-
强大的数据分析工具——Pandas操作、易错点、知识点三万字详解
一、 Pandas数据结构
1.Series
2.DataFrame
3.从DataFrame中查询出SeriesDataFrame: 二维数据、整个表格、多行多列
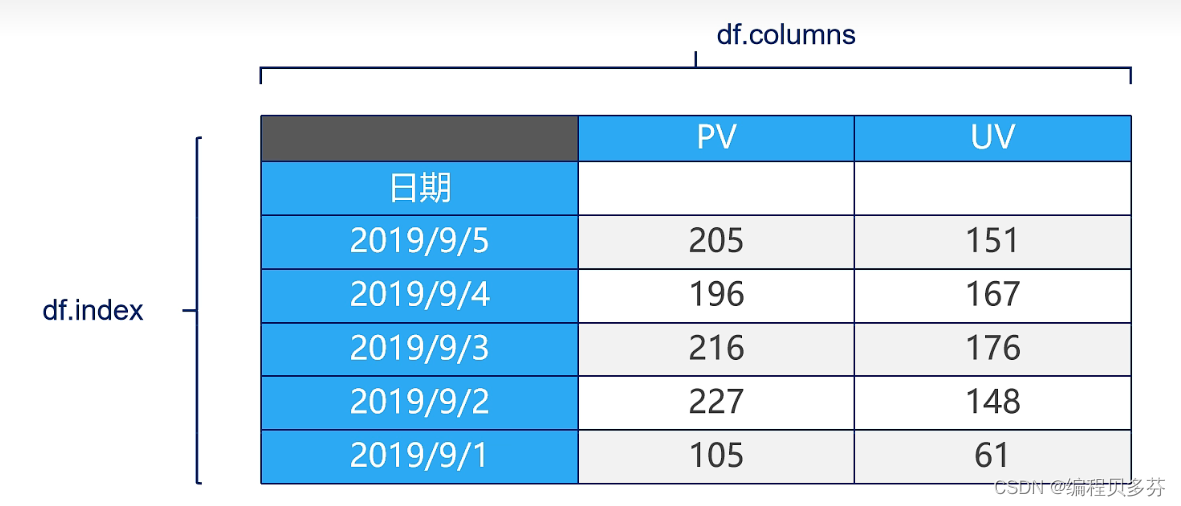
Series:一维数据,一行或者一列

- import pandas as pd
- import numpy as np
1、Series
Series是一种类似于一维数组的对象,它由一组数据〈不同数据类型)以及一组与之相关的数据标签(即索引)组成。
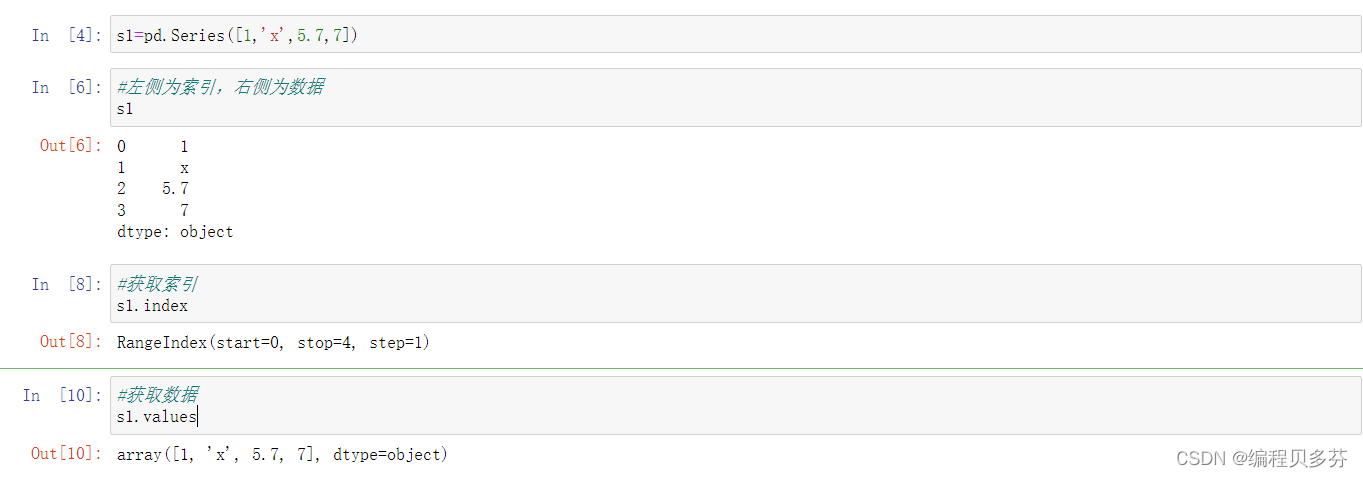
1.1仅有数据列表即可产生最简单的Series
左侧为索引,右侧为数据
- s1=pd.Series([1,'x',5.7,7])
- #左侧为索引,右侧为数据
- s1
获取索引
s1.index- 获取索引
- s1.index
获取数据
s1.values- #获取数据
- s1.values
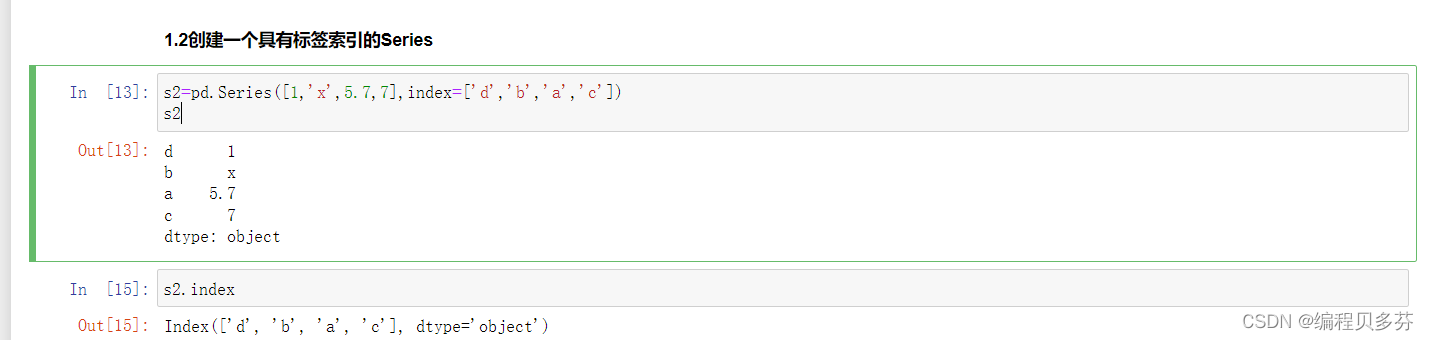
1.2创建一个具有标签索引的Series
- s2=pd.Series([1,'x',5.7,7],index=['d','b','a','c'])
- s2
- s2.index
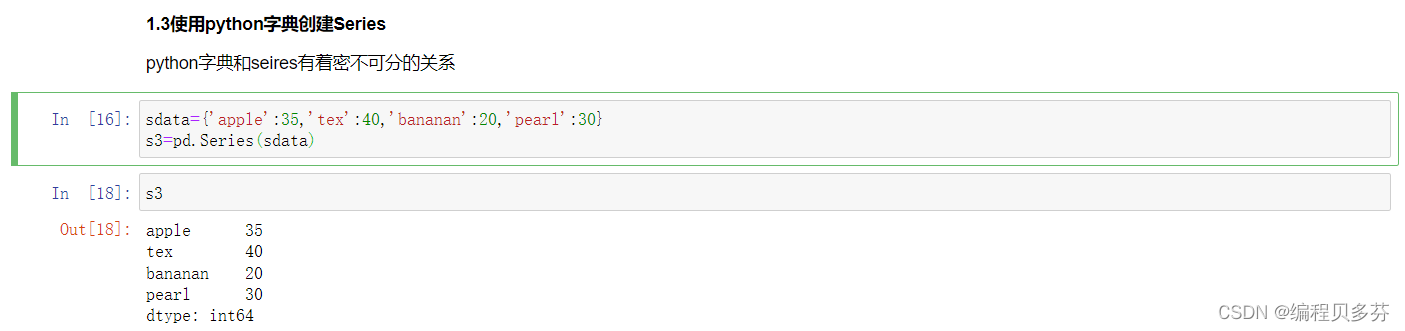
1.3使用python字典创建Series
python字典和seires有着密不可分的关系
- sdata={'apple':35,'tex':40,'bananan':20,'pearl':30}
- s3=pd.Series(sdata)
- s3
1.4根据标签索引查询数据
----类似pthon的字典dict
- s2
- s2['a']
查一个数据得到是python原生的数据类型
- #查一个数据得到是python原生的数据类型
- type(s2['a'])
- s2[['b','a']]
查询Series的类型 type(s2[['b','a']])
- #查询Series的类型
- type(s2[['b','a']])
2.DataFrame
DataFrame是一个表格型的数据结构¶
①每列可以是不同的值类型(数值、字符串、布尔值等)
②既有行索引index,也有列索引columns
③可以被看做由Series组成的字典
④创建dataframe最常用的方法,见读取纯文本文件、excel、mysql数据库2.1根据多个字典序列创建dataframe
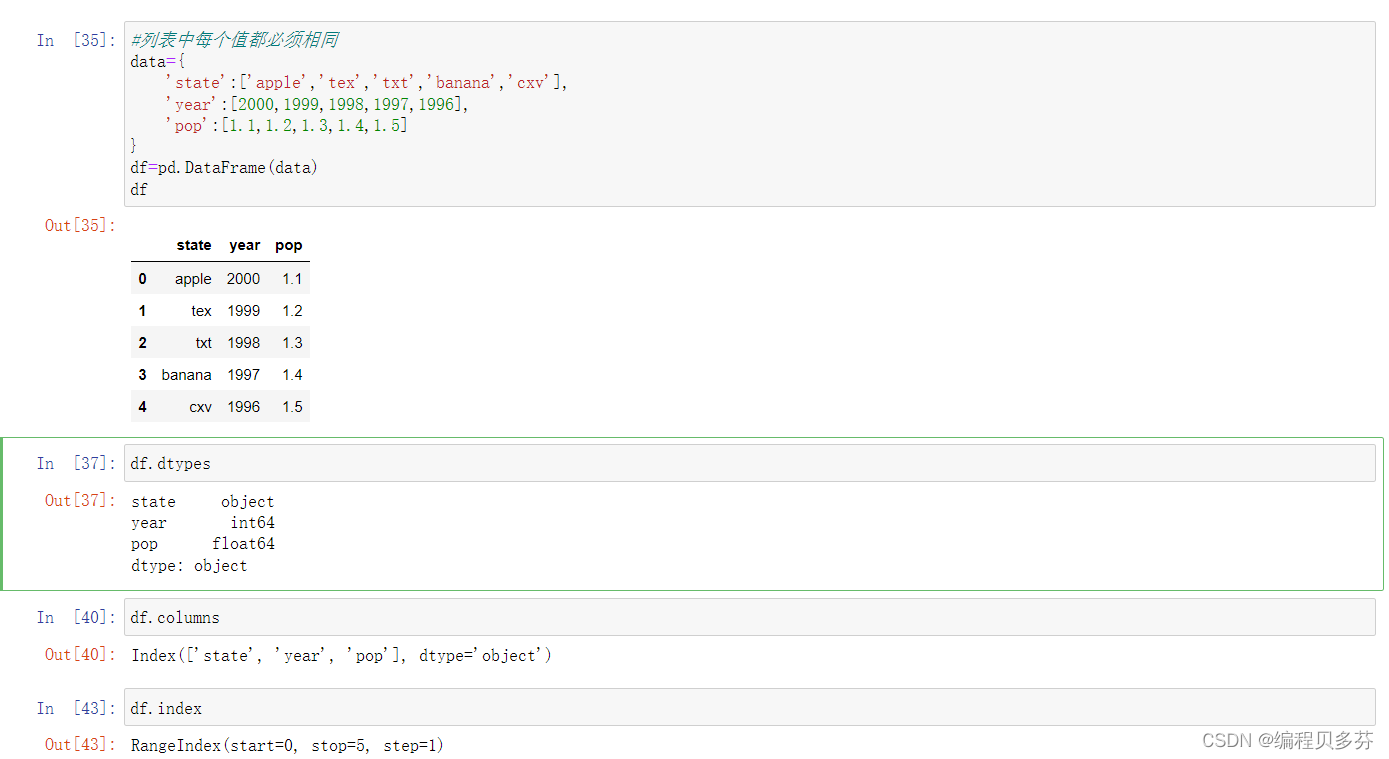
列表中每个值的个数都必须相同
- #列表中每个值都必须相同
- data={
- 'state':['apple','tex','txt','banana','cxv'],
- 'year':[2000,1999,1998,1997,1996],
- 'pop':[1.1,1.2,1.3,1.4,1.5]
- }
- df=pd.DataFrame(data)
- df
- df.dtypes
- df.columns
- df.index
3.从DataFrame中查询出Series
如果只查询一列,一行,返回的是pd.Series
如果查询多行、多列,返回的是pd.DataFramedf
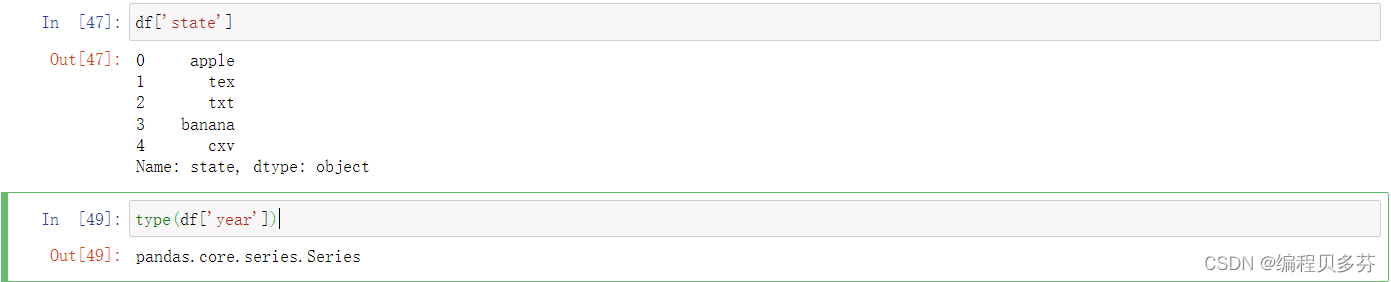
3.1查询一列,结果是一个pd.Series
- df['state']
- type(df['year'])
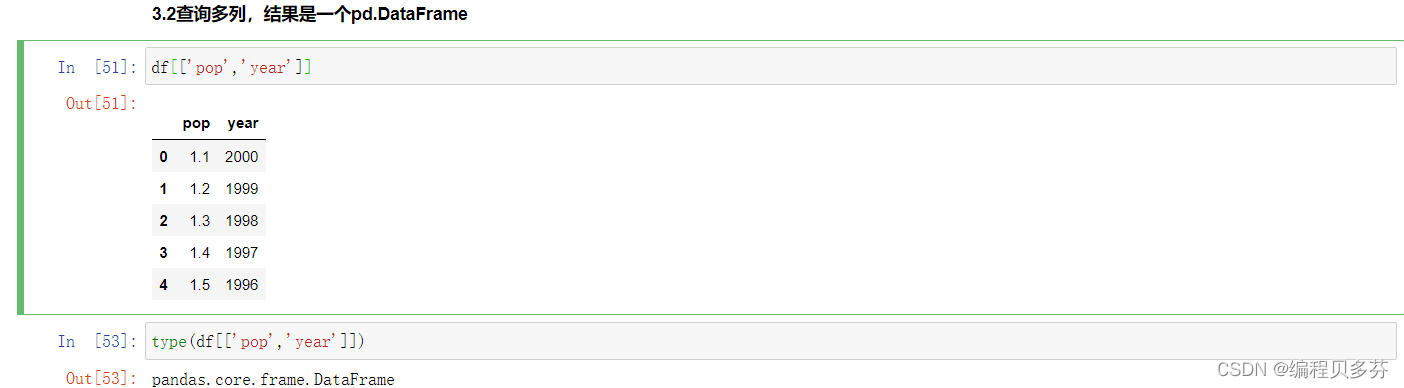
3.2查询多列,结果是一个pd.DataFrame
- df[['pop','year']]
- type(df[['pop','year']])
3.3查询一行,结果是一个pd.Series
loc(1)代表查询一行
- df.loc[1]
- type(df.loc[1])
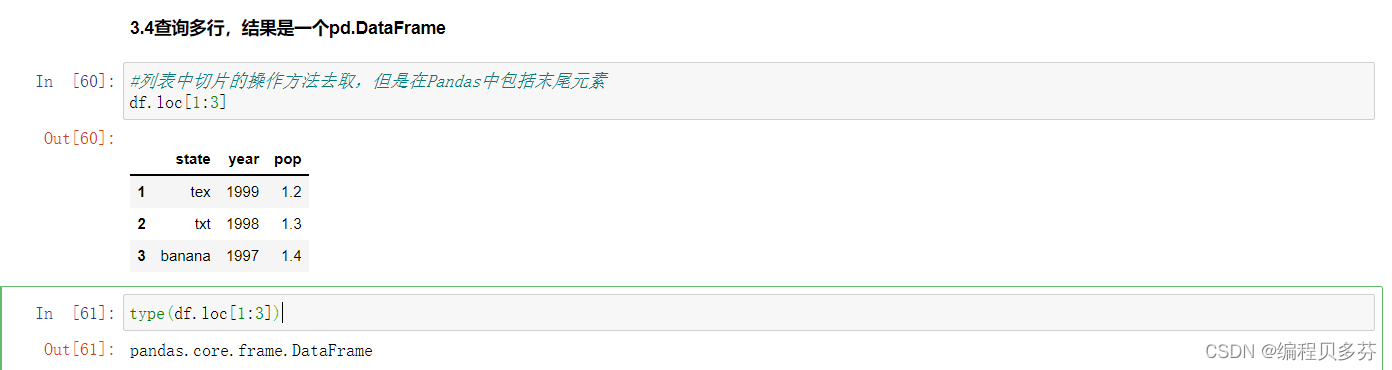
3.4查询多行,结果是一个pd.DataFrame
列表中切片的操作方法去取,但是在Pandas中包括末尾元素
- #列表中切片的操作方法去取,但是在Pandas中包括末尾元素
- df.loc[1:3]
- type(df.loc[1:3])
总结:
二、Pandas数据读取

