985、211 毕业一年,面试八家大厂,四面拿美团 offer(Java 后端)
ArcGIS10.1软件安装教程
『现学现忘』Docker常用命令 — 19、容器常用命令(一)
9.19-21,openEuler与您相约2023欧洲开源峰会
代码优化与程序加速指南——针对数值优化和深度学习领域
少儿编程 2023年9月中国电子学会图形化编程等级考试Scratch编程三级真题解析(判断题)
Gateway服务网关
阿里云香港云服务器公网带宽价格表及测试IP地址
CCS:调试
- 原文地址:https://blog.csdn.net/sheziqiong/article/details/126659798