-
干货 | 精准化测试原理简介与实践探索
小时候大家应该都玩过一个游戏,游戏很简单,就是找不同,在规定时间内两幅图直接的差异点找到就算赢,越快越好,就像下面这样:
上面这个不同点想找很简单,那么下面这样的呢?
这个,确实有的人会说"我可以!" 。比如在综艺节目"最强大脑"中,这群"变态"的非人类确实可以
反正我不行,我也不信你们看到文章这里的人可以~我只有最菜大脑
理论上,我们全面的测试覆盖,肯定就就可以保证,那么我们先看下下面的代码:
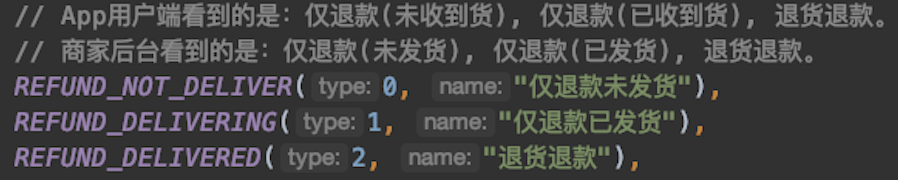
这是一份涉及订单状态的各种枚举,每一个状态的背后都有其业务逻辑,甚至还有交叉,假若按照笛卡尔积或者正交的方式来进行用例设计与覆盖,有。。。好多好多用例


-
那么~你真的有那么多时间去全覆盖吗?
开发:我改了点代码,等会帮忙全面回归一遍吧
测试:好的(*** bi~~ ***)
什么?自动化?Are you sure?
测试发展到如今,好像不会点自动化,都不好意思叫测试,简历上不写点自动化都拿不出手,但是自动化真的是测试的银弹不,做过的应该深有感触,自动化属于一个奢侈品: -
开发正本
-
维护成本
-
如何使用
-
用例的设计合理性
-
新功能的滞后性
再者,你确定你真的覆盖到了被测代码?也就是相当于魔方墙上的每个色块,实际在黑盒测试的过程中很大程度上取决于测试人员的经验,主观性很强,这样就很可能漏测,发布后出了问题就又要开撕了。。。

可能有的小伙伴会这样觉得,有人告诉我们答案,也就是告诉我们魔方墙的差异之处。这样我不就知道关注的测试点了吗?
没错,我们可以让开发告诉我们本次改了哪些方法,甚至有代码权限的情况下我们有能力可以自己去分析代码,妥了,金女士!
那么问题又来了。针对上面的情况,开发的描述一定是正确全面的吗?即使开发准确的说明了改动的代码,那么改动所影响到的其他范围呢?开发本人也不好确认的(不然还要测试干啥~),开发也有可能偷偷改代码不告诉你呢。

这个时候就渴望有这么一个"最强大脑"