1. pandas读取纯文本文件
·读取csv文件
·读取csv文件
2. pandas读取xlsx格式excel文件
3. pandas读取mysql数据表1、读取纯文本文件
1.1读取CSV,使用默认的标题行、逗号分隔符
- import pandas as pd
- fpath="./datas/ml-latest-small/ratings.csv"
- #注意是反斜杠/,不然会报错
注意:地址中是反斜杠/,不然会报错
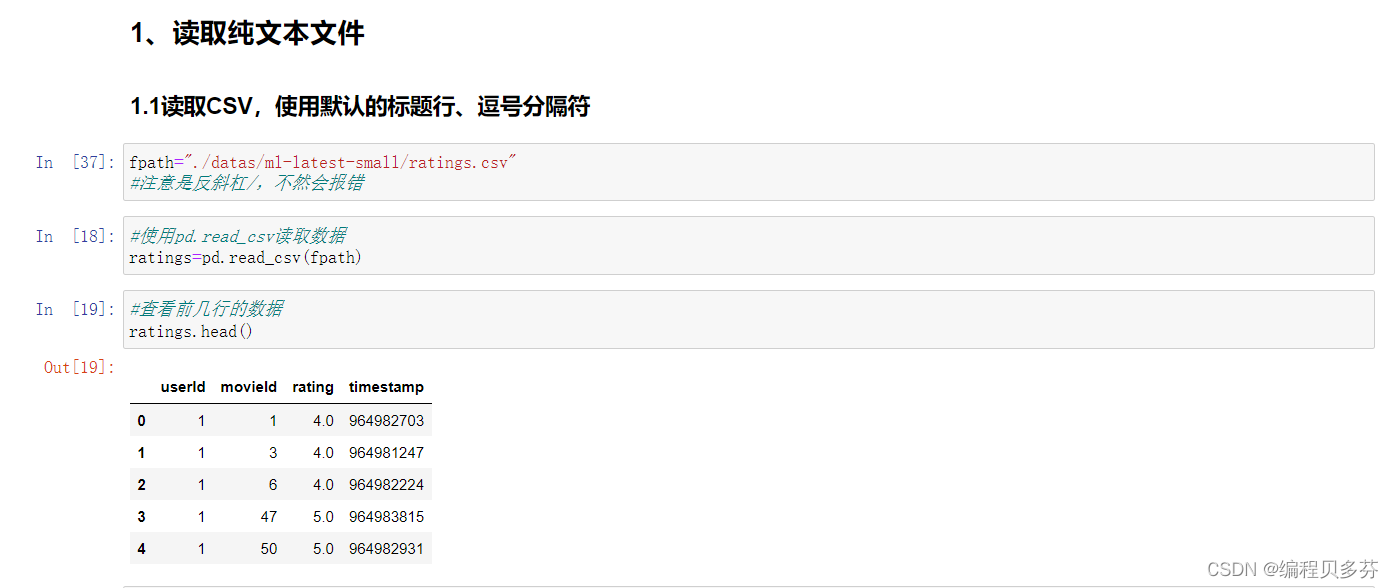
使用pd.read_csv读取数据
ratings=pd.read_csv(fpath)查看前几行的数据
ratings.head()- #查看前几行的数据
- ratings.head()
查看数据的形状,返回(行数,列数)ratings.shape
- #查看数据的形状,返回(行数,列数)
- ratings.shape
查看列名列表
ratings.columns- #查看列名列表
- ratings.columns
查看索引列
ratings.index- #查看索引列
- ratings.index
查看每列的数据类型
ratings.dtypes- #查看每列的数据类型
- ratings.dtypes

1.2 读取txt文件,自己指定分隔符、列名
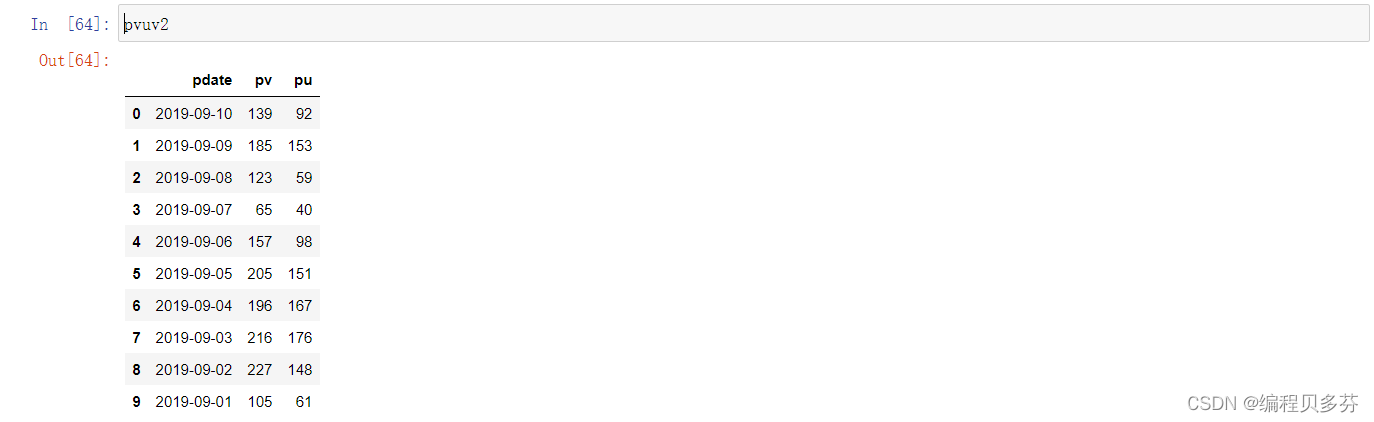
fpath2='./datas/crazyant/access_pvuv.txt'- pvuv2=pd.read_csv(
- fpath2,
- sep='\t',
- header=None,
- names=['pdate','pv','pu']
- #注意设置列名的时候是names,而不是nameread_csv() got an unexpected keyword argument 'name'
- )
- pvuv2
注意:设置列名的时候是names,而不是name 报错:read_csv() got an unexpected keyword argument 'name'
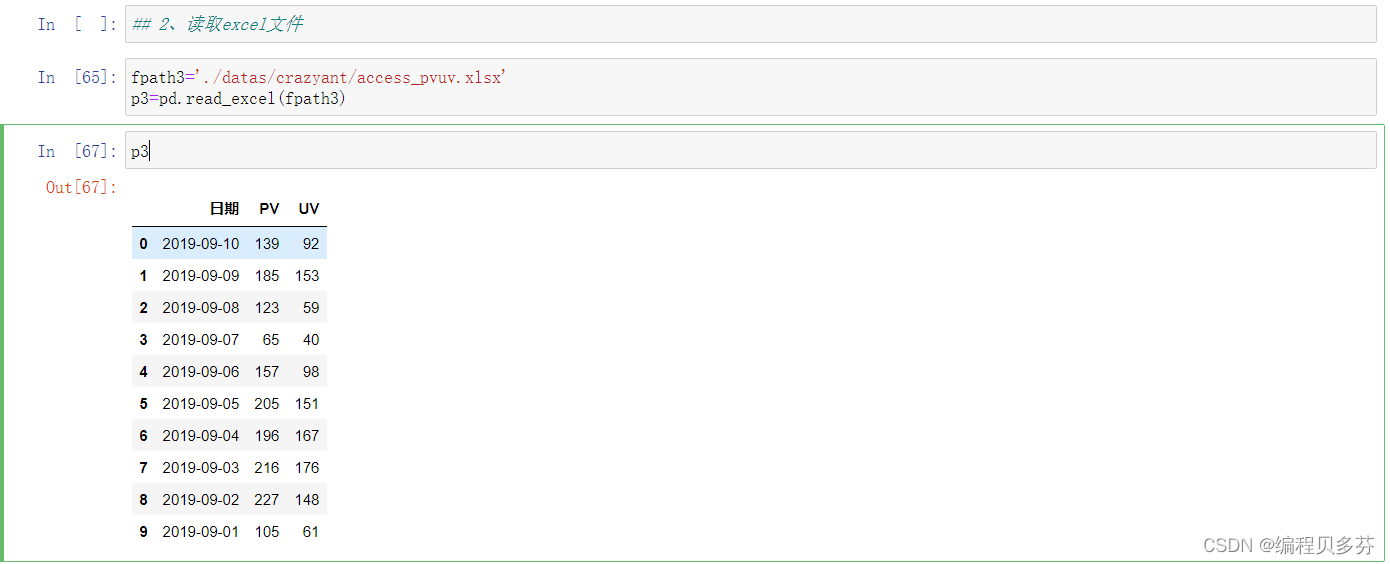
2、读取excel文件
- fpath3='./datas/crazyant/access_pvuv.xlsx'
- p3=pd.read_excel(fpath3)
- p3
3、读取MySQL数据库
- !pip install pymysql
- #使用的方法是read_sql
- import pymysql
使用的方法是read_sql:
- coon=pymysql.connect(
- host='127.0.0.1',
- user='root',
- database='test'
- charset='utf-8'
- )
- mysql_page=pd.read_sql('select * form crazyant_pvuv',con=coon)
注意:host是数据库的本地连接,user都是你本地电脑中设置的参数
三、Pandas查询数据
Pandas查询数据的几种方法
1.df.loc方法,根据行、列的标签值查询
2. df.iloc方法,根据行、列的数字位置查询
3. df.where方法
4. df.query方法
.loc既能查询,又能覆盖写入,强烈推荐!
Pandas使用df.loc查询数据的方法
1.使用单个label值查询数据
2.使用值列表批量查询
3.使用数值区间进行范围查询
4.使用条件表达式查询
5.调用函数查询
·以上查询方法,既适用于行,也适用于列·注意观察降维dataFrame>Series>值
import pandas as pd1、读取数据
北京2018年全年天气预报
- df=pd.read_csv('./datas/beijing_tianqi/beijing_tianqi_2018.csv',index_col='ymd')
- df.head()
- df.index

设置索引为日期,方便按日期筛选
inplace=True 表示直接在原存储空间上进行更改,不是重新开辟一块空间进行更改- #设置索引为日期,方便按日期筛选
- #inplace=True 表示直接在原存储空间上进行更改,不是重新开辟一块空间进行更改
- df.set_index('ymd',inplace=True)
- df.head()

替换掉温度后的℃
其实还是使用切片操作,首先筛选出所有的行,在筛选出yWendu中一列,带着类型replace修改完之后,在对修改后的类型进行转换- df.loc[:,'bWendu']=df['bWendu'].str.replace('℃','').astype('int32')
- df.loc[:,'yWendu']=df['yWendu'].str.replace('℃','').astype('int32')
- df.head()
- df.dtypes

值得注意的是:
AttributeError: Can only use .str accessor with string values!这种错误一般都是修改完之后了,不能在进行修改,说明已经修改过了
2、使用单个label值查询数据¶
行或列,都可以只传入单个值,实现精确匹配
查询一个单元格,只会返回一个数字值
- #查询一个单元格,只会返回一个数字值
- df.loc['2018-01-01','bWendu']
对于列的筛选,会产生一列,得到一个Series
- #对于列的筛选,会产生一列,得到一个Series
- df.loc['2018-01-01',['bWendu','yWendu']]

3、使用值列表批量查询
得到Series
- #得到Series
- df.loc[['2018-01-02','2018-01-03','2018-01-04'],'bWendu']
得到DataFrame
- #得到DataFrame
- df.loc[['2018-01-02','2018-01-03','2018-01-04'],['bWendu','yWendu']]

4、使用数值区间进行范围查询
注意:区间既包括开始,也包括结束
行index按区间,切片操作的时候不用加双【】
列index按区间
行和列都按区间查询
- #行index按区间,切片操作的时候不用加双【】
- df.loc['2018-01-03':'2018-01-05','bWendu']
- #列index按区间
- df.loc['2018-01-03','bWendu':'fengxiang']
- #行和列都按区间查询
- df.loc['2018-01-03':'2018-01-05','bWendu':'fengxiang']

5、使用条件表达式查询¶
bool列表的长度等于行数或者列数
简单条件查询,最低温度低于-10度的列表
- #简单条件查询,最低温度低于-10度的列表
- df.loc[df['yWendu']<-10,:]
观察这里的boolean条件
- #观察这里的boolean条件
- df['yWendu']<-10

复杂条件查询,查完美天气
注意,组合条件&符号合并,每个条件判断都得带括号
查询最高温度小于30度,最低温度大于15度,晴天,天气为优的数据
- #查询最高温度小于30度,最低温度大于15度,晴天,天气为优的数据
- df.loc[(df['bWendu']<=30) & (df['yWendu']>=15) & (df['tianqi']=='晴') & (df['aqiLevel']==1),:]
观察这里boolean的条件
- #观察这里boolean的条件
- (df['bWendu']<=30) & (df['yWendu']>=15) & (df['tianqi']=='晴') & (df['aqiLevel']==1)

6、调用函数查询
直接写lambda表达式
- # 直接写lambda表达式
- df.loc[lambda df :(df['bWendu']<=30)&(df['yWendu']>=15),:]
直接编写函数,查询9月份,空气质量好的数据
- #直接编写函数,查询9月份,空气质量好的数据
- def query_mydata(df):
- return df.index.str.startswith('2018-09')&df['aqiLevel']==1
- df.loc[query_mydata]


注意:
函数式编程的本质:函数自身可以像变量一样传递
四、 Pandas怎样新增数据列?¶
在进行数据分析时,经常需要按照一定条件创建新的数据列,然后进行进一步分析
1.直接赋值
2. df.apply方法
3. df.assign方法
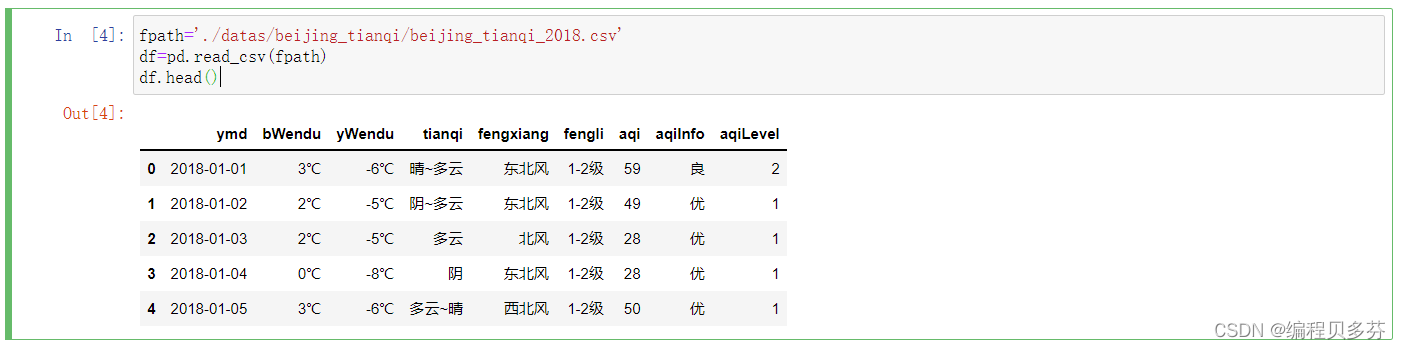
4.按条件选择分组分别赋值import pandas as pd1、读取CSV数据到dataframe
- fpath='./datas/beijing_tianqi/beijing_tianqi_2018.csv'
- df=pd.read_csv(fpath)
- df.head()
2、对数据进行一个预处理
清理温度列,变成一个数字类型
- df.loc[:,'bWendu']=df['bWendu'].str.replace('℃','').astype('int32')
- df.loc[:,'yWendu']=df['yWendu'].str.replace('℃','').astype('int32')
- df.head()
- #AttributeError: Can only use .str accessor with string values! 这种情况下语句代码只能运行一次,当运行第二次的时候,原存储的数据已经被改变了
需要注意的是:AttributeError: Can only use .str accessor with string values! 这种情况下语句代码只能运行一次,当运行第二次的时候,原存储的数据已经被改变了
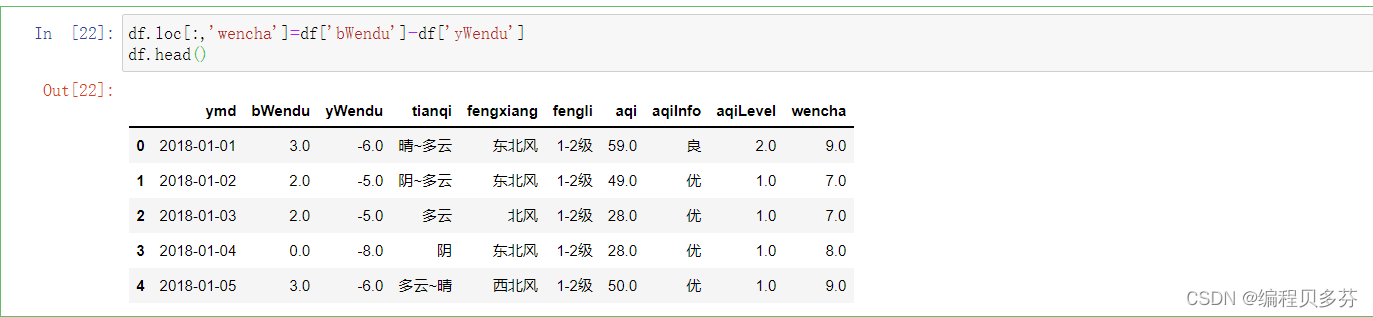
3、直接赋值方法
将温差加入表格当中,注意wencha是一个series,后面的减法返回的是一个series
- df.loc[:,'wencha']=df['bWendu']-df['yWendu']
- df.head()
4、df.apply方法
Apply a function along an axis of the DataFrame.
Objects passed to the function are Series objects whose index is either the DataFrame's index(axis=0) or the DataFrame's columns (axis=1).实例:添加─列温度类型:
1.如果最高温度大于33度就是高温
2.低于-10度是低温
3.否则是常温- def get_wendutype(x):
- if x['bWendu']>33:
- return '高温'
- if x['yWendu']<-10:
- return'低温'
- else:
- return '常温'
- df.loc[:,'wendutype']=df.apply(get_wendutype,axis=1)
df['wendutype'].value_counts()
5、df.assign方法
Assign new columns to a DataFrame.
Returns a new object with all original columns in addition to new ones.实例:将温度从摄氏度变成华氏度
注意:df.assign可以同时添加多个列
- #df.assign可以同时添加多个列
- df.assign(
- yWendu_huashi=lambda x: x['yWendu']*9/5+32,
- bWendu_huashi=lambda x: x['bWendu']*9/5+32
- )