- 眼过去就可以看出差异点(本次改动的逻辑)
- 脑海中就有了差异的影响范围(缩小需要测试的范围)
- 再一扫就看出哪些测试覆盖到了(确认测试覆盖率)
以求达到一种精准测试的程度
按照上面的描述,大概我们可以分为三个维度:
- 差异化
- 调用链
- 覆盖率
接下来的文章中会一个个详细来说~
不同的语言,都会有对应不同的语法分析器,语法分析器会把源代码作为字符串读入、解析,并建立语法树,这是一个程序完成编译所必要的前期工作。
我们看下 Java 的编译过程,重点关注步骤一和步骤二:
这里我们使用一个简单的Java对象,解析成AST后看下长什么样子
由于层级太多太复杂,这里选取属性user做个简单演示说明。如下:
每一项里面都包含了最全面的信息,包括名称、行号等,具体的可以访问在线调试网站https://astexplorer.net/进行调试查看
既然所有的代码信息都有了,那么我们就可以拿着这些信息进行比对,从而找出代码的差异之处;(当然这其中还是要很多降噪处理的,例如注释、空格、业务无关代码get/set等)
大概的流程逻辑如下3.2.1 字节码
因为Java代码的运行,是通过javac先将Java文件编译成.class结尾的字节码,再由JVM去执行;所以在字节码文件中,拥有了足够的元数据来解析类中的所有元素:类名称、父类名、方法、属性以及 Java 字节码(指令);
以如下源码为例:
- 1 public class AccurateTest {
- 2
- 3 private int a = 1;
- 4
- 5 public String add(int b){
- 6 return String.valueOf(a + b);
- 7 }
- 8 }
- 9
命令将其编译为字节码文件,再使用
命令将其反编译后得到如下信息:- Classfile /Users/qinzhen/Documents/My/TrainingProject/calctest/src/test/java/AccurateTest.class
- Last modified 2021-7-15; size 386 bytes
- MD5 checksum e67842e9b540c556d288c28b303298fb
- Compiled from "AccurateTest.java"
- public class AccurateTest
- minor version: 0
- major version: 52
- flags: ACC_PUBLIC, ACC_SUPER
- Constant pool:
- #1 = Methodref #4.#19 // java/lang/Object."
" :()V - #2 = Fieldref #3.#20 // AccurateTest.a:I
- #3 = Class #21 // AccurateTest
- #4 = Class #22 // java/lang/Object
- #5 = Utf8 a
- #6 = Utf8 I
- #7 = Utf8 <init>
- #8 = Utf8 ()V
- #9 = Utf8 Code
- #10 = Utf8 LineNumberTable
- #11 = Utf8 LocalVariableTable
- #12 = Utf8 this
- #13 = Utf8 LAccurateTest;
- #14 = Utf8 add
- #15 = Utf8 (I)I
- #16 = Utf8 b
- #17 = Utf8 SourceFile
- #18 = Utf8 AccurateTest.java
- #19 = NameAndType #7:#8 // "
" :()V - #20 = NameAndType #5:#6 // a:I
- #21 = Utf8 AccurateTest
- #22 = Utf8 java/lang/Object
- {
- public AccurateTest(); //构造函数
- descriptor: ()V
- flags: ACC_PUBLIC
- Code:
- stack=2, locals=1, args_size=1
- 0: aload_0
- 1: invokespecial #1 // Method java/lang/Object."
" :()V - 4: aload_0
- 5: iconst_1
- 6: putfield #2 // Field a:I
- 9: return
- LineNumberTable:
- line 1: 0
- line 3: 4
- LocalVariableTable:
- Start Length Slot Name Signature
- 0 10 0 this LAccurateTest;
- public java.lang.String add(int); //方法名
- descriptor: (I)Ljava/lang/String; //方法描述符(入参和返回值类型)
- flags: ACC_PUBLIC //方法的访问标致
- Code: //code开始
- stack=2, locals=2, args_size=2
- 0: aload_0
- 1: getfield #2 // 引用常量池的值 Field a:I
- 4: iload_1
- 5: iadd
- 6: invokestatic #3 // Method java/lang/String.valueOf:(I)Ljava/lang/String;
- 9: ireturn
- LineNumberTable: //行号表,将上述操作码与.java中的行号做对应
- line 6: 0
- LocalVariableTable:
- Start Length Slot Name Signature
- 0 7 0 this LAccurateTest;
- 0 7 1 b I //本地变量
- }
- SourceFile: "AccurateTest.java"
通过上述信息我们可以直观的看到字节码中包含了Java运行所需的所有信息,且JVM对于字节码文件要求严格,必须按照固定的组成和顺序,而这种特性也就适合利用访问者模式对字节码文件进行修改;因此也就要介绍我们的调用链生成的核心技术栈——ASM
3.2.2 ASM
操作;
API接口,每当
,扫描到类注解就会回调
等;
方法来实现字节码的读取和插入,例如在做调用链分析时我们就用到了其
方法来对方法体内的调用信息进行过滤和提取通过上述的信息进行匹配桥接,我们就可以拿到调用链中的一系列父子节点,形成我们的方法调用链