6、按条件选择分组分别赋值
按条件先选择数据,然后对这部分数据赋值新列
实例:高低温差大于10度,则认为温差大
- #先创建空列(第一种创建新列的方法)
- df['wencha']=''
- df.loc[df['bWendu']-df['yWendu']>10,'wencha']='温差大'
- df.loc[df['bWendu']-df['yWendu']<=10,'wencha']='温差正常'
- df['wencha'].value_counts()

五、Pandas 数据统计函数
1、汇总类统计
2、唯一去重和按值计数
3、相关系数和协方差
import pandas as pd1、预备步骤,对数据进行读取和预处理(将温度都改为Int类型)
- fpath='./datas/beijing_tianqi/beijing_tianqi_2018.csv'
- df=pd.read_csv(fpath)
- df.head()

- df.loc[:,'bWendu']=df['bWendu'].str.replace('℃','').astype('int32')
- df.loc[:,'yWendu']=df['yWendu'].str.replace('℃','').astype('int32')
- df.head()
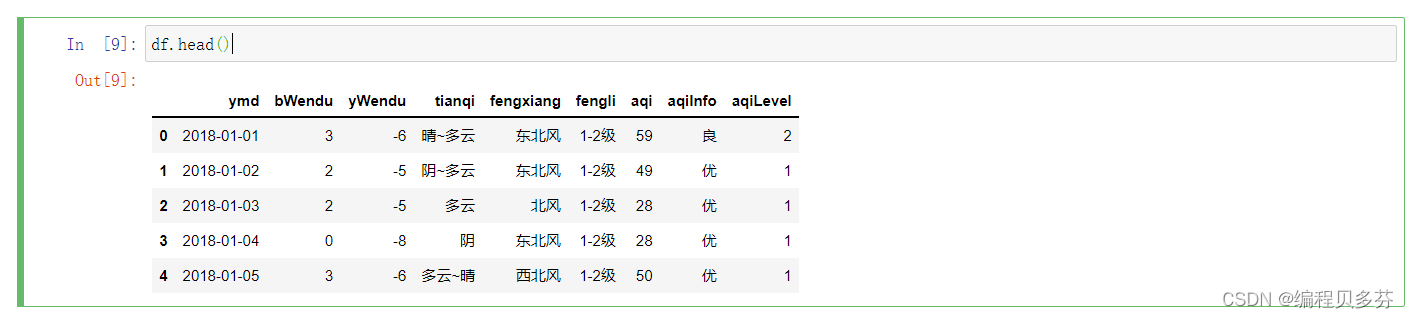
2、对数据进行汇总类统计
- #提取出所有数字列统计结果
- df.describe()

查看单个Series的数据---最高温度的平均值---df['bWendu'].mean()
- # 查看单个Series的数据---最高温度的平均值
- df['bWendu'].mean()
查看最高温度----df['bWendu'].max()
- #查看最高温度
- df['bWendu'].max()
最低温度----df['yWendu'].min()
- #最低温度
- df['yWendu'].min()

3、唯一去重和按值计算
3.1唯一去重性
一般不用于数值列,而是枚举,分类列-----df[“ ” ].unique()
- df['fengxiang'].unique()
- df['tianqi'].unique()
- df['fengli'].unique()

3.2 按值计数(对数据探索十分有用)
- df['fengxiang'].value_counts()
- df['tianqi'].value_counts()
- df['fengli'].value_counts()


5、相关系数和协方差用途(超级厉害)︰
1.两只股票,是不是同涨同跌?程度多大?正相关还是负相关?
2.产品销量的波动,跟哪些因素正相关、负相关,程度有多大?
对于两个变量X、Y:
1.协方差︰衡量同向反向程度,如果协方差为正,说明X,Y同向变化,协方差越大说明同向程度越高;如果协方差为负,说明×,Y反向运动,协方差越小说明反向程度越高。
2.相关系数:衡量相似度程度,当他们的相关系数为1时,说明两个变量变化时的正向相似度最大,当相关系数为- 1时,说明两个变量变化的反向相似度最大¶
协方差矩阵-----df.cov()
- #协方差矩阵
- df.cov()
相关系数矩阵----df.corr()
- #相关系数矩阵
- df.corr()
单独查看空气质量和最高温度的相关系数----df['aqi'].corr(df['bWendu'])
- #单独查看空气质量和最高温度的相关系数
- df['aqi'].corr(df['bWendu'])
- df['aqi'].corr(df['yWendu'])
检测空气质量和温差的相关系数----df['aqi'].corr(df['bWendu']-df['yWendu'])
- #检测空气质量和温差的相关系数
- df['aqi'].corr(df['bWendu']-df['yWendu'])


以上就是特征方程对于机器学习重要性的一个例子
注:什么是特征方程?
特征方程是为研究相应的数学对象而引入的一些等式,它因数学对象不同而不同,包括数列特征方程、矩阵特征方程、微分方程特征方程、积分方程特征方程等等。
下面所介绍的仅仅是数列的特征方程。
一个数列:

设 有r,s使

所以

得

消去s就导出特征方程式

六、Pandas 三类函数对缺失值的处理
Pandas使用这些函数处理缺失值:
. isnull和notnull:检测是否是空值,可用于df和series.
dropna:丢弃、删除缺失值
axis:删除行还是列,{0 or 'index',1 or 'columns'}, default 0
how :如果等于any则任何值为空都删除,如果等于all则所有值都为空才删除
inplace :如果为True则修改当前df,否则返回新的df
. fillna:填充空值
value:用于填充的值,可以是单个值,或者字典(key是列名,value是值)
method :等于ffill使用前一个不为空的值填充forword fill;等于bfill使用后一个不为空的值填充backword fill
axis:按行还是列填充,{0 or 'index',1 or 'columns'}
inplace:如果为True则修改当前df,否则返回新的dfimport pandas as pd1、实例:特殊Excel的读取、清洗、处理
步骤1:读取excel的时候,忽略前几个空行
- fpath='./datas/student_excel/student_excel.xlsx'
- df=pd.read_excel(fpath,skiprows=2)
- df

步骤2:检测空值--df.isnull()
df.isnull()
以下两个函数输出的是相反的值:
df['分数'].isnull()、df['分数'].notnull()
- df['分数'].isnull()
- df['分数'].notnull()

筛选出没有空分数的所有行---df.loc[df['分数'].notnull(),:]
- #筛选出没有空分数的所有行
- df.loc[df['分数'].notnull(),:]

步骤3:删除掉全是空值的列
- df.dropna(axis='columns',how='all',inplace=True)
- df

步骤4:删除掉全是空值的行
- df.dropna(axis='index',how='all',inplace=True)
- df

步骤5:将分数列为空的填充为0分
df.fillna({'分数':0})
上述操作可以等于以下代码
- #上述操作可以等于一下代码
- df.loc[:,'分数']=df['分数'].fillna(0)
- df

步骤6:将姓名的缺失值填充
使用前面的有效值填充,用ffill:forward fill
- df.loc[:,'姓名']=df['姓名'].fillna(method='ffill')
- df

步骤7:将清洗号的excel保存
df.to_excel('./datas/student_excel/student_excel_clean.xlsx',index=False)七、Pandas 的SettingWithCopyWarning 报警复现、原因、解决方案
1、读取数据并对数据进行预处理操作¶
- fpath='./datas/beijing_tianqi/beijing_tianqi_2018.csv'
- df=pd.read_csv(fpath)
- df.head()
- df
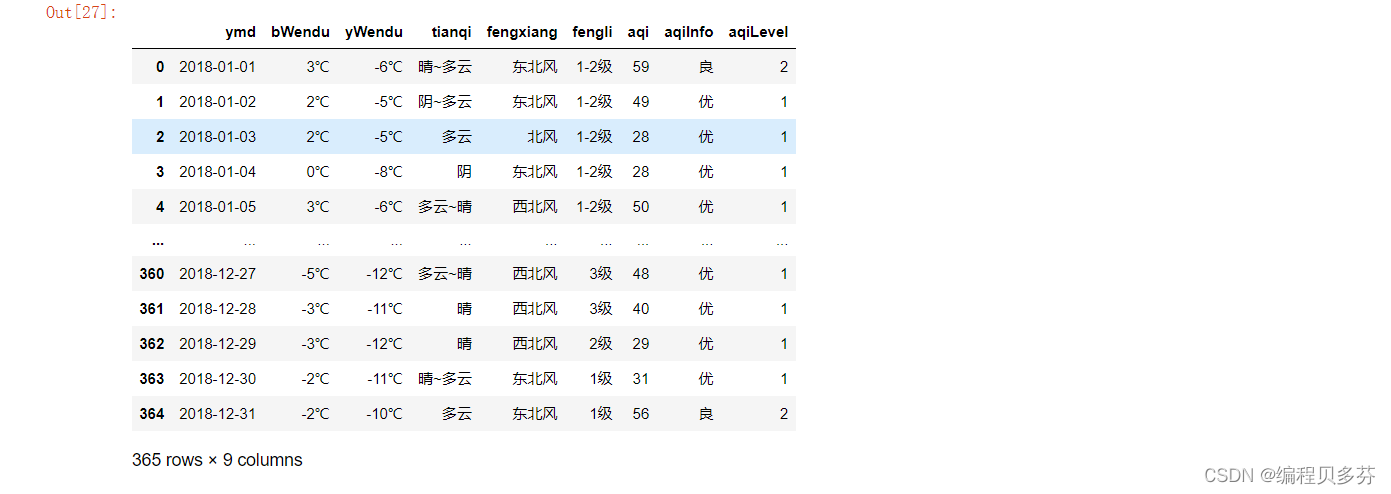
- import pandas as pd
- df.loc[:,'bWendu']=df['bWendu'].str.replace('℃','').astype('int32')
- df.loc[:,'yWendu']=df['yWendu'].str.replace('℃','').astype('int32')
- df

2、复现错误
只选出3月份的数据用来分析
- #只选出3月份的数据用来分析
- condition=df['ymd'].str.startswith('2018-03')
设置温差
- #设置温差
- df[condition]['wen_cha']=df['bWendu']-df['yWendu']

值得注意的是报错:
SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value instead 发现:df[condition]['wen_cha']=df['bWendu']-df['yWendu']改句代码出错
这里我们也可以查看官网网站去完成差错:Indexing and selecting data — pandas 1.4.4 documentation (pydata.org)
查看是否修改成功
- #查看是否修改成功
- df[condition].head()

3、原因
发出警告的代码: df[condition]['wen_cha']=df['bWendu']-df['yWendu']
相当于: df.get(condition).set(wen_cha),第一步的get发出了报警
链式操作其实是两个步骤,先get 后set,get得到的dateframe可能是View也可能是Copy、Pandas发出警告
【先可以去官网查看原因】核心: pandas的dataframe的修改写操作,只允许在dataframe上进行,一步到位
4、解决方法1
将get+set 的两步操作,改成set的一步操作
- df.loc[condition,'wen_cha']=df['bWendu']-df['yWendu']
- df.head()
df[condition].head()
5、解决方法2
如果需要预选筛选数据做后续的处理分析,使用copy复制Dataframe
- df_month3=df[condition].copy()
- df_month3.head()

- df_month3['wen_cha']=df['bWendu']-df['yWendu']
- df_month3.head()

八、Pandas数据排序【Series和DataFrame的排序操作函数】
1、Pandas数据排序:
Series的排序:
Series.sort_values(ascending=True, inplace=False)参数说明:
ascending:默认为True升序排序,为False降序排序.
inplace:是否修改原始SeriesDataFrame的排序:
DataFrame.sort_values(by, ascending=True, inplace=False)参数说明:
by:字符串或者List<字符串>,单列排序或者多列排序
ascending: bool或者List,升序还是降序,如果是list对应by的多列.
inplace:是否修改原始DataFrame1.1、对数据进行读取和处理操作
- import pandas as pd
- fpath='./datas/beijing_tianqi/beijing_tianqi_2018.csv'
- df=pd.read_csv(fpath)
- df
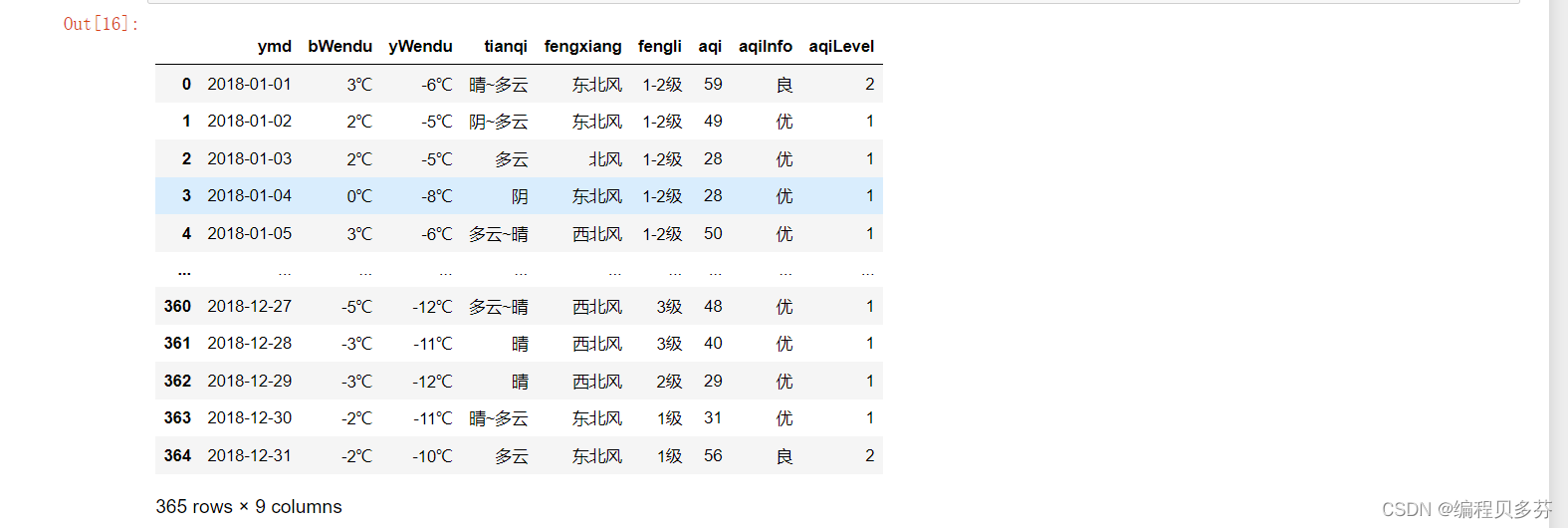
- df.loc[:,'bWendu']=df['bWendu'].str.replace('℃','').astype('int32')
- df.loc[:,'yWendu']=df['yWendu'].str.replace('℃','').astype('int32
df.head()
2、Series排序
df['aqi'].sort_values(ascending=False)
- ### 2、Series排序
- df['aqi'].sort_values(ascending=False)

默认为从低到高进行排序 df['aqi'].sort_values()
- #默认为从低到高进行排序
- df['aqi'].sort_values()
也可以对非数字序列进行排序——下述演示的是字符串序列进行排序 df['tianqi'].sort_values()
- #也可以对非数字序列进行排序——下述演示的是字符串序列进行排序
- df['tianqi'].sort_values()

3、DataFrame的排序
3.1 单列排序
默认天气状况从低到高进行排序 df.sort_values(by='aqi')
- #默认天气状况从低到高进行排序
- df.sort_values(by='aqi')

df.sort_values(by='aqi',ascending=False)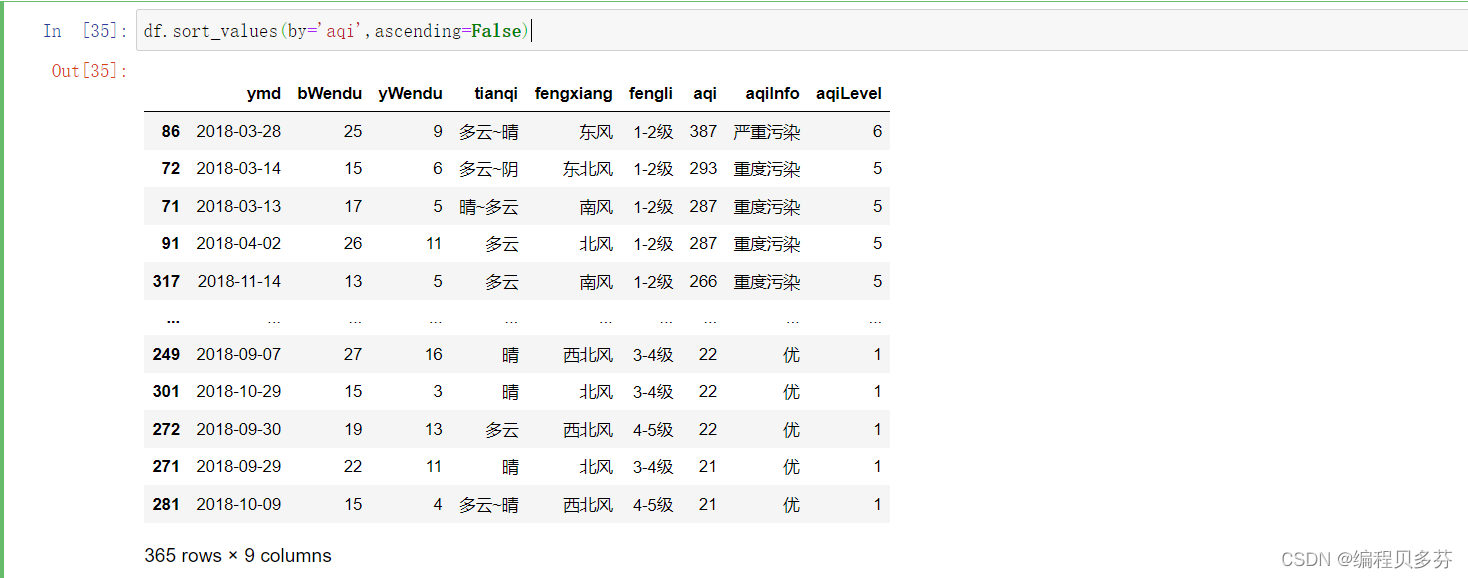
3.2多列排序
按空气质量等级、最高温度排序、默认升序
- #按空气质量等级、最高温度排序、默认升序
- df.sort_values(by=['aqiLevel','bWendu'])

两个字段都是降序排序 df.sort_values(by=['aqiLevel','bWendu'],ascending=False)
- #两个字段都是降序排序
- df.sort_values(by=['aqiLevel','bWendu'],ascending=False)

分别指定升序和降序
df.sort_values(by=['aqiLevel','bWendu'],ascending=[True,False])- #分别指定升序和降序
- df.sort_values(by=['aqiLevel','bWendu'],ascending=[True,False])

九、Pandas 的字符串处理操作
0、Pandas字符串处理
前面我们已经使用了字符串的处理函数:
df["bWendu"].str.replace("℃","").astype('int32')Pandas的字符串处理:1.使用方法:先获取Series的str属性,然后在属性上调用函数;
2.只能在字符串列上使用,不能数字列上使用;
3. Dataframe上没有str属性和处理方法
4.Series.str并不是Python原生字符串,而是自己的一套方法,不过大部分和原生str很相似;
内容如下:
1.获取Series的str属性,然后使用各种字符串处理函数
2.使用str的startswith、contains等bool类Series可以做条件查询
3.需要多次str处理的链式操作
4.使用正则表达式的处理
1、分步骤读取数据
- import pandas as pd
- fpath='./datas/beijing_tianqi/beijing_tianqi_2018.csv'
- df=pd.read_csv(fpath)
- df.head()

df.dtypes
2、获取Series的str属性,使用各种字符串处理函数
获取最高温度的Series的温度列
- #获取最高温度的Series的温度列
- df['bWendu'].str

字符串替换函数
- #字符串替换函数
- df['bWendu'].str.replace('℃','')

判断是不是数字
- #判断是不是数字
- df['bWendu'].str.isnumeric()

- df['aqi'].str.len()
- #AttributeError: Can only use .str accessor with string values! len()方法只能用于字符串类型的数据
AttributeError: Can only use .str accessor with string values! len()方法只能用于字符串类型的数据
3、使用str 的startwith、contains等得到bool的Series可以做条件查询
Pandas startswith()是另一种在系列或 DataFrame 中搜索和过滤文本数据的方法。此方法类似于Python的startswith()方法,但参数不同,并且仅适用于Pandas对象。因此,.str必须在每次调用此方法之前加上前缀,以便编译器知道它与默认函数不同。
用法:Series.str.startswith(pat, na=nan)
参数:
pat:要搜索的字符串。 (不接受正则表达式)
na:用于设置序列中的值为NULL时应显示的内容。返回类型:布尔序列,为True,其中值的开头是传递的字符串。
从ymd这一列挑选出2018-03这类型的数据,返回的是一个Boolean类型
- #从ymd这一列挑选出2018-03这类型的数据,返回的是一个Boolean类型
- condition=df['ymd'].str.startswith('2018-03')
- condition

输出在condition条件下的df中的数据
- #输出在condition条件下的df中的数据
- df[condition].head()

4、需要多次str处理的链式操作
1、先将日期2018-03-31替换成20180331的形式
2、提取月份字符串201803df['ymd'].str.replace('-','')
问题:直接在Series上面调用方法的话,是否可行?
答:不可行
原因:每次调用函数,都会返回一个新的series
df['ymd'].str.replace('-','').slice(0,6)
'Series' object has no attribute 'slice'---意思就是series不能够直接去调用slice函数,必须经过str调用后才可以使用- #原因:每次调用函数,都会返回一个新的series
- df['ymd'].str.replace('-','').slice(0,6)
- #'Series' object has no attribute 'slice'---意思就是series不能够直接去调用slice函数,必须经过str调用后才可以使用
df['ymd'].str.replace('-','').str.slice(0,6)slice是切片操作,也可以直接为str[0:6]
- #slice是切片操作,也可以直接为str[0:6]
- df['ymd'].str.replace('-','').str[0:6]

5、使用正则表达式的处理
- #添加新列
- def get_riqi(x):
- year,month,day=x['ymd'].split('-')
- return f'{year}年{month}月{day}日'
- df['中文日期']=df.apply(get_riqi,axis=1)
- df['中文日期']

new question? -----如何将日期中,年月日三个字去除
方法1:链式replace
- #方法1:链式replace
- df['中文日期'].str.replace('年','').str.replace('月','').str.replace('日','')

Series.str默认开启了正则表达式模式
方法2:正则表达式替换
- #方法2:正则表达式替换
- df['中文日期'].str.replace('[年月日]','',regex=True)

注:
The default value of regex will change from True to False in a future version.
在Pandas未来的版本中,.str.replace() 的regex的默认值将从True变为False
而当regex=True时,单字符正则表达式不会被视为文本字符串
因为我们是针对price中两个单个字符进行操作,因此设置regex=True
十、Pandas的axis参数【详解】--Pandas和Numpy的结合
0、Pandas的axis参数怎么理解?
. axis=O或者"index":
·如果是单行操作,就指的是某一行
·如果是聚合操作,指的是跨列cross columns
. axis=1或者"columns":
-如果是单列操作,就指的是某一列
·如果是聚合操作,指的是跨列cross columns按哪个axis,就是这个axis要动起来(类似被or遍历),其它的axis保持不动
- import pandas as pd
- import numpy as np
- df=pd.DataFrame(
- np.arange(12).reshape(3,4),
- columns=['A','B','C','D']
- )
- df