大概的流程逻辑如下:
说到覆盖率统计,就要介绍当前在这个技术领域中占据主导地位的开源工具-jacoco
jacoco使用总的来说和装大象一样,需要三步-
- 对被测项目进行字节码插桩
-
- 覆盖率数据的采集与导出
-
- 覆盖率数据的统计与报告生成
下面我们对这三个步骤逐一拆解
插桩,其实就是安插监控探头,我们的一行行代码就好比一条条马路,代码里的分支(if-else)就好比马路上的各种支路岔道,而插桩就相当于在每一条路的路口都装上了一个探头
- 覆盖率数据的统计与报告生成
如下就是在字节码中插入探针信息的图示:
jacoco的插桩模式有两种:
- on-the-fly模式(运行时插桩)
- 通过配置-javaagent在启动命令中,jacoco介入被测项目部署过程,将探针(探头)插入class文件,探针不改变原有方法的行为,只是记录是否已经执行。
- 优点:无需提前进行字节码插桩,无需考虑classpath 的设置。
- 缺点:要修改JVM参数,对环境的要求比较高,于一些无法修改启动命令的场景不适用。
- offline模式(编译时插桩)
- 在测试之前先对文件进行插桩,生成插过桩的class或jar包,测试插过桩的class和jar包,生成覆盖率信息到文件,最后统一处理,生成报告。
- 优点:屏蔽工具对虚拟机环境的依赖;
- 缺点:需要提前侵入代码;无法实时获取覆盖率,只能测试完成后停止项目后统一生成报告
选择:
方式无须入侵应用启动脚本,再加上公司的运维和开发可以配合部署
启动参数,因此我们最终选择
模式进行插桩3.3.2 覆盖率收集与导出
看了上面的插桩原理,想必覆盖率的收集也就很好理解了,依然是以监控探头为例,当我们测试一行行代码时,就相当于开着车跑在一条条道路上,而每进入一行代码就像是开车进入了一条道路,那么进入的时候就会被监控探头拍摄记录下来,也就知道你跑过哪条路了。
同理,覆盖到一行代码时,探针就会记录下信息,最终也就知道了哪一行代码被覆盖到了至于导出,覆盖率的统计信息会通过暴露的服务端口(默认6300)去获取,导出一份以.exec结尾的文件,文件中包含了当前的覆盖率信息
通过对exec文件的解析,jacoco便可以获取所有方法的探针信息,从而计算覆盖率,并对代码进行染色输出报告:
针对代码的染色如下
- 红色:代表未覆盖
- 黄色:代表部分覆盖,
- 绿色:代表完全覆盖
在实际的使用场景中,我们可能还更关注本次修改的代码,测试的时候我们会重点测试本轮开发的新增和改动范围,因此jacoco原生的功能就不能满足了,jacoco原生统计的是全量的覆盖率。
对于改动点,我们称之为增量,所以我们对jacoco的源码进行了二次开发,使其支持增量的覆盖率统计,以满足日常测试需求;对比上面全量的范围,可以看到增量的统计范围就明确了,数量就少了很多:
- 大概的架构逻辑如下:
开发修改了一个方法或者一个接口,那么这个接口可能被N个应用去调用,一旦这个接口有问题,那么影响面是相当大的;或者这个接口本身没问题,但是上下游没有兼容好,调用出了问题也是影响产品质量的;所以这个也是我们测试关注的重点。
再者,我们日常的测试有很大一部分比例是接口测试,包括自动化也是,接口自动化用例很多。那么如果可以通过调用链路找到本次修改所影响到的最上层的入口接口(
等),那么通过接口与用例的关联关系,就可以推荐出本轮修改必须要执行的用例,提高用例的精准程度和更加明确的测试范围。
还有,如果改动的接口没有关联的用例,或者用例执行完以后覆盖率不达标,那么也可以对用例进行查漏,添加新的用例进行覆盖。- 优点:方案相对成熟,业界有落地案例,实现难度尚可
- 缺点:链路也是通过插桩监控的,那么前提就是这条链路要走到了才会存在,这样就有滞后性,新增加的代码链路还没有测试过,那这条链路自然也就拿不到了
聊到这里,基本上就把测试人员的灵魂3问给回答完毕了。关于精准化测试,这里有几个问题会困扰测试开发人员。这里给出一些建议,希望可以对读者有所益处。
1、如果我的代码覆盖率达到100%了,是不是就可以说测试覆盖完全了,质量有保障了?答:不是, 覆盖率低,质量一定没有保障,但是覆盖率高,只是保障的一个维度达到了。
这里我们只是知道了代码被覆盖了,但是代码逻辑的正确性呢?精准化是无法判断的,要靠大家自己去断言了。
再者,覆盖到的代码都是开发按照自己理解的业务逻辑写的,如果他漏写了一些需求逻辑呢?那这部分就不存在覆盖的情况了。2、我是不是每次都要保证所有的方法覆盖率都达到100%?
答:不是,方法的覆盖率要达到什么样的一个值,不好直接下结论。有些代码逻辑,好比一些异常的捕获,这个异常的触发场景很难,日常测试几乎走不到,那么就是覆盖不了,覆盖率也就不可能达到100%。
3、根据问题2,既然达不到100%,那么我是不是设一个阈值,好比80%?90%?,达到这个阈值就可以了?
答:也不是,有些方法,它的代码逻辑可能都是核心逻辑,其中的分支都需要覆盖,缺少了就有漏测出Bug的风险,且理论上都是可以通过测试覆盖到的,那么这种方法就需要达到100%的覆盖率。
4、那要怎么衡量覆盖率的指标?
答:一方面可以设定一个最低阈值,哪怕代码有些逻辑走不到,也不会大面积并且占比很高,还是需要一个最低的覆盖率保障;
再者,需要测试的同学根据自己测试的业务进行情况划分,具备codereview的能力和习惯,平台仅作为一个辅助测试的工具;
最后,我们可以记录下以往测试的覆盖率,根据不同业务通过测试后的覆盖率情况统计覆盖率的趋势,以历史的覆盖率数据为依据来设定阈值或监控告警,如果覆盖率低于往期正常的值,就进行告警或者卡点内容全面升级,4 个月 20+ 项目实战强化训练,资深测试架构师、开源项目作者亲授 BAT 大厂前沿最佳实践,带你一站式掌握测试开发必备核心技能(对标阿里P6+,年薪50W+)!直推 BAT 名企测试经理,普遍涨薪 50%+!
-
-
相关阅读:
运动想象 (MI) 迁移学习系列 (9) : 数据对齐(EA)
qlib+mongo实现转债金融时间序列数据查询
【机器学习基础】机器学习入门(2)
图神经网络-GraphSage
智能投影:坚果、当贝前攻后防
docker安装
win10+vs2019 编译webrtc m108
花菁染料CY3/CY5.5/CY7标记壳多糖/壳聚糖/菊粉/果胶,CY3/CY5.5/CY7-Chitin/Chitosan/Inulin/Pectin
[SLAM] 传感器总结
2.Android系统启动
- 原文地址:https://blog.csdn.net/ceshiren456/article/details/126930984

{kind=link}
{kind=link}