1、单列drop,就是删除一列
代表的就是删除某列
- #代表的就是删除某列
- df.drop('A',axis=1)

2、单行drop,就是删除一行
代表的就是删除某行
- #代表的就是删除某行
- df.drop(1,axis=0)

3、按axis=0/index执行Mean聚合操作
并不是像我们想象的那个样子,输出的是每列的结果!!!
axis=0 or axis=index
- # axis=0 or axis=index
- df.mean(axis=0)


指定了按那个axis,就是这个axis要动起来(类似被for遍历),其他的axis保持不动
4、按axis=1/colums执行mean聚合操作
并不是像我们想象的那个样子,输出的是每行的结果!!
axis=1 or axis=colums
- # axis=0 or axis=colums
- df.mean(axis=1)


指定了按那个axis,就是这个axis要动起来(类似被for遍历),其他的axis保持不动
5、举例证明
- def get_sum(x):
- return x['A']+x['B']+x['C']+x['D']
- df['sum']=df.apply(get_sum,axis=1)
- df
- #跨列相加

十一、Pandas的索引index所具备的四大性能
0、Pandas的索引index
Pandas的索引index的用途:
把数据存储于普通的column列也能用于数据查询,那使用index有什么好处?
index的用途总结:
1.更方便的数据查询;
2.使用index可以获得性能提升;
3.自动的数据对齐功能;
4.更多更强大的数据结构支持;
1.更方便的数据查询
- import pandas as pd
- df=pd.read_csv('./datas/ml-latest-small/ratings.csv')
- df.head()

查询index的数量:df.count()
df.count()
drop==False,让索引列还保持在column:意思就是使id这一列继续存在于数据当中
- #drop==False,让索引列还保持在column:意思就是使id这一列继续存在于数据当中
- df.set_index('userId',inplace=True,drop=False)
- df.head()

df.index
第一种:使用index查询的方法---会使查询的代码比较简单
df.loc[500].head()- #第一种:使用index查询的方法---会使查询的代码比较简单
- df.loc[500].head()

第二种:使用column的condition查询方法
condition=df['userId']
df.loc[condition==500].head()- #第二种:使用column的condition查询方法
- condition=df['userId']
- df.loc[condition==500].head()

2.使用index会提升查询性能¶
如果index是唯一的,Pandas会使用哈希表优化,查询性能为O(1);
如果index不是唯一的,但是有序,Pandas会使用二分查找算法,查询性能为O(logN);
如果index是完全随机的,那么每次查询都要扫描全表,查询性能为O(N);

实验1:完全随机的顺序查询
将数据随机打散
- !pip install sklearn
- #将数据随机打散
- from sklearn.utils import shuffle
- df_shuffle=shuffle(df)
- df_shuffle.head()

查询我们的索引是不是递增的
df_shuffle.index.is_monotonic_increasing- #查询我们的索引是不是递增的
- df_shuffle.index.is_monotonic_increasing
查询我们的索引是不是递减的
df_shuffle.index.is_monotonic_decreasing- #查询我们的索引是不是递减的
- df_shuffle.index.is_monotonic_decreasing
%timeit 函数是经过大量运算,统计计算出平均运行所用的时间
计时,查询id==500数据性能
%timeit df_shuffle.loc[500]- # %timeit 函数是经过大量运算,统计计算出平均运行所用的时间
- # 计时,查询id==500数据性能
- %timeit df_shuffle.loc[500]

实验2:将index排序后查询
调用sort函数默认为升序操作
- #调用sort函数默认为升序操作
- df_sorted=df_shuffle.sort_index()
- df_sorted.head()
- df_sorted.index.is_monotonic_increasing
调用sort函数默认为降序操作 设置为ascending=False为降序操作
- #调用sort函数默认为降序操作 设置为ascending=False为降序操作
- df_sorted2=df_shuffle.sort_index(ascending=False)
- df_sorted2.index.is_monotonic_decreasing
判断索引是不是唯一的
df_sorted.index.is_unique- #判断索引是不是唯一的
- df_sorted.index.is_unique
如果index不是唯一的,但是有序,Pandas会使用二分查找算法,查询性能为O(logN);
%timeit df_sorted.loc[500]- #如果index不是唯一的,但是有序,Pandas会使用二分查找算法,查询性能为O(logN);
- %timeit df_sorted.loc[500]

3、使用index能自动对齐数据
包括series和dataframe
index会自动对齐
- #index会自动对齐
- s1=pd.Series([1,2,3],index=list('abc'))
- s1
- s2=pd.Series([2,3,4],index=list('bcd'))
- s2
当s1+s2中遇到另一方没有找到相同的索引时,会显示NaN,无法进行算术操作时
- #当s1+s2中遇到另一方没有找到相同的索引时,会显示NaN,无法进行算术操作时
- s1+s2

4.使用index更多更强大的数据结构支持
很多强大的索引数据结构
Categoricallndex,基于分类数据的Index,提升性能;
Multilndex,多维索引,用于groupby多维聚合后结果等;
Datetimelndex,时间类型索引,强大的日期和时间的方法支持;
十二、Pandas的Merge语法(内含设置行名方法)
1、 Pandas怎样实现DataFrame的Merge
Pandas的Merge,相当于Sql的Join,将不同的表按key关联到一个表
merge的语法:
pd.merge(left,right, how='nner , on=None,left_on=None, right_on=None,lef_index=False,right_index=False,sort=True, sufises=(‘_X’ ,“_Y” ), opy=Tue,indicator=False, validate=None)
left,right:要merge的dataframe或者有name的Series.
how: join类型,'left', 'right', 'outer', 'inner'
on: join的key,left和right都需要有这个key.
left_on: left的df或者series的key
right_on: right的df或者seires的key
left_index,right_index:使用index而不是普通的column做join
suffixes:两个元素的后缀,如果列有重名,自动添加后缀,默认是('_X','_y')本次讲解提纲:
1.电影数据集的join实例
2.理解merge时一对一、一对多、多对多的数量对齐关系
3.理解left join、right join、inner join、outer join的区别
4.如果出现非Key的字段重名怎么办- import pandas as pd
- df_ratings=pd.read_csv(
- './datas/movielens-1m/ratings.dat',
- sep="::",#设置其分隔服为::
- engine='python',#因为pandas语法中sep为两个字符的时候,系统默认其为正则表达式,但是分隔符就是::不是正则表达式,所以加engine=python
- names='UserID::MovieID::Rating::Timestamp'.split('::')
- )
- df_ratings.head()

- df_users=pd.read_csv(
- './datas/movielens-1m/users.dat',
- sep="::",
- engine='python',
- names='UserID::Gender::Age::Occupation::Zip-code'.split('::')
- )
- df_users.head()

- df_movies=pd.read_csv(
- './datas/movielens-1m/movies.dat',
- sep='::',
- engine='python',
- names='MovieID::Tile::Genres'.split("::")
- )
- df_movies.head()

- df_ratings_users=pd.merge(
- df_ratings,df_users,on='UserID',how='inner'
- )
- df_ratings_users.head()

- df_ratings_users_movies=pd.merge(
- df_ratings_users,df_movies,left_on='MovieID',right_on='MovieID',how='inner'
- )
- df_ratings_users_movies.head()

2、理解merge时数量的对齐关系以下关系要正确理解:
. one-to-one:—对一关系,关联的key都是唯一的
.比如(学号,姓名) merge (学号,年龄)
-结果条数为:1*1
. one-to-many:一对多关系,左边唯一key,右边不唯一key
-比如(学号,姓名) merge(学号,[语文成绩、数学成绩、英语成绩])
结果条数为:1*N
. many-to-many : [多对多关系,左边右边都不是唯一的
·比如(学号,[语文成绩、数学成绩、英语成绩])merge (学号,[篮球、足球、乒乓球)
-结果条数为:M*N
2.1 one-to-one 一对一关系的merge

- left=pd.DataFrame({
- 'sno':[11,12,13,14],
- 'name':['name_a','name_b','name_c','name_d']
- }
- )
- left

- right=pd.DataFrame({
- 'sno':[11,12,13,14],
- 'age':['21','22','23','24']
- })
- right

- #一对一关系中:结果有四条
- pd.merge(left,right,on='sno')

2.2 one-to-many一对多关系的
merge注意:数据会被制

- left=pd.DataFrame({
- 'sno':[11,12,13,14],
- 'name':['name_a','name_b','name_c','name_d']
- }
- )
- left


- right=pd.DataFrame({
- 'sno':[11,11,11,12,12,13],
- 'grade':['英语:21','语文:22','数学:23','英语:24',"语文:11","数学:55"]
- })
- right

- #一对多的关系对name名字进行了复制
- pd.merge(left,right,on='sno')

2.3 many-to-many多对多关系的merge
注意:结果数量会出现乘法

- left=pd.DataFrame({
- 'sno':[11,11,12,12,12],
- '爱好':['篮球','羽毛球','乒乓球','篮球','足球']
- }
- )
- left
- right=pd.DataFrame({
- 'sno':[11,11,11,12,12,13],
- 'grade':['英语:21','语文:22','数学:23','英语:24',"语文:11","数学:55"]
- })
- right

pd.merge(left,right,on='sno')
3、理解left join、right join、inner join、outer join的区别

- left=pd.DataFrame({
- 'key':['ko','k1','k2','k3'],
- 'A':['A0','A1','A2','A3'],
- 'B':['B0','B1','B2','B3']
- })
- right=pd.DataFrame({
- 'key':['k0','k1','k2','k3'],
- 'C':['C0','C1','C2','C3'],
- 'D':['D0','D1','D2','D3']
- })
- left

3.1 inner join,默认
左边和右边的key都有,才会出现在结果里
pd.merge(left,right,how='inner')
3.2 left join
左边的都会出现在结果里,右边的如果无法匹配则为Null
pd.merge(left,right,how='left')
3.3 right join
右边的都会出现在结果里,左边的如果无法匹配则为Nul
pd.merge(left,right,how='right')
3.4 outer join
左边、右边的都会出现在结果里,如果无法匹配则为Null
pd.merge(left,right,how='outer')
4、如果出现非Key的字段重名怎么办
- left=pd.DataFrame({
- 'key':['K0','k1','k2','k3'],
- 'A':['A0','A1','A2','A3'],
- 'B':['B0','B1','B2','B3']
- })
- right=pd.DataFrame({
- 'key':['K0','K1','K4','K5'],
- 'A':['A10','A11','A12','A13'],
- 'D':['D0','D1','D4','D5']
- })
- left

pd.merge(left,right,on='key')suffixes=('name1','name2')可以直接设置重名函数的函数名
pd.merge(left,right,on='key',suffixes=('_left','_right'))- #suffixes=('name1','name2')可以直接设置重名函数的函数名
- pd.merge(left,right,on='key',suffixes=('_left','_right'))

十三、Pandas 的Concat合并【实现Concat合并】
0、 Pandas实现数据的合并concat
使用场景:
批量合并相同格式的Excel、给DataFrame添加行、给DataFrame添加列
一句话说明concat语法:
。使用某种合并方式(inner/outer)
·沿着某个轴向(axis=0/1)
·把多个Pandas对象(DataFrame/Series)合并成一个。
concat语法: pandas.concat(objs, axis=0, join='outer', ignore_index=False)
. objs: 一个列表,内容可以是DataFrame或者Series,可以混合
. axis: 默认是0代表按行合并,如果等于1代表按列合并
. join:合并的时候索引的对齐方式,默认是outer join,也可以是inner join.
ignore_index:是否忽略掉原来的数据索引
append语法: DataFrame.append(other, ignore_index=False)
append只有按行合并,没有按列合并,相当于concat按行的简写形式.
other:单个dataframe、series、dict,或者列表
ignore_index:是否忽略掉原来的数据索引
- import pandas as pd
- import warnings
- warnings.filterwarnings('ignore')
1、使用pandas.concat合并数据
- df1=pd.DataFrame({
- 'A':['A0','A1','A2','A3'],
- 'B':['B0','B1','B2','B3'],
- 'C':['C0','C1','C2','C3'],
- 'D':['D0','D1','D2','D3'],
- 'E':['E0','E1','E2','E3']
- })
- df2=pd.DataFrame({
- 'A':['A4','A5','A6','A7'],
- 'B':['B4','B5','B6','B7'],
- 'C':['C4','C5','C6','C7'],
- 'D':['D4','D5','D6','D7'],
- 'F':['F4','F5','F6','F7']
- })
- df1

df21、默认的concat,参数为axis=0、 join=outer、ignore_index=False
因为默认axis=0,即第二个df2的值默认放在第一个df1内容的下面,即所谓的行合并
pd.concat([df1,df2])- #因为默认axis=0,即第二个df2的值默认放在第一个df1内容的下面,即所谓的行合并
- pd.concat([df1,df2])

2、使用ignore_index=True可以忽略原来的索引
忽略原来的缩影的列,从0,1,2,3........
pd.concat([df1,df2],ignore_index=True)
3、使用join=inner过滤掉不匹配的列
意思就是只要任意一组没有就进行过滤
pd.concat([df1,df2],ignore_index=True,join='inner')- #意思就是只要任意一组没有就进行过滤
- pd.concat([df1,df2],ignore_index=True,join='inner')

4、使用axis=1相当于添加新列
df1
A:添加一列Series
- s1=pd.Series(list(range(4)),name='F')
- s1
- pd.concat([df1,s1],axis=1)
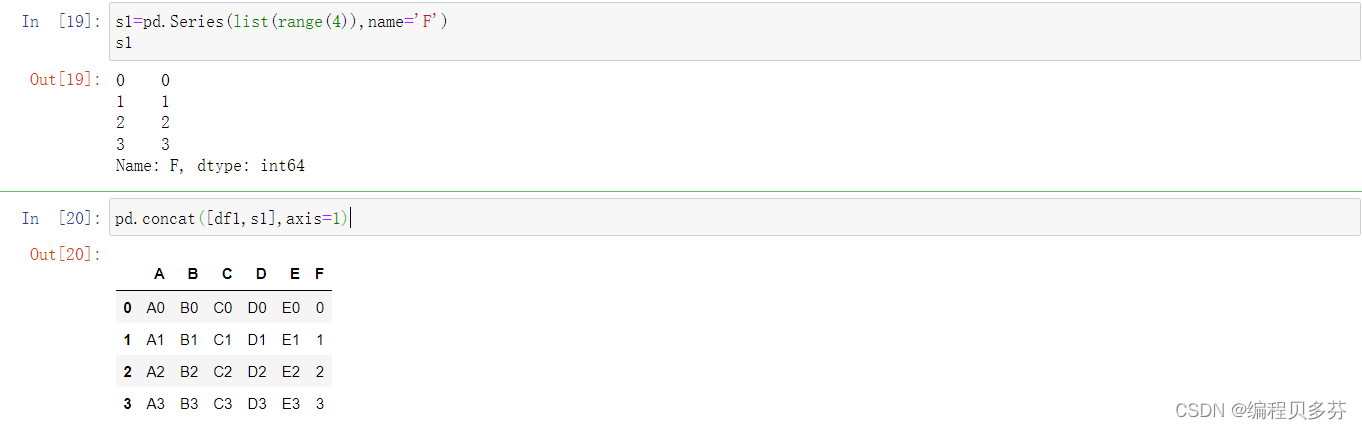
B:添加多列Series
- s2=df1.apply(lambda x:x["A"]+'_11',axis=1)
- s2
- s2.name='G'
- pd.concat([df1,s1,s2],axis=1)
- #列表中可以只有Series
- pd.concat([s1,s2],axis=1)
- #列表也可以是混合顺序的
- pd.concat([s1,df1,s2],axis=1)


二、使用DataFrame.append按行进行合并数据
- df1=pd.DataFrame([[1,2],[3,4]],columns=list('AB'))
- df1
- df2=pd.DataFrame([[5,6],[7,8]],columns=list('AB'))
- df2

1、给一个dataframe添加另一个dataframe
df1.append(df2)
2、忽略原来的索引ignore_index=True
df1.append(df2,ignore_index=True)
3、可以一行行的给DataFrame添加数据
- #一个空的df
- df=pd.DataFrame(columns=['A'])
- df

A:低新能版本
- for i in range(5):
- #利用这种循环,每次都在复制
- df=df.append({'A':i},ignore_index=True)
- df

B:高新能版本
- #第一个入参的是列表,避免了多次的复制,直接往里面添加就可以了
- pd.concat(
- [pd.DataFrame([i],columns=['A']) for i in range(5)],
- ignore_index=True
- )

十四、Pandas批量拆分与合并Excel文件
0、 Pandas批量拆分Excel与合并Excel
实例演示:
1.将一个大Excel等份拆成多个Excel
2.将多个小Excel合并成一个大Excel并标记来源
- #本节课的数据目录work_dir
- work_dir='./course_datas/c15_excel_split_merge'
- #work_dir下面的splits目录,来放置拆分后的小文件
- splits_dir=f'{work_dir}/splits'
- import os
- #如果splits_dir目录不存在就创建一个小目录
- if not os.path.exists(splits_dir):
- os.mkdir(splits_dir)
1、读取源Excel到Pandas
- import pandas as pd
- df_source=pd.read_excel(f'{work_dir}/crazyant_blog_articles_source.xlsx')
- df_source.head()

- df_source.index
- df_source.shape
- total_row_count=df_source.shape[0]
- total_row_count

一、将一个大Excel等份拆成多个Excel
1.使用df.iloc方法,将一个人的dataframe,拆分成多个小dataframe
2.将使用dataframe.to_excel保存每个小Excel
1、计算拆分后的每个excel的行数
- #将一个大的EXCEL文件拆分给这几个人
- user_name=['xiaohu','xiaoshuai','xiaolan','xiaofan','xiaok','xiaom']
- #每个人的任务数目
- splits_size=total_row_count//len(user_name)
- #判断每个人分配的任务数是否为整数,若不为整数则+1
- if total_row_count % len(user_name) !=0:
- splits_size+=1
- splits_size

2、拆分成多个dataframe
- #将拆出来的小的dataframe存在df_sub[]当中
- df_subs=[]
- for index,user_name in enumerate(user_name):
- #iloc的开始索引,从0开始进行索引
- begin=index*splits_size
- #iloc的结束索引
- end=begin+splits_size
- #实现df按照iloc拆分
- df_sub=df_source.iloc[begin:end]
- #将每个子df存入列表
- df_subs.append((index,user_name,df_sub))
3、将每个datafame存入excel
- for index,user_name,df_sub in df_subs:
- file_name=f'{splits_dir}/crazyant_blog_articles_{index}_{user_name}.xlsx'
- df_sub.to_excel(file_name,index=False)
二、合并多个小Excel到一个大Excel
1.遍历文件夹,得到要合并的Excel文件列表
2.分别读取到dataframe,给每个df添加—列用于标记来源
3.使用pd.concat进行df批量合并
4.将合并后的dataframe输出到excel
1、遍历文件夹,得到要合并的Excel名称列表
- import os
- excel_names=[]
- for excel_name in os.listdir(splits_dir):
- excel_names.append(excel_name)
- excel_names
- #os.listdir() 方法用于返回指定的文件夹包含的文件或文件夹的名字的列表。

2、分别读取到dataframe
- df_list=[]
- for excel_name in excel_names:
- #将每个excel读取到df当中
- excel_path=f'{splits_dir}/{excel_name}'
- df_split=pd.read_excel(excel_path)
- #得到username
- username=excel_name.replace('crazyant_blog_articles_','').replace('.xlsx','')[2:]
- print(excel_name,username)
- #给每个df添加1列,即用户名字
- df_split['username']=username
- df_list.append(df_split)

3、使用pd.concat进行合并
- df_merged=pd.concat(df_list)
- df_merged.shape
- df_merged.head()

df_merged['username'].value_counts()
4、将合并后的dataframe输出到excel中
df_merged.to_excel(f'{work_dir}/crazyant_blog_articles_merged.xlsx',index=False)十五、Pandas怎样实现groupby分组统计
0、 Pandas怎样实现groupby分组统计
类似SQL: select city,max(temperature) from city_weather group by city;
groupby:先对数据分组,然后在每个分组上应用聚合函数、转换函数本次演示:
一、分组使用聚合函数做数据统计
二、遍历groupby的结果理解执行流程
三、实例分组探索天气数据
- import pandas as pd
- import numpy as np
- #在jupyter notebook中展示matplot图表
- %matplotlib inline
- df=pd.DataFrame({
- 'A':['foo','bar','foo','bar','foo','bar','foo','foo'],
- 'B':['one','one','two','three','one','one','two','three'],
- 'C':np.random.randn(8),
- 'D':np.random.randn(8)
- })
- df

1、分组使用聚合函数做数据统计
1、单个列groupby,查询所有数据列的统计
- P=df.groupby('A').sum()
- #聚合操作后P仍然是一个Dataframe
- P

df.groupby('name').sum()
Ps: 1、将name列的不同名称作为索引
- 2、忽略df中不是数字列的一列
- 3、对是数字列的一列进行累加
- 4、统计在name不同名称下的,其他值的和
2、多个列groupby,查询所有数据列的统计
df.groupby(['A','B']).mean()
1、选取A、B两列的不同名称作为索引---在这里因为A列的bar没有B列中的two所以没有
2、对数字列进行求取平均值
3、统计在不同名下的平均值
4、将A、B变成二级索引
- #设置as_index=False,取消A、B作为二级索引
- df.groupby(['A','B'],as_index=False).mean()

3、同时查看多种数据统计
df.groupby('A').agg([np.sum,np.mean,np.std])
1、将name列的不同名称作为索引
- 2、忽略df中不是数字列的一列
- 3、对是数字列的一列进行操作
- 4、统计在name不同名称下的,其他值的和
列变成了多级索引
4、查看单列的结果数据统计
- #方法1:预过滤,性能更好
- df.groupby('A')['C'].agg([np.sum,np.mean,np.std])

- #方法2:
- df.groupby('A').agg([np.sum,np.mean,np.std])['C']

5、不同列使用不同的聚合函数
- df.groupby('A').agg({
- 'C':np.sum,
- 'D':np.mean
- })

二、遍历groupby的结果理解执行流程
for循环可以直接遍历每个group
1、遍历单个列聚合的分组
- g=df.groupby('A')
- g
- #相当于对A索引的不同值的列进行一个汇总,使数据看起来更加的清晰
- for name,group in g:
- print(name)
- print(group)
- print( )

可以获取单个分组的数据
g.get_group('bar')
2、遍历多个列聚合的分组
- g=df.groupby(['A','B'])
- for name,group in g:
- print(name)
- print(group)
- print( )
- #name 是一个2个元素的元组,代表不同的列

可以直接查询group后的某几列,生成Series或者子DataFrame
- g['C']
- for name,group in g:
- print(name)
- print(group)
- print( )

本质:所有的聚合统计,都是在dataframe和series上进行的
三、实例分组探索天气数据
- fpath='./datas/beijing_tianqi/beijing_tianqi_2018.csv'
- df=pd.read_csv(fpath)
- df

- #替换掉温度后缀℃
- df.loc[:,'bWendu']=df['bWendu'].str.replace('℃','')
- df.loc[:,'yWendu']=df['yWendu'].str.replace('℃','')
- df

- df2=df.drop(labels=['bWendu','yWendu'], axis=0, inplace=False)
- df2
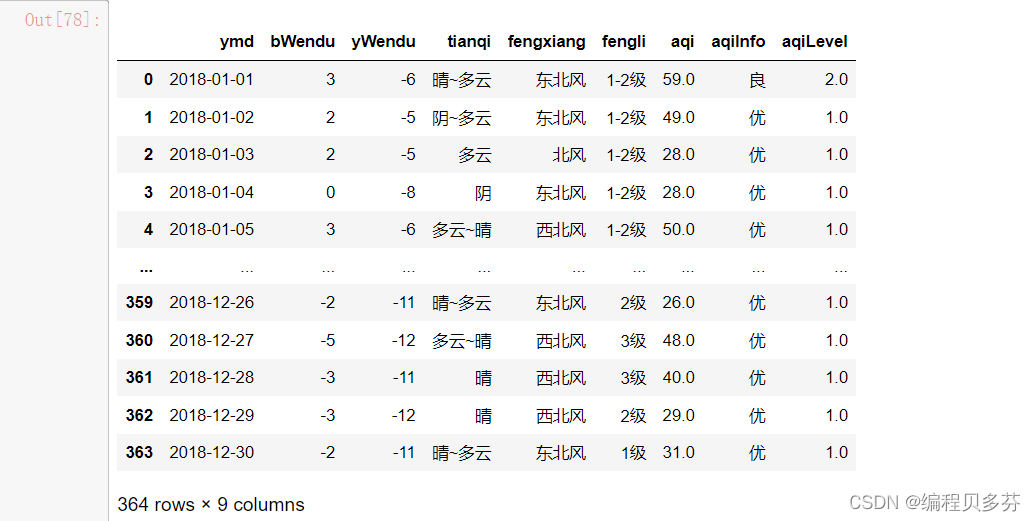
- df2.loc[:,'bWendu']=df2['bWendu'].astype('int32')
- df2.loc[:,'yWendu']=df2['yWendu'].astype('int32')
- df2.head()

- #新增一列为月份
- df['month']=df['ymd'].str[:7]
- df.head()

1、查看每个月的最高温度
- data=df.groupby('month')['bWendu'].max()
- data

- type(data)
- data=data.astype(float)
- data.plot()

2、查看每个月的最高温度、最低温度、平均空气质量指数
- df.head()
- group_data=df.groupby('month').agg({'bWendu':np.max,'yWendu':np.min,'aqi':np.mean})
- group_data


group_data.plot()
十六、Pandas的分层索引MultiIndex怎么用?
0、 Pandas的分层索引Multilndex¶
1为什么要学习分层索引Multilndex?
1、分层索引:在一个轴向上拥有多个索引层级,可以表达更高维度数据的形式;
2、方便的进行数据筛选,如果有序则性能更好;
3、groupby等操作的结果,如果是多KEY,结果是分层索引,需要会使用。
4、一般不需要自己创建分层索引(Multilndex有构造函数但一般不用)
演示数据:百度、阿里巴巴、爱奇艺、京东四家公司的10天股票数据数据来自:英为财经
—、Series的分层索引Multilndex
二、Series有多层索引怎样筛选数据?
三、DataFrame的多层索引Multilndex
四、DataFrame有多层索引怎样筛选数据?
- import pandas as pd
- %matplotlib inline
- stocks=pd.read_excel('./datas/stocks/互联网公司股票.xlsx')
- stocks.shape
stocks
- stocks['公司'].unique()
- stocks.index
- #计算每个公司收盘的平均值
- stocks.groupby('公司')['收盘'].mean()

1、Series的分层索引MultiIndex
- ser=stocks.groupby(['公司','日期'])['收盘'].mean()
- ser
ser.index- # unstack把二级索引变成列
- ser.unstack()
- ser
- #全部变成一维的普通索引模式
- ser.reset_index()


 2、Series有多层索引Multilndex怎样筛选数据?
2、Series有多层索引Multilndex怎样筛选数据?- ser
- ser.loc['BIDU']
- # 多层索引,可以用元组的形式进行筛选
- ser.loc[('BIDU','2019-10-02')]

- #求所有公司中指定月份的收盘价
- ser.loc[:,'2019-10-02']

3、DataFrame的多层索引Multilndex
- stocks.head()
- stocks.set_index(['公司','日期'],inplace=True)
- stocks

- stocks.index
- #自动根据索引进行排序,默认为升序排列
- stocks.sort_index(inplace=True)
- stocks


4、DataFrame有多层索引Multilndex怎样筛选数据?
【重要知识】在选择数据时:
。元组(key1.key2)代表筛选多层索引,其中key1是索引第一级,key2是第二级,比如key1=JD, key2=2019-10-02
·列表[key1,key2]代表同一层的多个KEY,其中key1和key2是并列的同级索引,比如key1=JD, key2=BIDU
stocks.loc['BIDU']
- # 'BIDU'是一级索引 '2019-10-02'是二级索引
- stocks.loc[('BIDU','2019-10-02'),:]

stocks.loc[('BIDU','2019-10-02'),'开盘']
- #设置日期的同一级索引的格式
- stocks.loc[('BIDU',['2019-10-03','2019-10-02']),'收盘']

- #slice(None)代表筛选中一索引的所有内容---在这里的意思就是筛选一级索引‘公司’的所有内容
- stocks.loc[(slice(None),['2019-10-03','2019-10-02']),:]

- #将多重索引全部重置,转换为一维索引
- stocks.reset_index()

十七、Pandas的数据转换函数--map、apply、applymap
0、Pandas的数据转换函数map.apply、applymap
数据转换函数对比: map、apply、applymap
1.map用于Series值的转换
实例:将股票代码英文转换成中文名字
Series.map(dict) or Series.map(function)均可
- import pandas as pd
- stocks=pd.read_excel('./datas/stocks/互联网公司股票.xlsx')
- stocks.head()

stocks['公司'].unique()- #公司股票代码到中文的映射,注意这里要小写
- dict_company_names={
- 'bidu':'百度',
- 'baba':'阿里巴巴',
- 'iq':'爱奇艺',
- 'jd':'京东'
- }

方法1:Series.map(dict) ----在map函数中传进去一个字典只用于Series
- # stocks['公司'].str.lower()---将公司中的所有字母转换为小写字母
- # .map(dict_company_names)--把公司中所有对应的列转换为其对应的中文字母
- stocks['公司中文1']=stocks['公司'].str.lower().map(dict_company_names)
- stocks.head()

方法2:Series.map(function) ----在map函数中传进去一个自定义函数只用于Series
function的参数是Series的每个元素的值
- stocks['公司中文2']=stocks['公司'].map(lambda x:dict_company_names[x.lower()])
- stocks.head()

2.apply用于Series和DataFrame的转换---既可以用于Series也可以用于DataFrame
Series.apply(function),函数的参数是每个值.
DataFrame.apply(function),函数的参数是Series
Series.apply(function)
function的参数是Series的每个值
- stocks['公司中文3']=stocks['公司'].apply(
- lambda x:dict_company_names[x.lower()]
- )
- stocks.head()

DataFrame.apply(function)
function的参数是对应轴的Series
- stocks['公司中文4']=stocks.apply(
- lambda x:dict_company_names[x['公司'].lower()],
- axis=1
- )
- stocks.head()

注意这个代码:
- 1、apply是在stocks这个DataFrame上调用;
- 2、lambda x的x是一个Series,因为指定了axis=1所以Seires的key是列名,可以用x[公司"]获取
3.applymap用于DataFrame所有值的转换
- sub_df=stocks[['收盘','开盘','高','低','交易量']]
- sub_df.head()

- #将这些数字取整数,应用于所有元素
- sub_df.applymap(lambda x:int(x))

- #直接修改原df的这几列
- stocks.loc[:,['收盘','开盘','高','低','交易量']]=sub_df.applymap(lambda x:int(x))
- stocks.head()

十八、Pandas如何对每个分组应用apply函数
0、 Pandas怎样对每个分组应用apply函数?
知识:Pandas的GroupBy遵从split、apply.combine模式

这里的split指的是pandas的groupby,我们自己实现apply函数,apply返回的结果由pandas进行combine得到结果
GroupBy.apply(function)
. function的第一个参数是dataframe
. function的返回结果,可是dataframe、series、单个值,甚至和输入dataframe完全没关系
本次内容:
1.怎样对数值列按分组的归—化?
2.怎样取每个分组的TOPN数据?
实例1:怎样对数值列按分组的归一化?
将不同范围的数值列进行归一化,映射到[0,1]区间:
·更容易做数据横向对比,比如价格字段是几百到几千,增幅字段是0到100
·机器学习模型学的更快性能更好
归一化的公式:

演示:用户对电影评分的归一化
每个用户的评分不同,有的乐观派评分高,有的悲观派评分低,按用户做归—化- import pandas as pd
- ratings=pd.read_csv(
- './datas/movielens-1m/ratings.dat',
- sep='::',
- engine='python',
- names='UserID::MovieID::Rating::Timestamp'.split('::')
- )
- ratings.head()

- #实现按照用户ID分组,然后对其中一列进行归一化
- def ratings_room(df):
- '''
- 每个用户分组的dataframe
- '''
- min_value=df['Rating'].min()
- max_value=df['Rating'].max()
- df['Rating_rooms']=df['Rating'].apply(
- lambda x:(x-min_value)/(max_value-min_value)
- )
- return df
- ratings=ratings.groupby('UserID').apply(ratings_room)
- ratings.head()

ratings[ratings['UserID']==1].head()
看到UserID==1这个用户,Rating==3是他的最低分,是个乐观派,我们归一化到0分
实例2:怎样取每个分组的TOPN数据?
获取2018年每个月温度最高的2天数据
- df=pd.read_csv(
- './datas/beijing_tianqi/beijing_tianqi_2018.csv'
- )
- df.loc[:,'bWendu']=df['bWendu'].str.replace('℃','').astype('int32')
- df.loc[:,'yWendu']=df['yWendu'].str.replace('℃','').astype('int32')
- #创建一个新的列为月份列
- df['month']=df['ymd'].str[:7]
- df

- def getWenduTopn(df,topn):
- '''
- 这里的df,是每个月份分组的group的df
- '''
- df2=df.sort_values(by='bWendu')[['ymd','bWendu']][-topn:]
- return df2
- df.groupby('month').apply(getWenduTopn,topn=2).head()

十九、Pandas使用stack和pivot实现数据透视
0、Pandas的stack和pivot实现数据透视
将列式数据变成二维交叉形式,便于分析,叫做重塑或透视

1.经过统计得到多维度指标数据
2.使用unstack实现数据二维透视
3.使用pivot简化透视
4.stack、unstack、pivot的语法
1.经过统计得到多维度指标数据
非常场景的统计场景,指定多个维度,计算聚合后的指标
实例:统计得到"电影评分数据集”,每个月份的每个分数被评分多少次:(月份、分数1~5、次数)
- import pandas as pd
- import numpy as np
- %matplotlib inline
- df=pd.read_csv(
- './datas/movielens-1m/ratings.dat',
- sep='::',
- engine='python',
- names='UserID::MovieID::Rating::Timestamp'.split('::')
- )
- df.head()

- df['pdata']=pd.to_datetime(df['Timestamp'],unit='s')
- df.head()

df.dtypes- #实现数据统计
- df_group=df.groupby([df['pdata'].dt.month,'Rating'])['UserID'].agg(pv=np.sum)
- df_group.head()

对于这样的格式数据,查看按月份,不同评分的次数趋势,是没法实现的
需要将数据变换成每个评分是一列才可以实现
2.使用unstack实现数据二维透视
目的:想要画图对比按照月份的不同评分的数量趋势
- df_stack=df_group.unstack()
- df_stack

df_stack.plot()
- #unstack和stack是互逆操作
- df_stack.stack().head()

3、使用pivot简化透视
df_group.head()- df_reset=df_group.reset_index()
- df_reset.head()

- #因为是二维的---pdata代表x轴,Rating代表y轴,pv代表数据
- df_pivot=df_reset.pivot('pdata','Rating','pv')
- df_pivot.head()

df_pivot.plot()
pivot方法相当于对df使用set_index的创建分层索引,然后调用unstack¶
4.stack、unstack、pivot的语法
stack: DataFrame.stack(level=-1, dropna=True),将column变成index,类似把横放的书籍变成竖放
level=-1代表多层索引的最内层,可以通过==0、1、2指定多层索引的对应层

unstack: DataFrame.unstack(level=-1, fill_value=None),将index变成column,类似把竖放的书籍变成横放

pivot: DataFrame.pivot(index=None , columns=None, values=None),指定index、columns、values实现二维透视¶

-
相关阅读:
rsync远程同步
java毕业设计爱宠医院管理系统mybatis+源码+调试部署+系统+数据库+lw
低代码引擎半岁啦,来跟大家唠唠嗑...
【Linux】环境变量
Python内置函数/方法详解—元组tuple
html静态网站基于动漫主题网站网页设计与实现共计10个页面——二次元漫画
React魔法堂:echarts-for-react源码略读
如何进行网站测试
了解list
【贪心 || 动态规划】最长对数链
- 原文地址:https://blog.csdn.net/qq_46044325/article/details/126923779